







由于TCP/IP是使用最普遍的Internet协议,下面只集中讨论TCP/IP 栈和以太网(Ethernet)。术语 LinuxTCP/IP栈和 Linux网络栈可互换使用,因为 TCP/IP栈是 Linux内核的组成部分,也被看作是 Linux默认的网络栈。
一、实例分析中使用的基准测试
1、 NetBench
NetBench是一种 Ziff-Davis基准测试, 可以测量文件服务器对来自客户端(向服务器提交网络文件操作的请求)的远程文件 I/O请求进行处理的程度。NetBench报告关于吞吐率和客户响应时间的测量结果。该基准测试主要用于测量 LinuxTCP/IP发送端(NetBench服务器)的吞吐率性能,因为对于该基准测试而言,接收端客户是 32位的 Windows客户。
2、 Netperf3
Netperf3是一种测试 Linux网络吞吐率和网络扩展性的微型基准测试。试验版本可从 http://www.netperf.org获取。该版本提供了多线程支持。 IBM公司对 Netperf3的功能加以增强,使其包含了对多网卡(NIC)和多客户的支持。添加这两个特性是为了测量Linux网络 SMP和网卡的扩展性。 IBM公司还添加了另一个可旁路 TCP/IP栈的接口,用于测试网络驱动程序。 Netperf3所测的度量是吞吐率(以每秒兆位为单位)。
二、Linux 2.6 内核中的增强机制
在当前的计算机系统里,互连总线速度和内存访问延迟并没有与处理器速度(GHz)和网络带宽容量(吉比特网络)成比例增长。减少对互连总线和内存等相对慢速部件的访问次数通常可以改进系统(包括网络)的性能。在 TCP/IP栈中, 作为传输和接收过程的组成部分,会发生多次数据复制操作,从而在互连总线中产生巨大流量。这些流量引起访存次数的增加,从而导致低下的网络性能和扩展性问题。在 SMP 和 NUMA系统中, 额外的高速CPU与相对慢速的互连总线之间的矛盾进一步加剧了扩展性问题 。
总线速率、总线吞吐率以及工作负荷生成的总线流量对于改进 Linux网络栈的性能至关重要。为了消除或减少数据流经总线的次数以及为了减少访存次数而对 Linux网络栈实施的任何改进都可以改善 Linux软件栈性能。下面分析2.6内核实现的一些增强特性,这些特性减少了在 TCP/IP 协议栈中执行的复制次数,从而提高了网络栈性能。这些增强特性具体包括以下内容:
- SendFile支持
- TCP分段卸载(TCP SegmentationOffloading, TSO)支持
- 进程和 IRQ亲合度
- 网络设备驱动程序 API(NAPI)
- TCP卸载引擎(TCP OffloadEngine, TOE
- 分配一个缓冲区。
- 将文件数据复制到缓冲区中(首先将文件数据从磁盘复制到内核缓冲区 cache,然后再复制到应用程序的缓冲区)。
- 对复制到内核 socket缓冲区中的数据执行发送操作。
- 获取到达 NIC的 DMA。
如名字所示,SendFileAPI只能传输文件系统数据。因此,诸如 Web服务器、Telnet等处理动态数据和交互式数据的应用无法使用这个 API。由于在 Internet上传输的数据大部分是静态(文件)数据并且文件传输是这种通信的主体部分,因此 SendFile API 和Zerocopy对于改进网络应用的性能非常重要。适当地使用了 SendFile和 Zerocopy的应用程序能够极大地改进网络性能。
