






sed linux 命令
It might sound crazy, but the Linux sed command is a text editor without an interface. You can use it from the command line to manipulate text in files and streams. We’ll show you how to harness its power.
听起来有些疯狂,但是Linux sed命令是一个没有界面的文本编辑器。 您可以从命令行使用它来处理文件和流中的文本。 我们将向您展示如何利用其功能。
sed的力量 (The Power of sed)
The sed command is a bit like chess: it takes an hour to learn the basics and a lifetime to master them (or, at least a lot of practice). We’ll show you a selection of opening gambits in each of the main categories of sed functionality.
sed命令有点像国际象棋:需要花费一个小时来学习基础知识,并且需要一生来掌握这些基础知识(或者至少需要大量练习)。 我们将向您展示sed功能的每个主要类别中的一些开放技巧。
sed is a stream editor that works on piped input or files of text. It doesn’t have an interactive text editor interface, however. Rather, you provide instructions for it to follow as it works through the text. This all works in Bash and other command-line shells.
sed是一种流编辑器 ,适用于管道输入或文本文件。 但是,它没有交互式文本编辑器界面。 相反,您将提供指示信息以使其在文本中有效。 所有这些都可以在Bash和其他命令行Shell中使用。
With sed you can do all of the following:
使用sed您可以执行以下所有操作:
- Select text 选择文字
- Substitute text 替代文字
- Add lines to text 在文本中添加行
- Delete lines from text 删除文字行
- Modify (or preserve) an original file 修改(或保留)原始文件
We’ve structured our examples to introduce and demonstrate concepts, not to produce the tersest (and least approachable) sed commands. However, the pattern matching and text selection functionalities of sed rely heavily on regular expressions (regexes). You’re going to need some familiarity with these to get the best out of sed.
我们已经构造了示例,以介绍和演示概念,而不是生成最有趣(且最不易接近)的sed命令。 但是, sed的模式匹配和文本选择功能在很大程度上依赖于正则表达式( regexes )。 您将需要对这些有所了解,以充分利用sed 。
一个简单的例子 (A Simple Example)
First, we’re going to use echo to send some text to sed through a pipe, and have sed substitute a portion of the text. To do so, we type the following:
首先,我们将使用echo将一些文本通过管道发送到sed ,并用sed替换部分文本。 为此,我们键入以下内容:
echo howtogonk | sed 's/gonk/geek/'
The echo command sends “howtogonk” into sed, and our simple substitution rule (the “s” stands for substitution) is applied. sed searches the input text for an occurrence of the first string, and will replace any matches with the second.
echo命令将“ howtogonk”发送到sed ,并应用我们的简单替换规则(“ s”代表替换)。 sed在输入文本中搜索第一个字符串的出现,并将所有匹配项替换为第二个。
The string “gonk” is replaced by “geek,” and the new string is printed in the terminal window.
字符串“ gonk”被替换为“ geek”,新的字符串被打印在终端窗口中。

Substitutions are probably the most common use of sed. Before we can dive deeper into substitutions, though, we need to know how to select and match text.
替换可能是sed的最常见用法。 但是,在我们更深入地研究替代之前,我们需要知道如何选择和匹配文本。
选择文字 (Selecting Text)
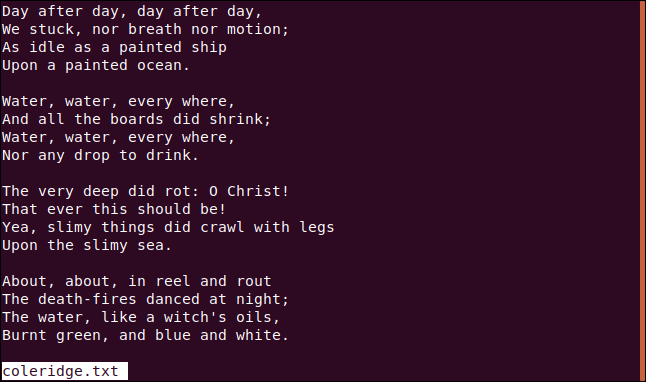
We’re going to need a text file for our examples. We’ll use one that contains a selection of verses from Samuel Taylor Coleridge’s epic poem “The Rime of the Ancient Mariner.”
我们的示例将需要一个文本文件。 我们将使用其中包含选自塞缪尔·泰勒·科尔里奇(Samuel Taylor Coleridge)的史诗《远古水手的降世》的诗句。
We type the following to take a look at it with less:
我们输入以下内容,以less的数量查看它:
less coleridge.txt
To select some lines from the file, we provide the start and end lines of the range we want to select. A single number selects that one line.
要从文件中选择一些行,我们提供要选择的范围的开始和结束行。 单个数字选择该行。
To extract lines one to four, we type this command:
要提取第一到第四行,我们键入以下命令:
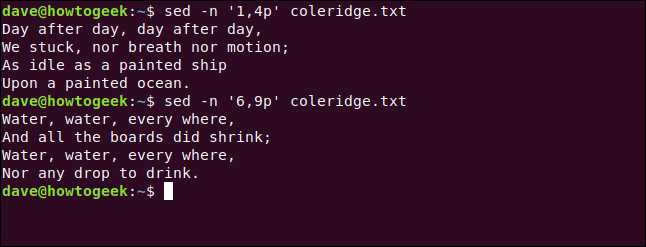
sed -n '1,4p' coleridge.txt
Note the comma between 1 and 4. The p means “print matched lines.” By default, sed prints all lines. We’d see all the text in the file with the matching lines printed twice. To prevent this, we’ll use the -n (quiet) option to suppress the unmatched text.
