





cte公用表表达式
Since we know that the SQL CTE (common table expression) offers us a tool to group and order data in SQL Server, we will see an applied example of using common table expressions to solve the business challenge of re-basing identifier columns. We can think of the business problem like the following: we have a table of foods that we sell with a unique identifier integer associated with the food. As we sell new foods, we insert the food in our list. After a few years, we observe that many of our queries involve the foods grouped alphabetically. However, our food list is just a list of foods that we add to as needed without any grouping. Rather than re-group or re-order through queries using a SQL CTE or subquery, we want to permanently update the identifier.
由于我们知道SQL CTE(公用表表达式)为我们提供了一种在SQL Server中对数据进行分组和排序的工具,因此我们将看到一个使用公用表表达式解决重新基准化标识符列的业务难题的应用示例。 我们可以像以下那样思考业务问题:我们有一个食品表,其中出售一个与食品相关的唯一标识符整数。 当我们出售新食品时,会将食品插入清单中。 几年后,我们发现许多查询都涉及按字母顺序分组的食物。 但是,我们的食物清单只是我们根据需要添加的食物清单,没有任何分组。 我们希望永久更新标识符,而不是通过使用SQL CTE或子查询通过查询进行重新分组或重新排序。
Because we prefer to use SARGable operators, grouping related items may be a task that will help some of our queries. One way we can solve this is by adding a new grouping field and using it. However, if we’re required to re-base our identifier, adding a new column will only be part of the solution.
因为我们更喜欢使用SARGable运算符,所以对相关项目进行分组可能会帮助我们进行某些查询。 解决此问题的一种方法是添加一个新的分组字段并使用它。 但是,如果需要重新设置标识符基础,则添加新列将仅是解决方案的一部分。
我们的示例数据集 (Our example data set)
For this tip, we’ll be solving this problem using the below example tables with organic foods and an orders table that holds orders from our organic foods table. To provide an extra check, I’ve organized the orders table where every order purchased 2 items and orders are either vegetable or fruit orders. This helps as another check as we work through the problem. We can use this same re-base technique involving common table expressions with any other set of tables where we’re required to re-base an identifier field with some considerations about how our tables are organized:
对于本技巧,我们将使用以下带有有机食品的示例表和包含来自有机食品表的订单的订单表来解决此问题。 为了提供额外的支票,我整理了订单表,其中每个订单购买了2个项目,并且订单是蔬菜订单或水果订单。 这是我们解决问题时的另一项检查。 我们可以使用涉及公共表表达式和其他任何表集的相同的重新设置技巧,在这种情况下,我们需要考虑与如何组织表有关的一些注意事项来重新创建标识符字段:
- If we are using foreign key references that are part of the identifier that is being re-based, we must first remove the foreign keys before we proceed. The same applies to other constraints 如果我们使用的外键引用是重新基于标识符的一部分,则必须先删除外键,然后再继续。 其他限制也是如此
- Since we’re looking at identifiers, this means that primary keys will be involved in at least one table’s re-basement, which affects dependencies, such as replication, auditing, etc. We must first solve these dependencies before proceeding 由于我们正在查看标识符,因此这意味着主键将涉及至少一个表的重新基础结构,这会影响依赖关系,例如复制,审计等。我们必须先解决这些依赖关系,然后再进行操作
For populating our experiment data, we’ll execute the below code and review:
为了填充实验数据,我们将执行以下代码并进行审查:
CREATE TABLE tbOrganicFoodsList(
OrganicFoodId SMALLINT NOT NULL,
OrganicFood VARCHAR(50) NOT NULL
)
ALTER TABLE tbOrganicFoodsList ADD CONSTRAINT PK_OrganicFoodId_List PRIMARY KEY CLUSTERED (OrganicFoodId)
INSERT INTO tbOrganicFoodsList
VALUES (1,'Broccoli')
, (2,'Apple')
, (3,'Fig')
, (4,'Potato')
, (5,'Kale')
, (6,'Cucumber')
CREATE TABLE tbOrganicFoodOrders (
OrderId INT NOT NULL,
OrganicFoodId SMALLINT NOT NULL
)
ALTER TABLE tbOrganicFoodOrders ADD CONSTRAINT FK_OrganicFoodId_Orders FOREIGN KEY (OrganicFoodId) REFERENCES tbOrganicFoodsList (OrganicFoodId)
INSERT INTO tbOrganicFoodOrders
VALUES (1,2)
, (1,3)
, (2,1)
, (2,5)
, (3,6)
, (3,1)
, (4,5)
, (4,6)
, (5,3)
, (5,2)
使用通用表表达式对标识重新设置基准 (Rebasing an identity with Common table expressions)
One principle in math is to show every step and to make this understandable, we will be doing this in this tip with the help of SQL CTEs, especially with ordering data before we rebase data. We will add one column to our tbOrganicFoodsList table and one column to our tbOrganicFoodOrders table. If we have any dependencies on our primary or foreign keys here, we would first either remove them (drop and re-create script for later) or disable them. Our next step will be dropping the foreign key and then the primary key.
