






总体流程
数据收集(开源or自建)→模型训练→发布验证
数据收集
开源数据集
可以使用开源的数据集,例如:
甄嬛台词项目链接:GitHub - KMnO4-zx/huanhuan-chat![]() https://github.com/KMnO4-zx/huanhuan-chat
https://github.com/KMnO4-zx/huanhuan-chat
自建数据集
也可使用Alpaca格式进行构建
-
instruction列对应的内容会与input列对应的内容拼接后作为模型输入,即为instruction\input。
-
output列对应的内容为模型回答。
-
如果指定,system列对应的内容将被作为系统提示词。
-
history列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]Alpaca格式数据具体示例如下:
{
"instruction": "描述一个可以从人工智能技术中受益的医疗应用。",
"input": "",
"output": "用于帮助医生诊断疾病的人工智能辅助诊断系统可以被视为一个可以从人工智能技术中受益的医疗应用。这种系统通过使用深度学习算法来分析患者的病史、临床数据和医学影像资料,能够为医生提供准确的诊断建议。\n\n例如,人工智能技术可以用来分析X光片、 CT扫描和MRI扫描图像,帮助医生诊断肺炎,肿瘤,中风等疾病。此外,通过分析大量患者数据,人工智能系统能够找出患病风险较高的人群并预测潜在健康问题,从而为预防性医疗提供有力支持。\n\n这类人工智能系统不仅能够提高诊断准确性,还能帮助医生节约时间,让他们能够更好地关注患者的治疗。因此,人工智能辅助诊断系统是一个可以从人工智能技术中受益的医疗应用,具有广阔的发展前景。",
"system": "",
"history": ""
}构建流程
1. 准备原始数据:书籍、剧本等
2. 进行文本筛选和分块
3. 提取问答对
举例流程
第一步:将一本专业领域书籍进行分节。
- 首先获得文字版pdf,然后转成Word
- 使用替换功能,将每节标题改为`title:XXX`格式
- 编写代码,获得每节title:content内容
def process_text_file(file_path: str) -> dict:
"""
处理包含多个以'title:'开头的条目的文本文件。
每个条目从'title:'开始,到下一个'title:'(或文件结束)为止。
Args:
file_path: 文本文件的路径
Returns:
一个字典,其中键是标题,值是对应的内容文本
"""
content_dict = {}
current_title = None
current_content = []
# 读取文件内容
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
# 处理每一行
for line in lines:
# 检查是否是新的标题行
if line.startswith('title:'):
# 如果已经有之前的标题和内容,保存它们
if current_title:
content_dict[current_title] = ''.join(current_content).strip()
