





In this data-driven era, replication is often a critical requirement for achieving a modern, agile database management environment. It is believed designing an enterprise-grade dataset is the to achieving this requirement but building datamarts from datasets always presents certain challenges
在这个数据驱动的时代,复制通常是实现现代,敏捷的数据库管理环境的关键要求。 相信设计企业级数据集是满足此要求的方法,但是从数据集构建数据集市始终带来某些挑战
In this article, we’ll discuss what it takes to setup “central subscriber with multiple publishers” replication model, to create an aggregate dataset from multiple sources, and you’ll also see how to scale with the data.
在本文中,我们将讨论设置“具有多个发布者的中央订户”复制模型,从多个来源创建聚合数据集所需要的操作,还将看到如何缩放数据。
Here’s a sneak peek of the topics:
以下是这些主题的简要介绍:
- Replication model; Central subscriber-multiple publisher 复制模型; 中央订户-多个发布者
- Understanding the state of the data 了解数据状态
- Highlights of a custom transaction log reading/replication 自定义事务日志读取/复制的重点
- Setup and internals 设置和内部
- And more! 和更多!
技术 (Technology)
For our SQL Server transaction log reading agent we will use ApexSQL Log, a 3rd party tool that can read the SQL Server transaction log and convert transactions into “redo” statements that can be executed on our various subscribers
对于我们的SQL Server事务日志阅读代理 ,我们将使用ApexSQL日志,一个第三方工具,它可以读取SQL Server事务日志和转换的交易成能够在我们的各种用户执行“重做”语句
复制模型 (Replication Model)
The “central subscriber–multiple publishers” model is commonly used in situations where data from multiple sites needs to be consolidated at a central location while providing access to the local site with local data. A shipment data warehouse is a typical example. Where orders are placed at all publisher locations and the order confirmation details are pushed to central subscriber from which the order is shipped to the respective parties.
在需要将来自多个站点的数据合并到一个中央位置,同时提供使用本地数据访问本地站点的情况下,通常使用“中央订户-多个发布者”模型。 装运数据仓库就是一个典型的例子。 在所有发布者位置都下达了订单的地方,订单确认详细信息被推送到中央订户,然后从该中心订户将订单运送到各个相关方。
In short, the multiple publisher databases replicate their data to the same subscription table but the process may pose a unique problem. We need to have a model to include the information to create a unique identifier for every row in every publisher database. For example, in this model, several publishers replicate data to a single, central subscriber. Basically, this is a process to support the data consolidation concept at a central database.
简而言之,多个发布者数据库将其数据复制到同一预订表,但是该过程可能会带来一个独特的问题。 我们需要一个模型来包含信息,以便为每个发布者数据库中的每一行创建唯一的标识符。 例如,在此模型中,几个发布者将数据复制到单个中央订阅者。 基本上,这是一个支持中央数据库中数据合并概念的过程。
In some other instances, the publisher databases replicate the data at the table level. In this case, the synchronization is straight-forward, as we deal with higher granularity.
在其他一些实例中,发布者数据库在表级别复制数据。 在这种情况下,同步是直接的,因为我们要处理更高的粒度。
For each article to be published in a Central Subscriber topology, a unique identifier should be defined to leverage the action. We can use a lookup table to generate the unique combination of rows in all the publishers. To publish rows from Publisher 1, unique combination of keys is defined in the article so that it will not end up in creating a duplicate row. Likewise, to publish rows from Publisher 2 and Publisher 3, and Publisher 4, the same logic is placed across all the articles.