数学中的一个原则是显示每个步骤并使其易于理解,在本文中,我们将借助SQL CTE进行此操作,尤其是在对数据进行基础计算之前对数据进行排序。 我们将在tbOrganicFoodsList表中添加一列,并在tbOrganicFoodOrders表中添加一列。 如果我们在这里对主键或外键有任何依赖关系 ,我们将首先删除它们(删除并重新创建脚本以供以后使用)或禁用它们。 我们的下一步将是删除外键,然后是主键。
ALTER TABLE tbOrganicFoodOrders DROP CONSTRAINT FK_OrganicFoodId_Orders
ALTER TABLE tbOrganicFoodsList DROP CONSTRAINT PK_OrganicFoodId_List
Now that we’ve removed our constraints, we’ll begin by adding a column to our tbOrganicFoodsList that will save our identifier field before we re-base it. This will help us avoid column re-naming by creating a new column that’s organized, dropping the old column, and then renaming our new column. That is also an acceptable way to solve this challenge.
现在,我们已经消除了约束,我们将从在tbOrganicFoodsList中添加一列开始,该列将在重新建立基础之前保存标识符字段。 通过创建经过组织的新列,删除旧列,然后重命名新列,这将有助于我们避免重命名列。 这也是解决这一挑战的可接受方法。
ALTER TABLE tbOrganicFoodsList ADD OldId SMALLINT
UPDATE tbOrganicFoodsList
SET OldId = OrganicFoodId
SELECT *
FROM tbOrganicFoodsList
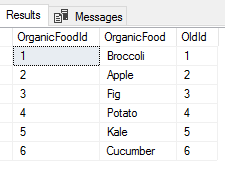
Using a Common table expression named UpdateOrder, in the below code we order the foods alphabetically in our UpdateOrder CTE and call it an UpdateId as well as select our OrganicFoodId, which we’ll be updating to this new order. From our select statement, we can see the new order of our OrganicFoodId versus the OldId. This is a key step if we have old archives on disk backup files or other servers, as this table will allow us to compare the data from our re-based data to our original data, assuming we don’t rebase archived data. Because of this reason, we’ll notice that we save a copy of this table in this step – the saved data is RebasedDataKey_tbOrganicFoodsList.
