






数据仓库配置是多对一的配置方案。多个源端数据库将数据发送到同一个目标数据仓库。OGG支持将源库同步到多个目标系统。

数据仓库配置需要注意以下事项:
假设每个源端的数据库发送到目标系统的数据都是不同的。如果在多个源端系统出现了相同的表,表中出现了相同的记录时,需要做出冲突解决。
你可以将源端系统和目标端系统的数据存储相互分离,节约目标端所需的大量磁盘空间。为了 避免提取进程通过网络直接将数据发送给目标端, 每个源端系统上都需要设置数据泵投递进程。
初级提取组将数据写入每个源端的本地trail
每个源端数据泵投递进程将读取本地trail,然后通过TCP/IP发送给专属复制组(dedicated replicat group)。
创建仓库分布结构
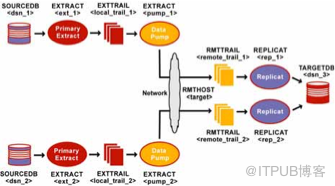
源端系统
配置管理进程
1,在源端配置管理进程,参见笔 【goldengate】官方文档笔记一
http://blog.itpub.net/29047826/viewspace-1249506/
2,在管理进程参数文件中,使用PURGEOLDEXTRACTS参数来控制本地trail文件的清除工作。
配置初级提取进程
3,在每一个源端上,使用ADD EXTRACT命令来创建一个初级提取组。在这里我们取名为ext_1和ext_2。
Extract_1
ADD EXTRACT , {TRANLOG | INTEGRATED TRANLOG}, BEGIN , [, THREADS]
Extract_2
ADD EXTRACT , {TRANLOG | INTEGRATED TRANLOG}, BEGIN , [, THREADS]
4,在每一个源端上,使用ADD EXTTRAIL命令来创建一个本地trail
Extract_1
ADD EXTTRAIL , EXTRACT
Extract_2
ADD EXTTRAIL , EXTRACT
使用参数EXTRACT将同一个系统上的提每一个取组连接到本地trail。提取组将信息写入trail,投递组从trail中读取。
5,在每一个源端上,使用EDIT PARAMS命令为初级提取组创建一个参数文件。
Extract_1 EXTRACT [SOURCEDB ][, USERID ][, PASSWORD []]
ENCRYPTTRAIL EXTTRAIL TABLE .
Extract_2
EXTRACT
[SOURCEDB ][, USERID ][, PASSWORD []]
ENCRYPTTRAIL
EXTTRAIL
TABLE . ;
配置数据泵投递组
6,在每一个源端上,使用ADD EXTRACT 命令为每一个目标系统创建数据泵。在这里我们取名为pump_1,pump2.
Data pump_1
ADD EXTRACT , EXTTRAILSOURCE , BEGIN
Data pump_2
ADD EXTRACT , EXTTRAILSOURCE , BEGIN
EXTTRAILSOURCE作为数据源选项,指定本地trail文件。
7,在每一个源端上,使用ADD RMTTRAIL命令创建一个目标数据库上的trail。
source_1
ADD RMTTRAIL , EXTRACT
source_2
ADD RMTTRAIL , EXTRACT
使用EXTRACT参数将每个远程的tail连接到不同的数据泵投递组。投递组通过TCP/IP向trail写入数据,然后复制组从trail读取数据。
8,在每一个源端上,使用EDIT PARAMS命令为每一个数据泵提取组创建参数文件。
Data pump_1
EXTRACT [SOURCEDB ][, USERID ][, PASSWORD []]
DECRYPTTRAIL RMTHOST , MGRPORT , ENCRYPT ENCRYPTTRAIL RMTTRAIL [PASSTHRU | NOPASSTHRU] TABLE .
Data pump_2
EXTRACT [SOURCEDB ][, USERID ][, PASSWORD []]
DECRYPTTRAIL RMTHOST , MGRPORT , ENCRYPT ENCRYPTTRAIL RMTTRAIL [PASSTHRU | NOPASSTHRU] TABLE .
目标系统
配置管理进程
9,在源端配置管理进程,参见笔 【goldengate】官方文档笔记一
http://blog.itpub.net/29047826/viewspace-1249506/
10,在管理进程参数文件中,使用PURGEOLDEXTRACTS参数来控制本地trail文件的清除工作。
配置复制组
11,在目标系统上,使用ADD REPLICAT命令为每一个远程的trail创建复制组(Replicat group)。在这里我们取名为rep_1,rep_2
Relicat_1
ADD REPLICAT , EXTTRAIL , BEGIN
Replicat_2
ADD REPLICAT , EXTTRAIL , BEGIN
EXTTRAIL参数用于将复制组连接到正确的trail。
12,在目标系统上,使用EDIT PARMAS命令分别创建一个提取组参数文件。
Relicat_1
REPLICAT SOURCEDEFS | ASSUMETARGETDEFS [TARGETDB ][, USERID ][, PASSWORD []]
DECRYPTTRAIL REPERROR (, ) MAP .
Replicat_2
REPLICAT SOURCEDEFS | ASSUMETARGETDEFS [TARGETDB ][, USERID ][, PASSWORD []]
DECRYPTTRAIL REPERROR (, ) MAP . 你可以为复制组使用多个MAP语句。这些MAP语句必须指定包含在连接到该组中相同trail里的对象。


数据仓库配置需要注意以下事项:
假设每个源端的数据库发送到目标系统的数据都是不同的。如果在多个源端系统出现了相同的表,表中出现了相同的记录时,需要做出冲突解决。
你可以将源端系统和目标端系统的数据存储相互分离,节约目标端所需的大量磁盘空间。为了 避免提取进程通过网络直接将数据发送给目标端, 每个源端系统上都需要设置数据泵投递进程。
初级提取组将数据写入每个源端的本地trail
每个源端数据泵投递进程将读取本地trail,然后通过TCP/IP发送给专属复制组(dedicated replicat group)。
创建仓库分布结构