请注意1和4之间的逗号。 p表示“打印匹配的行”。 缺省情况下, sed打印所有行。 我们会在文件中看到所有文本,并且匹配行打印两次。 为防止这种情况,我们将使用-n (安静)选项来抑制不匹配的文本。
We change the line numbers so we can select a different verse, as shown below:
我们更改行号,以便可以选择其他经文,如下所示:
sed -n '6,9p' coleridge.txt
We can use the -e (expression) option to make multiple selections. With two expressions, we can select two verses, like so:
我们可以使用-e (表达式)选项进行多个选择。 通过两个表达式,我们可以选择两个经文,如下所示:
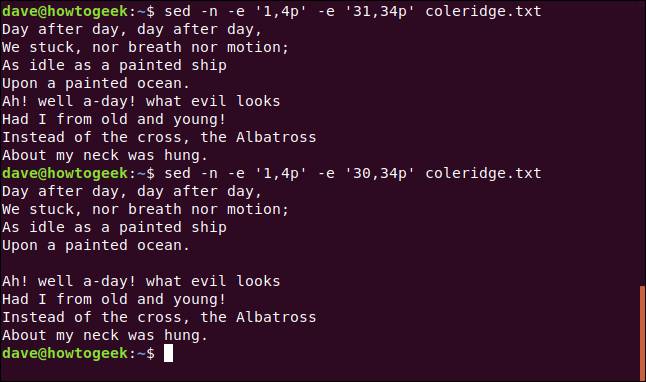
sed -n -e '1,4p' -e '31,34p' coleridge.txt
If we reduce the first number in the second expression, we can insert a blank between the two verses. We type the following:
如果我们减少第二个表达式中的第一个数字,则可以在两个经文之间插入空格。 我们输入以下内容:
sed -n -e '1,4p' -e '30,34p' coleridge.txt
We can also choose a starting line and tell sed to step through the file and print alternate lines, every fifth line, or to skip any number of lines. The command is similar to those we used above to select a range. This time, however, we’ll use a tilde (~) instead of a comma to separate the numbers.
我们还可以选择一个起始行,并告诉sed步执行文件并每隔第五行打印备用行,或者跳过任何行。 该命令与我们上面用来选择范围的命令相似。 但是,这一次,我们将使用代字号( ~ )而不是逗号来分隔数字。
The first number indicates the starting line. The second number tells sed which lines after the starting line we want to see. The number 2 means every second line, 3 means every third line, and so on.
第一个数字表示起点。 第二个数字告诉sed我们要在起始行之后的哪sed行。 数字2表示每隔第二行,数字3表示每隔三行,依此类推。
We type the following:
我们输入以下内容:
sed -n '1~2p' coleridge.txt
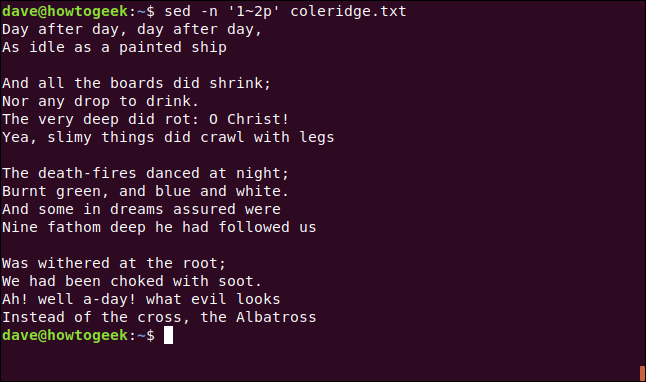
You won’t always know where the text you’re looking for is located in the file, which means line numbers won’t always be much help. However, you can also use sed to select lines that contain matching text patterns. For example, let’s extract all lines that start with “And.”
您不会总是知道要查找的文本在文件中的位置,这意味着行号不会总是很有帮助。 但是,您也可以使用sed选择包含匹配文本模式的行。 例如,让我们提取所有以“ And”开头的行。
The caret (^) represents the start of the line. We’ll enclose our search term in forward slashes (/). We also include a space after “And” so words like “Android” won’t be included in the result.
脱字号( ^ )代表行的开始。 我们将搜索词括在正斜杠( / )中。 我们还会在“与”之后加上一个空格,因此结果中将不会包含诸如“ Android”之类的字词。
Reading sed scripts can be a bit tough at first. The /p means “print,” just as it did in the commands we used above. In the following command, though, a forward slash precedes it:
首先,阅读sed脚本可能有点困难。 /p表示“打印”,就像上面我们使用的命令一样。 但是,在以下命令中,其前面是一个正斜杠:
sed -n '/^And /p' coleridge.txt
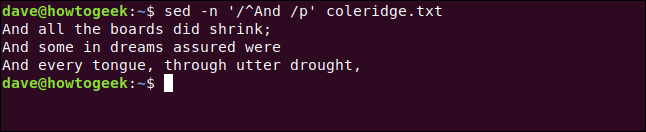
Three lines that start with “And ” are extracted from the file and displayed for us.
