






随着AI大模型的迅猛发展,在使用各大企业竞相推出基础通用大模型时,我们往往面临大模型“行行皆通而不精”的问题,在一些特殊语境下无法给出专业化、精准化的落实解决方案。尤其是在角色扮演、模拟特定人物聊天语气等场合。
于是各种经过特殊训练的“智能体”(常见如豆包或通义千问中的各种“问题专家”),即对应定制专属大模型。我们期待通过投喂特定语料改造大模型,使之训练为专业领域中有更加出色的表现!
本篇笔记将基于《甄嬛传》剧本中的甄嬛台词 ,通过五个简单的步骤,不写一行代码,打造一个模仿甄嬛语气、风格的专属聊天模型—— Chat-嬛嬛聊天体 。
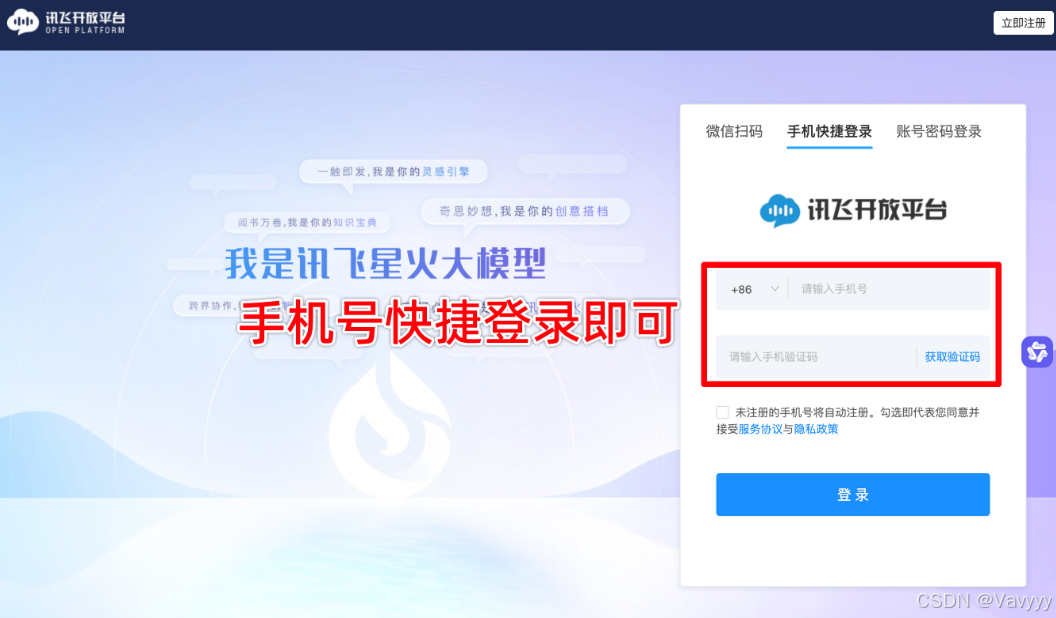
Step1:平台获取——注册讯飞星辰Maas
链接:星火大模型精调平台(点击即可)
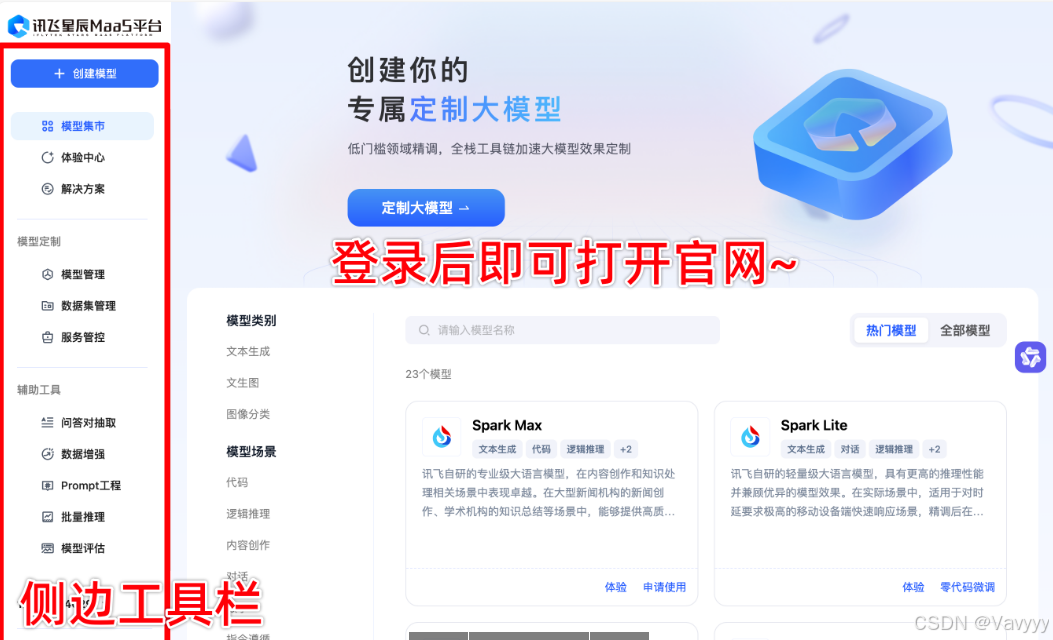
Step2:下载 嬛嬛数据集
数据来源:self-llm/dataset/huanhuan.json at master · datawhalechina/self-llm · GitHub
下载官方提供的嬛嬛语料数据集即可~
Tip1:什么是数据集?