对于要在中央订户拓扑中发布的每篇文章,都应定义唯一的标识符以利用操作。 我们可以使用查找表在所有发布者中生成行的唯一组合。 为了从Publisher 1发布行,在文章中定义了唯一的键组合,这样它就不会最终导致创建重复的行。 同样,要发布发布者2和发布者3以及发布者4中的行,请在所有文章中放置相同的逻辑。
建立 (Setup)
Let us walk through the entire process in detail
让我们详细介绍整个过程
-
- Order_id and Order_id和Region_ID is a primary-key constraint. Region_ID是主键约束。
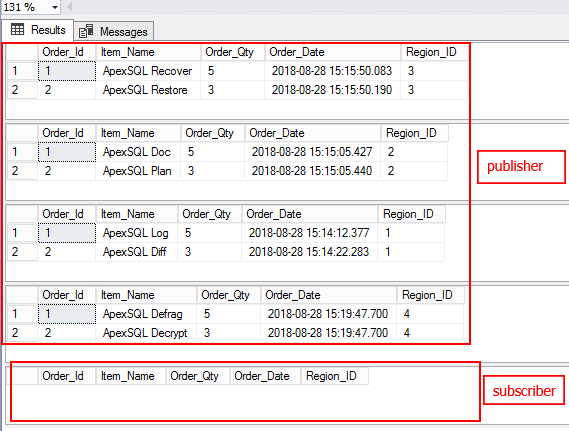
Query the publisher and subscriber database. You noticed that there are missing numbers of rows at the subscriber database.
查询发布者和订阅者数据库。 您注意到订户数据库中缺少行数。
-
- Start ApexSQL Log 启动ApexSQL日志
In the Select database, type in Server and Database details and Click Next
在“ 选择数据库”中 ,键入“ 服务器和数据库详细信息”,然后单击“ 下一步”。
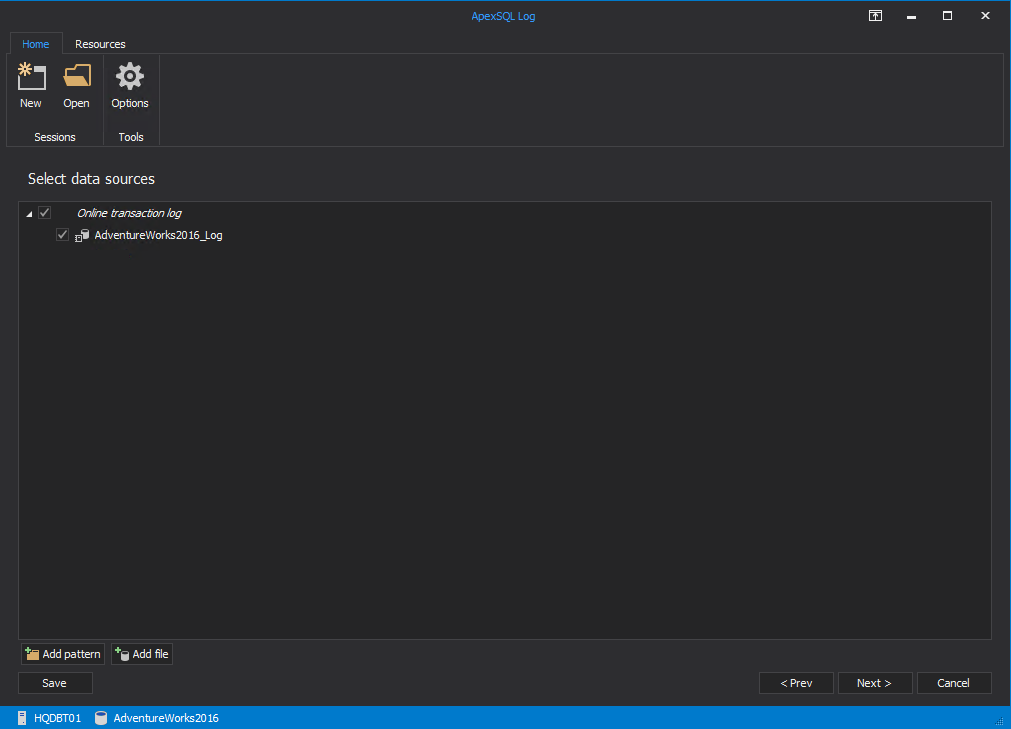
In Select data sources, leave the default Online transaction log option. This option allows the application to read online transaction log files.
