







文章目录
前言
本文主要讲解基于mxnet深度学习框架实现目标检测,实现的模型为YoloV4
环境配置:
python 3.8
mxnet 1.7.0
cuda 10.1
目标检测发展史及意义
图像分类任务的实现可以让我们粗略的知道图像中包含了什么类型的物体,但并不知道物体在图像中哪一个位置,也不知道物体的具体信息,在一些具体的应用场景比如车牌识别、交通违章检测、人脸识别、运动捕捉,单纯的图像分类就不能完全满足我们的需求了。
这时候,需要引入图像领域另一个重要任务:物体的检测与识别。在传统机器领域,一个典型的案例是利用HOG(Histogram of Gradient)特征来生成各种物体相应的“滤波器”,HOG滤波器能完整的记录物体的边缘和轮廓信息,利用这一滤波器过滤不同图片的不同位置,当输出响应值幅度超过一定阈值,就认为滤波器和图片中的物体匹配程度较高,从而完成了物体的检测。
一、数据集的准备
首先我是用的是halcon数据集里边的药片,去了前边的100张做标注,后面的300张做测试,其中100张里边选择90张做训练集,10张做验证集。
1.标注工具的安装
pip install labelimg
进入cmd,输入labelimg,会出现如图的标注工具:

2.数据集的准备
首先我们先创建3个文件夹,如图:
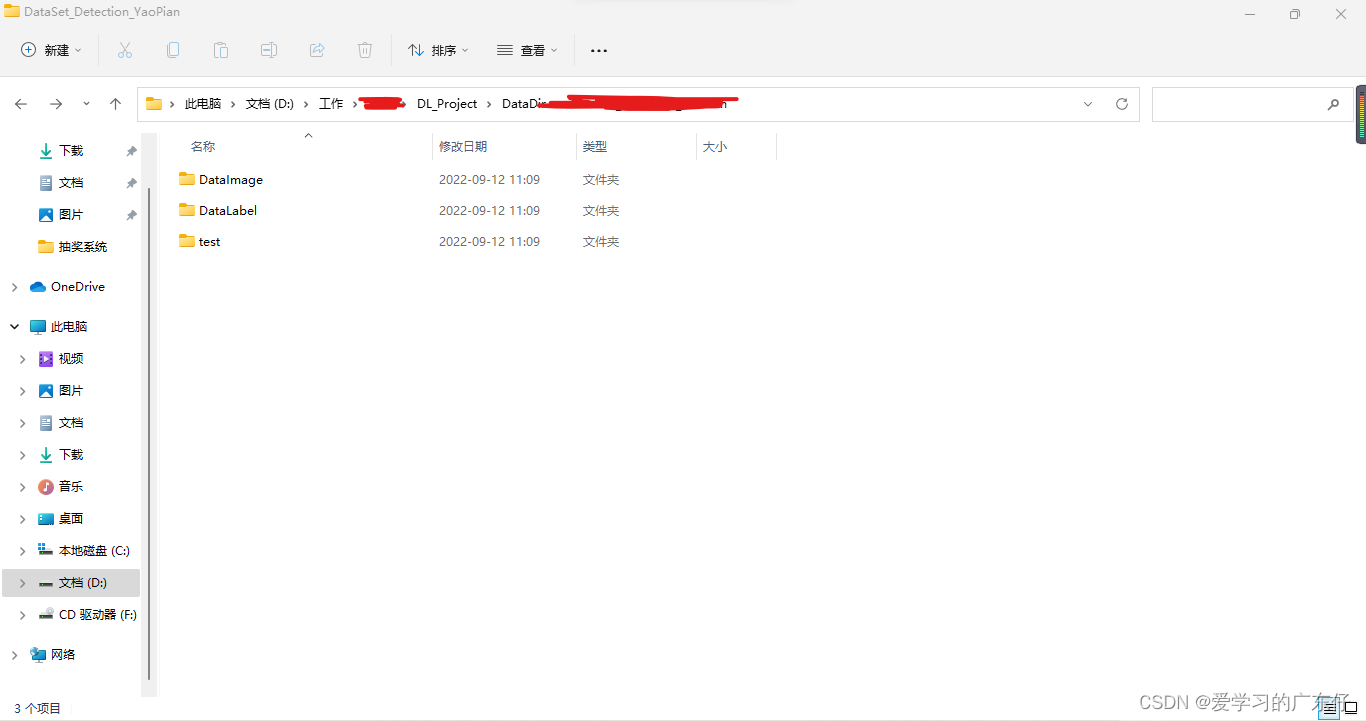
DataImage:100张需要标注的图像
DataLabel:空文件夹,主要是存放标注文件,这个在labelimg中生成标注文件
test:存放剩下的300张图片,不需要标注
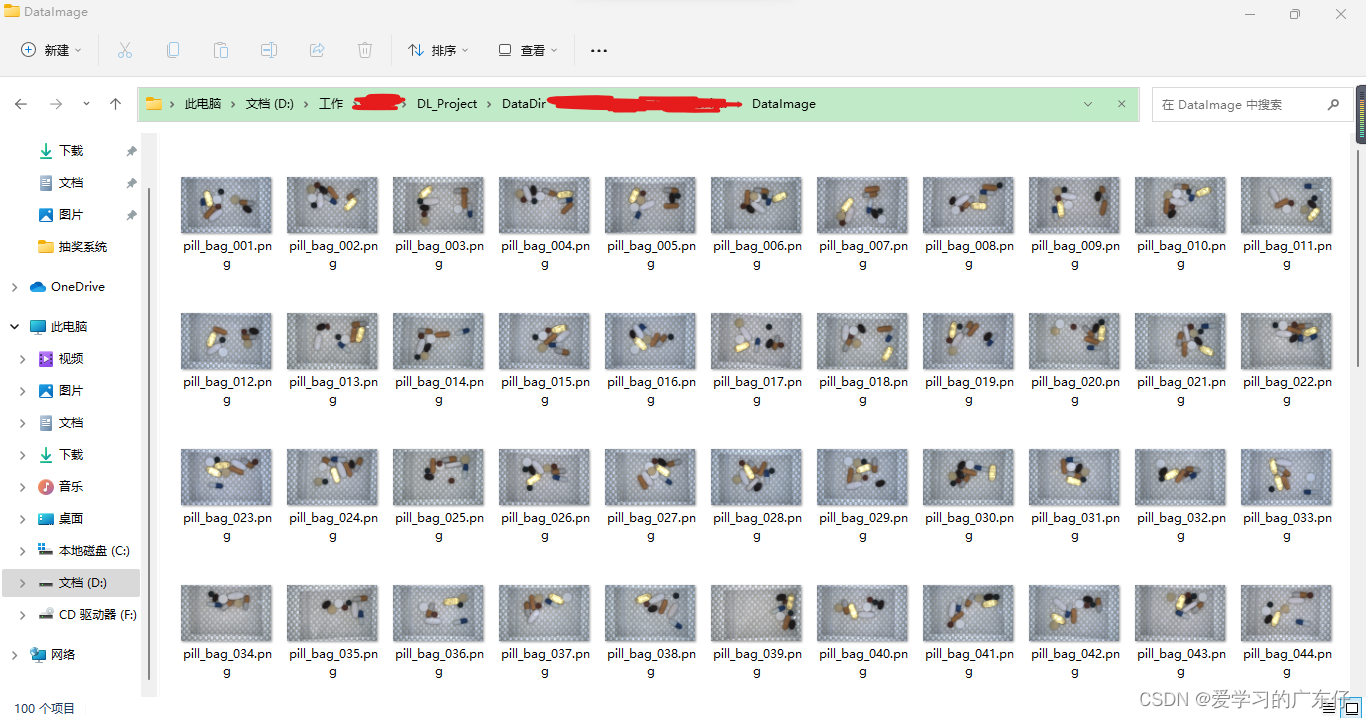
DataImage目录下和test目录的存放样子是这样的(以DataImage为例):
3.标注数据
首先我们需要在labelimg中设置图像路径和标签存放路径,如图:

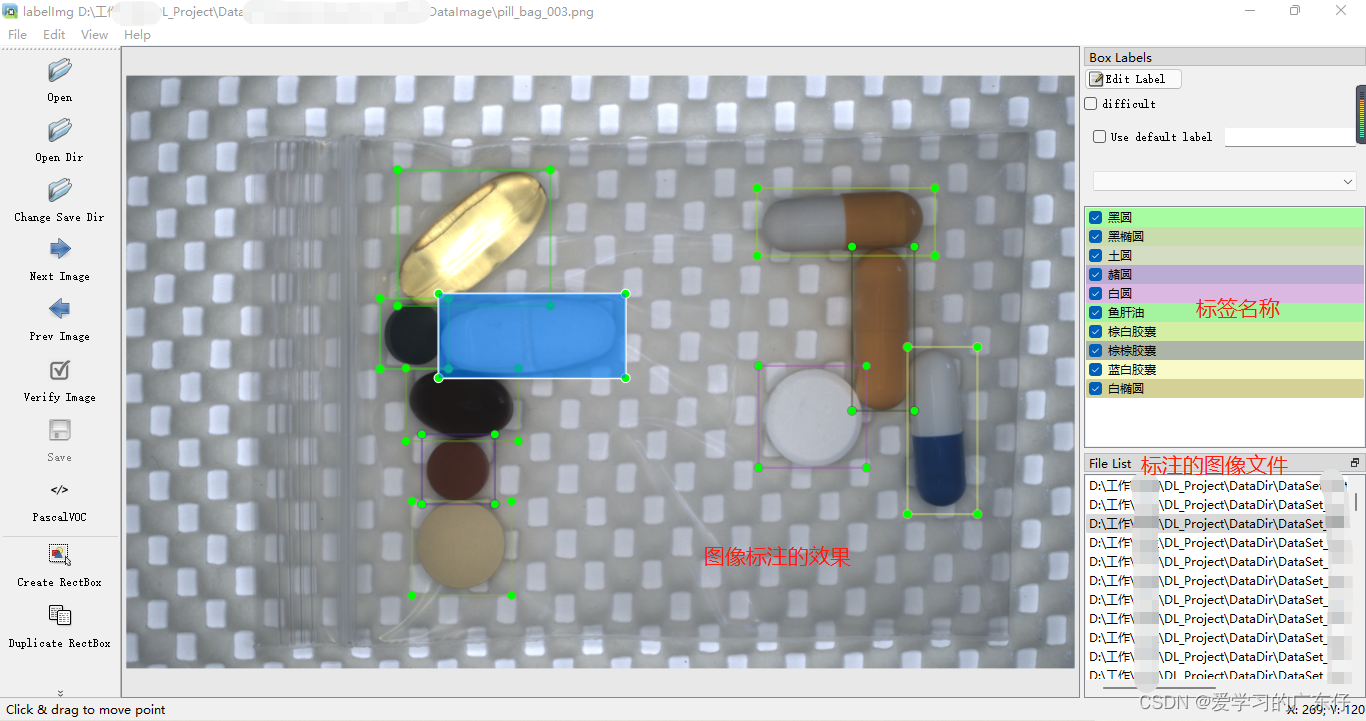