“微调的数据集是大模型的关键。”
真正复杂的工作都在清洗数据、处理、生成、归类数据上,这才是影响大模型的关键节点难点。——散步,Tianji作者
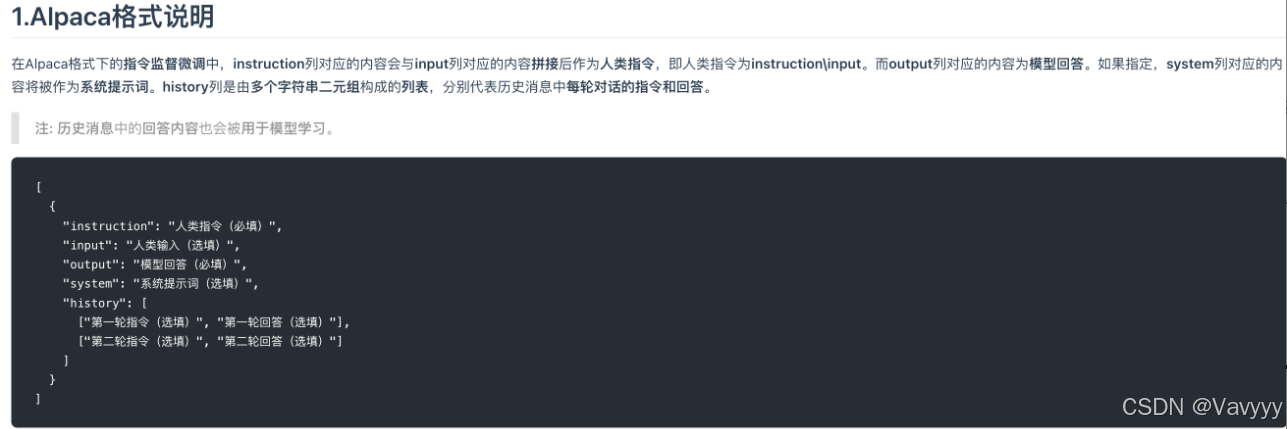
常见微调数据集以Alpaca格式展开,更加适合解决单轮、以任务为导向的指令微调任务。
接下来节选嬛嬛语料包中的部分片段为例:
{ "instruction": "小姐,别的秀女都在求中选,唯有咱们小姐想被撂牌子,菩萨一定记得真真儿的——", "input": "", "output": "嘘——都说许愿说破是不灵的。" }1. instruction:
任务的指令,模型需要完成的具体操作,一般可以对应到用户输入的 Prompt ;
2. input:
任务所需的输入内容。若任务是开放式的,或者不需要明确输入,可以为空字符串;
(这里对于空字符串的处理实际上对于后面聊天体微调效果不明显有影响)
3. output:
在给定指令和输入的情况下,模型需要生成的期望输出,也就是对应的正确结果或参考答案。(即训练的数据,给大模型投喂“参考答案”)
此外我们可以看到还有system与history两个选项对应系统与历史会话作用优化微调模型。
显然像Alpaca格式这样较为线性逻辑叙事的结构更利于我们与模型去理解,处理。明确地把任务指令与输入prompt分开,适用于自然语言处理任务(如文本生成、总结等)
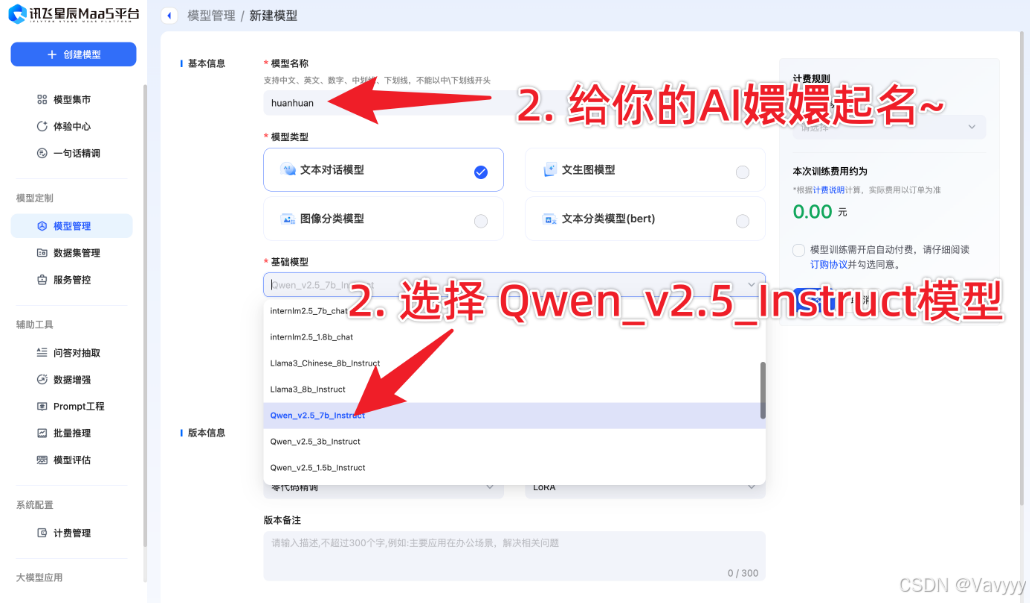
Step3:定制专属嬛嬛大模型!