在“ 选择数据源”中 ,保留默认的“ 在线事务日志”选项。 此选项允许应用程序读取在线事务日志文件。
Next, prepare redo script by selecting Undo/Redo script
接下来,通过选择撤消/重做脚本来准备重做脚本
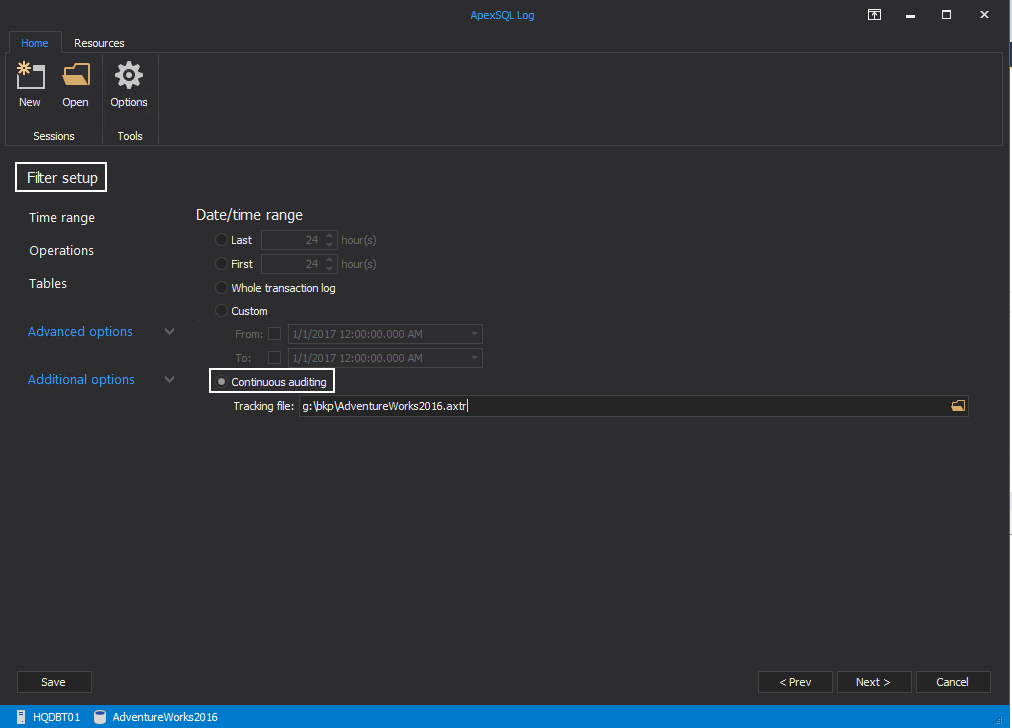
Now, In the Filter setup, select continuous auditing feature. The tracking file is a unique feature and it induces an intelligence to track the entire transactions by maintaining the LSN (Log Sequence Number) value. The safeguards integrity of the entire transactions.
现在,在“筛选器设置”中,选择“ 连续审核”功能。 跟踪文件是一个独特的功能,它通过保持LSN(日志序列号)值来诱导智能来跟踪整个事务。 保障整个交易的完整性。
In the Tables, select the object to be published on the central subscriber. In this case, the table Orders is selected as publishing article.