然后先记住快捷键:w:开始编辑,a:上一张,d:下一张。这个工具只需要这三个快捷键即可完成工作。
开始标注工作,首先按下键盘w,这个时候进入编辑框框的模式,然后在图像上绘制框框,输入标签(框框属于什么类别),即可完成物体1的标注,一张物体可以多个标注和多个类别,但是切记不可摸棱两可,比如这张图像对于某物体标注了,另一张图像如果出现同样的就需要标注,或者标签类别不可多个,比如这个图象A物体标注为A标签,下张图的A物体标出成了B标签,最终的效果如图:
最后标注完成会在DataLabel中看到标注文件,json格式:
4.解释xml文件的内容

xml标签文件如图,我们用到的就只有object对象,对其进行解析即可。
二、网络结构的介绍
论文地址:https://arxiv.org/pdf/2004.10934.pdf
网络结构:
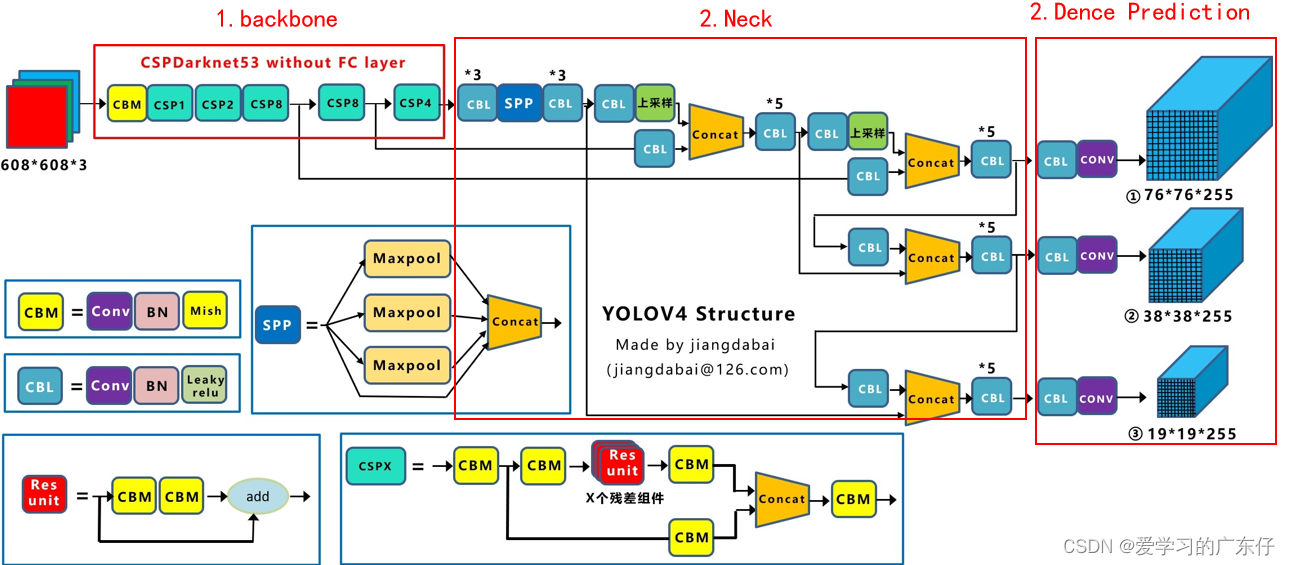
就是说这个YOLO-v4算法是在原有YOLO目标检测架构的基础上,采用了近些年CNN领域中最优秀的优化策略,从数据处理、主干网络、网络训练、激活函数、损失函数等各个方面都有着不同程度的优化,虽没有理论上的创新,但是会受到许许多多的工程师的欢迎,各种优化算法的尝试。文章如同于目标检测的trick综述,效果达到了实现FPS与Precision平衡的目标检测 new baseline。
三、代码实现
0.工程目录结构如下
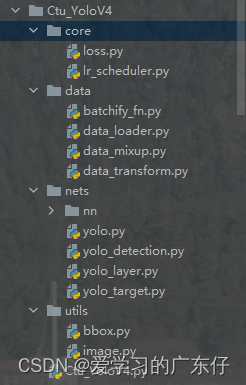
core:损失计算及一些核心计算的文件都存放在此文件夹
data:数据加载的相关函数及类
net:包含主干网络结构及标准的YoloV4结构
utils:数据预处理的相关文件
Ctu_YoloV4.py:YoloV4的训练类和测试类,是整个AI的主入口
1.导入库
import os, time, warnings,json,sys,cv2,colorsys,copy
sys.path.append('.')
