







本系列已完结,全部文章地址为:
Transformer解析——(二)Attention注意力机制-CSDN博客
Transformer解析——(三)Encoder-CSDN博客
Attention是一个独立的模型,在各种深度学习中都可以使用,只是transformer将其发扬光大了。本文我们先跳出transformer模型,关注Attention模型本身。
1 问题的引入
本文我们介绍自注意力(self-attention),在后文Decoder的说明中再讲解交叉注意力(cross-attention)。自注意力指单词对同一句话中每个词产生注意力。
为什么要用自注意力机制?Attention顾名思义是指输入序列中单词“注意”到了整个句子的每个词。假设用机器学习对"Good work"和"I work hard"做词性标注,如果直接将词语丢到一个训练好的神经网络中,第一个work和第二个work经过同样的神经网络,肯定会输出同样的结果。
为了解决这个问题,需要先经过一个Attention模块,使得词语能够注意到上下文,然后再经过一个神经网络(如下图所示),输出词语的类别。第一个"work"注意到了"good",构成了形容词+名词的结构,因此容易识别成名词;第二个"work"注意到了"I",构成了主语+动词的结构,因此容易识别成动词。经过Attention模块,两个"work"包含了不一样的上下文信息,因此可以识别出不同的词性。
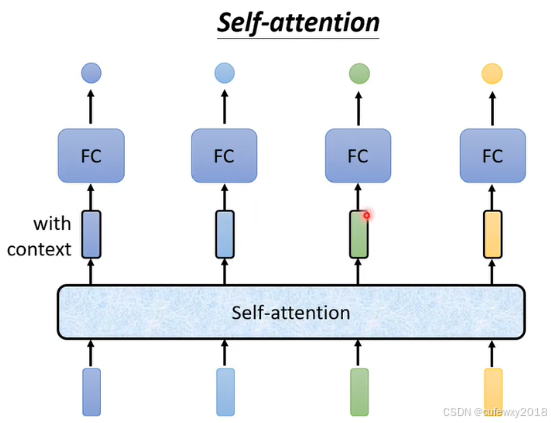
李宏毅老师课程中举了"I saw a saw"的例子,他认为第一个saw是动词,第二个saw是名词(锯),输入到attention后,使其包含上下文信息,才可以判断正确。个人愚见这个例子不太恰当,因为这2个saw是在同一个句子中的,输入到同样的attention模型,得到的上下文信息也是一样的,所以并不能区分词性。
2 Attention设计直觉
到目前为止,我们知道Attention能够让每个词的输出承载上下文信息,那么Attention具体应该怎么设计呢?
首先,既然单词要考虑上下文,那么单词要与句子中所有的词匹配,我们预期两个词越相关,匹配程度应该越大;两个词越不相关,匹配程度应该越小。因此,需要计算单词与句子中所有词的匹配程度。匹配程度很像是权重,把它归一化后,就得到了每个单词在句子中所有词应该分配的“精力”占比。
其次,只计算匹配程度还不足够,我们的最终目标是让输出的单词承载信息,以便于后续输入到神经网络中标注词性。这种信息应该是考虑了所有词的匹配程度后的结果,即对所有词的信息加权求和,权重就是匹配程度。
因此,Attention的设计原则是:第一,要计算词之间的匹配程度;第二,要抽取词的信息。
2.1 如何计算匹配程度
在计算单词之间匹配程度时,可以直接用Embedding后的向量算相似性吗?答案是不可以。我们知道两个同义词的向量可能非常相似,比如"cat"和"dog"两个词向量十分接近,"man"和"woman"两个词向量十分接近。如果直接用Embedding后的向量算相似性,那么只是描述了单词之间“词义”的匹配程度,但这并不是模型的关注点。
比如这句话"Bob is a boy, he is smart. Alice is a girl, she is beautiful."如果单纯计算词向量的相似性,那么"she"和"he"的相似性最大,但是这对于语义理解并无帮助,因为上文描述中"Alice"和"Bob"是两个不相关的人。理论上机器应该将"she"与"Alice","girl","beautiful"相关联,而不是"he"相关联,这样我们询问机器"Is Alice look beautiful?"时,机器才能回答正确。
因此,在计算两个单词之间匹配程度时,需要对单词做转换,使得词向量从“词义匹配”升级为“逻辑匹配”。逻辑匹配听起来非常抽象,Attention中是怎么实现的呢?