在表中,选择要在中央订户上发布的对象。 在这种情况下,表Orders被选择为发布文章。
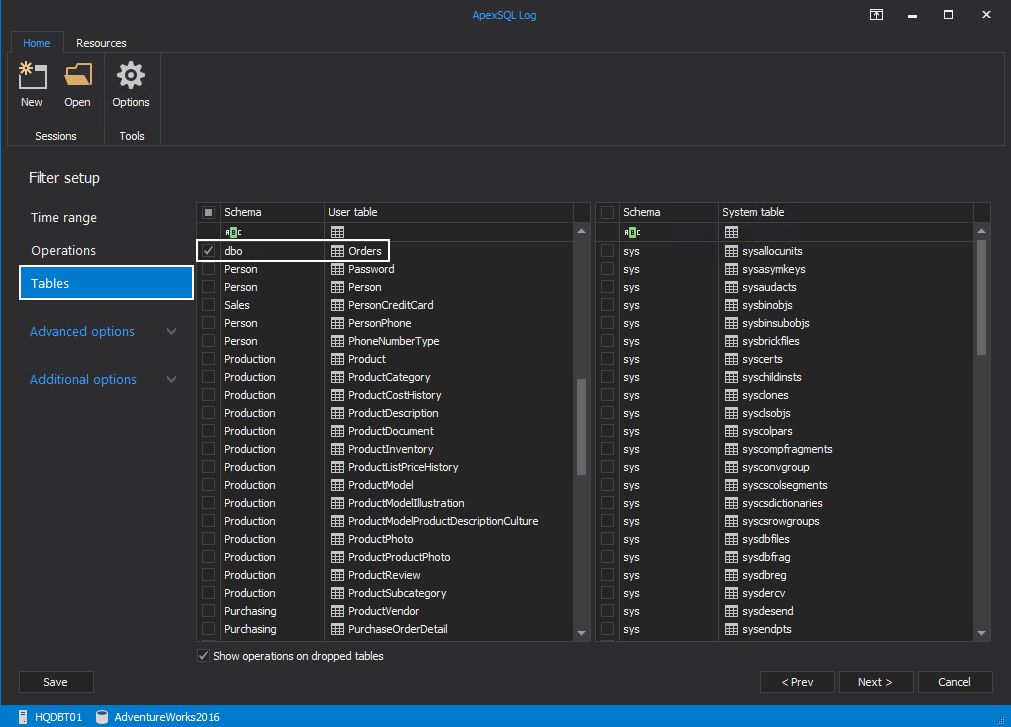
The configuration is all most done for the publisher database. Let’s save the batch script in the “Batch file”. Save the command as replication.BAT.
对于发布者数据库,大多数配置已完成。 让我们将批处理脚本保存在“批处理文件”中。 将命令另存为Replication.BAT 。
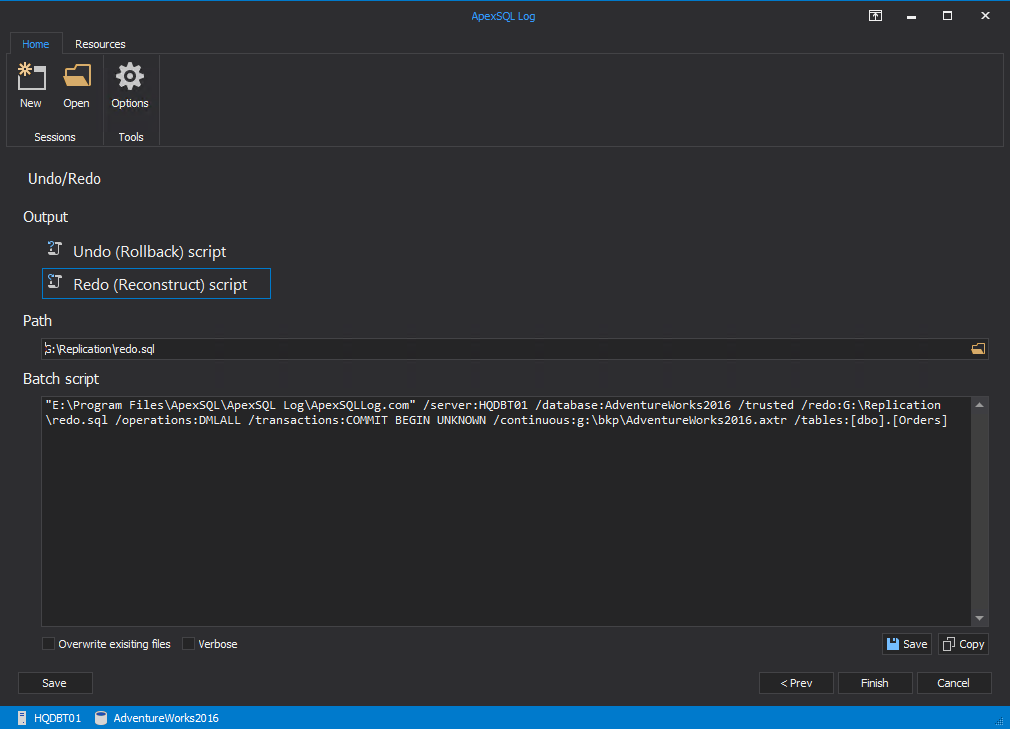
The batch file content is shown below
批处理文件的内容如下所示
“E:\Program Files\ApexSQL\ApexSQL Log\ApexSQLLog.com” /server:HQDBT01 /database:AdventureWorks2016 /trusted /redo:G:\Replication\redo.sql /operations:DMLALL /transactions:COMMIT BEGIN UNKNOWN /continuous:g:\bkp\AdventureWorks2016.axtr /tables:[dbo].[Orders]
“ E:\ Program Files \ ApexSQL \ ApexSQL Log \ ApexSQLLog.com” / server:HQDBT01 / database:AdventureWorks2016 / trusted /redo:G:\Replication\redo.sql / operations:DMLALL / transactions:COMMIT BEGIN UNKNOWN / continuous: g:\ bkp \ AdventureWorks2016.axtr / tables:[dbo]。[订单]
-
- You also have an option to test individual set of CLI commands or you can have all in a batch file and run it through PowerShell 您还可以选择测试单独的CLI命令集,也可以将所有命令放在批处理文件中并通过PowerShell运行
- In this case, the CLI commands are integrated. It is very simple and straight-forward. You need to copy and paste the content one after the other as per the number of publisher databases. 在这种情况下,将集成CLI命令。 这非常简单明了。 您需要根据发布者数据库的数量一个接一个地复制粘贴内容。
- As you see, the ‘/database’ switch has four different databases and the ‘/continuous’ switch has four unique tracking files. 如您所见,“ / database”开关具有四个不同的数据库,而“ / continuous”开关具有四个唯一的跟踪文件。
The SQL file is uniquely identified with a name. The name of the file <Publisher Name_<Date and timestamp>.sql is prepared and fed to ‘/redo’ switch
SQL文件用名称唯一标识。 准备文件名称<Publisher Name_ <日期和时间戳> .sql并将其输入到'/ redo'开关
Build PowerShell Script Replication.ps1
生成PowerShell脚本Replication.ps1
- Load the SQL Server Module 加载SQL Server模块
- Assign the current date and timestamp value to $datetime variable 将当前日期和时间戳记值分配给$ datetime变量
