









 本文深入探讨了 Kubernetes 的网络概念,包括 pod 间的通信和解决方案。重点介绍了网络策略 NetworkPolicy 的使用,包括入站和出站规则的配置,如通过标签、命名空间、IP 块限制流量。通过实例展示了如何配置 NetworkPolicy 来控制 pod 之间的通信,以及如何解决 svc 名称不能出的问题。同时,还讨论了 Calico 网络在集群间通信配置中的应用。
本文深入探讨了 Kubernetes 的网络概念,包括 pod 间的通信和解决方案。重点介绍了网络策略 NetworkPolicy 的使用,包括入站和出站规则的配置,如通过标签、命名空间、IP 块限制流量。通过实例展示了如何配置 NetworkPolicy 来控制 pod 之间的通信,以及如何解决 svc 名称不能出的问题。同时,还讨论了 Calico 网络在集群间通信配置中的应用。
文章目录
calico网络之间通信配置【docker容器互通流程配置】
去这篇博客
【Kubernetes】k8s网络概念和实操详细说明【含docker不同容器网络互通配置,k8s网络互通配置】【1】
网络说明
pod间通信
先丢几张图吧,随缘理解,不能理解无所谓,继续往后看就是了。
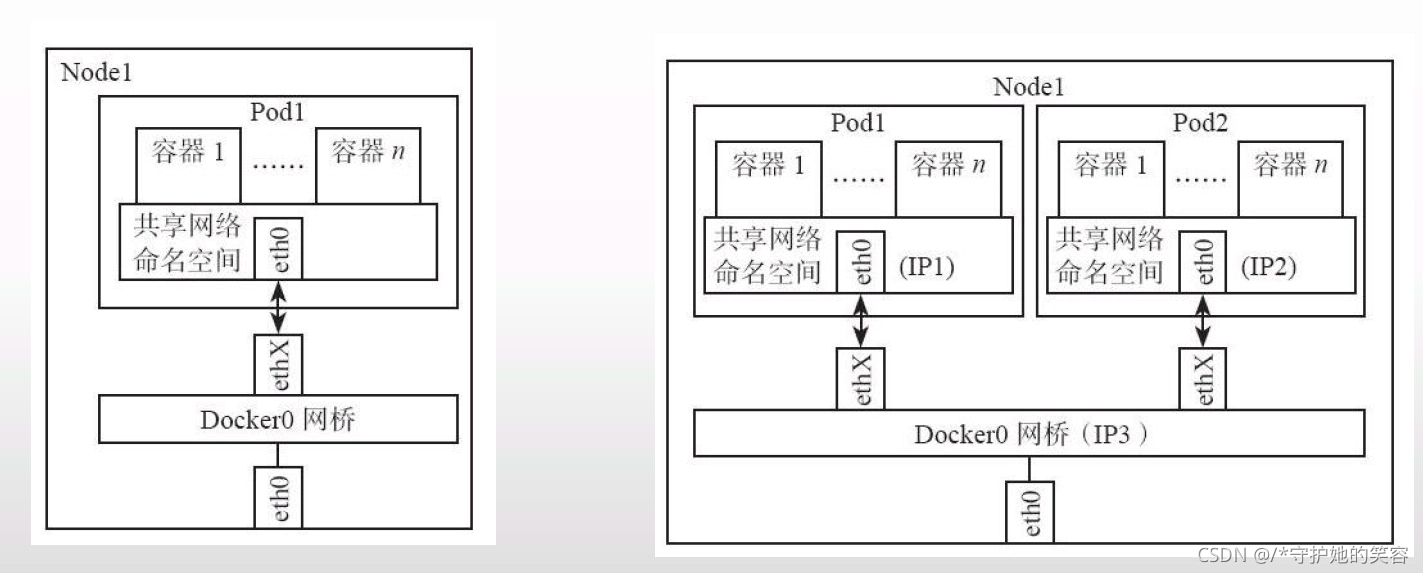
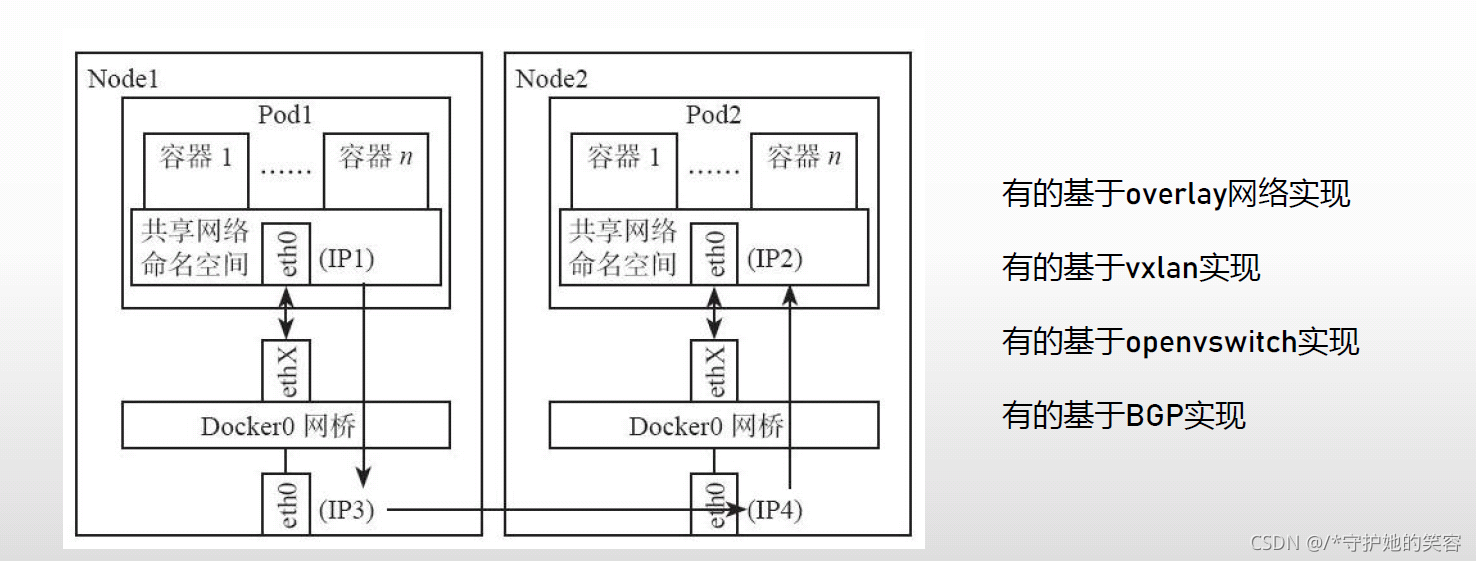
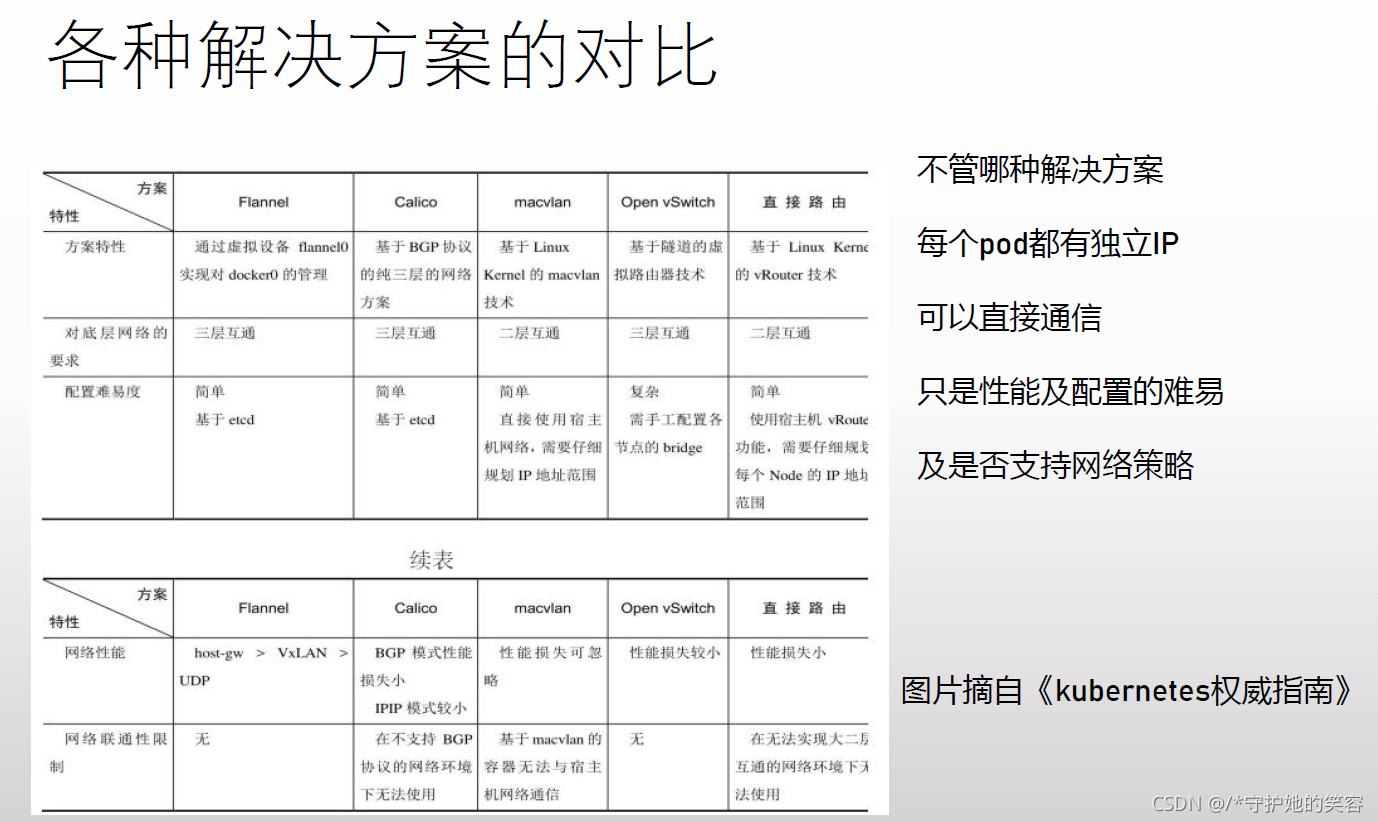
网络解决方案

做网络策略前的网络测试
做这个测试呢,是为了方便后面能更容易理解k8s的网络
环境准备
- 首先需要有一套集群
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 109d v1.21.0
node1 Ready <none> 109d v1.21.0
node2 Ready <none> 109d v1.21.0
[root@master ~]#
[root@master ~]#
- 然后我们创建一个文件用来放后面的测试文件,创建一个命名空间,后面测试都在这个命名空间做
[root@master ~]# mkdir net
[root@master ~]# cd net
[root@master net]# kubectl create ns net
namespace/net created
[root@master net]# kubens net
Context "context" modified.
Active namespace is "net".
[root@master net]#
[root@master net]#
测试镜像准备
如果有外网,直接在所有node节点都下载下面这个镜像
【因为我集群没有外网,所以我在有外网的主机上下载这个镜像,拷贝到集群的2个node节点上】
[root@ccx ~]# docker pull yauritux/busybox-curl
Using default tag: latest
latest: Pulling from yauritux/busybox-curl
8ddc19f16526: Pull complete
8fc23f4ea2fd: Pull complete
2c3b109dee57: Pull complete
Digest: sha256:e67b94a5abb6468169218a0940e757ebdfd8ee370cf6901823ecbf4098f2bb65
Status: Downloaded newer image for yauritux/busybox-curl:latest
