





redshift命令翻译
This article was originally published by TeamSQL. Thank you for supporting the partners who make SitePoint possible.
本文最初由TeamSQL发布。 感谢您支持使SitePoint成为可能的合作伙伴。
Importing a large amount of data into Redshift is easy using the COPY command. To demonstrate this, we’ll import the publicly available dataset “Twitter Data for Sentiment Analysis” (see Sentiment140 for additional information).
使用COPY命令很容易将大量数据导入Redshift。 为了证明这一点,我们将导入公开可用的数据集“用于情感分析的Twitter数据”(有关其他信息,请参见Sentiment140 )。
Note: You can connect to AWS Redshift with TeamSQL, a multi-platform DB client that works with Redshift, PostgreSQL, MySQL & Microsoft SQL Server and runs on Mac, Linux and Windows. You can download TeamSQL for free.
注意 :您可以使用TeamSQL连接到AWS Redshift,TeamSQL是一个多平台数据库客户端,可与Redshift,PostgreSQL,MySQL和Microsoft SQL Server一起使用,并在Mac,Linux和Windows上运行。 您可以免费下载TeamSQL 。
Download the ZIP file containing the training data here.
在此处下载包含训练数据的ZIP文件。
红移集群 (The Redshift Cluster)
For the purposes of this example, the Redshift Cluster’s configuration specifications are as follows:
就本示例而言,Redshift Cluster的配置规范如下:
Cluster Type: Single Node
集群类型 :单节点
Node Type: dc1.large
节点类型 :dc1.large
Zone: us-east-1a
区域 :us-east-1a
在Redshift中创建数据库 (Create a Database in Redshift)
Run the following command to create a new database in your cluster:
运行以下命令在集群中创建新数据库:
CREATE DATABASE sentiment;在情感数据库中创建模式 (Create a Schema in the Sentiment Database)
Run the following command to create a scheme within your newly-created database:
运行以下命令以在新创建的数据库中创建方案:
CREATE SCHEMA tweets;训练数据的架构(结构) (The Schema (Structure) of the Training Data)
The CSV file contains the Twitter data with all emoticons removed. There are six columns:
CSV文件包含已删除所有表情的Twitter数据。 有六列:
- The polarity of the tweet (key: 0 = negative, 2 = neutral, 4 = positive) 鸣叫的极性(键:0 =否,2 =中性,4 =正)
- The id of the tweet (ex. 2087) 鸣叫的ID(例如2087)
- The date of the tweet (ex. Sat May 16 23:58:44 UTC 2009) 鸣叫日期(例如,UTC 2009年5月16日星期六23:58:44)
- The query (ex. lyx). If there is no query, then this value is NO_QUERY. 查询(例如lyx)。 如果没有查询,则此值为NO_QUERY。
- The user that tweeted (ex. robotickilldozr) 发推文的用户(例如robotickilldozr)
- The text of the tweet (ex. Lyx is cool) 推文的文字(例如,Lyx很酷)
创建训练数据表 (Create a Table for Training Data)
Begin by creating a table in your database to hold the training data. You can use the following command:
首先在数据库中创建一个表以保存训练数据。 您可以使用以下命令:
CREATE TABLE tweets.training (
polarity int,
id BIGINT,
date_of_tweet varchar,
query varchar,
user_id varchar,
tweet varchar(max)
)将CSV文件上传到S3 (Uploading CSV File to S3)
To use Redshift’s COPY command, you must upload your data source (if it’s a file) to S3.
要使用Redshift的COPY命令,必须将数据源(如果是文件)上传到S3。
To upload the CSV file to S3:
要将CSV文件上传到S3:
Unzip the file you downloaded. You’ll see 2 CSV files: one is test data (used to show structure of original dataset), and the other (file name: training.1600000.processed.noemoticon) contains the original data. We will upload and use the latter file.
解压缩下载的文件 。 您将看到2个CSV文件:一个是测试数据(用于显示原始数据集的结构),另一个(文件名:training.1600000.processed.noemoticon)包含原始数据。 我们将上传并使用后一个文件。
Compress the file. If you’re using macOS or Linux, you can compress the file using GZIP by running the following command in Terminal:
gzip training.1600000.processed.noemoticon.csv压缩文件 。 如果您使用的是macOS或Linux,则可以通过在终端中运行以下命令来使用GZIP压缩文件:
gzip training.1600000.processed.noemoticon.csv- Upload your file using the AWS S3 Dashboard. 使用AWS S3仪表板上传文件。
Alternatively, you can use Terminal/Command Line to upload your file. To do this, you must install AWS CLI and, after installation, configure it (run aws configure in your terminal to start the configuration wizard) with your access and secret key.