- Pass the variable $datetime to ApexSQL Log CLI command 将变量$ datetime传递给ApexSQL Log CLI命令
- The batch file “replication.bat” is invoked and it generates four SQL replay files 批处理文件“ replication.bat”被调用并生成四个SQL重播文件
- Execute the SQL file in the same cadence using Invoke-SQLCMD 使用Invoke-SQLCMD以相同的节奏执行SQL文件
Import-Module SQLServer $datetime = (get-date).ToString("yyyyMMdd-HHmmss") cmd /c "G:\replication\replication.bat" $datetime Invoke-SQLcmd -inputfile "G:\replication\Publisher1_$datetime.sql" -serverinstance "hqdbt01" -database "AdventureWorks" Invoke-SQLcmd -inputfile "G:\replication\Publisher2_$datetime.sql" -serverinstance "hqdbt01" -database "AdventureWorks" Invoke-SQLcmd -inputfile "G:\replication\Publisher3_$datetime.sql" -serverinstance "hqdbt01" -database "AdventureWorks" Invoke-SQLcmd -inputfile "G:\replication\Publisher4_$datetime.sql" -serverinstance "hqdbt01" -database "AdventureWorks"Execute PowerShell script Replication.ps1
执行PowerShell脚本Replication.ps1
测试数据 (Test the data)
We can see that the aggregated set of rows got inserted into the subscriber databases.
我们可以看到,已聚合的行集已插入到订户数据库中。
:Connect HQDBT01\SQL2017 SELECT * FROM WideWorldImporters.dbo.Orders GO :Connect HQDBT01 SELECT * FROM Adventureworks2016.dbo.Orders GO :Connect HQDBT01 SELECT * FROM Adventureworks2014.dbo.Orders GO :Connect HQDBT01 SELECT * FROM Adventureworks2012.dbo.Orders GO :Connect HQDBT01 SELECT * FROM Adventureworks.dbo.Orders
安排工作 (Schedule a job)
To automate, schedule the PowerShell script to run at any interval you want e.g. 5 minutes. Refer to the scheduling section in this article How to set up a DDL and DML SQL Server database transactional replication solution
要实现自动化,请安排PowerShell脚本以您希望的任何间隔(例如5分钟)运行。 请参阅本文中的计划部分, 如何设置DDL和DML SQL Server数据库事务复制解决方案
结语 (Wrap Up)
In the article we reviewed the “central subscriber with multiple publishers” use-case and then designed and built the system using a 3rd party tool, ApexSQL Log, a SQL Server transaction log reader, and common scripting technologies e.g. batch files and PowerShell.