从文件中提取以“ And”开头的三行,并为我们显示。
换人 (Making Substitutions)
In our first example, we showed you the following basic format for a sed substitution:
在第一个示例中,我们向您展示了sed替换的以下基本格式:
echo howtogonk | sed 's/gonk/geek/'
The s tells sed this is a substitution. The first string is the search pattern, and the second is the text with which we want to replace that matched text. Of course, as with all things Linux, the devil is in the details.
s告诉sed这是一个替代。 第一个字符串是搜索模式,第二个字符串是我们要用来替换匹配文本的文本。 当然,与所有Linux一样,细节在于魔鬼。
We type the following to change all occurrences of “day” to “week,” and give the mariner and albatross more time to bond:
我们键入以下内容,将所有出现的“天”更改为“周”,并给水手和信天翁更多的时间绑定:
sed -n 's/day/week/p' coleridge.txt
In the first line, only the second occurrence of “day” is changed. This is because sed stops after the first match per line. We have to add a “g” at the end of the expression, as shown below, to perform a global search so all matches in each line are processed:
在第一行中,仅第二次出现的“ day”被更改。 这是因为sed在每行的第一个匹配项之后停止。 我们必须在表达式的末尾添加“ g”,如下所示,以执行全局搜索,以便处理每行中的所有匹配项:
sed -n 's/day/week/gp' coleridge.txt
This matches three out of the four in the first line. Because the first word is “Day,” and sed is case-sensitive, it doesn’t consider that instance to be the same as “day.”
这与第一行中的四个匹配。 因为第一个单词是“ Day”,并且sed区分大小写,所以它不认为该实例与“ day”相同。
We type the following, adding an i to the command at the end of the expression to indicate case-insensitivity:
我们键入以下内容,在表达式的末尾添加一个i到命令以指示不区分大小写:
sed -n 's/day/week/gip' coleridge.txt
This works, but you might not always want to turn on case-insensitivity for everything. In those instances, you can use a regex group to add pattern-specific case-insensitivity.
这可行,但是您可能并不总是希望对所有内容都启用不区分大小写的功能。 在这些情况下,您可以使用正则表达式组来添加特定于模式的不区分大小写。
For example, if we enclose characters in square brackets ([]), they’re interpreted as “any character from this list of characters.”
例如,如果我们将字符括在方括号( [] )中,则它们将被解释为“此字符列表中的任何字符”。
We type the following, and include “D” and “d” in the group, to ensure it matches both “Day” and “day”:
我们键入以下内容,并在组中包括“ D”和“ d”,以确保它与“ Day”和“ day”都匹配:
sed -n 's/[Dd]ay/week/gp' coleridge.txt
![The "sed -n 's/day/week/p' coleridge.txt," "sed -n 's/day/week/gp' coleridge.txt," "sed -n 's/day/week/gip' coleridge.txt," and "sed -n 's/[Dd]ay/week/gp' coleridge.txt" commands in a terminal window..](https://img-blog.csdnimg.cn/img_convert/50e06e97fd19e17f23b343095ab4cd01.png)
We can also restrict substitutions to sections of the file. Let’s say our file contains weird spacing in the first verse. We can use the following familiar command to see the first verse:
我们还可以将替换限制在文件的各个部分。 假设我们的文件在第一节经文中包含奇怪的空格。 我们可以使用以下熟悉的命令来查看第一节经文:
sed -n '1,4p' coleridge.txt
We’ll search for two spaces and substitute them with one. We’ll do this globally so the action is repeated across the entire line. To be clear, the search pattern is space, space asterisk (*), and the substitution string is a single space. The 1,4 restricts the substitution to the first four lines of the file.
我们将搜索两个空格,并用一个空格代替。 我们将在全局范围内执行此操作,以便在整个生产线上重复执行此操作。 明确地说,搜索模式是空格,星号( * ),替换字符串是单个空格。 1,4将替换限制为文件的前四行。
We put all of that together in the following command:
我们将所有这些放到以下命令中:
sed -n '1,4 s/ */ /gp' coleridge.txt
This works nicely! The search pattern is what’s important here. The asterisk (*) represents zero or more of the preceding character, which is a space. Thus, the search pattern is looking for strings of one space or more.
这很好用! 搜索模式在这里很重要。 星号( * )表示零个或多个前面的字符,它是一个空格。 因此,搜索模式正在寻找一个或多个空格的字符串。
If we substitute a single space for any sequence of multiple spaces, we’ll return the file to regular spacing, with a single space between each word. This will also substitute a single space for a single space in some cases, but this won’t affect anything adversely—we’ll still get our desired result.