Linux 中对 SendFile API 的支持以及在 Linux TCP/IP 栈和网络驱动程序中对Zerocopy的支持实现了在 TCP/IP 数据处理过程中的单次复制机制。SendFile对于应用程序是不透明的,因为应用程序需要实现这个 API以便利用该特性。
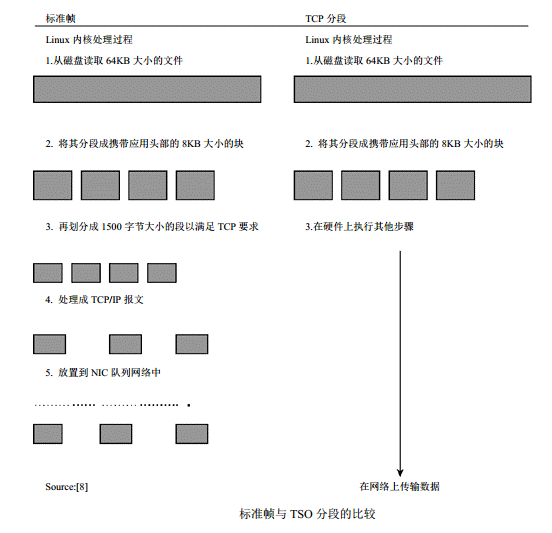
2、 TCP分段卸载
如果使能了 TSO特性, 则为 64KB数据封装一个伪报文头, 并通过 DMA将其发送至 NIC。 网络适配器的控制器将这个 64KB数据块解析成标准的以太网报文,从而减少了主机的 CPU利用率和对 PCI总线的访问。 TSO通过降低 CPU利用率和提高网络吞吐率来改善效率。针对该任务专门设计了网络芯片(network silicon)。在 Linux以及针对 TSO而设计的 Gigabit Ethernet芯片中激活 TSO特性能够增强系统性能。
亲合性或绑定的含义是指强制只在选定的一个或多个 CPU上执行进程中断的过程。在多处理器系统中,基于操作系统调度器使用的策略,在特定条件下可以将一个处理器上的进程迁移到其他处理器。通过将进程保持在同一个处理器——这强制调度器将某个特定任务调度到指定 CPU上——可以极大提高所需数据存在于 cache中的概率,从而可以减少内存延迟。有些情况下,即使进程被限定在同一个 CPU上调度, 诸如大型工作集以及多进程共享同一个 CPU等因素也常常导致清空 cache,因此进程亲合性可能无法在所有情况下都起作用。本章给出的实例分析非常适于利用进程亲合特性。
Linux内核实现了下列两个系统调用,以便执行进程与处理器的绑定操作:
asmlinkage int sys_sched_set_affinity(pid_t pid, unsigned int mask_len,unsigned long *new_mask_ptr);
asmlinkage int sys_sched_get_affinity(pid_t pid, unsigned int*user_mask_len_ptr, unsigned long *user_mask_ptr);进程亲合性意味着将进程或线程绑定到某个 CPU上。IRQ亲合性意味着强制在某个特定 CPU上执行具体 IRQ的中断处理。在 Linux中可以使用/proc接口设置 IRQ亲合性。通过确定 I/O接口所用的 IRQ,然后修改该特定 IRQ的屏蔽码,可以设置 IRQ亲合性。例如,以下命令将 IRQ 63设置到 CPU 0,并将 IRQ 63所生成的中断发送到 CPU 1上
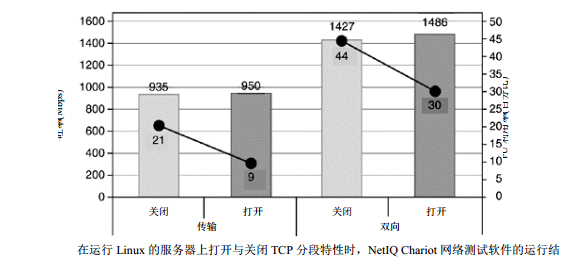
echo "1" > /proc/irq/63/smp_affinityNetperf3示例分析清晰表明,IRQ与进程亲合性的应用改善了Linux网络的 SMP扩展性和网络吞吐率性能。在该例子中,使用了 Netperf3的多适配器支持能力来测量网络扩展性。它对每个 NIC都创建一个进程, 该进程绑定到 4个 CPU中的某个 CPU以及某个 NIC上。该 NIC将由该进程使用并与之绑定到同一个CPU。一个 Netperf3进程的处理操作是被隔离的,并且对某个 NIC所生成的中断的执行操作被隔离到单个处理器上。在 Netperf3服务器上使用 TCP_STREAM测试来完成这个过程。
在服务器上,该工作负荷进行繁重的数据接收处理操作,会产生多次数据拷贝操作(将数据从 NIC复制到内核内存中,再从内核内存中复制到应用内存中)。绑定机制提高了性能,因为这些复制操作在单个处理器上完成,从而无需将数据加载到两个不同的处理器 cache中。如果同时应用这两个亲合性的话,那么绑定机制可以减少内存延迟。尽管可以单独使用IRQ亲合性或进程亲合性,但组合使用时能够进一步提高性能。