在本文中,我们回顾了“具有多个发布者的中央订户”用例,然后使用第三方工具,ApexSQL Log,SQL Server事务日志读取器以及常见的脚本技术(例如批处理文件和PowerShell)设计和构建了系统。
I re-iterate the importance of replication design. Data replication design is a balancing act between managing data at its various forms. Replication design techniques are vital and things get complicated quickly if we’ve not designed properly. For example, in this model, subscribers should be treated as read-only because changes are not propagated back to the publisher. So inserts, updates, and deletes should be avoided at the subscriber database as this could lead to non-convergence.
我重申复制设计的重要性。 数据复制设计是在以各种形式管理数据之间的一种平衡行为。 复制设计技术至关重要,如果设计不当,事情会很快变得复杂。 例如,在此模型中,应将订阅者视为只读,因为更改不会传播回发布者。 因此,应避免在订户数据库上进行插入,更新和删除,因为这可能导致不收敛。
That’s all for now… If you feel like giving it a try, feel free to let me know how it went on the comments below
现在就这些了...如果您想尝试一下,请随时让我知道它在下面的评论中是如何进行的
附录 (Appendix)
Batch Script
批处理脚本
@echo off
@回声关闭
SET “redofile=%1”
设置“ redofile =%1”
“E:\Program Files\ApexSQL\ApexSQL Log\ApexSQLLog.com” /server:HQDBT01 /database:AdventureWorks2016 /trusted /redo:G:\Replication\publisher1_%redofile%.sql /operations:DMLALL /transactions:COMMIT BEGIN UNKNOWN /continuous:g:\bkp\AdventureWorks2016.axtr /tables:[dbo].[Orders]
“ E:\ Program Files \ ApexSQL \ ApexSQL Log \ ApexSQLLog.com” / server:HQDBT01 / database:AdventureWorks2016 / trusted /redo:G:\Replication\publisher1_%redofile%.sql / operations:DMLALL / transactions:COMMIT BEGIN UNKNOWN /continuous:g:\bkp\AdventureWorks2016.axtr / tables:[dbo]。[订单]
“E:\Program Files\ApexSQL\ApexSQL Log\ApexSQLLog.com” /server:HQDBT01 /database:AdventureWorks2014 /trusted /redo:G:\Replication\publisher2_%redofile%.sql /operations:DMLALL /transactions:COMMIT BEGIN UNKNOWN /continuous:g:\bkp\AdventureWorks2014.axtr /tables:[dbo].[Orders]
“ E:\ Program Files \ ApexSQL \ ApexSQL Log \ ApexSQLLog.com” / server:HQDBT01 / database:AdventureWorks2014 / trusted /redo:G:\Replication\publisher2_%redofile%.sql / operations:DMLALL / transactions:COMMIT BEGIN UNKNOWN /continuous:g:\bkp\AdventureWorks2014.axtr / tables:[dbo]。[订单]
“E:\Program Files\ApexSQL\ApexSQL Log\ApexSQLLog.com” /server:HQDBT01 /database:AdventureWorks2012 /trusted /redo:G:\Replication\publisher3_%redofile%.sql /operations:DMLALL /transactions:COMMIT BEGIN UNKNOWN /continuous:g:\bkp\AdventureWorks2012.axtr /tables:[dbo].[Orders]
“ E:\ Program Files \ ApexSQL \ ApexSQL Log \ ApexSQLLog.com” / server:HQDBT01 / database:AdventureWorks2012 / trusted /redo:G:\Replication\publisher3_%redofile%.sql / operations:DMLALL / transactions:COMMIT BEGIN UNKNOWN /continuous:g:\bkp\AdventureWorks2012.axtr / tables:[dbo]。[订单]