如果将单个空格替换为多个空格的任何序列,则将文件恢复为常规间距,每个单词之间使用单个空格。 在某些情况下,这也可以用一个空格代替一个空格,但这不会产生任何不利影响-我们仍将获得理想的结果。
If we type the following and reduce the search pattern to a single space, you’ll see immediately why we have to include two spaces:
如果输入以下内容并将搜索模式减少到一个空格,您将立即看到为什么必须包含两个空格的原因:
sed -n '1,4 s/ */ /gp' coleridge.txt
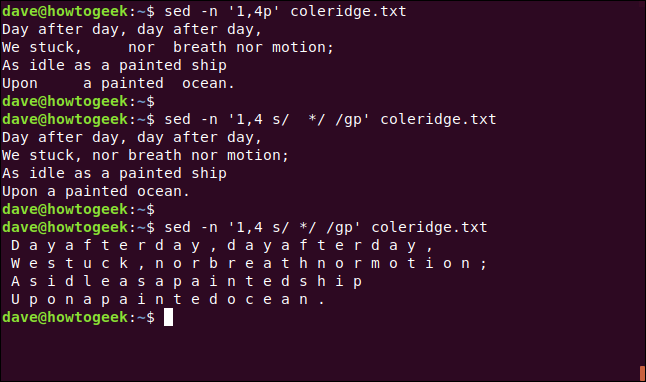
Because the asterisk matches zero or more of the preceding character, it sees each character that isn’t a space as a “zero space” and applies the substitution to it.
由于星号与零个或多个前一个字符匹配,因此它会将不是空格的每个字符都视为“零空格”,并对其进行替换。
However, if we include two spaces in the search pattern, sed must find at least one space character before it applies the substitution. This ensures nonspace characters will remain untouched.
但是,如果我们在搜索模式中包含两个空格,则sed在应用替换之前必须找到至少一个空格字符。 这样可以确保非空格字符保持不变。
We type the following, using the -e (expression) we used earlier, which allows us to make two or more substitutions simultaneously:
我们使用前面使用的-e (表达式)键入以下内容,这使我们可以同时进行两个或多个替换:
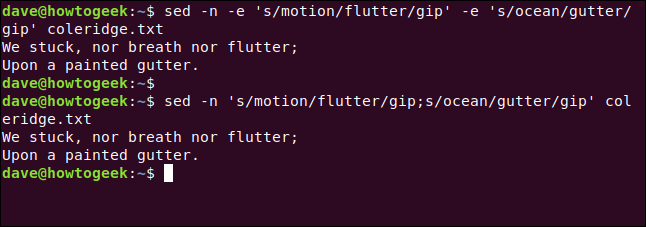
sed -n -e 's/motion/flutter/gip' -e 's/ocean/gutter/gip' coleridge.txt
We can achieve the same result if we use a semicolon (;) to separate the two expressions, like so:
如果使用分号( ; )分隔两个表达式,则可以实现相同的结果,如下所示:
sed -n 's/motion/flutter/gip;s/ocean/gutter/gip' coleridge.txt
When we swapped “day” for “week” in the following command, the instance of “day” in the expression “well a-day” was swapped as well:
当我们在以下命令中将“ day”替换为“ week”时,表达式“ day a-day”中的“ day”实例也被替换:
sed -n 's/[Dd]ay/week/gp' coleridge.txt
To prevent this, we can only attempt substitutions on lines that match another pattern. If we modify the command to have a search pattern at the start, we’ll only consider operating on lines that match that pattern.
为防止这种情况,我们只能在与另一个模式匹配的行上尝试替换。 如果我们修改命令以使其在开始时具有搜索模式,则仅考虑在与该模式匹配的行上进行操作。
We type the following to make our matching pattern the word “after”:
我们输入以下内容,使匹配模式成为单词“ after”:
sed -n '/after/ s/[Dd]ay/week/gp' coleridge.txt
That gives us the response we want.
这给了我们我们想要的回应。
![The "sed -n 's/[Dd]ay/week/gp' coleridge.txt" and "sed -n '/after/ s/[Dd]ay/week/gp' coleridge.txt" commands in a terminal window.](https://img-blog.csdnimg.cn/img_convert/666ae44533f5c8315c723da439aadcd1.png)
更复杂的替代 (More Complex Substitutions)
Let’s give Coleridge a break and use sed to extract names from the etc/passwd file.
让我们休息一下,使用sed从etc/passwd文件中提取名称。
There are shorter ways to do this (more on that later), but we’ll use the longer way here to demonstrate another concept. Each matched item in a search pattern (called subexpressions) can be numbered (up to a maximum of nine items). You can then use these numbers in your sed commands to reference specific subexpressions.
有较短的方法可以做到这一点(稍后会详细介绍),但是我们将在此处使用较长的方法来演示另一个概念。 搜索模式中的每个匹配项目(称为子表达式)都可以编号(最多9个项目)。 然后,您可以在sed命令中使用这些数字来引用特定的子表达式。
You have to enclose the subexpression in parentheses [()] for this to work. The parentheses also must be preceded by a backward slash (\) to prevent them from being treated as a normal character.