docker.io/yauritux/busybox-curl:latest
[root@ccx ~]#
[root@ccx ~]# docker save yauritux/busybox-curl > busybox-curl.tar
[root@ccx ~]#
- 拷贝到master上了,下面放一下流程吧,回顾一下,注意看主机名
sftp> lcd C:\Users\Administrator\Desktop
sftp> cd /root/net/
sftp> put bu
busybox-curl.tar busybox.tar
sftp> put busybox
busybox-curl.tar busybox.tar
sftp> put busybox-curl.tar
Uploading busybox-curl.tar to /root/net/busybox-curl.tar
100% 21047KB 21047KB/s 00:00:00
C:/Users/Administrator/Desktop/busybox-curl.tar: 21552128 bytes transferred in 0 seconds (21047 KB/s)
sftp>
[root@master net]# scp busybox-curl.tar node1:/
root@node1's password:
busybox-curl.tar 100% 21MB 23.4MB/s 00:00
[root@master net]# scp busybox-curl.tar node2:/
root@node2's password:
busybox-curl.tar 100% 21MB 20.6MB/s 00:01
[root@master net]#
[root@node1 /]# docker load -i busybox-curl.tar
8ac8bfaff55a: Loading layer 1.293MB/1.293MB
dde6eb4e8fe0: Loading layer 10.23MB/10.23MB
1fb28a84ff8d: Loading layer 10.01MB/10.01MB
Loaded image: yauritux/busybox-curl:latest
[root@node1 /]# docker images | grep curl
yauritux/busybox-curl latest 69894251bd3c 4 years ago 21.3MB
[root@node1 /]
[root@node2 /]# docker load -i busybox-curl.tar
8ac8bfaff55a: Loading layer 1.293MB/1.293MB
dde6eb4e8fe0: Loading layer 10.23MB/10.23MB
1fb28a84ff8d: Loading layer 10.01MB/10.01MB
Loaded image: yauritux/busybox-curl:latest
[root@node2 /]# docker images | grep curl
yauritux/busybox-curl latest 69894251bd3c 4 years ago 21.3MB
[root@node2 /]
搭建一套svc出来
- 这个pod呢依然使用nginx的镜像,并且在index分别写入不同内容,便于后面测试看出区别
[root@master net]# cp ../svc/pod1.yaml .