import numpy as np
import mxnet as mx
from mxnet import nd
from PIL import Image,ImageFont,ImageDraw
from mxnet import gluon
from mxnet import autograd
from mxnet.contrib import amp
from data.data_loader import VOCDetection, VOC07MApMetric
from data.data_mixup import MixupDetection
from nets.yolo import get_yolov4
from data.batchify_fn import Tuple,Pad,Stack
from data.data_transform import YOLO3DefaultTrainTransform,YOLO3DefaultValTransform,RandomTransformDataLoader
from core.lr_scheduler import LRScheduler,LRSequential
2.配置GPU/CPU环境
self.ctx = [mx.gpu(int(i)) for i in USEGPU.split(',') if i.strip()]
self.ctx = self.ctx if self.ctx else [mx.cpu()]
3.数据加载器
这里输入的是迭代器,后面都会利用它构建训练的迭代器
class VOCDetection(dataset.Dataset):
def CreateDataList(self,IMGDir,XMLDir):
ImgList = os.listdir(IMGDir)
XmlList = os.listdir(XMLDir)
classes = []
dataList=[]
for each_jpg in ImgList:
each_xml = each_jpg.split('.')[0] + '.xml'
if each_xml in XmlList:
dataList.append([os.path.join(IMGDir,each_jpg),os.path.join(XMLDir,each_xml)])
with open(os.path.join(XMLDir,each_xml), "r", encoding="utf-8") as in_file:
tree = ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
classes.append(cls)
return dataList,classes
def __init__(self, ImageDir, XMLDir,transform=None):
self.datalist,self.classes_names = self.CreateDataList(ImageDir,XMLDir)
self._transform = transform
self.index_map = dict(zip(self.classes_names, range(len(self.classes_names))))
# self._label_cache = self._preload_labels()
@property
def classes(self):
return self.classes_names
def __len__(self):
return len(self.datalist)
def __getitem__(self, idx):
img_path = self.datalist[idx][0]
# label = self._label_cache[idx] if self._label_cache else self._load_label(idx)
label = self._load_label(idx)
img = mx.image.imread(img_path, 1)
if self._transform is not None:
return self._transform(img, label)
return img, label.copy()
def _preload_labels(self):
return [self._load_label(idx) for idx in range(len(self))]
def _load_label(self, idx):
anno_path = self.datalist[idx][1]
root = ET.parse(anno_path).getroot()
size = root.find('size')
width = float(size.find('width').text)
height = float(size.find('height').text)
label = []
for obj in root.iter('object'):
try:
difficult = int(obj.find('difficult').text)
except ValueError:
difficult = 0
cls_name = obj.find('name').text.strip().lower()
if cls_name not in self.classes:
continue
cls_id = self.index_map[cls_name]
xml_box = obj.find('bndbox')
xmin = (float(xml_box.find('xmin').text) - 1)
ymin = (float(xml_box.find('ymin').text) - 1)
xmax = (float(xml_box.find('xmax').text) - 1)
ymax = (float(xml_box.find('ymax').text) - 1)
try:
self._validate_label(xmin, ymin, xmax, ymax, width, height)
label.append([xmin, ymin, xmax, ymax, cls_id, difficult])
except AssertionError as e:
pass
return np.array(label)
def _validate_label(self, xmin, ymin, xmax, ymax, width, height):
assert 0 <= xmin < width, "xmin must in [0, {}), given {}".format(width, xmin)
assert 0 <= ymin < height, "ymin must in [0, {}), given {}".format(height, ymin)
assert xmin < xmax <= width, "xmax must in (xmin, {}], given {}".format(width, xmax)
assert ymin < ymax <= height, "ymax must in (ymin, {}], given {}".format(height, ymax)
4.模型构建
本项目使用YoloV4的代码
class YOLOV4(gluon.HybridBlock):
def __init__(self, anchors, strides, classes, alloc_size=(128, 128), nms_thresh=0.45, nms_topk=400, post_nms=100, pos_iou_thresh=1.0, ignore_iou_thresh=0.7, **kwargs):
super(YOLOV4, self).__init__(**kwargs)
self._classes = classes
self.nms_thresh = nms_thresh
self.nms_topk = nms_topk
self.post_nms = post_nms
self._pos_iou_thresh = pos_iou_thresh
self._ignore_iou_thresh = ignore_iou_thresh
if pos_iou_thresh >= 1:
self._target_generator = YOLOV3TargetMerger(len(classes), ignore_iou_thresh)
else:
raise NotImplementedError("pos_iou_thresh({}) < 1.0 is not implemented!".format(pos_iou_thresh))
self._loss = YOLOV3Loss()
with self.name_scope():
# backbone
self.backbone = CSPDDarkNet53()
# Neck
self.Neck = Neck()
self.Outputs = nn.HybridSequential()
# note that anchors and strides should be used in reverse order
for i, anchor, stride in zip(range(3), anchors[::-1], strides[::-1]):
output = YOLO4OutputV3(i, len(classes), anchor, stride, alloc_size=alloc_size)
self.Outputs.add(output)
@property
def num_class(self):
return self._num_class
@property
def classes(self):
return self._classes
def hybrid_forward(self, F, x, *args):
if len(args) != 0 and not autograd.is_training():
raise TypeError('YOLOV4 inference only need one input data.')