Attention假定匹配的时候每个单词都有“关注点”和“标签”,利用单词的关注点与每个词的标签做匹配,即可得到两个词之间的逻辑匹配程度。Attention会训练出“关注点提取器”和“标签提取器”,输入原始词向量,输出关注点和标签的提取。
就像是相亲软件中,每个用户都有关注的要求,用于筛选其他人,如性格温柔,学历硕士以上等;同时自身也有标签,用于被其他人选择,如性格温柔,学历硕士;或者性格腼腆,学历博士等。也像是搜索引擎中,用关键字查询网站主题一样。
2.2 如何抽取信息
同样,单词的Embedding直接用作信息是不合理的,因为单词Embedding只是语义上的表示,不能体现其蕴含的信息。在一句话中单个词蕴含的信息应该是语义、语法等多维度的结果,因此也需要一个“信息抽取器”,将词变换成信息。
就像在相亲时,构成结婚对象这个生物体的基因编码本身是没有价值的,他/她的实力、性格等才有价值。
上文所说的关注点、标签、信息等在Attention中都有术语,见下表:
| 概念 | 含义 | 相亲软件类比 | 搜索引擎类比 |
| Query | 查询,用于查询其他词 | 对另一半的要求 | 搜索关键字 |
| Key | 键,用于被其他词查询 | 每个人的身高、学历等标签 | 网站主题 |
| Value | 值,即词蕴含的信息 | 另一半带来的价值 | 搜索结果带来的信息 |
2.3 输出结果的直观解释
对每个词的注意力做归一化,从而使得各词的注意力之和为1,表示为权重。
注意力权重只代表关注程度,并不包含实际的信息。而V才包含信息。因此需要单词对其余所有词的价值按注意力权重加权求和,这样得到了综合了所有词的注意力特征。
在相亲软件的例子中,这种加权求和得到的价值就是相亲软件中基于所有候选人匹配程度为用户带来的价值,可以理解成每个用户感受到这个相亲软件推荐另一半的整体质量。
在翻译的例子中,"Bob is a boy, he is smart.",其中"he"对"Bob"的注意力可能是最高的,因此"he"的特征中"Bob"的占比可能是很高的,"Bob"本身的信息,如身高体重等,同样也会构成"he"的信息,这样"he"的信息不再是孤立的,而是参考了上下文的结果。
2.4 通过训练达到目标
总结一下,Attention模型中需要对单词做3个转换:QKV,需要训练出QKV的变换权重。注意这里的变换都是线性变换,这保证了计算高效。