[root@master net]# cat pod1.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
test: pod1
name: pod1
spec:
terminationGracePeriodSeconds: 0
containers:
- name: pod1
image: nginx
imagePullPolicy: IfNotPresent
[root@master net]# kubectl apply -f pod1.yaml
pod/pod1 created
[root@master net]#
[root@master net]# sed 's/pod1/pod2/' pod1.yaml | kubectl apply -f -
pod/pod2 created
[root@master net]#
[root@master net]# kubectl get pods
NAME READY STATUS RESTARTS AGE
pod1 1/1 Running 0 33s
pod2 1/1 Running 0 3s
[root@master net]#
[root@master net]# kubectl exec pod1 -- sh -c "echo 111 > /usr/share/nginx/html/index.html"
[root@master net]# kubectl exec pod2 -- sh -c "echo 222 > /usr/share/nginx/html/index.html"
[root@master net]#
- 为这2个pod分别创建svc
[root@master net]# kubectl expose --name=svc1 pod pod1 --port=80
service/svc1 exposed
[root@master net]# kubectl expose --name=svc2 pod pod2 --port=80
service/svc2 exposed
[root@master net]#
[root@master net]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc1 ClusterIP 10.106.121.18 <none> 80/TCP 9s
svc2 ClusterIP 10.98.5.155 <none> 80/TCP 3s
[root@master net]#
测试pod创建
- 现在命名空间是没有网络策略的
[root@master ~]# kubectl get networkpolicy
No resources found in net namespace.
[root@master ~]#
svc为ClusterIP类型
- 创建一个临时同命名空间的pod出来【当前在net命名空间】
curl之前的svc,现在是没有任何网络策略的情况下,是可以直接curl通外面的svc地址的
[root@master net]# kubectl run testpod --image=yauritux/busybox-curl:latest -it --rm --image-pull-policy=IfNotPresent -- sh
If you don't see a command prompt, try pressing enter.
/home #
/home #
/home # curl svc1
111
/home #
/home # curl svc2
222
/home #
- 创建一个临时但不同命名空间的pod出来【现在创建到default的命名空间中】
curl之前的svc,现在是没有任何网络策略的情况下,也是可以直接curl通外面的svc地址的
[root@master svc]# kubectl run testpod --image=yauritux/busybox-curl:latest -it --rm --image-pull-policy=IfNotPresent -n default -- sh
If you don't see a command prompt, try pressing enter.
/home #
/home # curl svc1.net
111
/home # curl svc2.net
222
/home #
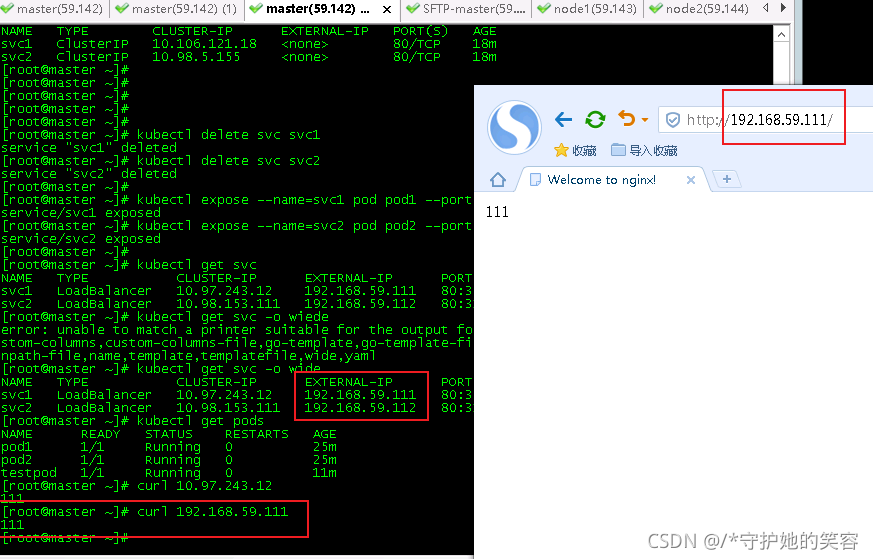
svc为LoadBalancer
- 注:我现在能正常创建Lb类型是因为我这个集群之前配置过Lb配置【如果你没配置,可以忽略这个测试,或者去我之前博客svc中跟着配置LB,再做这个测试】
[root@master ~]# kubectl expose --name=svc1 pod pod1 --port=80 --type=LoadBalancer
service/svc1 exposed
[root@master ~]# kubectl expose --name=svc2 pod pod2 --port=80 --type=LoadBalancer
service/svc2 exposed
[root@master ~]#
[root@master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
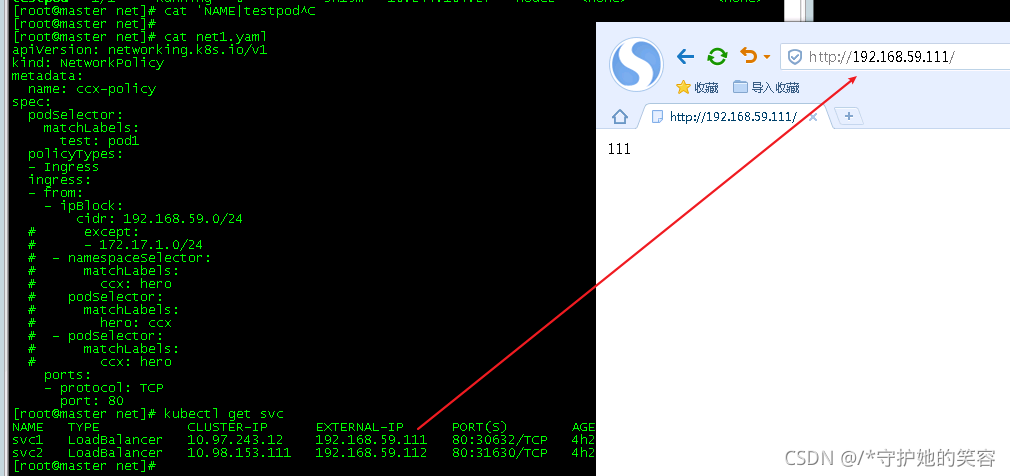
svc1 LoadBalancer 10.97.243.12 192.168.59.111 80:30632/TCP 10s
svc2 LoadBalancer 10.98.153.111 192.168.59.112 80:31630/TCP 4s
[root@master ~]#
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
pod1 1/1 Running 0 25m
pod2 1/1 Running 0 25m
testpod 1/1 Running 0 11m
[root@master ~]# curl 10.97.243.12
111
[root@master ~]# curl 192.168.59.111
111
[root@master ~]#
- 这样呢,我就可以直接在物理机浏览器中访问LB地址了
网络策略【Network Policy】【k8s的网络】
- 这个创建的流程可以在官网搜索的
networkpolicy
- 里面呢有一个模版代码,用图简单对这说明一下【下面会有详细说明的】

-简单来说,networkpolicy实际上就是防火墙。
概述
-
Kubernetes要求集群中所有pod,无论是节点内还是跨节点,都可以直接通信,或者说所有pod工作在同一跨节点网络,此网络一般是二层虚拟网络,称为pod网络。在安装引导kubernetes时,由选择并安装的network plugin实现。默认情况下,集群中所有pod之间、pod与节点之间可以互通。
-
网络主要解决两个问题,一个是连通性,实体之间能够通过网络互通。另一个是隔离性,出于安全、限制网络流量的目的,又要控制实体之间的连通性。Network Policy用来实现隔离性,只有匹配规则的流量才能进入pod,同理只有匹配规则的流量才可以离开pod。
-
但请注意,kubernetes支持的用以实现pod网络的network plugin有很多种,并不是全部都支持Network Policy,为kubernetes选择network plugin时需要考虑到这点,是否需要隔离?可用network plugin及是否支持Network Policy更多
可以参考这里
基本原理
- Network Policy是kubernetes中的一种资源类型,它从属于某个namespace。其内容从逻辑上看包含两个关键部分,一是pod选择器,基于标签选择相同namespace下的pod,将其中定义的规则作用于选中的pod。另一个就是规则了,就是网络流量进出pod的规则,其采用的是白名单模式,符合规则的通过,不符合规则的拒绝。
- 规则有2种
- ingress【进来的规则】
- Egress【出去的规则】
Network Policy对象Spec说明【yaml文件代码说明】
- 下面是官网的代码规则,并且一些基本的代码规则呢,官网也有说明。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
- 为了更方便的直观理解,我还是直接在官网代码里面做说明吧,注意看注释内容
apiVersion: networking.k8s.io/v1 #版本提示,一般不做修改
kind: NetworkPolicy # 类型
metadata:
name: test-network-policy #自定义一个policy名称
namespace: default #所属ns空间【一般需要修改为当前所在空间】
#【或者直接将namespace该行删除,也是默认当前ns空间】
spec:
podSelector:
matchLabels: # 标签控制,就是说需要对哪些pod生效
# 这放标签内容,对所有有该标签的pod生效
# 如果不放标签内容,则对所有pod生效
role: db #这个是标签内容哈
policyTypes:
- Ingress # 进规则启用 【可以和出规则二选一的哈】
- Egress # 出规则启用【可以和进规则二选一的哈】
ingress: # 定义进规则的模版【一般是下面3种方法选1个来定义】
- from:
- ipBlock: #1、 用ip的方式定义
cidr: 172.17.0.0/16 #拒绝许这个段的主机访问,如果不指定,则默认拒绝所有
except: #列外,就是允许下面的ip,如果拒绝所有,则这个可以不要
- 172.17.1.0/24
- namespaceSelector: #2、 用命名空间的方式定义
matchLabels:
project: myproject # 如果不指定,则默认对所有生效
- podSelector: #3、 用pod标签的方式定义【这个使用比较多】
matchLabels:
role: frontend # 如果不指定,则默认对所有生效
ports: #允许通过的端口类型和端口号
- protocol: TCP
port: 6379
egress: # 出规则定义
- to:
- ipBlock: # 这个用ip定义 ,除此之外也可以用上面入的方法
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
- 上面代码中做了简单说明,这呢,做详细说明
-
.spec.PodSelector