all_box_centers = []
all_box_scales = []
all_objectness = []
all_class_pred = []
all_anchors = []
all_offsets = []
all_feat_maps = []
all_detections = []
routes = []
feat0, feat1, feat2 = self.backbone(x)
routes = self.Neck(feat0, feat1, feat2)
for tip, output in zip(routes, self.Outputs):
if autograd.is_training():
dets, box_centers, box_scales, objness, class_pred, anchors, offsets = output(tip)
all_box_centers.append(box_centers.reshape((0, -3, -1)))
all_box_scales.append(box_scales.reshape((0, -3, -1)))
all_objectness.append(objness.reshape((0, -3, -1)))
all_class_pred.append(class_pred.reshape((0, -3, -1)))
all_anchors.append(anchors)
all_offsets.append(offsets)
fake_featmap = F.zeros_like(tip.slice_axis(axis=0, begin=0, end=1).slice_axis(axis=1, begin=0, end=1))
all_feat_maps.append(fake_featmap)
else:
dets = output(tip)
all_detections.append(dets)
if autograd.is_training():
if autograd.is_recording():
box_preds = F.concat(*all_detections, dim=1)
all_preds = [F.concat(*p, dim=1) for p in [
all_objectness, all_box_centers, all_box_scales, all_class_pred]]
all_targets = self._target_generator(box_preds, *args)
return self._loss(*(all_preds + all_targets))
return (F.concat(*all_detections, dim=1), all_anchors, all_offsets, all_feat_maps,
F.concat(*all_box_centers, dim=1), F.concat(*all_box_scales, dim=1),
F.concat(*all_objectness, dim=1), F.concat(*all_class_pred, dim=1))
result = F.concat(*all_detections, dim=1)
if self.nms_thresh > 0 and self.nms_thresh < 1:
result = F.contrib.box_nms(result, overlap_thresh=self.nms_thresh, valid_thresh=0.01, topk=self.nms_topk, id_index=0, score_index=1, coord_start=2, force_suppress=False)
if self.post_nms > 0:
result = result.slice_axis(axis=1, begin=0, end=self.post_nms)
ids = result.slice_axis(axis=-1, begin=0, end=1)
scores = result.slice_axis(axis=-1, begin=1, end=2)
bboxes = result.slice_axis(axis=-1, begin=2, end=None)
return ids, scores, bboxes
def set_nms(self, nms_thresh=0.45, nms_topk=400, post_nms=100):
self._clear_cached_op()
self.nms_thresh = nms_thresh
self.nms_topk = nms_topk
self.post_nms = post_nms
def reset_class(self, classes, reuse_weights=None):
self._clear_cached_op()
old_classes = self._classes
self._classes = classes
if self._pos_iou_thresh >= 1:
self._target_generator = YOLOV3TargetMerger(len(classes), self._ignore_iou_thresh)
if isinstance(reuse_weights, (dict, list)):
if isinstance(reuse_weights, dict):
# trying to replace str with indices
new_keys = []
new_vals = []
for k, v in reuse_weights.items():
if isinstance(v, str):
try:
new_vals.append(old_classes.index(v)) # raise ValueError if not found
except ValueError:
raise ValueError("{} not found in old class names {}".format(v, old_classes))
else:
if v < 0 or v >= len(old_classes):
raise ValueError("Index {} out of bounds for old class names".format(v))
new_vals.append(v)
if isinstance(k, str):
try:
new_keys.append(self.classes.index(k)) # raise ValueError if not found
except ValueError:
raise ValueError("{} not found in new class names {}".format(k, self.classes))
else:
if k < 0 or k >= len(self.classes):
raise ValueError("Index {} out of bounds for new class names".format(k))
new_keys.append(k)