Query的线性变换提取出当前词关注的特征,想要从句子其他部分获取的语义、语法等相关信息,后续将根据此特征查询其他词,从而完成匹配。
Key的线性变换提取出当前词的语义语法特征,从而与其他词的Query相匹配。
Value的线性变换提取出当前词的实质信息。一旦K与某个单词的Q匹配,就会从该单词中提取出信息。
当然,上述分析都是“一厢情愿”的,QKV转换真的能表示查询、标签、信息吗?事实上,深度学习设计了巧妙的结构后,需要通过大量训练,QKV的转换权重才会从初始随机化的权重逐渐产生相应的意义。当然,也许最初设计的结构在学习后已经偏离了设计初衷。一部分人认为力大砖飞,能work就行;另一部分人研究可解释性。这就是另一个话题了。
3 Attention的计算
3.1 符号定义
| 符号 | 含义 | 示例 | 维度 |
| batch_size | 训练批次大小,即每次训练时包含多少个句子。预测时为1 | 64 | 单个数字 |
| seq_len | 序列长度,即包含token的大小。若batch包含多个序列,取最长 | 37 | 单个数字 |
| d_model | Embedding后每个token的词向量维度 | 128 | 单个数字 |
| num_heads | 多头的数量 | 8 | 单个数字 |
| I | 输入矩阵 | batch_size*seq_len*d_model,下文忽略batch_size,仅考虑单个批次 | |
| i | 输入元素,即单个token | d_model | |
| WQ | 对token线性变换的矩阵,得到Query | d_model*d_model | |
| WK | 对token线性变换的矩阵,得到Key | d_model*d_model | |
| WV | 对token线性变换的矩阵,得到Value | d_model*d_model | |
| q | 单个token线性变换得到的Query | d_model | |
| k | 单个token线性变换得到的Key | d_model | |
| v | 单个token线性变换得到的Value | d_model | |
| Q | 得到的Query矩阵 | seq_len*d_model | |