current_content = [] # 重置内容列表
# 提取新标题(去除'title:'前缀和空白字符)
current_title = line[6:].strip()
else:
# 如果不是标题行且已有当前标题,将该行添加到当前内容
if current_title:
current_content.append(line)
# 保存最后一个条目
if current_title and current_content:
content_dict[current_title] = ''.join(current_content).strip()
return content_dict
# 使用示例
import json
# 处理文件
file_path = 'test.txt' # 替换为你的文件路径
result = process_text_file(file_path)
# 保存为JSON文件
output_path = 'processed_content.json'
with open(output_path, 'w', encoding='utf-8') as f:
json.dump(result, f, ensure_ascii=False, indent=2)
# 打印处理结果的统计信息
print(f"处理完成!共提取了 {len(result)} 个条目")
for title in result.keys():
content_length = len(result[title])
print(f"- 标题:{title}")
print(f" 内容长度:{content_length} 字符")json输出如下
{
"保守主义(Conservatism)": "保守主义是当代世界三⼤主流意识形态之⼀ 。……”",
}
第二步:对长文本进行分块。
- 书籍每一节长度太长,所以需要对文本进行切分
- 因为pdf转的文本有许多不规则的换行符,所以采用 句号+换行符 的格式进行文本切分。
import json
import logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
def clean_and_split_content(text):
"""
这个函数执行以下任务:
1. 识别并保留句号后的换行符作为切分点
2. 替换掉其他所有的换行符
3. 过滤掉长度小于10个字符的文本片段
处理步骤:
- 首先将文本按句号分割,保留句号
- 检查每个句子后是否跟着换行符
- 清理其他位置的换行符
- 检查处理后的文本片段长度
- 只保留长度大于等于10的文本片段
"""
sentences = text.split('。')
processed_chunks = []
current_chunk = ""
for i, sentence in enumerate(sentences):
if sentence: # 确保不是空句子
# 移除句子中的所有换行符,替换为空格
cleaned_sentence = ' '.join(sentence.split())
# 检查原始句子后是否有换行符
original_end = text.find('。', text.find(sentence))