使用名为UpdateOrder的通用表表达式,在下面的代码中,我们在UpdateOrder CTE中按字母顺序对食物进行排序,并将其命名为UpdateId并选择我们的OrganicFoodId,我们将更新为该新订单。 从我们的select语句中,我们可以看到OrganicFoodId与OldId的新顺序。 如果我们在磁盘备份文件或其他服务器上有旧的归档文件,这是关键的一步,因为此表将使我们能够将重新基于基准的数据与原始数据进行比较,假设我们不对归档数据进行基准化。 由于这个原因,我们将注意到在此步骤中保存了该表的副本–保存的数据为RebasedDataKey_tbOrganicFoodsList。
;WITH UpdateOrder AS(
SELECT ROW_NUMBER() OVER (ORDER BY OrganicFood ASC) UpdateId --- orders foods alphabetically
, OrganicFoodId
FROM tbOrganicFoodsList
)
UPDATE UpdateOrder
SET OrganicFoodId = UpdateId
SELECT *
FROM tbOrganicFoodsList
ORDER BY OrganicFoodId
---- Saved re-basement data
SELECT * INTO RebasedDataKey_tbOrganicFoodsList FROM tbOrganicFoodsList
In our next step, we’ll look at our tables joined and see the results of the OrganicFoodId and OldId with the orders that we’ll be using to create a SQL CTE to update the food list. Since I intentionally grouped the orders so that we could perform a quick check, we can see how the new OrganicFoodId that’s been re-based will appear on the tbOrganicFoodOrders table. From here, we use the same join and only select the two OrganicFoodId columns – one from the table we’ve re-based (tbOrganicFoodsList) and the other from the table we’ll be updating (tbOrganicFoodOrders). To make this clear, I’ve titled the column in the SQL CTE to what they’ll be used for – one needs to be re-based (NeedsRebase) and it will be updated and the other is the base which will be the reference point for the update. We then see the update run against this CTE in SQL Server, which updates the appropriate rows of the tbOrganicFoodOrders table.
在下一步中,我们将查看联接的表,并查看OrganicFoodId和OldId的结果以及将用于创建SQL CTE以更新食品清单的顺序。 由于我有意对订单进行了分组,以便我们可以执行快速检查,因此我们可以看到重新基于的新OrganicFoodId将如何出现在tbOrganicFoodOrders表上。 在这里,我们使用相同的联接,并且仅选择两个OrganicFoodId列–一个是我们重新基于表格的表(tbOrganicFoodsList),另一个是我们将要更新的表格(tbOrganicFoodOrders)。 为了清楚起见,我在SQL CTE中的列标题下指定了它们的用途–一个需要重新基于(NeedsRebase),它将被更新,另一个是作为参考的基础。更新点。 然后,我们在SQL Server中看到针对此CTE运行的更新,该更新将更新tbOrganicFoodOrders表的相应行。
SELECT *
FROM tbOrganicFoodsList t
INNER JOIN tbOrganicFoodOrders t2 ON t.OldId = t2.OrganicFoodId
;WITH UpdateBase AS(
SELECT
t2.OrganicFoodId OrganicFoodId_NeedsRebase
, t.OrganicFoodId OrganicFoodId_Base
FROM tbOrganicFoodsList t
INNER JOIN tbOrganicFoodOrders t2 ON t.OldId = t2.OrganicFoodId
)
UPDATE UpdateBase
SET OrganicFoodId_NeedsRebase = OrganicFoodId_Base
SELECT
t2.OrderId
, t2.OrganicFoodId
, t.OrganicFood
FROM tbOrganicFoodsList t
INNER JOIN tbOrganicFoodOrders t2 ON t.OrganicFoodId = t2.OrganicFoodId
Our final step is to remove the OldId column and add our primary key and foreign key constraints:
我们的最后一步是删除OldId列,并添加主键和外键约束:
ALTER TABLE tbOrganicFoodsList DROP COLUMN OldId
ALTER TABLE tbOrganicFoodsList ADD CONSTRAINT PK_OrganicFoodId_List PRIMARY KEY CLUSTERED (OrganicFoodId)
ALTER TABLE tbOrganicFoodOrders ADD CONSTRAINT FK_OrganicFoodId_Orders FOREIGN KEY (OrganicFoodId) REFERENCES tbOrganicFoodsList (OrganicFoodId)
一些注意事项 (Some considerations)
- What if we wanted to group the items alphabetically within a category, like alphabetical list of vegetables, fruits, etc? We’d take the same logic only we’d partition it further by more detailed groups. As we’ve seen with CTEs in SQL Server, these make it easy to organize data and work intuitively to update columns from new columns or new designs 如果我们想按字母顺序将商品归类,例如按字母顺序排列的蔬菜,水果等,该怎么办? 我们只会采用相同的逻辑,只是将其进一步细分为更详细的组。 正如我们在SQL Server中使用CTE所看到的那样,它们使组织数据和直观地工作以从新列或新设计中更新列变得容易。