| K | 得到的Key矩阵 | seq_len*d_model | |
| V | 得到的Value矩阵 | seq_len*d_model | |
| A | Attention矩阵,即句子中每个token之间的注意力矩阵 | seq_len*seq_len | |
| A' | A经过softmax得到的权重 | seq_len*seq_len | |
| o | 输出 | d_model | |
| O | 输出的矩阵 | seq_len*d_model |
3.2 计算过程
前文的解析实际已说明了计算过程,本节用具体实例说明。
Embedding后的token记为i(假设为128维),假设一句话有37个token。
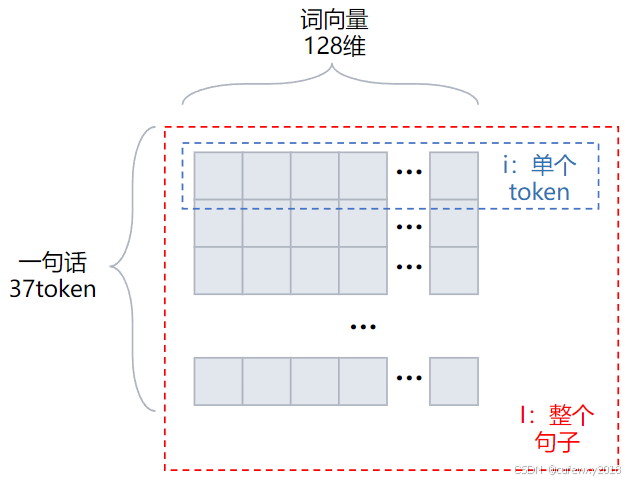
第一步,进行WQ变换。将i向量乘WQ矩阵(128*128维),得到q向量(128维),表示该token的Query。
与WQ矩阵相乘等价于将i传入一个神经网络,输入是128维,输出是128维,无偏置和激活函数(与上一篇的Input Embedding分析类似,即传入一个神经网络等价于矩阵线性变换)。
注意每个i都与WQ相乘,相当于I与WQ相乘,得到Q(37*128维)。下图中I矩阵中的黄色代表其中1个token,Q矩阵中红色代表该token对应的query。
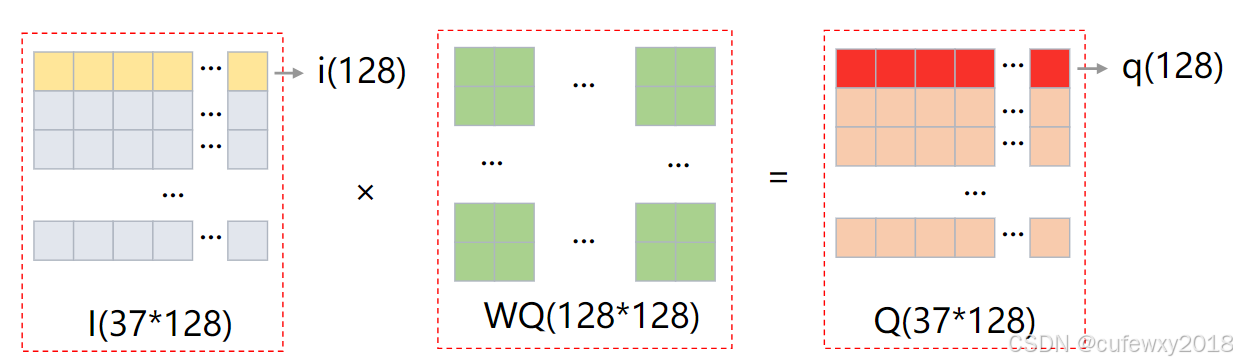
第二步,进行WK变换。同理,将i乘WK,得到k(128维),用矩阵表示为K(37*128维)。
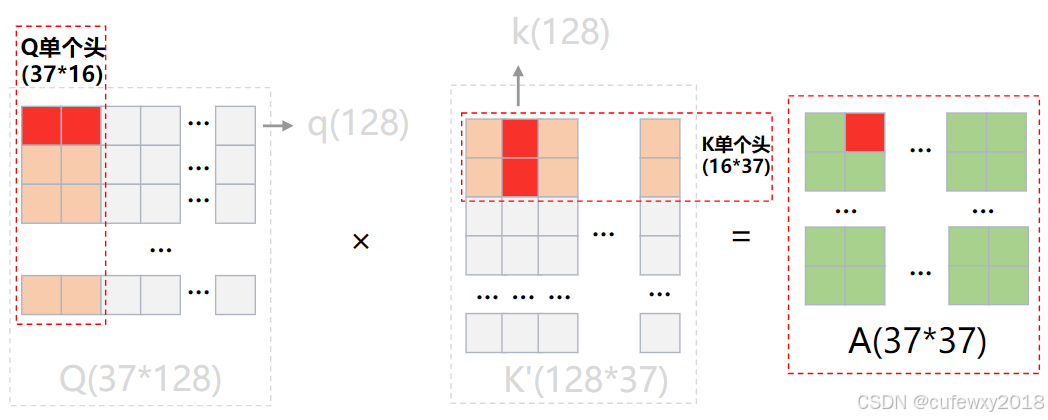
第三步,求Attention,并使用softmax归一化。q与k两两相乘,相当于Q与K的转置相乘,得到A(37*37维),即表示这37个token两两之间的注意力。两个向量相乘结果越高代表相似性越大,匹配度越高。此处矩阵需要除以sqrt(d_model),原因是随着d_model增大,矩阵点积将增大,过大的值影响softmax对于概率的计算,使得注意力分布不均,影响模型收敛。
下图中Q矩阵红色部分代表第1个q,K'矩阵红色部分代表第2个k,得到A矩阵红色部分代表第1个q与第2个k相乘得到的Attention。