您必须将子表达式括在括号[ () ]中才能正常工作。 括号中还必须带有反斜杠( \ ),以防止将其视为普通字符。
To do this, you would type the following:
为此,您将键入以下内容:
sed 's/\([^:]*\).*/\1/' /etc/passwd
![sed 's/\([^:]*\).*/\1/' /etc/passwd in a terminal window](https://img-blog.csdnimg.cn/img_convert/0aea1839aa98c7a557eca9070dd8af3e.png)
Let’s break this down:
让我们分解一下:
sed 's/: Thesedcommand and the beginning of the substitution expression.sed 's/:sed命令和替换表达式的开头。\(: The opening parenthesis [(] enclosing the subexpression, preceded by a backslash (\).\(:圆括号[(]括住子表达式,后跟反斜杠(\)。[^:]*: The first subexpression of the search term contains a group in square brackets. The caret (^) means “not” when used in a group. A group means any character that isn’t a colon (:) will be accepted as a match.[^:]*:搜索词的第一个子表达式在方括号中包含一组。 插入符号(^)在组中使用时表示“不是”。 A组指的是不是一个冒号任何字符(:)将被接受为匹配。\): The closing parenthesis [)] with a preceding backslash (\).\)将闭括号[)]与前面的反斜杠(\)。.*: This second search subexpression means “any character and any number of them.”.*:第二个搜索子表达式的意思是“任何字符和任何数目的字符”。/\1: The substitution portion of the expression contains1preceded by a backslash (\). This represents the text that matches the first subexpression./\1:表达式的替换部分包含1后跟反斜杠(\)。 这表示与第一个子表达式匹配的文本。/': The closing forward-slash (/) and single quote (') terminate thesedcommand./':右斜杠(/)和单引号(')终止sed命令。
What this all means is we’re going to look for any string of characters that doesn’t contain a colon (:), which will be the first instance of matching text. Then, we’re searching for anything else on that line, which will be the second instance of matching text. We’re going to substitute the entire line with the text that matched the first subexpression.
这一切都说明就是我们要寻找那些不包含冒号任意字符串( : ),这将是匹配的文本的第一个实例。 然后,我们正在搜索该行上的任何其他内容,这将是匹配文本的第二个实例。 我们将用与第一个子表达式匹配的文本替换整行。
Each line in the /etc/passwd file starts with a colon-terminated username. We match everything up to the first colon, and then substitute that value for the entire line. So, we’ve isolated the usernames.
/etc/passwd文件中的每一行都以冒号结尾的用户名开头。 我们将所有内容匹配到第一个冒号,然后将该值替换为整行。 因此,我们隔离了用户名。
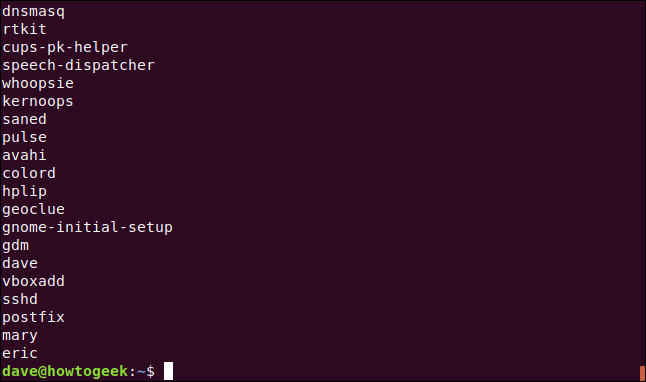
Next, we’ll enclose the second subexpression in parentheses [()] so we can reference it by number, as well. We’ll also replace \1 with \2. Our command will now substitute the entire line with everything from the first colon (:) to the end of the line.
接下来,将第二个子表达式括在括号[ () ]中,以便我们也可以按数字引用它。 我们还将\1替换为\2 。 (我们的命令现在的一切,从第一个冒号代替整条生产线: )到行的末尾。
We type the following:
我们输入以下内容:
sed 's/\([^:]*\)\(.*\)/\2/' /etc/passwd
![The "sed 's/\([^:]*\)\(.*\)/\2/' /etc/passwd" command in a terminal window.](https://img-blog.csdnimg.cn/img_convert/70126a8cd04e77528b79e1fa26a09733.png)
Those small changes invert the meaning of the command, and we get everything except the usernames.
这些小的更改使命令的含义反转,除用户名外,我们获得了所有内容。
![Output from sed 's/\([^:]*\)\(.*\)/\2/' /etc/passwd in a terminal window](https://img-blog.csdnimg.cn/img_convert/f136e608734380bef62c19a7139283c3.png)
Now, let’s take a look at the quick and easy way to do this.
现在,让我们看一下执行此操作的快速简便的方法。
Our search term is from the first colon (:) to the end of the line. Because our substitution expression is empty (//), we won’t replace the matched text with anything.
我们的搜索项是来自第一冒号( : )到行的结尾。 由于我们的替换表达式为空( // ),因此我们不会将匹配的文本替换为任何内容。
So, we type the following, chopping off everything from the first colon (:) to the end of the line, leaving just the usernames:
所以,我们键入以下内容,从第一个冒号斩去一切( : )到线的尽头,只留下用户名:
sed 's/:.*//" /etc/passwd

Let’s look at an example in which we reference the first and second matches in the same command.