顾名思义,它是pod选择器,基于标签选择与Network Policy处于同一namespace下的pod,如果pod被选中,则对其应用Network Policy中定义的规则。此为可选字段,当没有此字段时,表示选中所有pod。 -
.spec.PolicyTypes
Network Policy定义的规则可以分成两种,一种是入pod的Ingress规则,一种是出pod的Egress规则。本字段可以看作是一个开关,如果其中包含Ingress,则Ingress部分定义的规则生效,如果是Egress则Egress部分定义的规则生效,如果都包含则全部生效。当然此字段也可选,如果没有指定的话,则默认Ingress生效,如果Egress部分有定义的话,Egress才生效。怎么理解这句话,下文会提到,没有明确定义Ingress、Egress部分,它也是一种规则,默认规则而非没有规则。 -
.spec.ingress与.spec.egress
前者定义入pod规则,后者定义出pod规则,详细参考这里,这里只讲一下重点。上例中ingress与egress都只包含一条规则,两者都是数组,可以包含多条规则。当包含多条时,条目之间的逻辑关系是“或”,只要匹配其中一条就可以。 -
.spec.ingress[].from
也是数组,数组成员对访问pod的外部source进行描述,符合条件的source才可以访问pod,有多种方法,如示例中的ip地址块、名称空间、pod标签等,数组中的成员也是逻辑或的关系。 -
.spec.ingress[].from.prots表示允许通过的协议及端口号。 -
.spec.egress.to
定义的是pod想要访问的外部destination,其它与ingress相同。
-
默认规则实例说明
- 不定义规则并非没有规则,此时默认规则生效,以下展示默认规则用法。
- 下面就是默认情况下的全部yaml文件代码,可以直接修改ns名称创建的哦。
默认禁止所有入pod流量(Default deny all ingress traffic)
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
spec:
podSelector: {}
policyTypes:
- Ingress
-
上例中没有定义pod选择器,表示如果namespace下的某个pod没有被任何Network Policy对象选中,则应用此对象,如果被其它Network Policy先中则不应用此对象。
-
policyTypes的值为Ingress,表示本例启用Ingress规则。但是本例没有定义具体的Ingress,那就应用默认规则。默认规则禁止所有入pod流量,但例外情况是如果source就是pod运行的节点,则允许通过。
默认允许所有入pod流量(Default allow all ingress traffic)
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all
spec:
podSelector: {}
ingress:
- {}
- 同样没有定义pod选择器,意义与上例同。注意ingress的定义,这个是有规则的,只是规则中的条目为空,与默认规则不同,表示全部允许通过。
默认禁止所有出pod流量(Default deny all egress traffic)
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
spec:
podSelector: {}
policyTypes:
- Egress
- 与默认禁止所有入pod流量(Default deny all ingress traffic)同,只是流量由入变成出
默认允许所有出pod流量(Default allow all egress traffic)
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all
spec:
podSelector: {}
egress:
- {}
policyTypes:
- Egress
- 与默认允许所有入pod流量(Default allow all ingress traffic)同,只是流量由入变成出。
默认禁止所有入出pod流量(Default deny all ingress and all egress traffic)
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
- 无需详解,但请注意,pod与所运行节点之间流量不受Network Policy限制。
实例测试【入规则】
- 注:此时,上面做测试用的所有内容都被保留,没有被删除。
查看现有pod标签
[root@master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod1 1/1 Running 0 35m test=pod1
pod2 1/1 Running 0 35m test=pod2
testpod 1/1 Running 0 21m run=testpod
[root@master ~]#
- 注,下面所有代码都是基于官网代码,然后在基础上做了操作罢了。
- 并且我现在的命名空间是:
net,这个在前面网络测试中的环境准备步骤也说明过了。
测试pod创建
我在当前命名空间和default空间分别创建了一个pod
[root@master net]# cat pod1.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
test: pod1
name: pod1
spec:
terminationGracePeriodSeconds: 0
containers:
- name: pod1
image: nginx
imagePullPolicy: IfNotPresent
[root@master net]#
[root@master net]# sed 's/pod1/testpod/' pod1.yaml | kubectl apply -f -
pod/testpod created
[root@master net]#
[root@master net]# sed 's/pod1/testpod2/' pod1.yaml | kubectl apply -f - -n default
pod/testpod2 created
[root@master net]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod1 1/1 Running 0 93m test=pod1
pod2 1/1 Running 0 92m test=pod2
testpod 1/1 Running 0 2m38s test=testpod
[root@master net]#
[root@master net]# kubectl get pods --show-labels -n default
NAME READY STATUS RESTARTS AGE LABELS
recycler-for-pv-nfs2 0/1 ImagePullBackOff 0 67d <none>
testpod2 1/1 Running 0 2m17s test=testpod2
[root@master net]#
然后新建2个会话窗口,分别进入这2个pod内部
[root@master svc]# kubectl exec -it testpod -- bash
root@testpod:/#
[root@master net]# kubectl exec -it -n default testpod2 -- bash
root@testpod2:/#
root@testpod2:/#
使用标签限制入规则
- 该规则是:yaml规则中只会对当前命名空间生效,所以通过标签限制了以后,其他命名空间就会全部被阻断了。【适用于让当前ns中的部分pod生效】
- 我这用pod1来做用标签限制测试,如果没有
ccx=hero这个标签的pod都不允许进来,因为镜像是nginx,所以端口也需要改为80
然后创建该规则,就可以看到多了一条pulicy规则了
[root@master net]# cat net1.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ccx-policy
spec:
podSelector:
matchLabels:
test: pod1 #pod1上才有的标签
policyTypes:
- Ingress
ingress:
- from:
# - ipBlock
# cidr: 172.17.0.0/16
# except:
# - 172.17.1.0/24
# - namespaceSelector:
# matchLabels:
# project: myproject
- podSelector:
matchLabels:
ccx: hero # 必须有这个标签的才能访问
ports:
- protocol: TCP
port: 80 #pod端口
[root@master net]#
[root@master net]# kubectl apply -f net1.yaml
networkpolicy.networking.k8s.io/ccx-policy created
[root@master net]#
[root@master net]# kubectl get networkpolicy
NAME POD-SELECTOR AGE
ccx-policy test=pod1 10s
[root@master net]#
- 测试
此时呢,我们进入到testpod的内部,就可以看到已经surl不同svc1了,会一直卡着,ctrl+c结束以后,访问svc2是正常的,因为我们规则只限制了pod1
[root@master svc]# kubectl get pods --show-labels | grep testpod
testpod 1/1 Running 0 7m38s test=testpod
[root@master svc]#
[root@master svc]# kubectl exec -it testpod -- bash
root@testpod:/#
root@testpod:/# curl -s svc1
^C
root@testpod:/#
root@testpod:/# curl -s svc2
222
root@testpod:/#
# 同理,default命名空间中也是一样的情况,都被阻断
[root@master net]# kubectl exec -it -n default testpod2 -- bash
root@testpod2:/# curl -s svc1
root@testpod2:/# curl -s svc1.net
^C