或者,您可以使用终端/命令行上载文件。 为此,您必须安装AWS CLI,并在安装后使用访问权限和密钥对其进行aws configure在终端中运行aws configure以启动配置向导)。
将TeamSQL连接到Redshift集群并创建模式 (Connect TeamSQL to the Redshift Cluster and Create the Schema)
Open TeamSQL (if you don’t have the TeamSQL Client, download it from teamsql.io) and add a new connection.
打开TeamSQL(如果没有TeamSQL客户端,请从teamsql.io下载)并添加新连接。
Click Create a Connection to launch the Add Connection window.
单击创建连接以启动“添加连接”窗口。
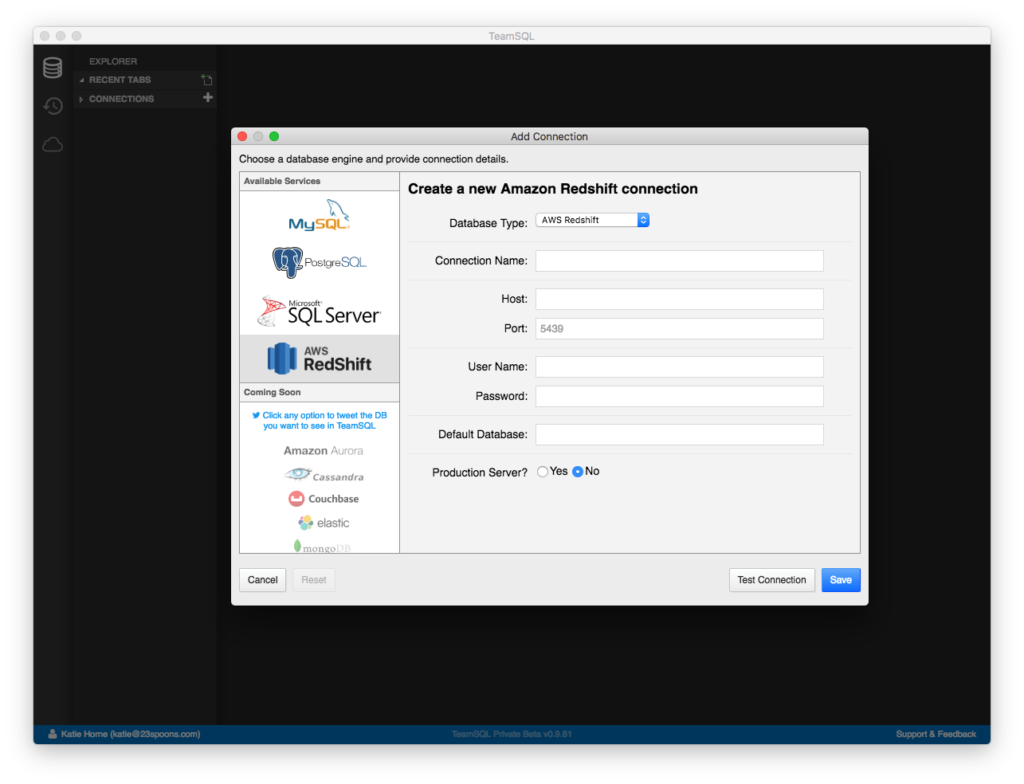
- Select Redshift and provide the requested details to set up your new connection. 选择Redshift并提供所需的详细信息以建立新连接。
Do not forget to enter the Default Database Name!
不要忘记输入默认数据库名称 !
Test the connection, and save if the test is successful.
测试连接,如果测试成功,则保存 。
By default, TeamSQL displays the connections you’ve added in the left-hand navigation panel. To enable the connection, click on the socket icon.
