




 本文介绍了携程在实体链接技术上的探索与实践,通过构建旅游知识图谱,解决了文本多样性带来的实体消歧问题。文章详细阐述了实体链接的三阶段流程,包括实体提及识别、候选实体生成和实体消歧,并展示了在旅游搜索、智能客服、POI关键信息更新和重复POI识别等场景中的应用,有效提升了用户体验和信息准确性。
本文介绍了携程在实体链接技术上的探索与实践,通过构建旅游知识图谱,解决了文本多样性带来的实体消歧问题。文章详细阐述了实体链接的三阶段流程,包括实体提及识别、候选实体生成和实体消歧,并展示了在旅游搜索、智能客服、POI关键信息更新和重复POI识别等场景中的应用,有效提升了用户体验和信息准确性。
作者简介
携程旅游AI研发团队致力于为携程旅游事业部提供丰富的AI技术产品,其中知识图谱组专注旅游领域知识图谱的构建及应用落地。
一、背景介绍
随着网络应用技术的飞速发展,多元化、低密度数据的急剧膨胀对人们获取正确信息带来巨大挑战,大量冗余信息出现的根源在于自然语言表达的多样性,即一词多义和多词同义。例如,“苹果”在不同语境下既可以表示蔷薇科苹果属植物又可以表示苹果产品公司,“申城”和“魔都”尽管字面完全不同,却都是上海市的别称。实现对海量Web数据的高效处理,理解用户意图,降低信息过载,是实体链接的目标。
在旅游领域,用户关注的实体通常是旅游目的地周边景点、酒店和玩乐方式等,这些对象在地理信息系统(Geographic Information Systems, GIS)中统称为兴趣点(Point of Interest,POI),主要包含四个核心维度:名称、地址、坐标和类别。随着互联网电子地图服务与基于位置的服务(Location Based Services,LBS)的普及,POI无论从概念范畴还是信息纵深上都有了长足发展,已成长为信息空间的参天大树,可以说目前如日中天的互联网各个风口都和POI有一定关系,如电商、O2O、社交、本地生活、互联网金融、共享经济等。
构建以POI知识库为基础的实体链接服务,提升旅游搜索、智能问答、知识挖掘和信息抽取等工作的效果,对改善用户体验有重要意义。
二、问题分析
实体链接,指将文本中的表述链接到知识库中相应实体来进行实体消歧、帮助计算机理解文本具体含义的任务,一般包含实体提及识别、候选实体生成和候选实体消歧三个步骤。
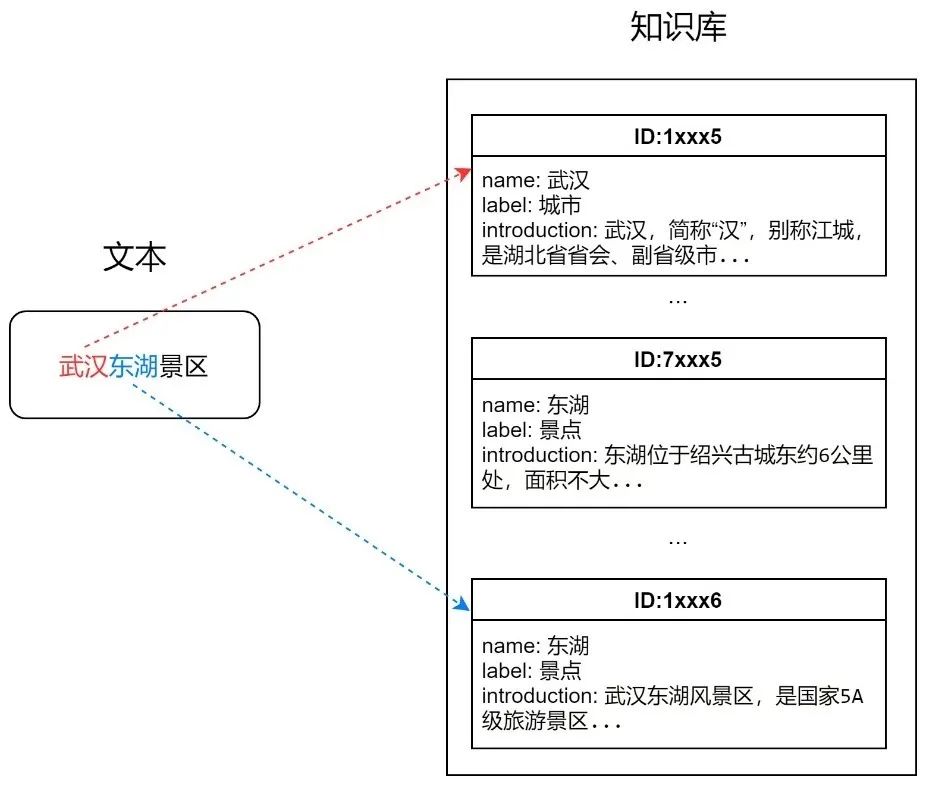
图1 实体链接功能示例
1)实体提及识别,旨在识别出自然语言中实体提及片段的边界,并标示其在输入文本中的位置。以图1例子进行说明,用户输入的搜索词“武汉东湖景区”包含了“武汉”和“东湖”两个命名实体提及,它们可能表示知识库中某些实体的正式名称、简称、俗称或者别名。