if original_end != -1 and original_end + 1 < len(text):
has_newline = text[original_end + 1] == '\n'
else:
has_newline = False
# 根据是否有换行符决定是否开始新的chunk
if has_newline:
current_chunk += cleaned_sentence + '。\n'
# 检查当前chunk的长度是否达到最小要求
if current_chunk.strip() and len(current_chunk.strip()) >= 10:
processed_chunks.append(current_chunk.strip())
current_chunk = ""
else:
current_chunk += cleaned_sentence + '。'
# 处理最后可能剩余的文本
if current_chunk.strip() and len(current_chunk.strip()) >= 10:
processed_chunks.append(current_chunk.strip())
return processed_chunks
def process_json_file(input_path, output_path):
"""
处理JSON文件,对每个值进行清理和切分。
保存处理记录,包括:
- 原始内容
- 符合长度要求的处理后片段
- 处理的统计信息
"""
logging.info(f"开始处理文件: {input_path}")
try:
# 读取输入文件
with open(input_path, 'r', encoding='utf-8') as f:
data = json.load(f)
processed_data = {}
# 处理每个条目
for key, content in data.items():
logging.info(f"正在处理关键词: {key}")
chunks = clean_and_split_content(content)
# 只有当有符合长度要求的片段时才添加到结果中
if chunks:
processed_data[key] = {
"original": content,
"chunks": chunks,
"chunk_count": len(chunks),
"average_chunk_length": sum(len(chunk) for chunk in chunks) / len(chunks)
}
logging.info(f"完成 {key} 的处理: 生成了 {len(chunks)} 个有效片段")
else:
logging.warning(f"关键词 {key} 没有生成任何符合长度要求的片段")
# 保存处理结果
with open(output_path, 'w', encoding='utf-8') as f:
json.dump(processed_data, f, ensure_ascii=False, indent=2)