默认情况下,TeamSQL在左侧导航面板中显示您添加的连接。 要启用连接,请单击套接字图标。
- Right click on default database to open a new tab. 右键单击默认数据库以打开一个新选项卡。
- Run this command to create a new schema in your database. 运行此命令以在数据库中创建新的架构。
CREATE SCHEMA tweets;- Refresh the database list in the left-hand navigation panel with right clicking on connection item. 右键单击连接项,以刷新左侧导航面板中的数据库列表。
- Create a new table for training data. 创建用于训练数据的新表。
CREATE TABLE tweets.training (
polarity int,
id int,
date_of_tweet varchar,
query varchar,
user_id varchar,
tweet varchar
)
- Refresh the connection and your table should appear in the left-hand list. 刷新连接,您的表应出现在左侧列表中。
使用COPY命令导入数据 (Using the COPY Command to Import Data)
To copy your data from your source file to your data table, run the following command:
要将数据从源文件复制到数据表,请运行以下命令:
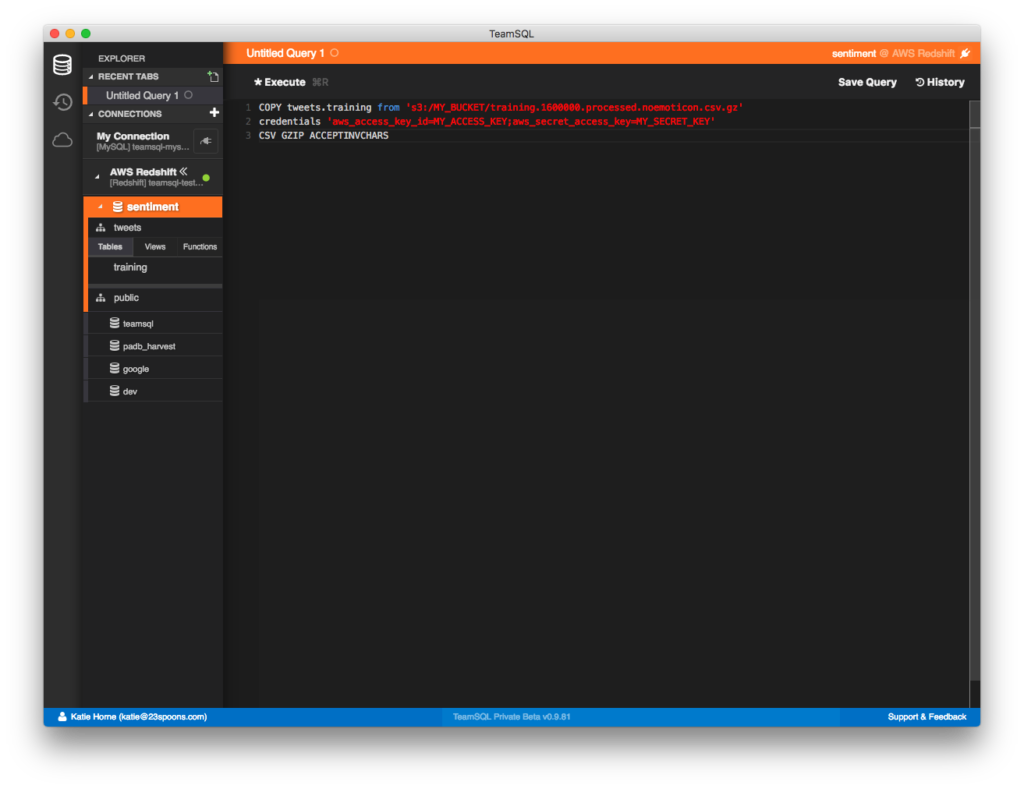
COPY tweets.training from 's3://MY_BUCKET/training.1600000.processed.noemoticon.csv.gz'
credentials 'aws_access_key_id=MY_ACCESS_KEY;aws_secret_access_key=MY_SECRET_KEY'
CSV GZIP ACCEPTINVCHARSThis command loads the CSV file and imports the data to our tweets.training table.
此命令将加载CSV文件并将数据导入到我们的tweets.training表中。
命令参数定义 (Command Parameter Definitions)
CSV: Enables use of the CSV format in the input data.
CSV :允许在输入数据中使用CSV格式。
DELIMITER: Specifies the single ASCII character that is used to separate fields in the input file, such as a pipe character ( | ), a comma ( , ), or a tab ( \t ).
DELIMITER :指定用于分隔输入文件中字段的单个ASCII字符,例如竖线字符(|),逗号(,)或制表符(\ t)。
GZIP: A value that specifies that the input file or files are in compressed gzip format (.gz files). The COPY operation reads each compressed file and uncompresses the data as it loads.
GZIP :一个值,指定一个或多个输入文件为压缩gzip格式(.gz文件)。 COPY操作读取每个压缩文件并在加载时解压缩数据。
ACCEPTINVCHARS: Enables loading of data into VARCHAR columns even if the data contains invalid UTF-8 characters. When ACCEPTINVCHARS is specified, COPY replaces each invalid UTF-8 character with a string of equal length consisting of the character specified by replacement_char. For example, if the replacement character is ‘^’, an invalid three-byte character will be replaced with ‘^^^’.
ACCEPTINVCHARS :即使数据包含无效的UTF-8字符,也可以将数据加载到VARCHAR列中。 当指定ACCEPTINVCHARS,COPY替换相等的长度由被replacement_char指定的字符的字符串每个无效的UTF-8字符。 例如,如果替换字符为“ ^ ”,则无效的三字节字符将替换为“ ^^^ ”。
The replacement character can be any ASCII character except NULL. The default is a question mark ( ? ). For information about invalid UTF-8 characters, see Multibyte Character Load Errors.