root@testpod2:/# curl -s svc2.net
222
root@testpod2:/#
- 对testpod添加
ccx=hero标签再次测试
结果是:同命名空间的容器能访问svc1了,但default的pod依然无法访问svc1
[root@master net]# kubectl label pod testpod ccx=hero
pod/testpod labeled
[root@master net]# kubectl label pod testpod2 -n default ccx=hero
pod/testpod2 labeled
[root@master net]#
[root@master net]# kubectl get pods --show-labels | grep testpod
testpod 1/1 Running 0 11m ccx=hero,test=testpod
[root@master net]#
[root@master net]# kubectl get pods --show-labels -n default | grep testpod
testpod2 1/1 Running 0 11m ccx=hero,test=testpod2
[root@master net]#
# 因为我一直在容器内部,所以就直接测试了
# 当前命名空间是通的
root@testpod:/# curl -s svc1
111
root@testpod:/#
# default空间不通
root@testpod2:/# curl -s svc1.net
^C
root@testpod2:/#
通过命名空间限制入规则
-
该规则是:只要命名空间有这个标签,那么该命名空间下的所有pod都默认通【适用于以ns为单位的场景使用】
-
如我现在只允许有
ccx=hero的命名空间访问svc1,然后在default的空间中增加该标签
注:netwrokpublicy是可以直接覆盖创建规则的,所以不用删除直接的规则
[root@master net]# cat net1.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ccx-policy
spec:
podSelector:
matchLabels:
test: pod1
policyTypes:
- Ingress
ingress:
- from:
# - ipBlock
# cidr: 172.17.0.0/16
# except:
# - 172.17.1.0/24
- namespaceSelector:
matchLabels:
ccx: hero
# - podSelector:
# matchLabels:
# ccx: hero
ports:
- protocol: TCP
port: 80
[root@master net]#
[root@master net]# kubectl apply -f net1.yaml
networkpolicy.networking.k8s.io/ccx-policy configured
[root@master net]# kubectl get networkpolicy
NAME POD-SELECTOR AGE
ccx-policy test=pod1 18m
[root@master net]# kubectl label ns default ccx=hero
namespace/default labeled
- 现在去测试
正常情况 default上能curlsvc1了,但同命名空间的不能访问了,因为没有这个标签
#default空间通
root@testpod2:/# curl -s svc1.net
111
root@testpod2:/#
# 同名名空间不通
root@testpod:/# curl -s svc1
^C
root@testpod:/#
- 现在给当前命名空间也加上这个标签再次测试吧
[root@master net]# kubectl label ns net ccx=hero
namespace/net labeled
[root@master net]#
root@testpod:/# curl -s svc1
111
root@testpod:/#
- 两个命名空间都通了,因为2个命名空间都有这个标签
[root@master net]# kubectl get ns --show-labels | egrep -w 'net|default'
default Active 119d ccx=hero,kubernetes.io/metadata.name=default
net Active 4h27m ccx=hero,kubernetes.io/metadata.name=net
[root@master net]#
通过命名空间和标签限制入规则
- 很明显,该规则是结合使用上面2个,所以作用呢就是:允许某个ns中含有特定标签的pod访问
- 如:我现在只允许含有
ccx=hero的命名空间下含有hero=ccx的pod访问
注:netwrokpublicy是可以直接覆盖创建规则的,所以不用删除直接的规则
[root@master net]# cat net1.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ccx-policy
spec:
podSelector:
matchLabels:
test: pod1
policyTypes:
- Ingress
ingress:
- from:
# - ipBlock
# cidr: 172.17.0.0/16
# except:
# - 172.17.1.0/24
- namespaceSelector:
matchLabels:
ccx: hero #命名空间标签
podSelector:
matchLabels:
hero: ccx #命名空间下的pod标签
# - podSelector:
# matchLabels:
# ccx: hero
ports:
- protocol: TCP
port: 80
[root@master net]# kubectl apply -f net1.yaml
networkpolicy.networking.k8s.io/ccx-policy configured
[root@master net]# kubectl get networkpolicy
NAME POD-SELECTOR AGE
ccx-policy test=pod1 170m
[root@master net]#
- 现在呢,当前ns和default的ns中pod都没有
hero=ccx的标签,所以现在2个测试pod都无法访问svc1
[root@master net]# kubectl get ns --show-labels | egrep -w 'net|default'
default Active 119d ccx=hero,kubernetes.io/metadata.name=default
net Active 4h38m ccx=hero,kubernetes.io/metadata.name=net
[root@master net]#
[root@master net]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod1 1/1 Running 0 4h30m test=pod1
pod2 1/1 Running 0 4h29m test=pod2
testpod 1/1 Running 0 179m ccx=hero,test=testpod
[root@master net]# kubectl get pods --show-labels -n default
NAME READY STATUS RESTARTS AGE LABELS
recycler-for-pv-nfs2 0/1 ImagePullBackOff 0 67d <none>
testpod2 1/1 Running 0 179m ccx=hero,test=testpod2
[root@master net]#
#当前ns
root@testpod:/# curl -s svc1
^C
root@testpod:/#
#default的ns
root@testpod2:/# curl -s svc1.net
^C
root@testpod2:/#
- 现在呢,我们给这2个命名空间下的2个测试pod都加上
hero=ccx这个标签,再次测试
[root@master net]# kubectl label pod testpod hero=ccx
pod/testpod labeled
[root@master net]# kubectl label pod testpod2 -n default hero=ccx
pod/testpod2 labeled
[root@master net]#
[root@master net]# kubectl get pods --show-labels | grep hero=ccx
testpod 1/1 Running 0 3h2m ccx=hero,hero=ccx,test=testpod
[root@master net]#
[root@master net]# kubectl get pods --show-labels -n default | grep hero=ccx
testpod2 1/1 Running 0 3h2m ccx=hero,hero=ccx,test=testpod2
[root@master net]#
#当前ns
root@testpod:/# curl -s svc1
111
root@testpod:/#
# default的ns
root@testpod2:/# curl -s svc1.net
111
root@testpod2:/#
通过IP限制入规则
- 该规则就是:拒绝定义的网段访问,包含集群外的主机【注意,如果我们限制了主机的网段,虽然pod的ip一般不是主机网段,但也会被限制】
[root@master net]# cat net1.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ccx-policy
spec:
podSelector:
matchLabels:
test: pod1
policyTypes:
- Ingress
ingress:
- from:
- ipBlock:
cidr: 192.168.59.0/24 #拒绝该网段