在讯飞星辰平台上,按照如下步骤操作即可:

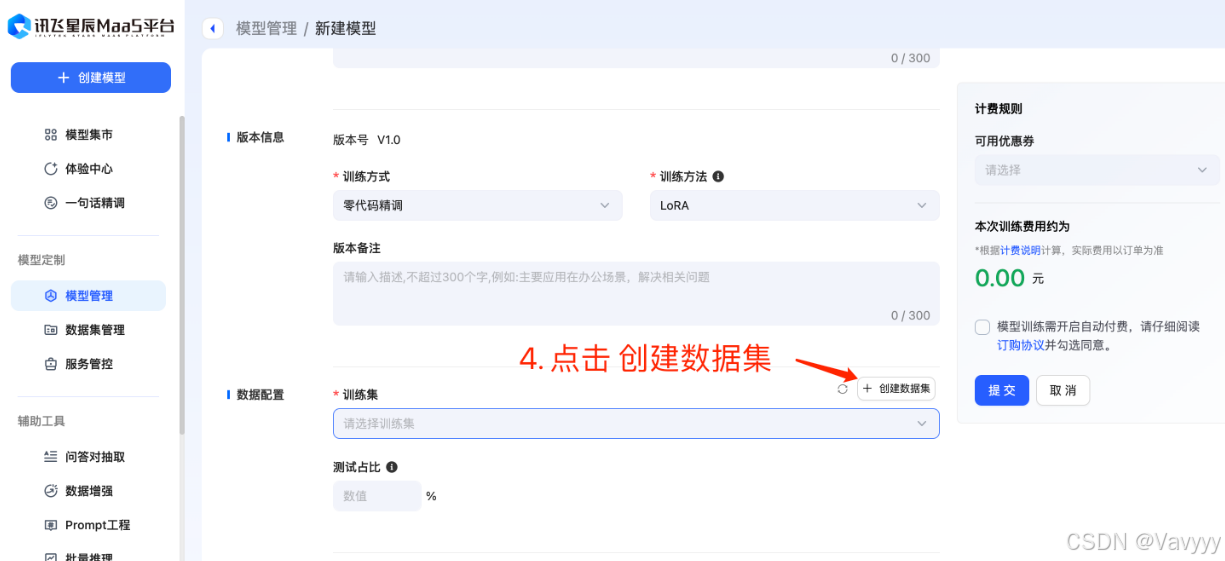
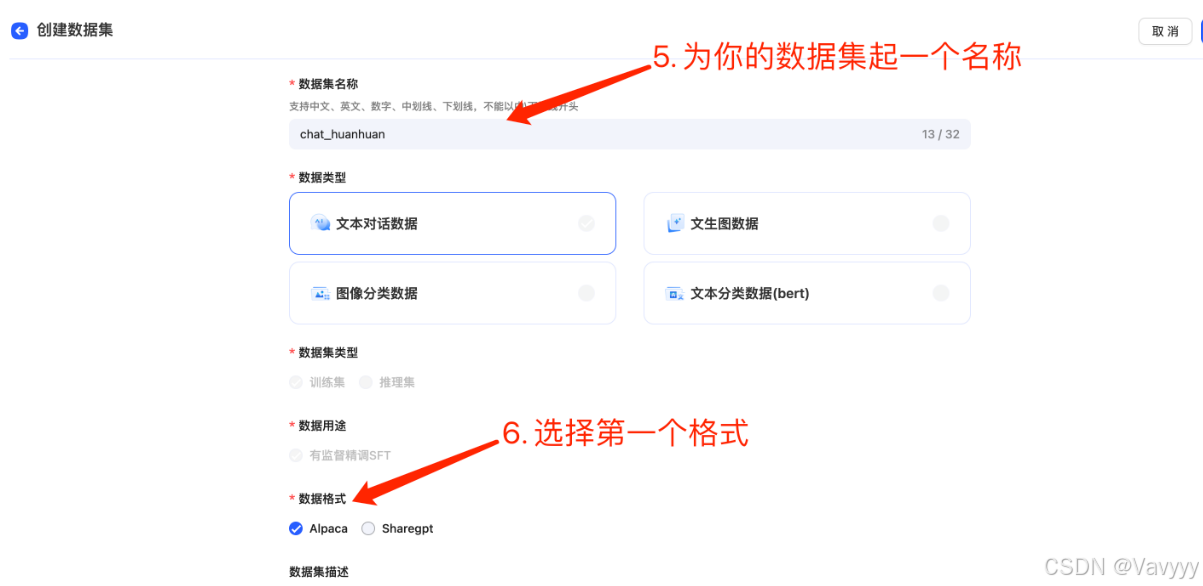