logging.info(f"所有处理完成,结果已保存到: {output_path}")
except Exception as e:
logging.error(f"处理过程中发生错误: {str(e)}")
raise
if __name__ == "__main__":
input_file = "processed_content.json"
output_file = "cleaned_split_content.json"
process_json_file(input_file, output_file)json输出如下
{
"保守主义(Conservatism)": {
"original":……,
"chunks": [
"保守主义是当代世界三⼤主流意识形态之⼀。保守是⼈对变故 时的⼀种基本的⼼理倾向和态度 ,即对可能打乱习以为常的⽣活和⼯ 作⽅式的变动保持审慎 ,反对或抵制突如其来的变化。保守的倾向和 ⼼理⻓期、⼴泛地存在于⼈类社会 ,保守主义则是诞⽣于近代的政治 思潮 ,是对现代性挑战的⼀种回应 ,它反对激进的变⾰ ,重视秩序和 传统 ,提倡调和、平衡和节制。保守主义常常被视为右翼思想 ,但它 并不囊括所有的右翼思想。同时 ,保守主义与政治⽣活中的右派—— 保守派并没有必然的对应关系 ,保守派多是守旧派 ,保守主义者的⽬ 光则更多地注视着前⽅。",
……
],
"chunk_count": 8,
"average_chunk_length": 516.375
},
……
}第三步:构建alpaca格式数据集
调用免费的智谱glm-4-flash模型,并及时记录错误信息
import json
import logging
import time
import os
from typing import List, Dict, Optional, Union
from zhipuai import ZhipuAI
def setup_logging():
"""
配置双重日志系统:控制台输出和错误文件记录
"""
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# 创建logs目录
os.makedirs('logs', exist_ok=True)
# 控制台处理器
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
console_formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
console_handler.setFormatter(console_formatter)
# 错误日志文件处理器
error_handler = logging.FileHandler('logs/error.log', encoding='utf-8')
error_handler.setLevel(logging.ERROR)
error_formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s\n详细信息:%(exc_info)s')
error_handler.setFormatter(error_formatter)
logger.addHandler(console_handler)