替换字符可以是除NULL之外的任何ASCII字符。 默认值为问号(?)。 有关无效UTF-8字符的信息,请参阅《 多字节字符加载错误》 。
COPY returns the number of rows that contained invalid UTF-8 characters, and it adds an entry to the STL_REPLACEMENTS system table for each affected row, up to a maximum of 100 rows for each node slice. Additional invalid UTF-8 characters are also replaced, but those replacement events are not recorded.
COPY返回包含无效UTF-8字符的行数,并为每个受影响的行在STL_REPLACEMENTS系统表中添加一个条目,每个节点切片的最大行数为100。 其他无效的UTF-8字符也会被替换,但是不会记录这些替换事件。
If ACCEPTINVCHARS is not specified, COPY returns an error whenever it encounters an invalid UTF-8 character.
如果未指定ACCEPTINVCHARS,则COPY在遇到无效的UTF-8字符时将返回错误。
ACCEPTINVCHARS is valid only for VARCHAR columns.
ACCEPTINVCHARS仅对VARCHAR列有效。
For additional information, please see Redshift Copy Parameters and Data Format.
有关更多信息,请参阅Redshift复制参数和数据格式 。
访问导入的数据 (Accessing Imported Data)
After your COPY process has finished, run a SELECT query to see if everything imported properly:
COPY过程完成后,运行SELECT查询以查看是否正确导入了所有内容:
SELECT * FROM tweets.training LIMIT 200;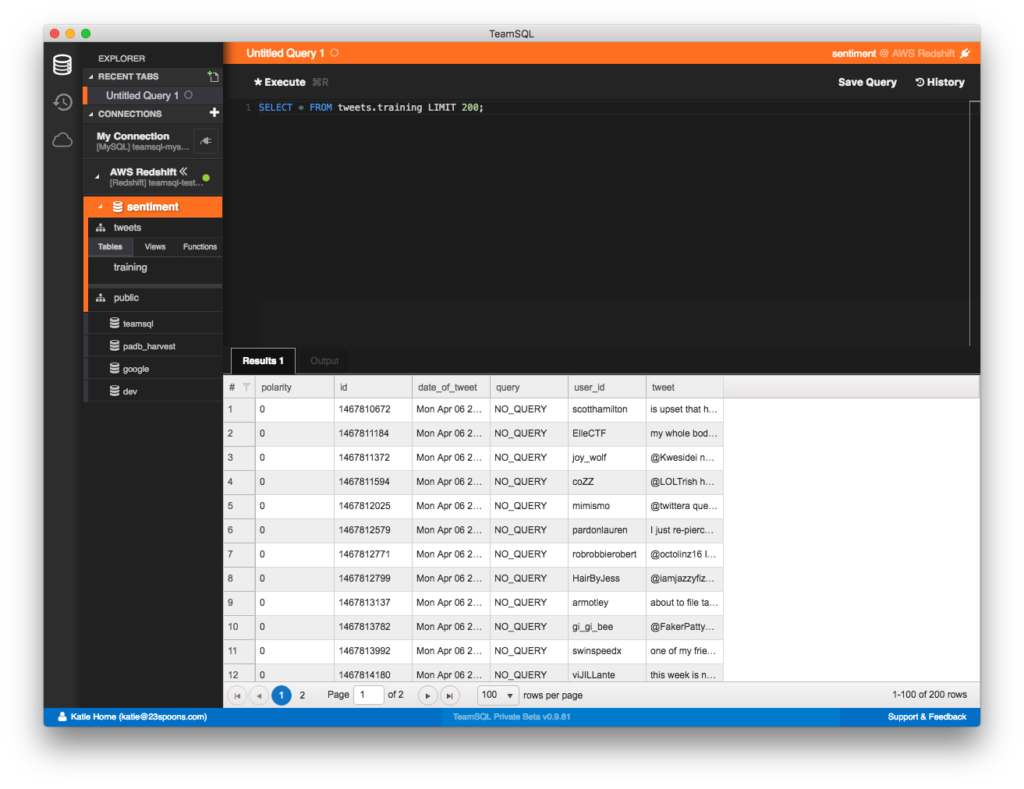
故障排除 (Troubleshooting)
If you get an error while executing the COPY command, you can check the Redshift logs by running the following:
如果在执行COPY命令时遇到错误,则可以通过运行以下命令检查Redshift日志:
SELECT * FROM stl_load_errors;You can download TeamSQL for free.
您可以免费下载TeamSQL 。
翻译自: https://www.sitepoint.com/import-data-into-redshift-using-the-copy-command/
redshift命令翻译

















 2369
2369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