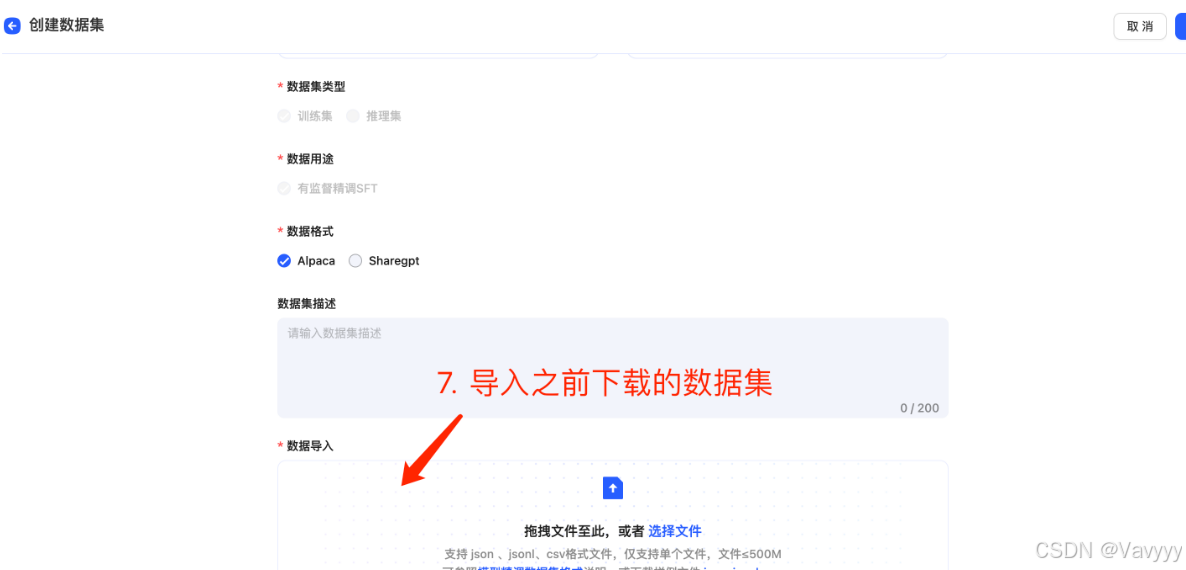
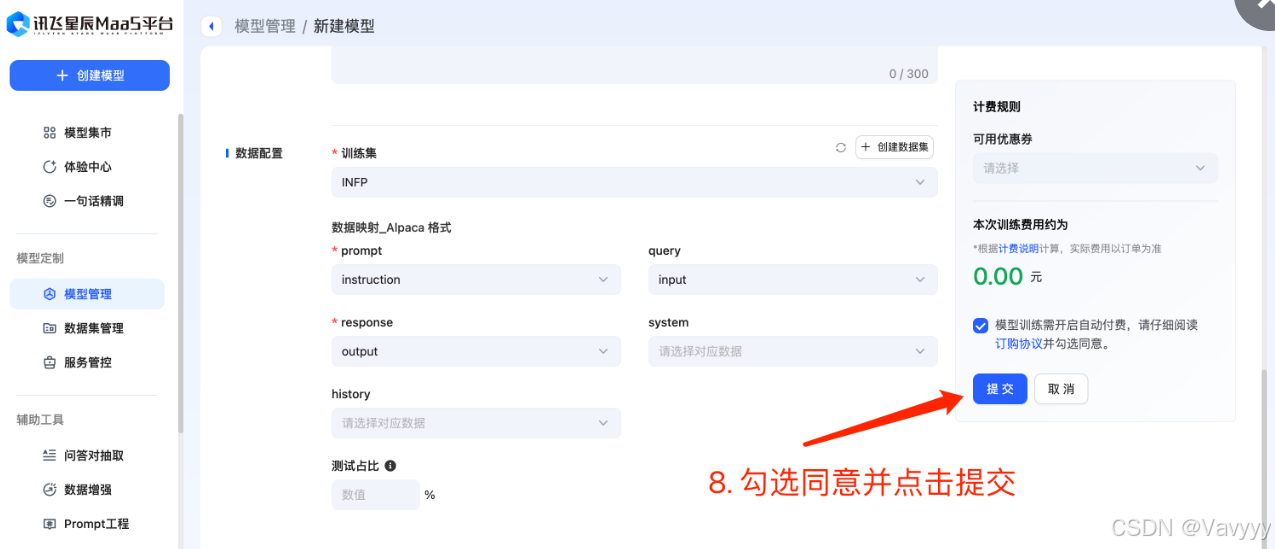
可能平台同时需要执行的任务过多,需要排队,大家不用担心,都可以排上队的!