- Since it’s impossible to have all information up front, on the initial design of our tables a best practice to avoid this problem is to consider the columns that will be used in queries and how much space should be allowed between these values. Using the same example with a food list, for each group, we may want up to 10000 or more of range values for each category, even if we only use a fraction of those values. We can apply math operations to SQL CTE order, such as the following creating a grouping identifier on sys.tables: 由于不可能事先获得所有信息,因此在表的初始设计中,避免此问题的最佳实践是考虑将在查询中使用的列以及这些值之间应留有多少空间。 使用带有食物清单的相同示例,对于每个组,即使我们仅使用这些值的一小部分,对于每个类别,我们可能也希望多达10000个或更多的范围值。 我们可以将数学运算应用于SQL CTE顺序,例如以下在sys.tables上创建分组标识符的操作:
;WITH PartitionTables AS(
SELECT
DENSE_RANK() OVER (ORDER BY is_ms_shipped) PlusId
, (ROW_NUMBER() OVER (PARTITION BY is_ms_shipped ORDER BY [name])) Id
, (DENSE_RANK() OVER (ORDER BY is_ms_shipped)*1000) + (ROW_NUMBER() OVER (PARTITION BY is_ms_shipped ORDER BY [name])) GroupId
, is_ms_shipped
FROM sys.tables
)
SELECT *
FROM PartitionTables
- Of the steps required, the most manual will be re-basing the primary table, as our re-basement is determined by how we want to group: alphabetically, by category or status, by range, etc. For instance, if we had 1000 foods and wanted to group them by color, the step of grouping would be manual to get our table with the new grouping. Unfortunately, SQL CTEs and subqueries can’t help us for custom grouping, but once we have them, we can use them to assist with ordering other tables. From there, we would follow the same plug-and-play pattern of updates of the identifier fields through joins on the old identifier field 在所需的步骤中,最手动的将是重新建立主表的基础,因为我们的重新确定基础取决于我们要如何分组:按字母顺序,按类别或状态,按范围等。例如,如果我们有1000食物,并想按颜色对它们进行分组,分组的步骤将是手动完成的,以使表格具有新分组。 不幸的是,SQL CTE和子查询无法帮助我们进行自定义分组,但是一旦有了它们,我们就可以使用它们来协助订购其他表。 从那里开始,我们将通过旧标识符字段上的联接遵循相同的即插即用模式来更新标识符字段
结论 (Conclusion)
Because we don’t always know how our data will be used by clients, rebasing an identity field to optimize queries against data comes up in some situations. While there are many approaches to solving this problem, common table expressions offer us one tool to organize our data and solve for this problem. In addition, if we need to add extra “space” to our identifier column or columns, we can use mathematical operations with SQL CTEs to give our data space to grow
由于我们并不总是知道客户端将如何使用我们的数据,因此在某些情况下会出现基于身份字段优化针对数据的查询的情况。 尽管有很多方法可以解决此问题,但通用表表达式为我们提供了一种工具来组织数据并解决该问题。 另外,如果我们需要在一个或多个标识符列中添加额外的“空间”,则可以对SQL CTE使用数学运算来增加数据空间
目录 (Table of contents)
| CTEs in SQL Server; Querying Common Table Expressions |
| Inserts and Updates with CTEs in SQL Server (Common Table Expressions) |
| CTE SQL Deletes; Considerations when Deleting Data with Common Table Expressions in SQL Server |
| CTEs in SQL Server; Using Common Table Expressions To Solve Rebasing an Identifier Column |
| SQL Server中的CTE; 查询公用表表达式 |
| 在SQL Server中使用CTE进行插入和更新(公用表表达式) |
| CTE SQL删除; 在SQL Server中删除具有公用表表达式的数据时的注意事项 |
| SQL Server中的CTE; 使用公用表表达式解决重新编制标识符列的问题 |
cte公用表表达式















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