reuse_weights = dict(zip(new_keys, new_vals))
else:
new_map = {}
for x in reuse_weights:
try:
new_idx = self._classes.index(x)
old_idx = old_classes.index(x)
new_map[new_idx] = old_idx
except ValueError:
warnings.warn("{} not found in old: {} or new class names: {}".format(x, old_classes, self._classes))
reuse_weights = new_map
for outputs in self.Outputs:
outputs.reset_class(classes, reuse_weights=reuse_weights)
5.模型训练
1.学习率设置
lr_steps = sorted([int(ls) for ls in lr_decay_epoch.split(',') if ls.strip()])
lr_decay_epoch = [e for e in lr_steps]
lr_scheduler = LRSequential([
LRScheduler('linear', base_lr=0, target_lr=learning_rate,
nepochs=0, iters_per_epoch=self.num_samples // self.batch_size),
LRScheduler(lr_mode, base_lr=learning_rate,
nepochs=TrainNum,
iters_per_epoch=self.num_samples // self.batch_size,
step_epoch=lr_decay_epoch,
step_factor=lr_decay, power=2),
])
2.优化器设置
if optim == 1:
trainer = gluon.Trainer(self.model.collect_params(), 'sgd', {'learning_rate': learning_rate, 'wd': 0.0005, 'momentum': 0.9, 'lr_scheduler': lr_scheduler})
elif optim == 2:
trainer = gluon.Trainer(self.model.collect_params(), 'adagrad', {'learning_rate': learning_rate, 'lr_scheduler': lr_scheduler})
else:
trainer = gluon.Trainer(self.model.collect_params(), 'adam', {'learning_rate': learning_rate, 'lr_scheduler': lr_scheduler})
3.损失设置
obj_metrics = mx.metric.Loss('ObjLoss')
center_metrics = mx.metric.Loss('BoxCenterLoss')
scale_metrics = mx.metric.Loss('BoxScaleLoss')
cls_metrics = mx.metric.Loss('ClassLoss')
4.循环训练
for i, batch in enumerate(self.train_loader):
data = gluon.utils.split_and_load(batch[0], ctx_list=self.ctx, batch_axis=0)
# objectness, center_targets, scale_targets, weights, class_targets
fixed_targets = [gluon.utils.split_and_load(batch[it], ctx_list=self.ctx, batch_axis=0) for it in range(1, 6)]
gt_boxes = gluon.utils.split_and_load(batch[6], ctx_list=self.ctx, batch_axis=0)
sum_losses = []
obj_losses = []
center_losses = []
scale_losses = []
cls_losses = []
with autograd.record():
for ix, x in enumerate(data):
obj_loss, center_loss, scale_loss, cls_loss = self.model(x, gt_boxes[ix], *[ft[ix] for ft in fixed_targets])
sum_losses.append(obj_loss + center_loss + scale_loss + cls_loss)
obj_losses.append(obj_loss)
center_losses.append(center_loss)
scale_losses.append(scale_loss)
cls_losses.append(cls_loss)
if self.ampFlag:
with amp.scale_loss(sum_losses, trainer) as scaled_loss:
autograd.backward(scaled_loss)
else:
autograd.backward(sum_losses)
trainer.step(self.batch_size)
obj_metrics.update(0, obj_losses)
center_metrics.update(0, center_losses)
scale_metrics.update(0, scale_losses)
cls_metrics.update(0, cls_losses)
name1, loss1 = obj_metrics.get()
name2, loss2 = center_metrics.get()
name3, loss3 = scale_metrics.get()
name4, loss4 = cls_metrics.get()
print('[Epoch {}][Batch {}], LR: {:.2E}, Speed: {:.3f} samples/sec, {}={:.3f}, {}={:.3f}, {}={:.3f}, {}={:.3f}'.format(epoch, i, trainer.learning_rate, self.batch_size/(time.time()-btic), name1, loss1, name2, loss2, name3, loss3, name4, loss4))
btic = time.time()
6.模型预测
def predict(self,image,confidence=0.5, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
start_time = time.time()
origin_img = copy.deepcopy(image)