越早提交,越容易排上队,以防需要等待的时间过长哟~(另外,数据集越大,任务所需要花的时间也会越长)
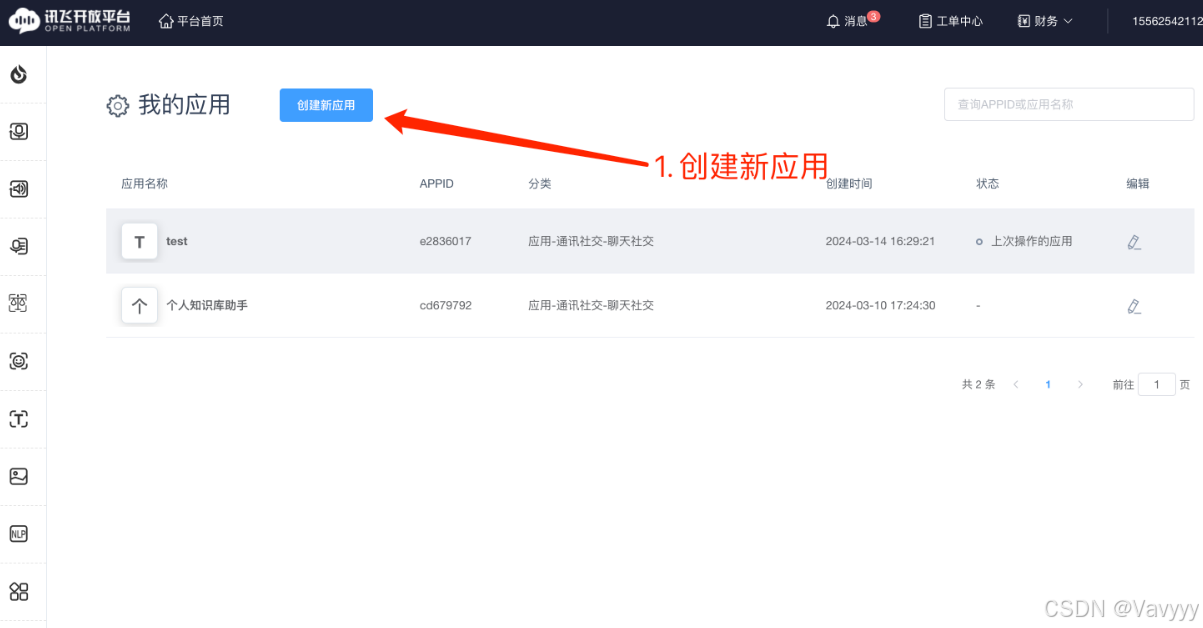
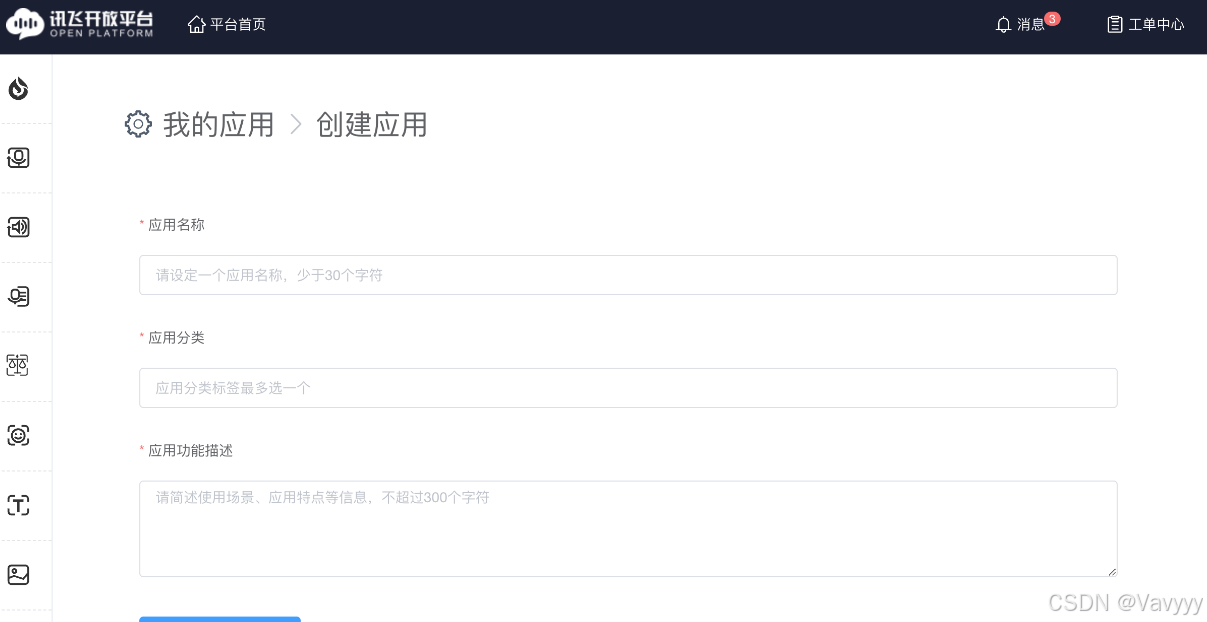
Step4: 创建应用(点击可跳转)