让我们看一个示例,其中我们在同一命令中引用了第一和第二个匹配项。
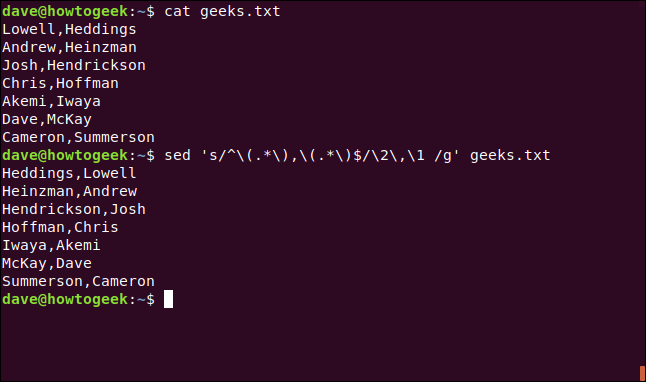
We’ve got a file of commas (,) separating first and last names. We want to list them as “last name, first name.” We can use cat, as shown below, to see what’s in the file:
我们有一个用逗号( , )分隔名字和姓氏的文件。 我们希望将它们列出为“姓氏,名字”。 我们可以使用cat ,如下所示,查看文件中的内容:
cat geeks.txt
Like a lot of sed commands, this next one might look impenetrable at first:
像许多sed命令一样,下一个命令乍一看似乎不可理解:
sed 's/^\(.*\),\(.*\)$/\2,\1 /g' geeks.txt
This is a substitution command like the others we’ve used, and the search pattern is quite easy. We’ll break it down below:
就像我们使用的其他命令一样,这是一个替换命令,搜索模式非常简单。 我们将其分解如下:
sed 's/: The normal substitution command.sed 's/:正常的替换命令。^: Because the caret isn’t in a group ([]), it means “The start of the line.”^:因为插入号不在组([])中,所以它表示“行的开始”。\(.*\),: The first subexpression is any number of any characters. It’s enclosed in parentheses [()], each of which is preceded by a backslash (\) so we can reference it by number. Our entire search pattern so far translates as search from the start of the line up to the first comma (,) for any number of any characters.\(.*\),,:第一个子表达式是任意数量的任何字符。 它用括号[()]括起来,每个括号前面都有一个反斜杠(\),因此我们可以按数字引用它。 到目前为止,我们的整个搜索模式都是从行首到第一个逗号(,)进行搜索,以查找任意数量的任何字符。\(.*\): The next subexpression is (again) any number of any character. It’s also enclosed in parentheses [()], both of which are preceded by a backslash (\) so we can reference the matching text by number.\(.*\):下一个子表达式(再次)是任意数量的任意字符。 它也被括在括号[()]中,两者都以反斜杠(\)开头,因此我们可以按数字引用匹配的文本。$/: The dollar sign ($) represents the end of the line and will allow our search to continue to the end of the line. We’ve used this simply to introduce the dollar sign. We don’t really need it here, as the asterisk (*) would go to the end of the line in this scenario. The forward slash (/) completes the search pattern section.$/:美元符号($)表示行的结尾,这将使我们的搜索继续到行的结尾。 我们只是用它来介绍美元符号。 我们在这里实际上并不需要它,因为在这种情况下星号(*)会移至行的末尾。 正斜杠(/)表示搜索模式部分。\2,\1 /g': Because we enclosed our two subexpressions in parentheses, we can refer to both of them by their numbers. Because we want to reverse the order, we type them assecond-match,first-match. The numbers have to be preceded by a backslash (\).\2,\1 /g':因为我们在圆括号中包含了两个子表达式,所以我们可以通过它们的编号来引用它们。 因为我们想颠倒顺序,所以我们将它们键入为second-match,first-match。 数字前面必须有一个反斜杠(\)。/g: This enables our command to work globally on each line./g:这使我们的命令可以在每一行上全局工作。geeks.txt: The file we’re working on.geeks.txt:我们正在处理的文件。
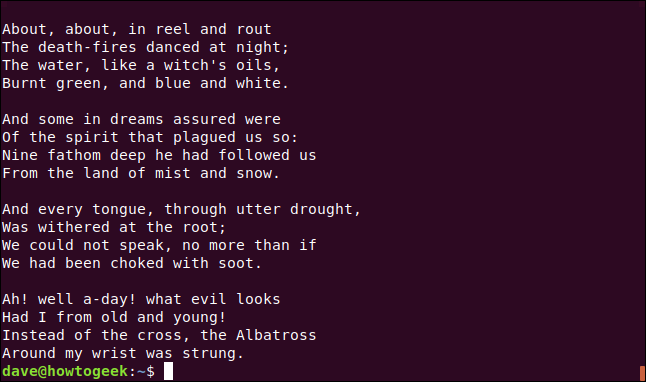
You can also use the Cut command (c) to substitute entire lines that match your search pattern. We type the following to search for a line with the word “neck” in it, and replace it with a new string of text:
您还可以使用Cut命令( c )替换与搜索模式匹配的整行。 我们键入以下内容以搜索其中包含单词“ neck”的行,并将其替换为新的文本字符串:
sed '/neck/c Around my wrist was strung' coleridge.txt

Our new line now appears at the bottom of our extract.
现在,我们的新行显示在摘要的底部。
插入行和文本 (Inserting Lines and Text)
We can also insert new lines and text into our file. To insert new lines after any matching ones, we’ll use the Append command (a).