4、 NAPI
Linux 2.5内核中的 NAPI实现使得网络设备驱动程序员无需在每个驱动程序中人工实现轮询,还可以管理中断泛洪,并保护系统免受拒绝服务(Denial of Service, DoS)攻击。由于中断处理程序的 CPU开销,在没有 NAPI支持的情况下泛洪的最高限额要低得多。NAPI也消除了编制大量代码来实现NIC硬件中断缩减(interrupt mitigation)解决方案的需求。为了利用 NAPI的优点,网络设备驱动程序需要使用新的网络 API(NAPI)。当前,许多网络设备驱动程序都提供对 NAPI的支持。 Intel Gigabit Ethernet等网络驱动程序将NAPI作为一个可构建在驱动程序中的选项, 而诸如 BroadComTg3等驱动程序默认地支持 NAPI。如果网络驱动程序不使用 NAPI特性的话,则内核中的 NAPI代码也不被使用。
对千兆位以太网的工作负荷分析表明, 系统需要 1GHz的 CPU处理能力来处理每吉比特网络流量。随着更高速的处理器系统、高性能串行PCI-Express系统总线、内置了检验和运算逻辑的以太网控制器以及中断缩减机制的出现,用户将可以在服务器中使用多条千兆位以太网连接,同时不会导致性能下降。然而,网络带宽的改善也与系统通过诸如TOE之类的解决方案来提高网络性能的其他部件改进保持一致。但由于存在着严重的性能问题,并且实际部署 TCP卸载机制比较复杂,TCP卸载作为一种通用解决方案已经失败。学术界和产业界中对于 TOE技术都存在着支持与反对的声音。然而,除了集群和网络存储解决方案外,许多厂商还开发了用于其他各种工作负荷的 TNIC。
与 LinuxTCP/IP软件栈代码相比,各种 TOE解决方案都是专有的,其功能也各异。这些专有的 TOE方案中可能不提供某些特性如 IPCHAINS、 IPTABLES以及通用报文处理能力。许多开发 TNIC和驱动程序的厂商都支持多种操作系统。尽管早期测试结果显示在Linux上 NetBench的性能改进了 17%, 但所用的驱动程序在测试时并不稳定, 因此需要进一步研究这种特性。如果驱动程序和 NIC更稳定的话,应该会实现更高的性能结果。
注意 TOE不同于 TCP分片卸载(TSO)。 TSO只对数据分片操作进行卸载。在 TSO技术中,TCP/IP栈将应用程序传来的整个消息都封装在帧里传递给 NIC。 NIC再将数据(消息)划分为多个帧,为每个帧构造帧头以便进行传输。这种卸载操作只在发送端(输出通信)完成,不处理输入通信。而 TOE将整个 TCP/IP协议栈处理操作都卸载到 NIC上,包括输入和输出处理。
尽管TOE解决方案是一种改进网络性能的急需技术, 但目前还不清楚 Linux开源社区将如何采纳该技术。有些人认为 LinuxTCP/IP栈中已支持 Zerocopy机制, 因此复制操作的次数已得到减少。采用 TOE技术所实现的多数性能收益可通过 NIC中的校验和、分片卸载以及中断缩减机制来获取,而其余功能只执行基本的 socket管理和进程唤醒,因此不需要这种技术。如果 TOE解决方案不断改进, 并且与软件网络栈相比能够显示出巨大优势,则 TOE技术的采用量可能会增加。
目前,只有商业公司在开发 TOE引擎, 因此这类解决方案的实现随着厂商的不同而各异。厂商也许能够减少或解决 TOE实现和部署中的难题, 并改变那些不愿意承认 TOE是网络性能改进可行方案的怀疑者的想法。
三、 示例分析