链接:控制台-讯飞开放平台
这一步中是配置好应用的后台与分类设置,然后将我们训练好的大模型投入其中,完成Chat-嬛嬛
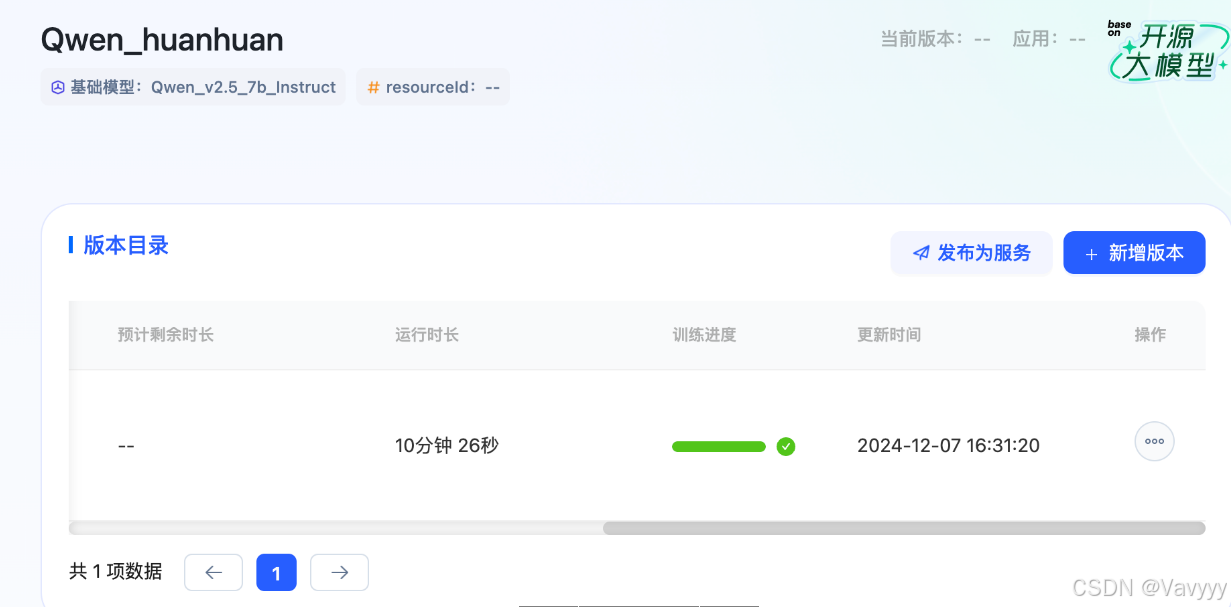
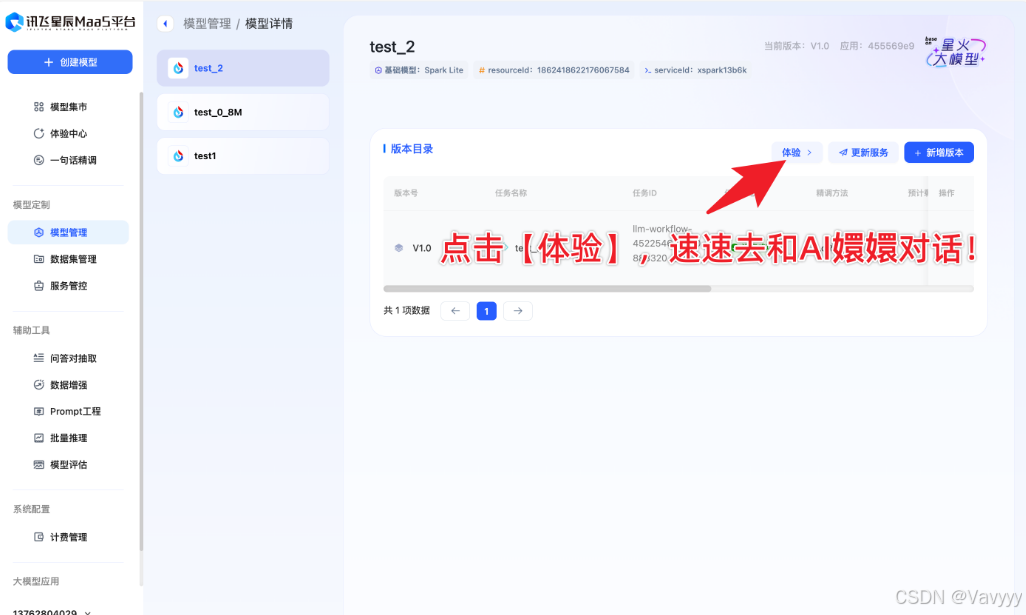
Step5:体验AI嬛嬛!