两个向量相乘为什么可以代表相似性?从几何意义的角度理解,两个向量内积反映了他们之间的夹角,夹角为0°代表方向一致,内积较大;夹角垂直代表毫不相干,内积为0;夹角为180°代表方向相反,内积为负数。从特征表示的角度理解,每个向量每个维度都代表一定特征,内积是对应维度相乘求和,内积越大代表两个向量对应维度都较大,说明他们具有相似的特征。比如“猫”和“狗”两个词向量,第一个维度假设代表动物,第二个维度假设表示可爱程度,这2个向量在前2个维度都较大,那么相乘求和自然更大。
经过一个softmax运算得到A',使得每一行之和为1,即得到注意力权重。
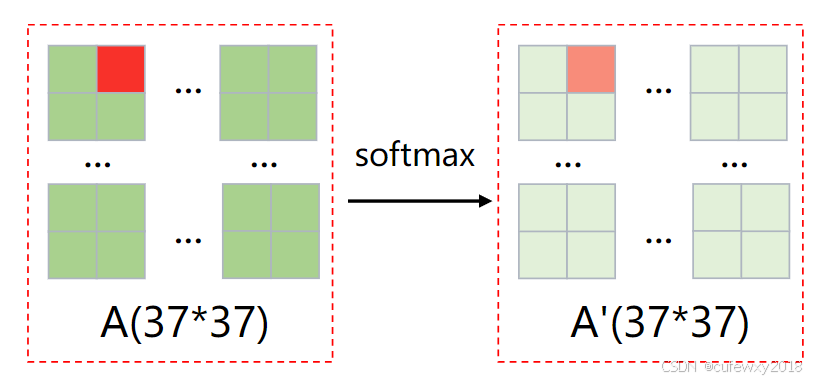
第四步,使用注意力权重A'乘V,即可得到最终结果。
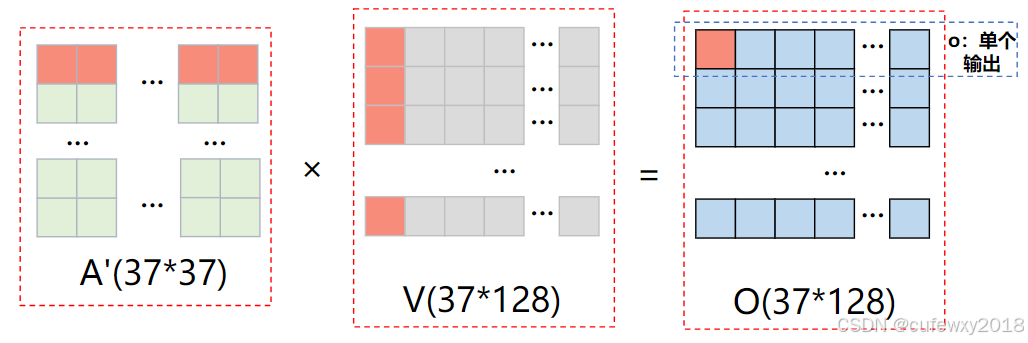
上图中A'矩阵的红色代表第1个token对其余所有token的注意力权重(加起来为1),V矩阵中红色代表第1个维度各个token的价值,O矩阵中红色代表第1个token考虑了所有token注意力后第一个维度的整体价值,O矩阵中第一行就代表所有128个维度的价值。注意O矩阵的37行与输入的37个token是一一对应的。
4 多头注意力
4.1 问题的引入
在计算Attention时,考虑词与词之间的匹配维度可能不止一种。比如有时需要考虑语法之间的匹配程度,有时需要考虑词义之间的匹配程度。那么可以设计出多个QKV线性变换,使得同一个词在不同的角度(即不同的头head)下“查询”、“标签”、“信息”是不一样的。
类比到相亲软件的例子,每个人关注的维度是多方面的,应从多角度筛选另一半。比如从身高维度看,每个人的“查询”表示对于身高的要求(要求高/要求不能过高/没有要求等),每个人的“标签”表示自身身高的条件(高/中/矮),每个人的“信息”表示基于身高带来的价值(比如身高越高安全感越高,身高越矮保护欲越强);从学历维度看,每个人的“查询”表示对于学历的要求(希望另一半是博士/硕士/本科/其他),每个人的“标签”表示自身的学历,每个人的“信息”表示基于学历带来的价值(比如对后代的言传身教,日常生活问题的解答等)。
4.2 计算过程
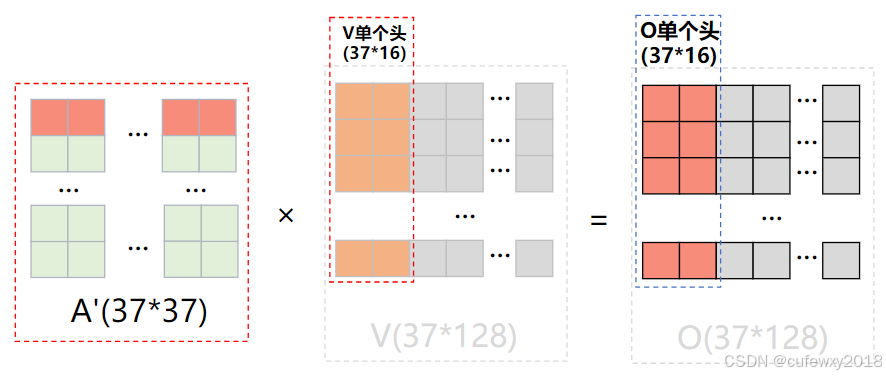
在计算完毕QKV之后,按词向量维度d_model切分,每个头计算相应维度的Attention和加权Value。然后把他们拼接起来,组装成d_model维度,最后再经过一个线性网络即可。