下面给出该示例分析所使用的基准测试的结果,并展示目前为止所讨论的各种性能增强特性的累积性能改进。某些基准测试捕获所有特性的累积收益,而另一些则捕获特定工作负荷的特定收益。
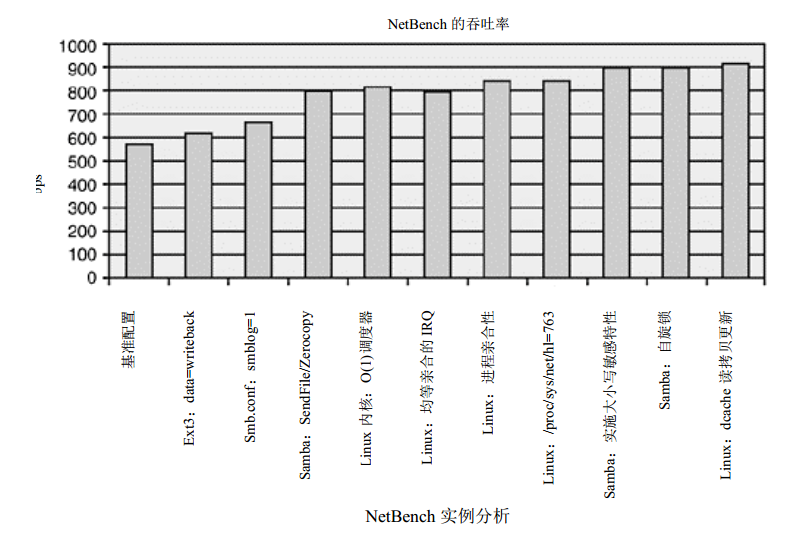
- 基准配置(Baseline)。代表了 SUSE Linux企业级服务器 8.0版本(SUSE SLES 8)的一个干净安装,未对性能配置进行任何修改。
- data=writeback。 对一个 Ext3默认挂接选项的配置加以改动,将/data文件系统(提供了 Samba共享)从 ordered改为 writeback。这极大改进了文件系统在元数据密集的工作负荷下的性能,例如本例。
- smblog=1。Samba日志级别从 2改为 1,以减少对 Samba日志文件的磁盘 I/O操作。级别1足以将关键错误记入日志中。
- SendFile/Zerocopy。 该补丁使得 Samba对于客户读请求使用 SendFile机制。该补丁与 Linux的 Zerocopy技术(最早出现于 2.4.4版本中)结合使用,可以消除两种高开销的内存复制操作。
- O(1)调度器。 这个小改进有利于未来的其他性能改进。 O(1)调度器是能够改进对称多处理器性能的多队列调度器。这是 Linux 2.5和 2.6内核中的默认调度器。
- 均等亲合的 IRQ(evenly affined IRQ)。 4个网络适配器中每个适配器的中断都由唯一的处理器来处理。在 P4体系结构中,SUSE SLES 8的 IRQ至 CPU映射机制默认为轮询分配(destination= irq_num% num_cpus)。在示例中,网络适配器的所有 IRQ都被转至 CPU0。 这对于性能非常有益, 因为该代码上的 cache暖和性已获得改进, 但随着更多 NIC被添加到系统中, 单个 CPU可能难以处理全部网络负荷。理想的解决方案是均匀地亲合这些 IRQ, 使得每个处理器都处理来自一个 NIC的中断。这种机制与进程亲合性结合使用,应该能够将指派给某个特定 NIC上的进程也指派到一个 CPU上,以便获取最高性能。
- 进程亲合性。 该技术确保对于每个被处理的网络中断,相应的 smbd进程都在同一个 CPU上被调度以便进一步改善 cache暖和性。
- /proc/sys/net/hl=763。 增加网络协议栈代码中拥有的缓冲区数量,从而使网络栈不需调用内存系统来从中获取或释放缓冲区。 Linux 2.6内核中未提供这个调优特性。
- 实施大小写敏感特性。 如果未实施这个特性, Samba在打开一个文件前可能需要搜索该文件的不同版本名称, 因为同一个文件可以拥有多个文件名组合。启动大小写敏感特性就可以消除这些猜测。
- 自旋锁(spinlock)。 Samba的数据库中使用了高开销的 fcntl()调用。可以使用自旋锁来代替这个调用。利用在 posix_lock_file()中发现的大内核锁(Big Kernel Lock)可以减少大内核锁的竞争和等待时间。要使用该特性, 可以通过--use-spin-locks来配置Samba,如下例所示。
Smbd --use-spin-locks -p <port_number> -O<socket option>
-s <configuration file>- dcache 读复制更新(read copy update)。 通过使用读复制更新技术,一种新的dlookup()实现可以减少目录项查询次数。读复制更新是 Linux中用作互斥机制的一种两阶段更新方法, 可以避免自旋等待锁的开销。更多信息参见 Linux可伸缩性研究计划(Linux Scalability Effort)中关于锁(locking)技术方面的工作。