base_imageSize = origin_img.shape
image = cv2.cvtColor(image,cv2.COLOR_RGB2BGR)
image = cv2.resize(image,(self.image_size,self.image_size))
img = nd.array(image)
img = mx.nd.image.to_tensor(img)
img = mx.nd.image.normalize(img, mean=mean, std=std)
x = img.expand_dims(0)
x = x.as_in_context(self.ctx[0])
labels, scores, bboxes = [xx[0].asnumpy() for xx in self.model(x)]
origin_img_pillow = self.cv2_pillow(origin_img)
font = ImageFont.truetype(font='./model_data/simhei.ttf', size=np.floor(3e-2 * np.shape(origin_img_pillow)[1] + 0.5).astype('int32'))
thickness = max((np.shape(origin_img_pillow)[0] + np.shape(origin_img_pillow)[1]) // self.image_size, 1)
imgbox = []
for i, bbox in enumerate(bboxes):
if (scores is not None and scores.flat[i] < confidence) or labels is not None and labels.flat[i] < 0:
continue
cls_id = int(labels.flat[i]) if labels is not None else -1
xmin, ymin, xmax, ymax = [int(x) for x in bbox]
xmin = int(xmin / self.image_size * base_imageSize[1])
xmax = int(xmax / self.image_size * base_imageSize[1])
ymin = int(ymin / self.image_size * base_imageSize[0])
ymax = int(ymax / self.image_size * base_imageSize[0])
# print(xmin, ymin, xmax, ymax, self.classes_names[cls_id])
class_name = self.classes_names[cls_id]
score = '{:d}%'.format(int(scores.flat[i] * 100)) if scores is not None else ''
imgbox.append([(xmin, ymin, xmax, ymax), cls_id, self.classes_names[cls_id], score])
top, left, bottom, right = ymin, xmin, ymax, xmax
label = '{}-{}'.format(class_name, score)
draw = ImageDraw.Draw(origin_img_pillow)
label_size = draw.textsize(label, font)
label = label.encode('utf-8')
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
for i in range(thickness):
draw.rectangle([left + i, top + i, right - i, bottom - i], outline=self.colors[cls_id])
draw.rectangle([tuple(text_origin), tuple(text_origin + label_size)], fill=self.colors[cls_id])
draw.text(text_origin, str(label,'UTF-8'), fill=(0, 0, 0), font=font)
del draw
result_value = {
"image_result": self.pillow_cv2(origin_img_pillow),
"bbox": imgbox,
"time": (time.time() - start_time) * 1000
}
return result_value
四、算法主入口
if __name__ == '__main__':
# ctu = Ctu_YoloV4(USEGPU='0',image_size=300,ampFlag = False,mixup=False)
# ctu.InitModel(DataDir=r'D:/Ctu/Ctu_Project_DL/DataSet/DataSet_Detection_YaoPian',batch_size=1,num_workers=0,Pre_Model = None,label_smooth=True)
# ctu.train(TrainNum=150,learning_rate=0.0001,lr_decay_epoch='50,100,150,200',lr_decay = 0.9,ModelPath='./Model',optim=0,lr_mode='step')
ctu = Ctu_YoloV4(USEGPU='0')
ctu.LoadModel(r'./Model_yoloV4')
cv2.namedWindow("result", 0)
cv2.resizeWindow("result", 640, 480)
index = 0
for root, dirs, files in os.walk(r'D:/Ctu/Ctu_Project_DL/DataSet/DataSet_Detection_YaoPian/DataImage'):
for f in files:
img_cv = ctu.read_image(os.path.join(root, f))
if img_cv is None:
continue
res = ctu.predict(img_cv, 0.7)
for each in res['bbox']:
print(each)
print("耗时:" + str(res['time']) + ' ms')
# cv2.imwrite(str(index + 1)+'.bmp',res['image_result'])
cv2.imshow("result", res['image_result'])
cv2.waitKey()
# index +=1
五、训练效果展示
备注:项目模型的本人没有保存因此会后续提供训练效果


















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











