







Clustering by fast search and find of density
-这是science 上2014年5月的一篇文章,主要的思想就是聚类中心点的选择。
在kmeans的方法中,我们随机生成种子点进行迭代。此方法是先用密度峰值来确定聚类中心,确定聚类中心之后,得到距离近的点为同一类。
此方法有两个计算的要点
- 局部密度

- 与高密度点的距离

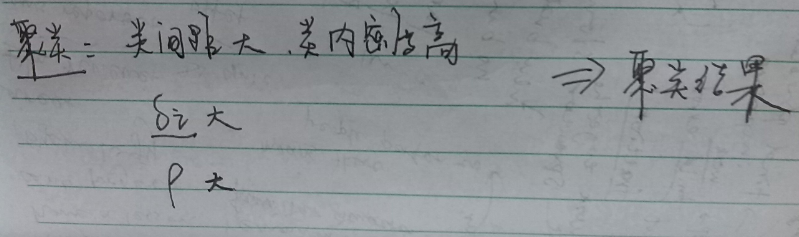
- matlab实现
clear;clc;
cluster = 3;
center = 50*randn(3,2);
dcc = 10;
numOfpoint = 300;
for i = 1:numOfpoint
centerindex = randperm(3,1);
centerx = center(centerindex,1);
centery = center(centerindex,2);
theta = rand(1)*2*pi;
radius = dcc*rand(1);
point(i,1) = centerx + radius*cos(theta);
point(i,2) = centery + radius*sin(theta);
end
plot(center(:,1),center(:,2),'r*')
hold on
plot(point(:,1),point(:,2),'bo')
P = [center; point];
distance = zeros(size(P,1));
% first compute distance of each pair
for i = 1:size(P,1)
for j = i+1:size(P,1)
distance(i,j) = sqrt(sum((P(i,:)-P(j,:)).^2));
distance(j,i) = distance(i,j);
end
end
% compute local density of every point
for i = 1:size(P,1)
density(i,1) = length(find(distance(i,:)<dcc))-1;
end
%compute delta
maxdensity = find(density == max(density));
for i = 1:size(P,1)
tempindex = find(density>density(i));
if ~isempty(tempindex)
delta(i,1) = min(distance(i,tempindex));
else
delta(i,1) = max(distance(i,:));
end
end
figure
plot(density,delta,'ro')














 2136
2136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