例如d_model=128,n_heads=8,则每个头只计算128/8=16个维度。
这样得到了8个头对应的注意力矩阵A,A经过softmax归一化后,每个头的A都与V(单个头,37*16维)得到8个输出,每个输出都是37*16维度。将8个头的输出拼接起来,即得到整体输出(37*128维),随后经过线性变换层,即可得到最终的输出。
4.3 不同头的联合方式
可能有读者有疑问(也是笔者初学时的疑问),不同的头处理的是不同词向量的维度,比如第一个头处理所有词的第1~16维,第二个头处理所有词的17~32维等。那么词A的第1维和词B的第17维分属于2个头处理,岂不是这2个维度永远都无法接头,计算Attention了?事实上,在不同的头处理后,会将所有头的输出拼接,然后再经过一个线性的变换,线性变换中是可以将不同的头联系起来的。
4.4 Transformer的并行且对应特性
注意,Attention的输入和输出是并行且对应的,一个输出对应一个输入,与顺序无关(transformer中是引入位置编码才与顺序有关)。上图中矩阵只是为了将所有token放在一起运算,如果对调了矩阵中第m个词和第n个词的顺序,那么QKV中第m行和第n行也会互换,最终结果O的m和n行也会对调,所以依然是对应的,而其他词的输出并不会受影响。比如我们分析第q个词的输出,现在m和n调换顺序,第q个词与m、n的注意力权重对调,但加权求和后并不影响结果。在多头注意力机制下,结论是一致的,即使最后要经过一个线性变换层,线性变换是针对每个单词进行的,等价于O(37*128维)与线性变换矩阵(128*128维)相乘,在线性变换矩阵参数不变的情况下,对调m和n只是让最终输出的矩阵中m和n行对调。这样输入与输出同时对调,Attention的输入和输出依然是对应的。
4.5 计算总结
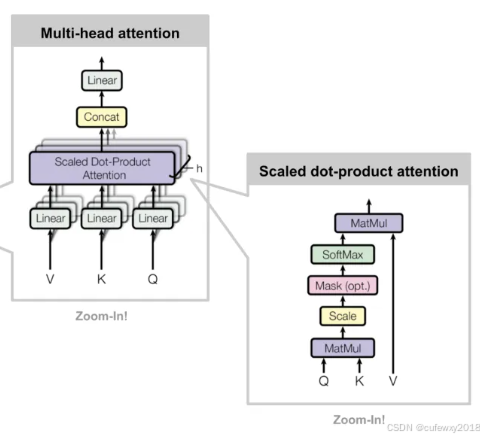
如上图所示,QKV经过线性变换后,Q与K矩阵相乘,做Mask(后几篇将介绍),经过Softmax层得到概率,并与V矩阵相乘,每个头都按这种方式计算,各个头的结果拼接,最后经过一个线性层输出结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