价格日益降低的千兆位以太网卡正快速取代百兆位以太网卡。当前,系统制造商在主板上提供了千兆位以太网支持, 系统供应商和集成商也选择使用千兆位以太网卡和交换机来连接磁盘服务器、计算机中心以及部门骨干网。下面讨论 Linux操作系统中的千兆位网络性能,以及千兆位以太网调优对网络性能的改进。
千兆位以太网卡(Intel Gigabit Ethernet和 Acenic Gigabit Ethernet)提供了几个有利于处理高吞吐率的额外特性。这些特性包括对巨型帧(MTU)长度、中断延迟(interrupt-delay)以及TX/RX描述符的支持:
- 巨型帧长度。千兆位以太网卡的 MTU长度可以大于 1500B。百兆位以太网中 1500B的 MTU限制不再存在。增加 MTU的大小通常能够改进网络吞吐率,但必须确保网络路由器支持巨型帧长度。否则,当系统连入百兆位以太网络时,千兆位以太网卡会降至百兆位的能力。
- 中断延迟/中断合并。可以针对接收中断和传输中断设置中断合并特性,使得 NIC在指定时间内延缓生成中断。例如,当 RxInt设置为 1.024μs(这是 Intel GigabitEthernet网卡上的默认值)时, NIC将收到的帧放入内存中, 在经过 1.024μs后才生成一个中断。这个特性减少了上下文切换次数,因此可以改进 CPU效率,但它同时也增加了接收报文的延迟。如果针对网络流量对中断合并特性加以适当调优,也能够改进 CPU效率和网络吞吐率性能。
- 传输和接收描述符。千兆位以太网驱动程序使用这些参数来分配数据发送和接收缓冲区。增加其取值可以允许驱动程序缓冲更多的输入报文。每个描述符都包含一个传输和接收描述符缓冲区以及一个数据缓冲区。这个数据缓冲区的大小依赖于MTU长度。对于本例的驱动程序, MTU最大长度为 16110。
在一台主频为1.6GHz的4路Pentium 4机器与4台客户机(主频为1.0GHz的Pentium3)之间执行这些测试,这些机器拥有可达到通信介质速度上限的千兆位网卡。所有机器都使用 Linux 2.4.17 SMP vanilla内核。 e1000驱动程序的版本号是 4.1.7。测试类型是Netperf3的 PACKET_STREAM和 PACKET_MAERTS,其 MTU都是 1500B。 Pentium 4
机器拥有 16GB RAM和 4个 CPU。4个 NIC均等分布在 100MHz和 133MHz PCI-X插槽之间。在Pentium 4系统上禁用了超线程特性。
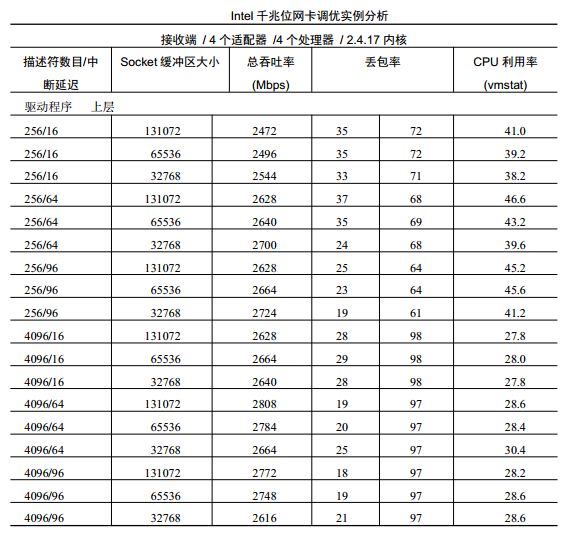
PACKET_STREAM测试只传输没有任何 TCP/IP报文头部的原始数据。它不通过TCP/IP协议层次来传输或接收报文,只是为了测试 CPU、 内存、 PCI 总线和 NIC驱动程序以查找这些部件中的瓶颈。它使用不同值来调优千兆位驱动程序的中断延迟以及传输和接收描述符,以确定这些参数针对环境的最佳取值。另一个调优选项是改变 socket缓冲区容量。
如下表所示,在这 4个网卡中,可达到的最大吞吐率是 2808Mbps,实现该吞吐率的调优参数设置如下: 传输和接收描述符数量为 4096, 接收端和发送端的中断延迟都为 64, socket缓冲区大小约为 132 000 。















 96
96

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