“E:\Program Files\ApexSQL\ApexSQL Log\ApexSQLLog.com” /server:HQDBT01\SQL2017 /database:WideWorldImporters /trusted /redo:G:\Replication\publisher4_%redofile%.sql /operations:DMLALL /transactions:COMMIT BEGIN UNKNOWN /continuous:g:\bkp\WideWorldImporters.axtr /tables:[dbo].[Orders]
“ E:\ Program Files \ ApexSQL \ ApexSQL Log \ ApexSQLLog.com” / server:HQDBT01 \ SQL2017 / database:WideWorldImporters / trusted /redo:G:\Replication\publisher4_%redofile%.sql / operations:DMLALL / transactions:COMMIT开始未知/continuous:g:\bkp\WideWorldImporters.axtr / tables:[dbo]。[订单]
SQL
SQL
:Connect <Publisher1> Use Adventureworks2016 GO CREATE TABLE Orders( Order_Id int, Item_Name varchar(100), Order_Qty int, Order_Date DATETIME default GETDATE(), Region_ID int, CONSTRAINT PK_OrdersRegion PRIMARY KEY (Order_Id,Region_ID) ) INSERT INTO Orders VALUES (1,'ApexSQL Recover',5,Getdate(),3) INSERT INTO Orders VALUES (2,'ApexSQL Restore',3,Getdate(),3) :Connect <Publisher1> Use Adventureworks2016 GO CREATE TABLE Orders( Order_Id int, Item_Name varchar(100), Order_Qty int, Order_Date DATETIME default GETDATE(), Region_ID int, CONSTRAINT PK_OrdersRegion PRIMARY KEY (Order_Id,Region_ID) ) INSERT INTO Orders VALUES (1,'ApexSQL Defrag',5,Getdate(),4) INSERT INTO Orders VALUES (2,'ApexSQL Decrypt',3,Getdate(),4) :Connect <Publisher3> Use Adventureworks2016 GO CREATE TABLE Orders( Order_Id int, Item_Name varchar(100), Order_Qty int, Order_Date DATETIME default GETDATE(), Region_ID int, CONSTRAINT PK_OrdersRegion PRIMARY KEY (Order_Id,Region_ID) ) INSERT INTO Orders VALUES (1,'ApexSQL Defrag',5,Getdate(),2) INSERT INTO Orders VALUES (2,'ApexSQL Decrypt',3,Getdate(),2) :Connect <Publisher4> Use Adventureworks2016 GO CREATE TABLE Orders( Order_Id int, Item_Name varchar(100), Order_Qty int, Order_Date DATETIME default GETDATE(), Region_ID int, CONSTRAINT PK_OrdersRegion PRIMARY KEY (Order_Id,Region_ID) ) INSERT INTO Orders VALUES (1,'ApexSQL Defrag',5,Getdate(),1) INSERT INTO Orders VALUES (2,'ApexSQL Decrypt',3,Getdate(),1)目录 (Table of contents)
SQL Server复制:组件和拓扑概述 SQL复制:基本设置和配置 如何从SQL Server中的现有出版物中添加/删除文章 如何对两个大型SQL Server数据库中的数据进行快速估计比较,以查看它们是否相等 SQL Server事务复制:如何使用SQL Server数据库备份重新初始化订阅 如何使用中央订阅服务器和多个发布者数据库设置自定义SQL Server事务复制模型 如何使用中央发布者和多个订阅者数据库设置自定义SQL Server事务复制 如何设置DDL和DML SQL Server数据库事务复制解决方案 如何在Linux上为数据库报告设置跨平台事务SQL Server复制 SQL Server数据库迁移,数据丢失为零,停机时间为零 使用事务数据复制来重放和测试登台服务器上的生产负载 如何为报表服务器设置SQL Server数据库复制 SQL Server事务复制:如何使用“仅复制支持” –TBA重新初始化订阅 使用PowerShell –TBASQL Server复制监视和设置警报

















 210
210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









