







在接口测试时(Post)需要传入参数:
但参数较多时,如果每次都创建,那非常不方便,且不灵活,为了便于维护,将输入参数在Excel中维护,灵活多变:
直入主题:
Excel参数如下(由于公司安全考虑,字段参数都会打码):
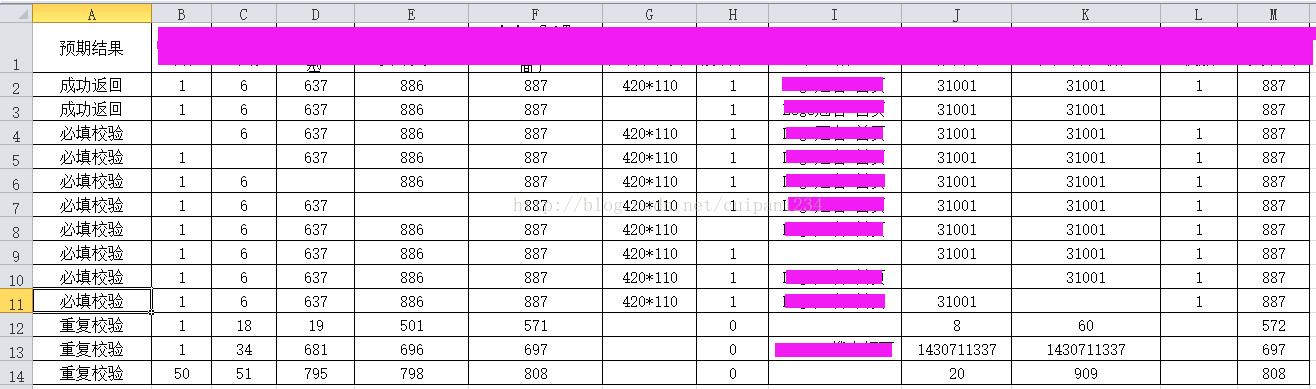
我们的接口传参有12个参数,个别类型有13个参数(多出来这一个通过脚本判断,这里不讲)
PS:
左侧第一列,是我单独加的一列,通过读出第一列的值,判断走哪个循环,进行校验
Excel中设置 有的非必填项为空,有的必填项为空
有人会说:你上面的数据为什么都是重复的呢(这是因为每次新增如果成功以后,会有数据回收机制,也就是进行判断将他删除)
以下是读Excel的步骤:
read_myExcel
#######读Excel文件,并保存为list
open_Excel ${path}\\read_Position_SSP.xls
${count_row_sheet1} get_row_count mytext_filename #get_row_count/get_column_count 获取文本行/列数
${Excel_Param_list} Create_list
: FOR ${x} IN RANGE ${count_row_sheet1 -1} #读取Count-1次(不读取第一行)
\ ${read_row_sheet1} Get_Row_Values mytext_filename ${x+1} #mytext_filename是Excel的sheet名,1代表Excel的第一行,读完${read_column_sheet1_A}是一个list
\ Set_suite_variable ${read_row_sheet1}
\ 处理每行为一个list
\ Insert_Into_List ${Excel_Param_list} ${x} ${row_list}
${count_Excel_Param_list} Evaluate len(${Excel_Param_list})
Set_Suite_Variable ${count_Excel_Param_list}
Set_Suite_Variable ${Excel_Param_list}
log ${Excel_Param_list}
不读取第一行,第一行是参数对应的字段行,所以循环时候给循环次数 -1
For的第1行:从${x+1}行开始读取,也就初始是从第一行开始读(Excel从第0行开始)
For的第3行:"处理每行为一个list"关键字,处理完后是个list:${row_list},下文会详细讲(作用:每次读一行以后把该行转为list)
For的第4行:将读到的该行插入到预设的list ${Excel_Param_list}中&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5994
5994











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