# except: #允许列外
# - 172.17.1.0/32 #单个ip一般用32位掩码
# - namespaceSelector:
# matchLabels:
# ccx: hero
# podSelector:
# matchLabels:
# hero: ccx
# - podSelector:
# matchLabels:
# ccx: hero
ports:
- protocol: TCP
port: 80
[root@master net]#
[root@master net]# kubectl get networkpolicy
NAME POD-SELECTOR AGE
ccx-policy test=pod1 3h8m
[root@master net]#
- 如,我当前是59网段的ip,是无法访问svc1内容了,并且ns中的testpod的ip虽然是10.244.104段的,但也是无法访问的
[root@master net]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod1 1/1 Running 0 4h46m 10.244.104.31 node2 <none> <none>
pod2 1/1 Running 0 4h45m 10.244.104.32 node2 <none> <none>
testpod 1/1 Running 0 3h15m 10.244.104.27 node2 <none> <none>
[root@master net]# kubectl get pods -o wide | egrep 'NAME|testpod'
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
testpod 1/1 Running 0 3h15m 10.244.104.27 node2 <none> <none>
[root@master net]#
[root@master net]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc1 LoadBalancer 10.97.243.12 192.168.59.111 80:30632/TCP 4h39m
svc2 LoadBalancer 10.98.153.111 192.168.59.112 80:31630/TCP 4h39m
[root@master net]#
[root@master net]# ip a | grep 59
inet 192.168.59.142/24 brd 192.168.59.255 scope global noprefixroute ens33
#同网段已经被现在访问svc1了
[root@master net]#
[root@master net]# curl -s 192.168.59.111
^C
[root@master net]#
[root@master net]# curl -s 192.168.59.112
222
[root@master net]#
#容器内
root@testpod:/# curl -s svc1
^C
root@testpod:/#
但是呢,现在还是可以在外面使用浏览器访问到59段这个ip内容的【因为物理机(集群虚机所属的主机)是不会被限制的】
- 如:我现在禁止所有59段的ip访问pod1,但是允许59.143访问pod1
[root@master net]# cat net1.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ccx-policy
spec:
podSelector:
matchLabels:
test: pod1
policyTypes:
- Ingress
ingress:
- from:
- ipBlock:
cidr: 192.168.59.0/24
except:
- 192.168.59.143/32
# - namespaceSelector:
# matchLabels:
# ccx: hero
# podSelector:
# matchLabels:
# hero: ccx
# - podSelector:
# matchLabels:
# ccx: hero
ports:
- protocol: TCP
port: 80
[root@master net]#
- 测试,看是否其他所有59段不能访问,只有59.143可以访问
[root@master net]# kubectl apply -f net1.yaml
networkpolicy.networking.k8s.io/ccx-policy created
[root@master net]#
[root@master net]# curl 192.168.59.111
^C
[root@master net]#
# 去59.143的主机上测试
[root@node1 /]# ip a | grep 59
inet 192.168.59.143/24 brd 192.168.59.255 scope global noprefixroute ens33
7: cali80b7a593152@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP group default
[root@node1 /]#
[root@node1 /]# curl -s 192.168.59.111
111
[root@node1 /]# curl -s 192.168.59.112
222
[root@node1 /]#
- 总结:我发现一个问题,这个玩意限制好像不太好使,只有第一次配置的时候和预期一样,但中途修改的话,这个限制就和预期不一样了,也不知道是不是缓存的原因。
但是这个玩意挺厉害的,之前的两种方法主要是针对集群内嘛,但这个ip可以限制所有,就是集群外的ip也可以限制
实例测试【出规则】
创建一个测试pod
[root@master net]# sed 's/pod1/nginx1/' pod1.yaml | kubectl apply -f -
[root@master net]# kubectl exec nginx1 -- sh -c "echo 333 > /usr/share/nginx/html/index.html"
[root@master net]# kubectl expose --name=svc3 pod nginx1 --port=80
[root@master net]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc1 LoadBalancer 10.97.243.12 192.168.59.111 80:30632/TCP 5h45m
svc2 LoadBalancer 10.98.153.111 192.168.59.112 80:31630/TCP 5h45m
svc3 ClusterIP 10.98.121.94 <none> 80/TCP 40m
[root@master net]#
通过标签限制出规则
- 该规则是:yaml规则中只会对当前命名空间生效,所以通过标签限制了以后,其他命名空间就会全部被阻断了。【适用于让当前ns中的部分pod生效】
- 如,我对pod1做限制,只允许出到有
test=nginx1的pod,并且只有80端口可以出。
[root@master net]# cat net2.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ccx-policy
spec:
podSelector:
matchLabels:
test: pod1 #对pod1做i限制
policyTypes:
- Egress
egress:
- to:
- podSelector:
matchLabels:
test: nginx1 #只允许出到有这个标签的pod
# - ipBlock:
# cidr: 192.168.59.0/24
# except:
# - 192.168.59.143/32
ports:
- protocol: TCP
port: 80 #只允许出80端口
[root@master net]#
[root@master net]# kubectl apply -f net2.yaml
networkpolicy.networking.k8s.io/ccx-policy configured
[root@master net]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx1 1/1 Running 0 39m
pod1 1/1 Running 0 6h5m
pod2 1/1 Running 0 6h5m
testpod 1/1 Running 0 4h34m
[root@master net]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc1 LoadBalancer 10.97.243.12 192.168.59.111 80:30632/TCP 5h42m
svc2 LoadBalancer 10.98.153.111 192.168.59.112 80:31630/TCP 5h42m
svc3 ClusterIP 10.98.121.94 <none> 80/TCP 37m
- 进入到pod1的容器内部测试
这呢,我们可以看到通过svc全部无法访问,而通过svcIP呢,我们确实是只有svc3可以出,其他出不了【解决方法看下面标签和命名空间使用】
[root@master net]# kubectl exec -it pod1 -- bash
root@pod1:/#
root@pod1:/# curl svc1
^C
root@pod1:/# curl svc2
^C
root@pod1:/# curl svc3
^C
root@pod1:/# curl 10.98.121.94
333
root@pod1:/# curl 10.98.153.111
^C
root@pod1:/#
- 只有ip能出是因为策略中我们只放开了80端口,而使用svc名称,不属于80端口,所以被拒绝了
通过命名空间限制出规则
这个和入是一样的逻辑,吧ns限制的代码嵌入上面一个就行,我这不单独做测试了【下面有一起使用的】
通过命名空间和标签限制出规则【解决svc名称不能出】
-
就是解决这个
别问为什么,照下面做能解决就是了!!!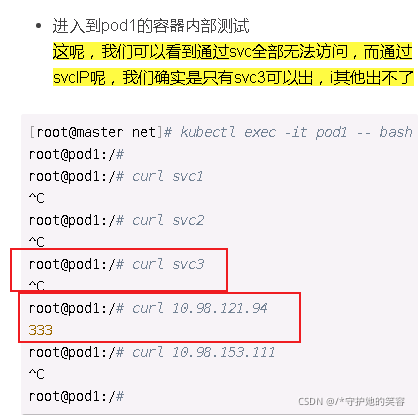
-
先给下面这个命名空间增加一行信息
[root@master net]# kubectl get ns --show-labels | grep kube-system
kube-system Active 119d kubernetes.io/metadata.name=kube-system