logger.addHandler(error_handler)
class TextSummarizer:
"""
文本总结器,负责生成总结并保存相关文件
"""
def __init__(self, api_key: str, model: str = "glm-4"):
"""
初始化总结器
Args:
api_key: 智谱AI的API密钥
model: 使用的模型名称
"""
self.client = ZhipuAI(api_key=api_key)
self.model = model
self.summaries_dir = "summaries"
os.makedirs(self.summaries_dir, exist_ok=True)
logging.info(f"初始化TextSummarizer完成,使用模型: {model}")
def create_summary(self, text: str, key: str, max_retries: int = 3) -> Optional[str]:
"""
使用智谱AI为文本生成总结
Args:
text: 需要总结的文本内容
key: 关键词/主题
max_retries: 最大重试次数
"""
retry_count = 0
while retry_count < max_retries:
try:
prompt = f"请针对以下与'{key}'相关的内容进行简明扼要的总结,用一句话概括其核心观点:"
response = self.client.chat.completions.create(
model=self.model,
messages=[
{
"role": "system",
"content": "你是一位平易近人的文化研究教授,请用一句简单易懂的话总结文本的核心内容。"
},
{
"role": "user",
"content": f"{prompt}\n\n{text}"
}
],
temperature=0.7,
top_p=0.7,
max_tokens=1024,
stream=False
)
if hasattr(response, 'choices') and len(response.choices) > 0:
summary = response.choices[0].message.content
logging.info(f"成功生成总结: {summary}")
return summary.strip()
except Exception as e:
retry_count += 1
logging.error(f"生成总结时发生错误: {str(e)}", exc_info=True)
if retry_count < max_retries:
time.sleep(2 * retry_count)
continue
return None
def save_summary_and_text(self, summary: str, text: str, key: str, index: int) -> str:
"""
将总结和原文保存到txt文件
Args:
summary: 生成的总结
text: 原始文本