我们还可以在文件中插入新行和文本。 要在任何匹配的行之后插入新行,我们将使用Append命令( a )。
Here’s the file we’re going to work with:
这是我们要使用的文件:
cat geeks.txt
猫geeks.txt
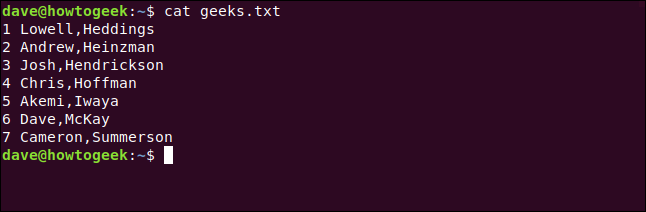
We’ve numbered the lines to make this a bit easier to follow.
我们对行进行了编号,以使其更容易理解。
We type the following to search for lines that contain the word “He,” and insert a new line beneath them:
我们键入以下内容以搜索包含单词“ He”的行,并在其下方插入新行:
sed '/He/a --> Inserted!' geeks.txt
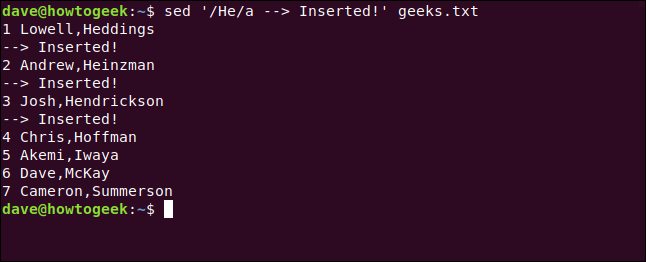
We type the following and include the Insert Command (i) to insert the new line above those that contain matching text:
我们输入以下内容,并包含“插入命令”( i ),以在包含匹配文本的行上方插入新行:
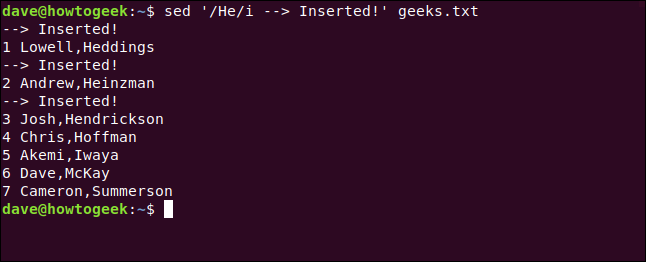
sed '/He/i --> Inserted!' geeks.txt
We can use the ampersand (&), which represents the original matched text, to add new text to a matching line. \1 , \2, and so on, represent matching subexpressions.
我们可以使用代表原始匹配文本的&字符( & )将新文本添加到匹配行。 \1 , \2等表示匹配的子表达式。
To add text to the start of a line, we’ll use a substitution command that matches everything on the line, combined with a replacement clause that combines our new text with the original line.
要将文本添加到行的开头,我们将使用匹配该行中所有内容的替换命令,并使用将新文本与原始行组合在一起的替换子句。
To do all of this, we type the following:
为此,我们键入以下内容:
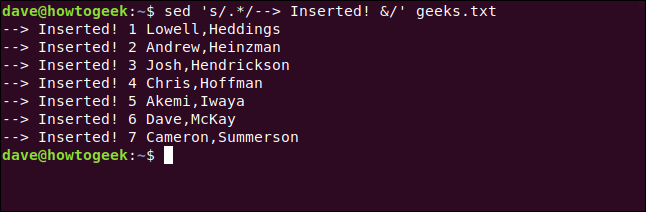
sed 's/.*/--> Inserted &/' geeks.txt
We type the following, including the G command, which will add a blank line between each line:
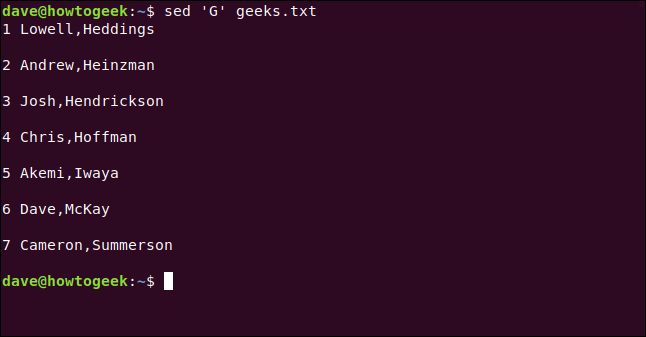
我们键入以下内容,包括G命令,该命令将在每行之间添加一个空行:
sed 'G' geeks.txt
If you want to add two or more blank lines, you can use G;G, G;G;G, and so on.
如果要添加两个或更多空行,则可以使用G;G , G;G;G等。
删除线 (Deleting Lines)
The Delete command (d) deletes lines that match a search pattern, or those specified with line numbers or ranges.