[root@master net]#
[root@master net]# kubectl label ns kube-system name=kube-system
namespace/kube-system labeled
[root@master net]#
- 编辑yaml文件【也就是增加一条ns限制】
[root@master net]#
[root@master net]# cat net2.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ccx-policy
spec:
podSelector:
matchLabels:
test: pod1 #对这个做策略
policyTypes:
- Egress
egress:
- to:
- podSelector:
matchLabels:
test: nginx1 # pod标签
- namespaceSelector:
matchLabels:
name: kube-system #ns标签【我们在控制器上创建了这个标签】
# - ipBlock:
# cidr: 192.168.59.0/24
# except:
# - 192.168.59.143/32
ports:
- protocol: TCP
port: 80
- protocol: UDP #是为了svc名称能出的类型和端口
port: 53
[root@master net]#
[root@master net]# kubectl apply -f net2.yaml
networkpolicy.networking.k8s.io/ccx-policy configured
[root@master net]#
- 现在再次测试,诶,正常了。
[root@master net]# kubectl exec -it pod1 -- bash
root@pod1:/#
root@pod1:/# curl svc2
^C
root@pod1:/#
root@pod1:/# curl svc3
333
root@pod1:/#
root@pod1:/# curl 10.98.121.94
333
root@pod1:/#
通过IP限制入规则
- 现在集群的任意主机上安装httpd服务并且启动并且随便写入内容,并且能访问到该内容
[root@node1 /]# ip a | grep 143
inet 192.168.59.143/24 brd 192.168.59.255 scope global noprefixroute ens33
[root@node1 /]# yum -y install httpd
[root@node1 /]# systemctl restart httpd
[root@node1 /]# cd /var/www/html/
[root@node1 html]# ls
[root@node1 html]# echo 192.168.59.143> index.html
[root@node1 html]# curl 192.168.59.143
192.168.59.143
[root@node1 html]#
[root@node1 html]# netstat -ntlp | grep 80
tcp6 0 0 :::80 :::* LISTEN 6494/httpd
[root@node1 html]#
[root@node1 html]#
- 然后进入一个没有配置规则的容器内部,看是否能curl通这个地址【通为正常】
[root@master svc]# kubectl exec -it testpod -- bash
root@testpod:/# curl 192.168.59.143
192.168.59.143
root@testpod:/#
- 编辑yaml文件,并生成该规则
[root@master net]# cat net2.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ccx-policy
spec:
podSelector:
matchLabels:
test: pod1
policyTypes:
- Egress
egress:
- to:
# - podSelector:
# matchLabels:
# test: nginx1
# - namespaceSelector:
# matchLabels:
# name: kube-system
- ipBlock:
cidr: 192.168.59.0/24 #允许出到这个段
ports:
- protocol: TCP
port: 80 #这个端口
# - protocol: UDP
# port: 53
[root@master net]# kubectl apply -f net2.yaml
networkpolicy.networking.k8s.io/ccx-policy configured
[root@master net]#
- 测试
和预期一样,没问题
[root@master net]# kubectl exec -it pod1 -- bash
root@pod1:/# curl 192.168.59.143
192.168.59.143
root@pod1:/#
root@pod1:/#
- 上面是集群内的,我按上面方法配置了一个集群外的ip,发现也是可以正常访问的,就是说,这个策略对集群外的ip生效
[root@etcd2 ~]# cd /var/www/html/
[root@etcd2 html]# echo 192.168.59.157> index.html
[root@etcd2 html]# ip a | grep 59
inet 192.168.59.157/24 brd 192.168.59.255 scope global ens32
[root@etcd2 html]# systemctl restart httpd
[root@etcd2 html]#
#pod1内
[root@master net]# kubectl exec -it pod1 -- bash
root@pod1:/# curl 192.168.59.143
192.168.59.143
root@pod1:/#
root@pod1:/# curl 192.168.59.157
192.168.59.157
root@pod1:/#
- 为了证实逻辑没问题,我们现在在配置文件中将59改了,再测试,看是否不通了
[root@master net]# cat net2.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ccx-policy
spec:
podSelector:
matchLabels:
test: pod1
policyTypes:
- Egress
egress:
- to:
# - podSelector:
# matchLabels:
# test: nginx1
# - namespaceSelector:
# matchLabels:
# name: kube-system
- ipBlock:
cidr: 192.168.5.0/24
ports:
- protocol: TCP
port: 80
# - protocol: UDP
# port: 53
[root@master net]# kubectl apply -f net2.yaml
networkpolicy.networking.k8s.io/ccx-policy configured
[root@master net]#
# 确实不通了,没问题
root@pod1:/# curl 192.168.59.157
^C
root@pod1:/#
root@pod1:/# curl 192.168.59.143
^C
root@pod1:/#
- 至此,网络内容就完毕了,删除所有pod,svc和policy吧
[root@master net]#
[root@master net]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx1 1/1 Running 0 108m
pod1 1/1 Running 0 7h15m
pod2 1/1 Running 0 7h14m
testpod 1/1 Running 0 5h44m
[root@master net]# kubectl delete pod pod1
pod "pod1" deleted
[root@master net]# kubectl delete pod pod2
pod "pod2" deleted
[root@master net]# kubectl delete pod testpod
pod "testpod" deleted
[root@master net]# kubectl delete pod nginx1
pod "nginx1" deleted
[root@master net]#
[root@master net]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc1 LoadBalancer 10.97.243.12 192.168.59.111 80:30632/TCP 6h52m
svc2 LoadBalancer 10.98.153.111 192.168.59.112 80:31630/TCP 6h52m
svc3 ClusterIP 10.98.121.94 <none> 80/TCP 107m
[root@master net]#
[root@master net]# kubectl delete svc svc1
service "svc1" deleted
[root@master net]# kubectl delete svc svc2
service "svc2" deleted
[root@master net]# kubectl delete svc svc3
service "svc3" deleted
[root@master net]#
[root@master net]# kubectl get networkpolicy
NAME POD-SELECTOR AGE
ccx-policy test=pod1 89m
[root@master net]# kubectl delete networkpolicy ccx-policy
networkpolicy.networking.k8s.io "ccx-policy" deleted
[root@master net]#
编写网络策略说明
下面内容是我在网上找的资料,有点多,感觉内容太多反而容易把人混淆,所以,建议,下面内容过一遍就行,不用刻意去了解她,上面代码已经做了很简单但详细的介绍,感觉够用了!