key: 关键词/主题
index: 文本块索引
"""
safe_key = "".join(c for c in key if c.isalnum() or c in (' ', '-', '_')).strip()
filename = f"{safe_key}_chunk_{index}.txt"
filepath = os.path.join(self.summaries_dir, filename)
try:
with open(filepath, 'w', encoding='utf-8') as f:
f.write(f"总结:\n{summary}\n\n原文:\n{text}")
logging.info(f"已保存文件: {filepath}")
return filepath
except Exception as e:
logging.error(f"保存文件时发生错误: {str(e)}", exc_info=True)
return ""
class AlpacaFormatter:
"""
负责将处理结果转换为Alpaca格式
"""
@staticmethod
def convert_to_alpaca(data: Dict[str, Dict]) -> List[Dict]:
"""
将数据转换为Alpaca训练格式
Args:
data: 原始数据字典
"""
alpaca_data = []
for key, content in data.items():
if "processed_chunks" in content:
for item in content["processed_chunks"]:
alpaca_entry = {
"instruction": item["summary"],
"input": "",
"output": item["original"],
"metadata": {
"key": key,
"file_path": item.get("file_path", ""),
"length": item.get("length", 0)
}
}
alpaca_data.append(alpaca_entry)
return alpaca_data
def process_content(input_file: str, output_file: str, summarizer: TextSummarizer):
"""
主处理函数,读取JSON文件并生成总结
Args:
input_file: 输入JSON文件路径
output_file: 输出JSON文件路径
summarizer: TextSummarizer实例
"""
try:
# 读取输入文件
with open(input_file, 'r', encoding='utf-8') as f:
data = json.load(f)
processed_data = {}
# 处理每个关键词的内容
for key, content in data.items():
logging.info(f"正在处理关键词: {key}")
chunks = content.get("chunks", [])
results = []