Delete命令( d )删除与搜索模式匹配的行,或用行号或范围指定的行。
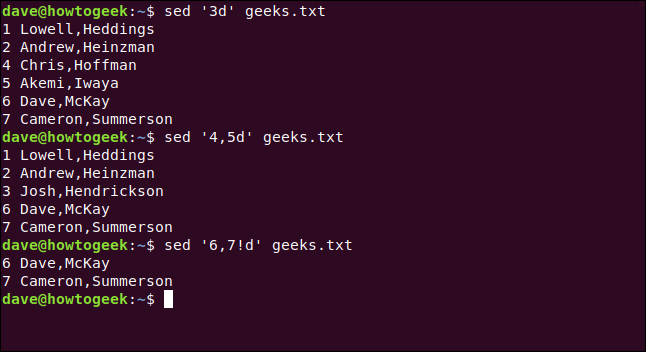
For example, to delete the third line, we would type the following:
例如,要删除第三行,我们将键入以下内容:
sed '3d' geeks.txt
To delete the range of lines four to five, we’d type the following:
要删除第4至5行的范围,请输入以下内容:
sed '4,5d' geeks.txt
To delete lines outside a range, we use an exclamation point (!), as shown below:
要删除范围之外的行,我们使用感叹号( ! ),如下所示:
sed '6,7!d' geeks.txt
保存更改 (Saving Your Changes)
So far, all of our results have printed to the terminal window, but we haven’t yet saved them anywhere. To make these permanent, you can either write your changes to the original file or redirect them to a new one.
到目前为止,我们所有的结果都已打印到终端窗口,但是我们还没有将它们保存到任何地方。 要永久保留这些内容,您可以将更改写入原始文件,也可以将其重定向到新文件。
Overwriting your original file requires some caution. If your sed command is wrong, you might make some changes to the original file that are difficult to undo.
覆盖原始文件需要谨慎。 如果sed命令错误,则可能对原始文件进行了一些难以撤消的更改。
For some peace of mind, sed can create a backup of the original file before it executes its command.
为了让您高枕无忧, sed可以在执行命令之前创建原始文件的备份。
You can use the In-place option (-i) to tell sed to write the changes to the original file, but if you add a file extension to it, sed will back up the original file to a new one. It will have the same name as the original file, but with a new file extension.
您可以使用就地选项( -i )告诉sed将更改写入原始文件,但是如果您向其中添加文件扩展名,则sed会将原始文件备份到新文件。 它将具有与原始文件相同的名称,但具有新的文件扩展名。
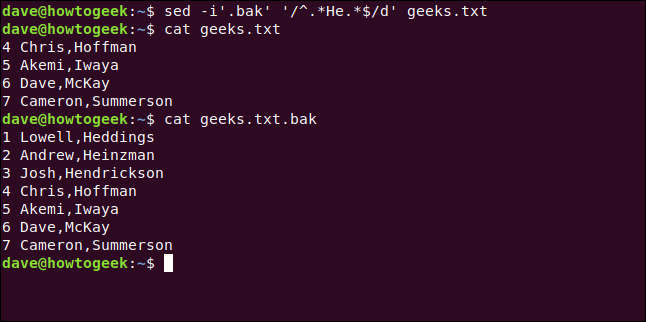
To demonstrate, we’ll search for any lines that contain the word “He” and delete them. We’ll also back up our original file to a new one using the BAK extension.
为了演示,我们将搜索包含单词“ He”的所有行并将其删除。 我们还将使用BAK扩展名将原始文件备份到新文件。
To do all of this, we type the following:
为此,我们键入以下内容:
sed -i'.bak' '/^.*He.*$/d' geeks.txt
We type the following to make sure our backup file is unchanged:
我们输入以下内容以确保我们的备份文件未更改:
cat geeks.txt.bak
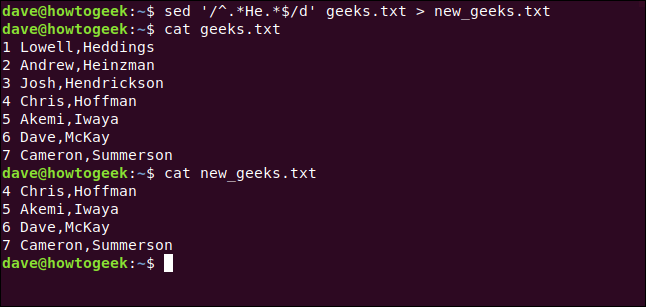
We can also type the following to redirect the output to a new file and achieve a similar result:
我们还可以键入以下命令将输出重定向到新文件并获得类似的结果:
sed -i'.bak' '/^.*He.*$/d' geeks.txt > new_geeks.txt
We use cat to confirm the changes were written to the new file, as shown below:
我们使用cat确认更改已写入新文件,如下所示:
cat new_geeks.txt
唱完了 (Having sed All That)
As you’ve probably noticed, even this quick primer on sed is quite long. There’s a lot to this command, and there’s even more you can do with it.
您可能已经注意到,即使sed快速入门也很长。 该命令有很多功能,甚至可以做更多的事情 。
Hopefully, though, these basic concepts have provided a solid foundation on which you can build as you continue to learn more.
但是,希望这些基本概念提供了坚实的基础,您可以在不断学习的基础上继续构建。
翻译自: https://www.howtogeek.com/666395/how-to-use-the-sed-command-on-linux/
sed linux 命令















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