使用方法
- 与其他Kubernetes资源一样,网络策略可以使用一种称为YAML的语言定义。下面是一个简单的例子,它允许从负载均衡到postgres的访问。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default.postgres
namespace: default
spec:
podSelector:
matchLabels:
app: postgres
ingress:
- from:
- podSelector:
matchLabels:
app: balance
policyTypes:
- Ingress
-
为了编写你自己的网络策略,你需要对yaml有基本的了解。Yaml基于缩进(使用的是空格,而不是tab)。缩进项属于其上方最接近的缩进项。连字符(破折号)开始一个新的列表项。所有其他项都是映射条目。你可以在网上找到大量关于yaml的信息。
-
编写完策略的YAML文件后,使用kubectl创建策略:
kubectl create -f policy.yaml
网络策略定义
-
网络策略定义由四个元素组成:
- podSelector:将受此策略约束的pod(策略目标)。必填
- policyType:指定哪些类型的策略包含在这个策略中,ingress或egress。该项是可选的,但建议总是明确的指定它。可选
- ingress:允许传入目标pod的流量。可选
- egress:允许从目标pod传出的流量。可选
-
下面这个例子是从Kubernetes官网上改编的(将“role”改为了“app”),它指定了四个元素:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
app: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
-
注意,你不必包含所有四个元素。podSelector是必填的,其余三个是可选的。
-
如果你忽略了policyType,则推断如下:
- 策略总是被认为指定了一个ingress定义。如果你没有明确的定义它,它将被视为“不允许流量“。
- egress将由是否存在egress元素诱导。
- 为了避免错误,建议总是显式的指定policyType。
-
如果没有提供ingress或egress的定义,并且根据上面的逻辑假定它们存在,策略将认为它们是“不允许流量”。
默认策略是允许
- 当没有定义任何策略时,Kubernetes允许所有通信。所有pod都可以相互自由通信。从安全角度来看,这听起来可能有悖常理,但请记住,Kubernetes是由希望应用程序进行通信的开发人员设计的。网络策略是作为后来的增强功能添加的。
命名空间
-
命名空间是Kubernetes的多租户机制,旨在将命名空间环境相互隔离,但是,命名空间的通信在默认情况下仍然是被允许的。
-
与大多数Kubernetes实体一样,网络策略也位于特定的命名空间中。元数据头部告诉Kubernetes策略属于哪个命名空间:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: my-namespace
spec:
...
- 如果你没有明确指定元数据的命名空间,它将应用于kubectl提供的命名空间(默认是namespace=default)。
kubectl apply -n my-namespace -f namespace.yaml
-
建议显式指定命名空间,除非你正在编写的策略要统一应用在多个命名空间中。
-
策略中的podSelector元素将从策略所属的命名空间中选择pod(它不能从另一个命名空间选择pod)。
-
ingress和egress元素中的podSelector也会选择相同命名空间中的pod,除非你将它们和namespaceSelector一起使用。
策略命名约定
-
策略的名称在命名空间中是唯一的。一个命名空间中不能有两个同名的策略,但是不同的命名空间可以有同名的策略。当你想要在多个命名空间重复应用某个策略时,这非常方便。
-
我喜欢的策略命名方法之一是将命名空间与pod组合起来,例如:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default.postgres
namespace: default
spec:
podSelector:
matchLabels:
app: postgres
ingress:
- from:
- podSelector:
matchLabels:
app: admin
policyTypes:
- Ingress
标签
- Kubernetes对象,如pod和namespace,可以附加用户自定义标签。Kubernetes网络策略依赖于标签来选择它们应用于的pod:
podSelector:
matchLabels:
role: db
- 或者它们应用于的命名空间。下面的例子中选择匹配标签的命名空间中的所有pod:
namespaceSelector:
matchLabels:
project: myproject
- 需要注意的一点是:如果你使用namespaceSelector,请确保所选择的命名空间确实具有所使用的标签。请记住,像default和kube-system这样的内置命名空间没有现成的标签。你可以像这样给命名空间添加一个标签:
kubectl label namespace default namespace=default
- 元数据中的namespace是命名空间的实际名称,而不是标签:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
...
源和终点
- 防火墙策略由具有源和终点的规则组成。Kubernetes网络策略是为目标(应用策略的一组pod)定义的,然后为目标指定传入或传出流量。再次使用相同的例子,你可以看到策略目标——默认命名空间中所有具有标签为“db:app”的pod:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
app: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
- 该策略中的ingress项允许到目标pod的传入流量。因此,ingress被解释为“源”,目标被解释为各自的“终点”。同样,egress被解释为“终点”,目标是各自的“源”。
Egress和DNS
- 当执行egress时,必须小心不要阻止DNS,Kubernetes使用DNS将service的名称解释为其IP地址。否则,这个策略将不起作用,因为你没有允许balance执行DNS查找:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default.balance
namespace: default
spec:
podSelector:
matchLabels:
app: balance
egress:
- to:
- podSelector:
matchLabels:
app: postgres
policyTypes:
- Egress
- 要解决它,你必须允许访问DNS服务:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default.balance
namespace: default
spec:
podSelector:
matchLabels:
app: balance
egress:
- to:
- podSelector:
matchLabels:
app: postgres
- to:
ports:
- protocol: UDP
port: 53
policyTypes:
- Egress
-
“to”元素为空,它隐式选择了所有命名空间中的所有pod,从而允许balance通过Kubernetes的DNS服务执行DNS查找,DNS服务通常位于kube-system命名空间中。
-
虽然这是有效的,但它过于宽松和不安全——它允许在集群外部进行DNS查找。
-
你可以分阶段锁定它:
- 1.通过添加一个namespaceSelector只允许在集群内进行DNS查找:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default.balance
namespace: default
spec:
podSelector:
matchLabels:
app: balance
egress:
- to:
- podSelector:
matchLabels:
app: postgres
- to:
- namespaceSelector: {}
ports:
- protocol: UDP
port: 53
policyTypes:
- Egress
- 2.只允许DNS在kube-system命名空间中
为此,你需要为kube-system命名空间添加一个标签:
kubectl label namespace kube-system namespace=kube-system
然后用namespaceSelector在策略中指定它:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default.balance
namespace: default
spec:
podSelector:
matchLabels:
app: balance
egress:
- to:
- podSelector:
matchLabels:
app: postgres
- to:
- namespaceSelector:
matchLabels:
namespace: kube-system
ports:
- protocol: UDP
port: 53
policyTypes:
- Egress
- 3.偏执狂可能想更进一步,将DNS限制为kube-system命名空间中特定的DNS服务。请参考下面的“通过命名空间和pod过滤”章节。
另一种选择是在命名空间级别允许DNS,这样就不需要为每个服务指定它了:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default.dns
namespace: default
spec:
podSelector: {}
egress:
- to:
- namespaceSelector: {}
ports:
- protocol: UDP
port: 53
policyTypes:
- Egress
空的podSelector选择该命名空间中的所有pod。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