微调时间大概在15~25min间不等,根据排队人数而定
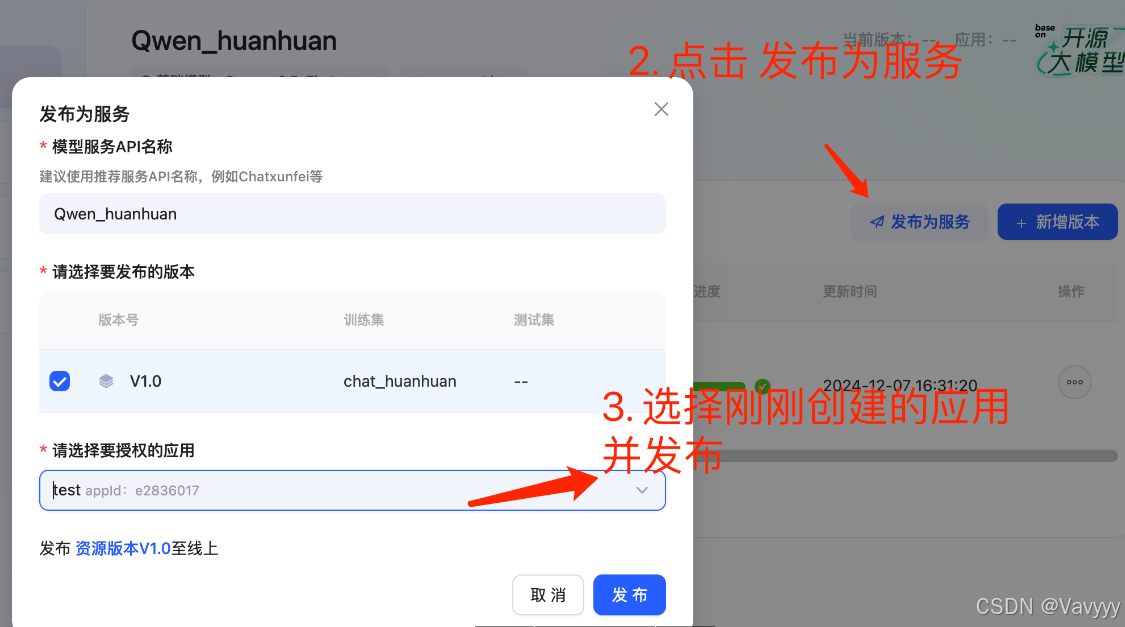
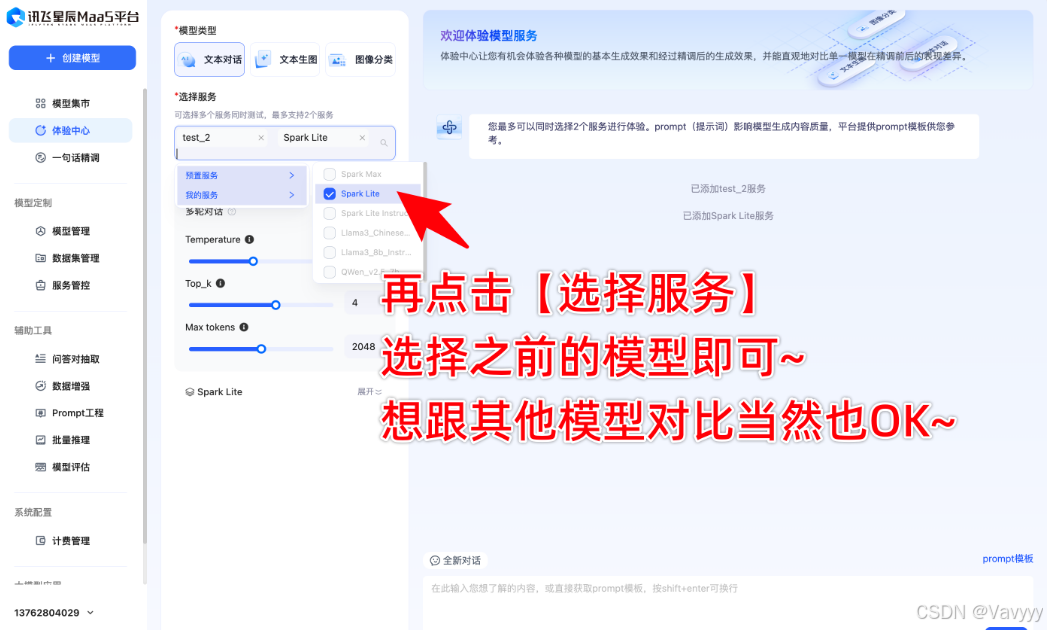
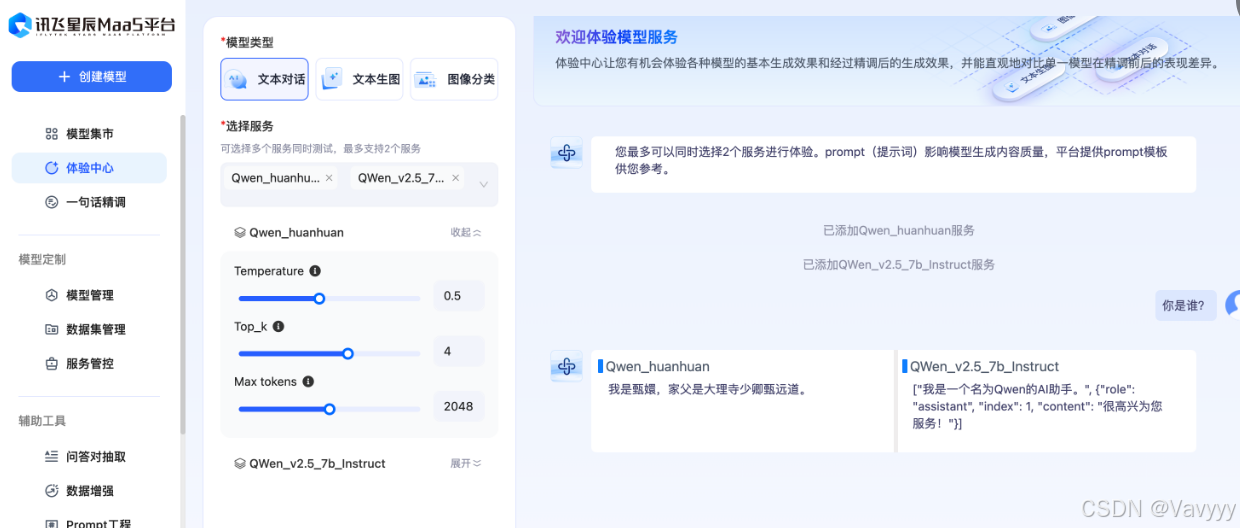
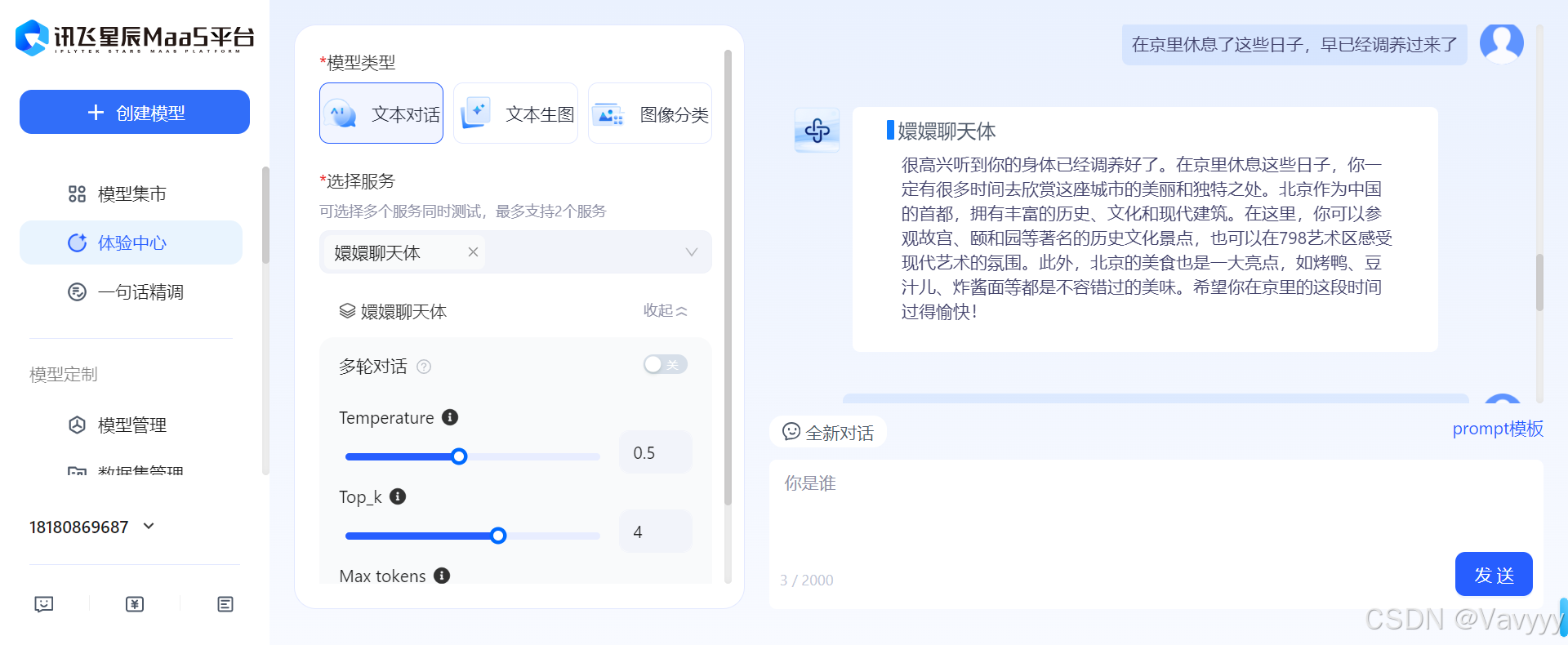
可以看出大模型不是很理想,与我们的数据库提供语料过于死板与平常聊天不符、Alpoco格式过于线性的逻辑以及input的空白条件缺失不确定性太大所导致,后续还有很大的改进提升空间。
但总之我们已经初步了解了特定专属大模型的训练过程及原理。

















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