源端系统
配置管理进程
1,在源端配置管理进程,参见笔 【goldengate】官方文档笔记一
http://blog.itpub.net/29047826/viewspace-1249506/
2,在管理进程参数文件中,使用PURGEOLDEXTRACTS参数来控制本地trail文件的清除工作。
配置初级提取进程
3,在每一个源端上,使用ADD EXTRACT命令来创建一个初级提取组。在这里我们取名为ext_1和ext_2。
Extract_1
ADD EXTRACT , {TRANLOG | INTEGRATED TRANLOG}, BEGIN , [, THREADS]
Extract_2
ADD EXTRACT , {TRANLOG | INTEGRATED TRANLOG}, BEGIN , [, THREADS]
4,在每一个源端上,使用ADD EXTTRAIL命令来创建一个本地trail
Extract_1
ADD EXTTRAIL , EXTRACT
Extract_2
ADD EXTTRAIL , EXTRACT
使用参数EXTRACT将同一个系统上的提每一个取组连接到本地trail。提取组将信息写入trail,投递组从trail中读取。
5,在每一个源端上,使用EDIT PARAMS命令为初级提取组创建一个参数文件。
Extract_1 EXTRACT [SOURCEDB ][, USERID ][, PASSWORD []]
ENCRYPTTRAIL EXTTRAIL TABLE .
Extract_2
EXTRACT
[SOURCEDB ][, USERID ][, PASSWORD []]
ENCRYPTTRAIL
EXTTRAIL
TABLE . ;
配置数据泵投递组
6,在每一个源端上,使用ADD EXTRACT 命令为每一个目标系统创建数据泵。在这里我们取名为pump_1,pump2.
Data pump_1
ADD EXTRACT , EXTTRAILSOURCE , BEGIN
Data pump_2
ADD EXTRACT , EXTTRAILSOURCE , BEGIN
EXTTRAILSOURCE作为数据源选项,指定本地trail文件。
7,在每一个源端上,使用ADD RMTTRAIL命令创建一个目标数据库上的trail。
source_1
ADD RMTTRAIL , EXTRACT
source_2
ADD RMTTRAIL , EXTRACT
使用EXTRACT参数将每个远程的tail连接到不同的数据泵投递组。投递组通过TCP/IP向trail写入数据,然后复制组从trail读取数据。
8,在每一个源端上,使用EDIT PARAMS命令为每一个数据泵提取组创建参数文件。
Data pump_1
EXTRACT [SOURCEDB ][, USERID ][, PASSWORD []]
DECRYPTTRAIL RMTHOST , MGRPORT , ENCRYPT ENCRYPTTRAIL RMTTRAIL [PASSTHRU | NOPASSTHRU] TABLE .
Data pump_2
EXTRACT [SOURCEDB ][, USERID ][, PASSWORD []]
DECRYPTTRAIL RMTHOST , MGRPORT , ENCRYPT ENCRYPTTRAIL RMTTRAIL [PASSTHRU | NOPASSTHRU] TABLE .
目标系统
配置管理进程
9,在源端配置管理进程,参见笔 【goldengate】官方文档笔记一
http://blog.itpub.net/29047826/viewspace-1249506/
10,在管理进程参数文件中,使用PURGEOLDEXTRACTS参数来控制本地trail文件的清除工作。
配置复制组
11,在目标系统上,使用ADD REPLICAT命令为每一个远程的trail创建复制组(Replicat group)。在这里我们取名为rep_1,rep_2
Relicat_1
ADD REPLICAT , EXTTRAIL , BEGIN
Replicat_2
ADD REPLICAT , EXTTRAIL , BEGIN
EXTTRAIL参数用于将复制组连接到正确的trail。
12,在目标系统上,使用EDIT PARMAS命令分别创建一个提取组参数文件。
Relicat_1
REPLICAT SOURCEDEFS | ASSUMETARGETDEFS [TARGETDB ][, USERID ][, PASSWORD []]
DECRYPTTRAIL REPERROR (, ) MAP .
Replicat_2
REPLICAT SOURCEDEFS | ASSUMETARGETDEFS [TARGETDB ][, USERID ][, PASSWORD []]
DECRYPTTRAIL REPERROR (, ) MAP . 你可以为复制组使用多个MAP语句。这些MAP语句必须指定包含在连接到该组中相同trail里的对象。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/29047826/viewspace-1254627/,如需转载,请注明出处,否则将追究法律责任。
请登录后发表评论
登录
全部评论
<%=items[i].createtime%>
<%=items[i].content%>
<%if(items[i].items.items.length) { %>
<%for(var j=0;j
<%}%> <%if(items[i].items.total > 5) { %>
<%}%> <%}%>
<%=items[i].items.items[j].createtime%>
<%=items[i].items.items[j].username%> 回复 <%=items[i].items.items[j].tousername%>: <%=items[i].items.items[j].content%>
还有<%=items[i].items.total-5%>条评论
) data-count=1 data-flag=true>点击查看
<%}%>

北京盛拓优讯信息技术有限公司. 版权所有 京ICP备09055130号-4 北京市公安局海淀分局网监中心备案编号:11010802021510
广播电视节目制作经营许可证(京) 字第1234号 中国互联网协会会员
转载于:http://blog.itpub.net/29047826/viewspace-1254627/















 557
557












 到【灌水乐园】发言
到【灌水乐园】发言