for i, chunk in enumerate(chunks, 1):
logging.info(f"正在处理 {key} 的第 {i}/{len(chunks)} 个文本块")
# 生成总结
summary = summarizer.create_summary(chunk, key)
if summary:
# 保存到文件
file_path = summarizer.save_summary_and_text(summary, chunk, key, i)
results.append({
"original": chunk,
"summary": summary,
"length": len(chunk),
"file_path": file_path
})
time.sleep(1) # 避免API限制
# 保存处理结果
processed_data[key] = {
"original": content.get("original", ""),
"processed_chunks": results,
"metadata": {
"chunk_count": len(results),
"total_length": sum(len(chunk) for chunk in chunks)
}
}
# 保存中间结果
with open(f"{output_file}.temp", 'w', encoding='utf-8') as f:
json.dump(processed_data, f, ensure_ascii=False, indent=2)
# 转换为Alpaca格式
alpaca_data = AlpacaFormatter.convert_to_alpaca(processed_data)
# 保存最终结果
alpaca_output = output_file.replace('.json', '_alpaca.json')
with open(alpaca_output, 'w', encoding='utf-8') as f:
json.dump(alpaca_data, f, ensure_ascii=False, indent=2)
logging.info(f"处理完成,结果已保存至: {alpaca_output}")
except Exception as e:
logging.error(f"处理文件时发生错误: {str(e)}", exc_info=True)
raise
def main():
"""
主函数,配置并启动处理流程
"""
# 设置日志系统
setup_logging()
# 配置参数
API_KEY = "your_key"
MODEL = "glm-4-flash"
INPUT_FILE = "cleaned_split_content.json"
OUTPUT_FILE = "output.json"
try:
summarizer = TextSummarizer(API_KEY, MODEL)
process_content(INPUT_FILE, OUTPUT_FILE, summarizer)
except Exception as e:
logging.error(f"程序执行出错: {str(e)}", exc_info=True)