2)候选实体生成为文本中给定的实体名称生成可能链接的候选实体集合,即根据前一步识别到实体提及片段从知识库中召回所有用户可能感兴趣的实体,该步骤生成的候选项集确定了实体消歧的范畴。例如,“武汉”这一实体提及可以从知识库中召回作为城市的“武汉”,而“东湖”则可以召回“武汉东湖”和“绍兴东湖”两个景点。
3)实体消歧是确定一个实体指称项所指向的真实世界中实体的过程,通过候选实体的静态特征、或与query交互计算的动态特征输出一个用于排序的分值。以图1为例,结合上下文可知,用户真正查询的是武汉市下面的东湖,而非位于绍兴市的东湖,因此“武汉东湖”相对“绍兴东湖”应有更高的得分。
实体提及识别常被视作序列标注任务,经典方法有基于词典的方法和基于统计的方法。基于词典的方法可分为前向最大匹配、后向最大匹配和双向最大匹配;基于统计学习的代表方法有HMM和CRF,其表现通常依赖大量人工构建和维护的特征模板。随着算力的提升和端到端的神经网络技术的发展,CNN、RNN等结构被广泛用于建模序列表示,其自动组合低阶特征获得高阶特征的功能摆脱了人工特征工程耗时费力的弊端,同时神经网络强大的表达能力显著提升了传统算法的效果。
Google在2018年提出的Transformer则首次将自注意力模型带入大众视野,为序列表征的高效并行计算提供了可行的方案。Self-attention机制的运用使得序列中每个位置的token都能充分学习到上下文语义,自适应地接收来自不同位置token的信息流入,成为近年大热的自监督学习任务的基本编码单元,启发了众多以此构型为基础的大型预训练语言模型,BERT便是代表之一。
使用Transformer Encoder结构的BERT从无标签语料中学到了大量先验知识,只需在特定下游任务上微调权重,便能获得出色的结果。BERT一度霸榜GLUE,刷新了各大自然语言理解任务的SOTA,其预训练加微调的学习范式也成为NLP界的重大里程碑。
候选实体生成是一种检索任务,传统检索方法以词袋模型(Bag of Words,BOW)为代表,如TF-IDF、BM25等,这类算法不考虑词序,也忽略了词与词之间的前后关联,除需人工设计公式外,在统计词的权重、词频的基础上,还要引入覆盖率、紧密度,扩展同义词等,才能达到一个较好的效果。词袋模型最
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2164
2164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