raise
if __name__ == "__main__":
main()生成效果
[
{
"instruction": "保守主义强调维护传统秩序,反对激进变革,主张审慎应对变化,追求平衡与节制。",
"input": "",
"output": "保守主义是当代世界三⼤主流意识形态之⼀。保守是⼈⾯对变故 时的⼀种基本的⼼理倾向和态度 ,即对可能打乱习以为常的⽣活和⼯ 作⽅式的变动保持审慎 ,反对或抵制突如其来的变化。保守的倾向和 ⼼理⻓期、⼴泛地存在于⼈类社会 ,保守主义则是诞⽣于近代的政治 思潮 ,是对现代性挑战的⼀种回应 ,它反对激进的变⾰ ,重视秩序和 传统 ,提倡调和、平衡和节制。保守主义常常被视为右翼思想 ,但它 并不囊括所有的右翼思想。同时 ,保守主义与政治⽣活中的右派—— 保守派并没有必然的对应关系 ,保守派多是守旧派 ,保守主义者的⽬ 光则更多地注视着前⽅。",
"metadata": {
"key": "保守主义(Conservatism)",
"file_path": "summaries\\保守主义Conservatism_chunk_1.txt",
"length": 268
}
},……
]maas平台数据增强
-
利用两到三条数据作为 example 丢给LLM,让其生成风格类似的数据。
-
也可以找一部分日常对话的数据集,使用 RAG 生成一些固定角色风格的对话数据。
以大模型生成文本总结为例:
总结下面的内容。用一句不超过50字的话总结这段小说的情节。仅回答总结,不需要添加其他内容。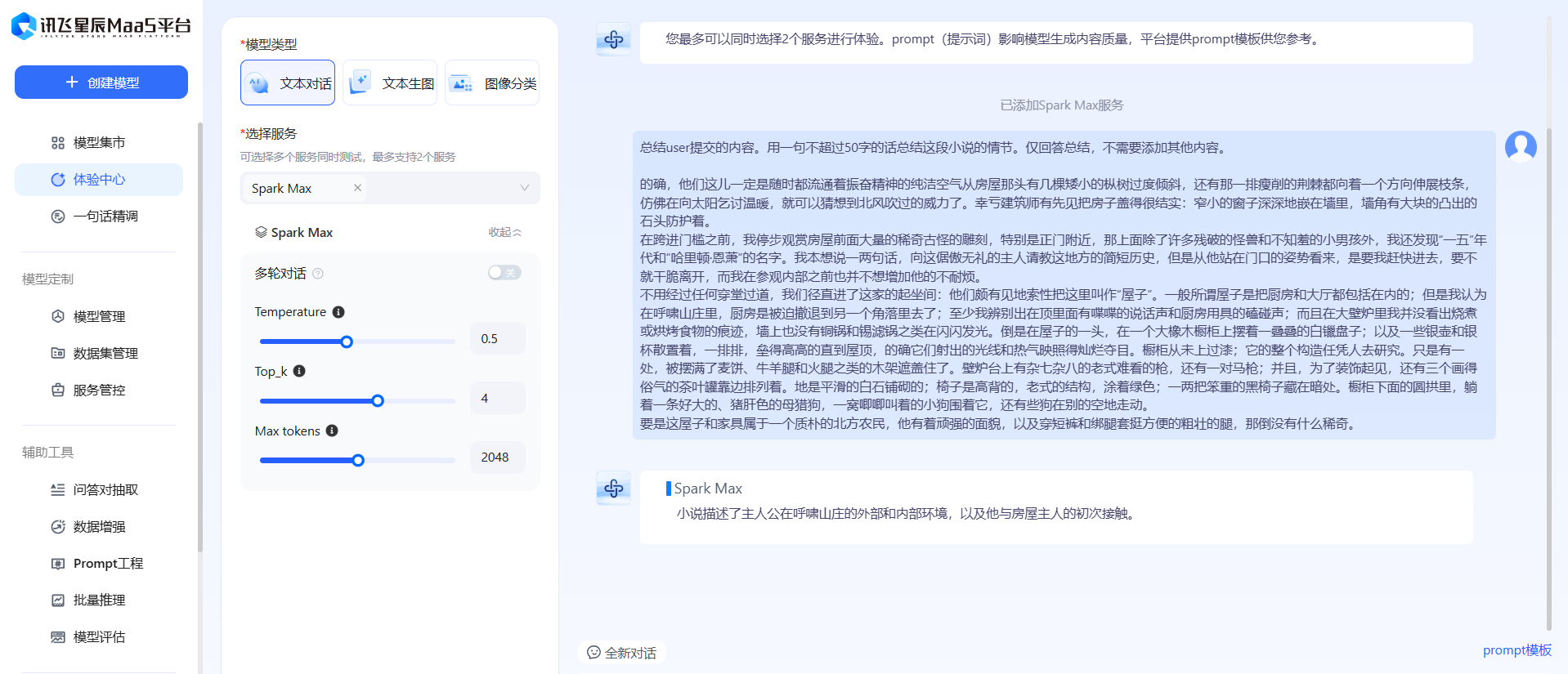
这里可以进行 数据增强 ,优化Prompt。
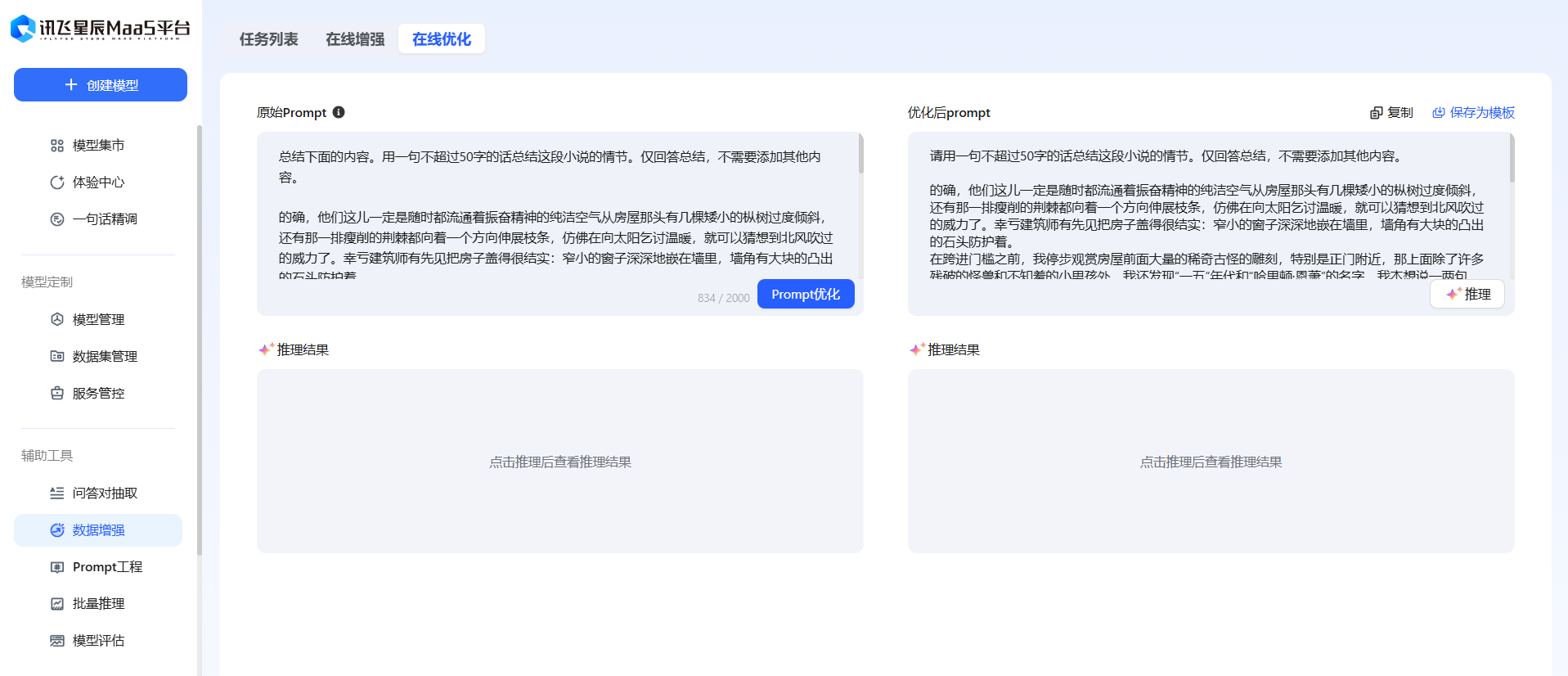
然后点击 推理 ,查看Prompt优化前后的的效果。
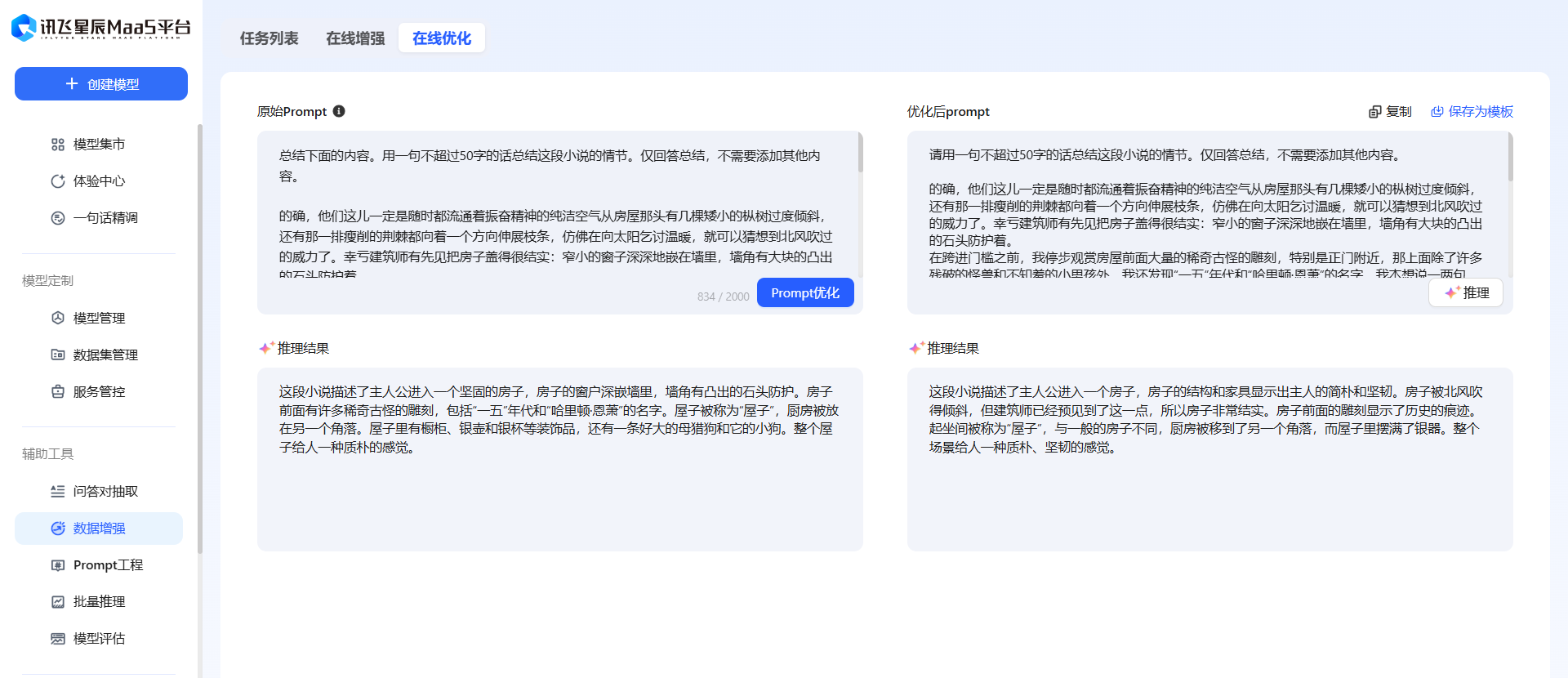
这个过程可以重复多次,直到符合预期。
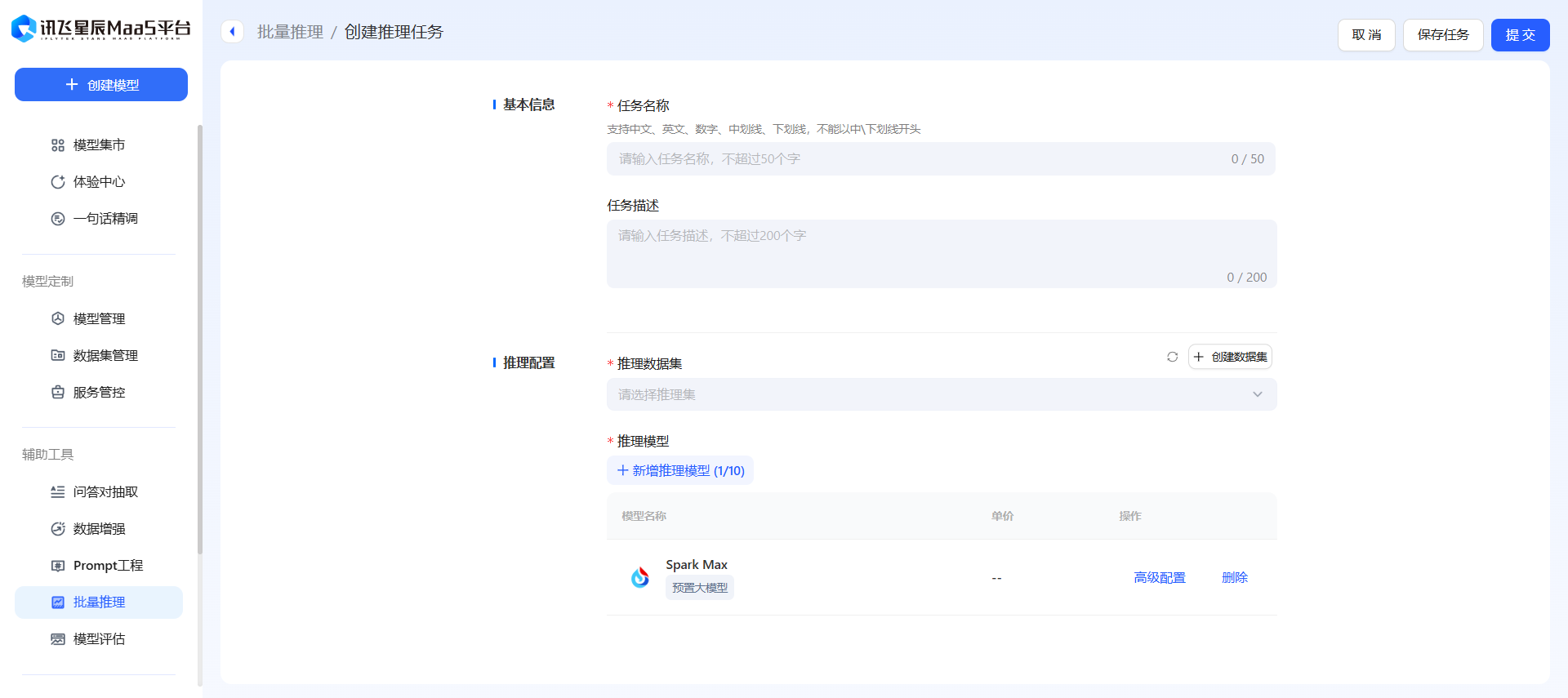
最后,通过 批量推理 ,获取训练集。
模型训练
创建模型→配置训练参数
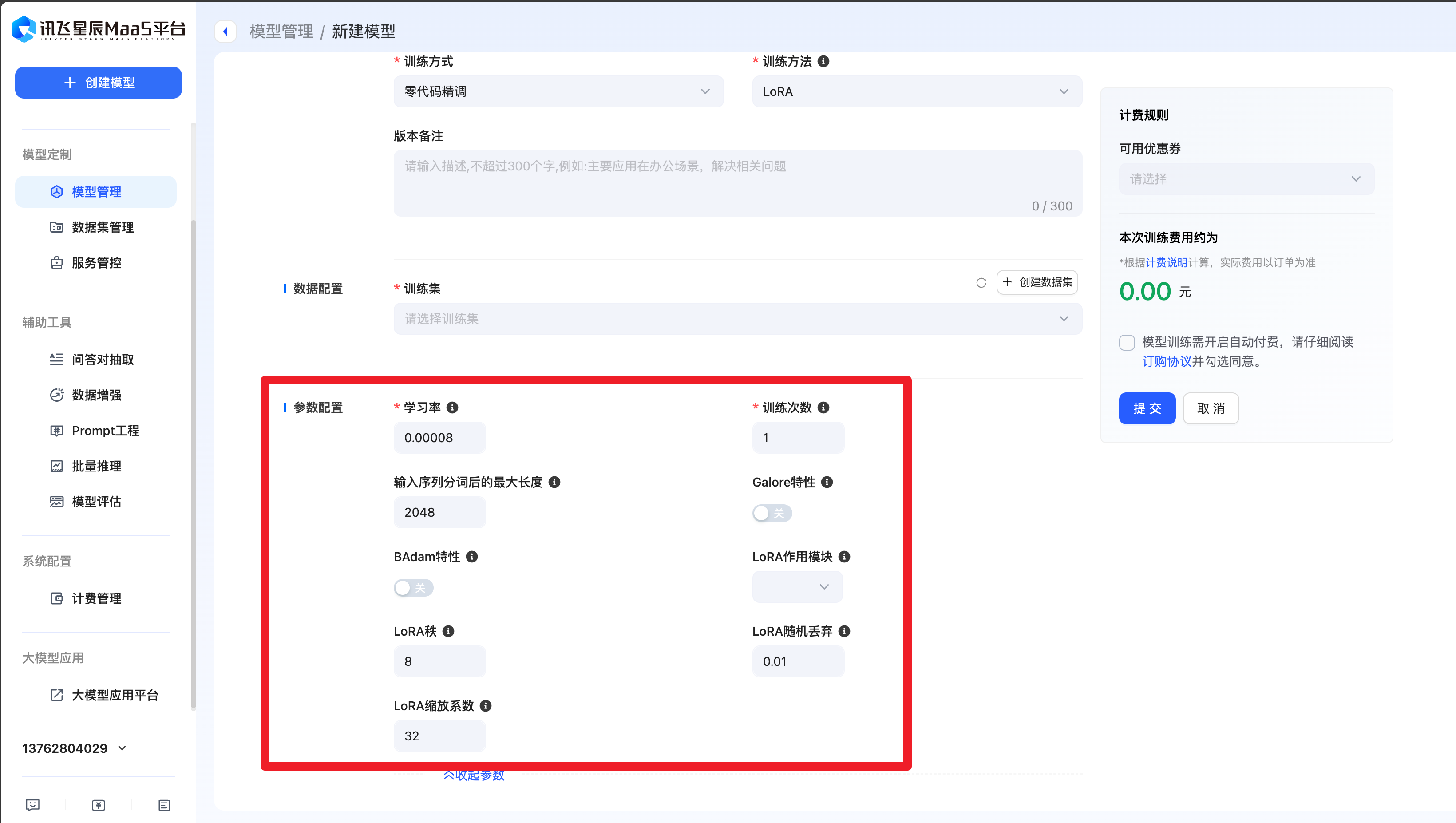
在讯飞星辰MaaS平台,可支持配置的微调参数可以分成下面三个大类。

发布和验证
模型训练完成后,可以将 模型发布为服务 ,使用简单数据进行效果验证。

创建应用
链接:控制台-讯飞开放平台![]() https://console.xfyun.cn/app/myapp
https://console.xfyun.cn/app/myapp
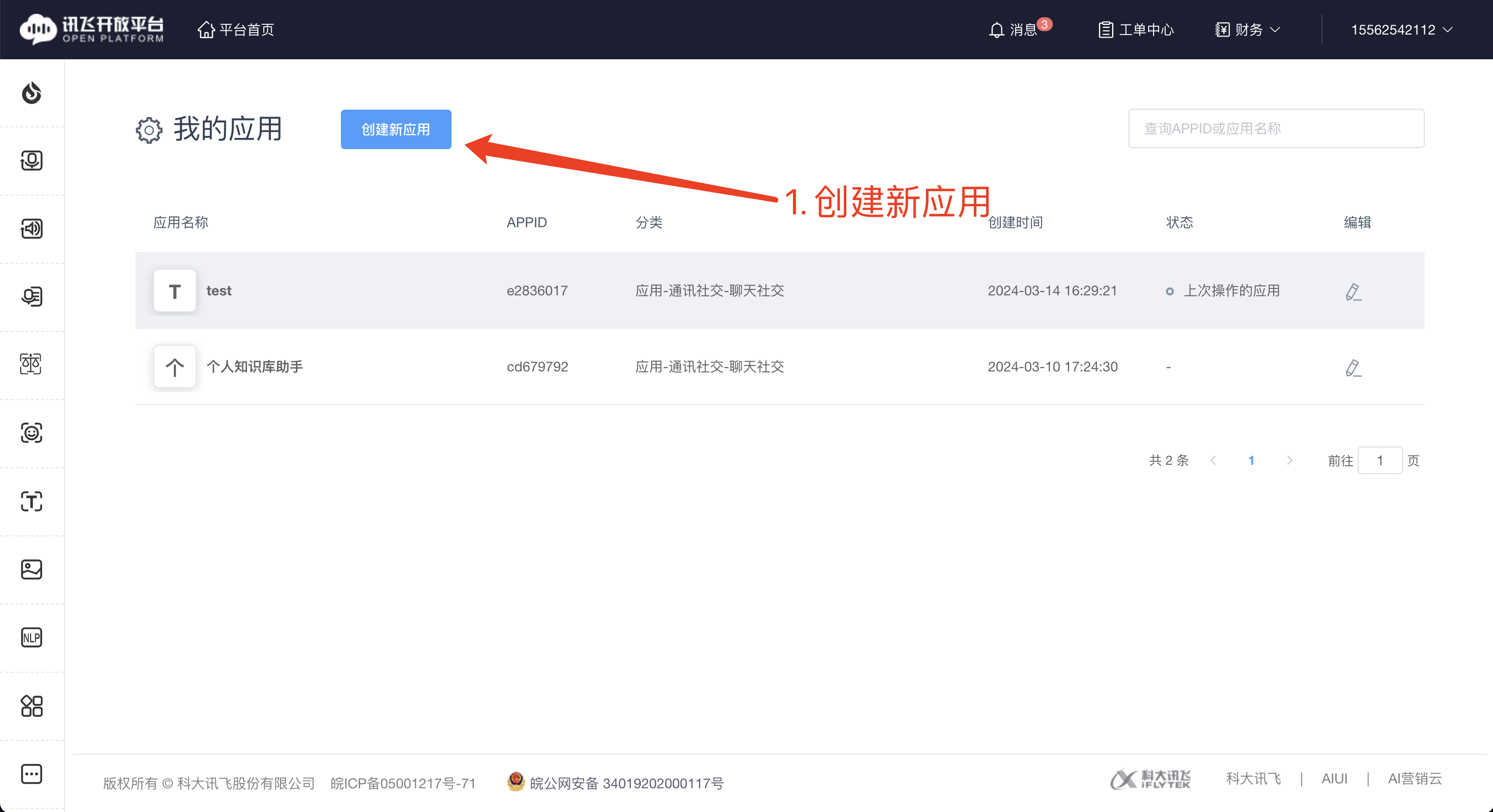
1. 点击【创建新应用】
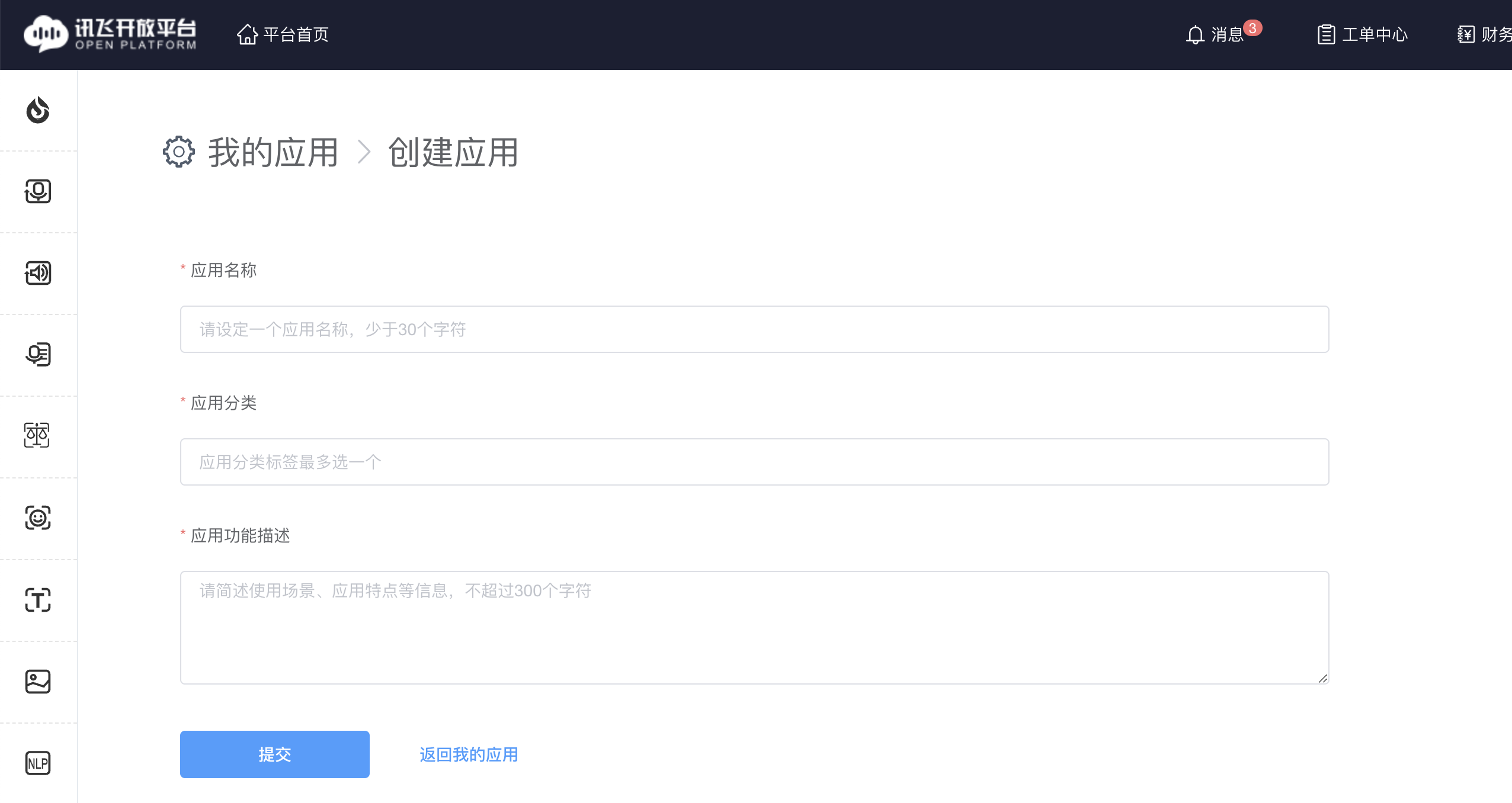
2. 按需填写内容即可
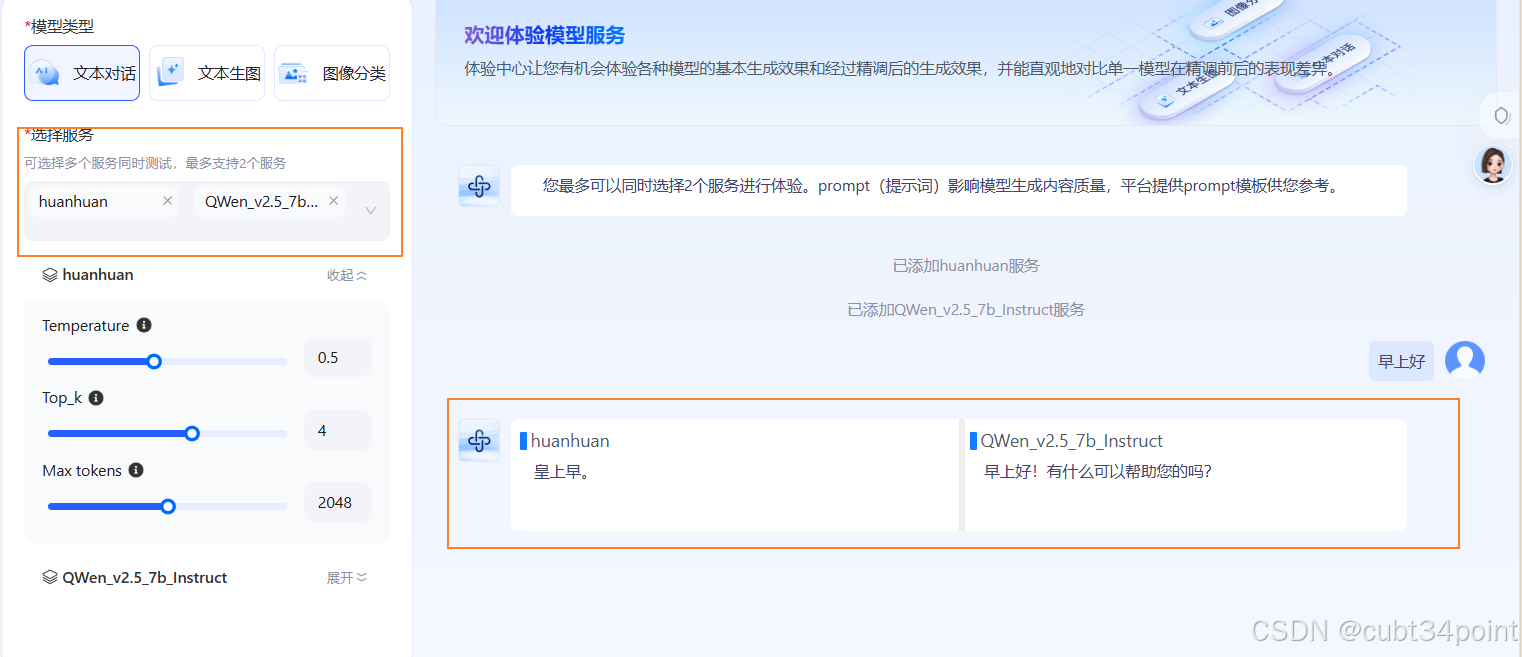
选择两个模型进行效果对比

















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









