





Bringing impactful analysis into a data always comes with challenges. In many cases, we rely on automated tools and techniques to overcome many of these challenges.
将有影响力的分析纳入数据始终会带来挑战。 在许多情况下,我们依靠自动化工具和技术来克服许多挑战。
In this article, we’ll describe a simple task to validate the table (row count only) between the databases on different SQL instances. For our use case, let us consider a scenario involving transactional replication, as a good practice; it is required to perform data validation test between Publisher and Subscriber databases to validate the integrity of our replication process. It is quite evident that a simple validation process helps to identify the state of the subscriber. If there is a difference in the data, it’s pretty much advised to re-initialize the subscription with the latest snapshot.
在本文中,我们将描述一个简单的任务来验证不同SQL实例上的数据库之间的表(仅行计数)。 对于我们的用例,让我们考虑一个涉及事务复制的场景,这是一个好习惯。 需要在发布服务器和订阅服务器之间执行数据验证测试,以验证复制过程的完整性。 很明显,简单的验证过程有助于识别订户的状态。 如果数据存在差异,建议您使用最新快照重新初始化订阅。
介绍 (Introduction)
There are several reasons why we might need to consider table comparison. In a robust replication system, one has to audit the integrity of the data. The audit process ensures that the data produced from various automation tools or batch jobs are correct. Also, when you pass the values on the subscription database, it should return the near-production values.
我们可能需要考虑表比较的原因有几个。 在一个强大的复制系统中,必须审核数据的完整性。 审核过程可确保从各种自动化工具或批处理作业生成的数据是正确的。 同样,当您在订阅数据库上传递值时,它应该返回接近生产的值。
SQL Server Transactional replication has an option to validate the data at the Subscriber with data at the Publisher. Validation can be performed for specific subscriptions or for all subscriptions to a publication. We can specify the ‘Row count only’ option as the validation type and the Distribution Agent will validate data when it runs for the next time. But if we create our own replication scenario, independent of SQL Server replication, we will want to duplicate this feature to ensure our databases are in sync
SQL Server事务复制具有一个选项,可以用发布服务器上的数据验证订阅服务器上的数据。 可以对特定订阅或出版物的所有订阅执行验证。 我们可以将“仅行数”选项指定为验证类型,并且分发代理将在下次运行数据时对其进行验证。 但是,如果创建独立于SQL Server复制的自己的复制方案,我们将希望复制此功能以确保数据库同步
In this article, we will simulate the “Row count only” process of Microsoft’s SQL Server database replication solution. In this validation process, the tables are compared for a number of rows between Publisher and Subscriber but it does not validate the content of the data. It is considered as a lightweight approach to validate the number of rows between publisher and subscriber.
在本文中,我们将模拟MicrosoftSQL Server数据库复制解决方案的“仅行计数”过程。 在此验证过程中,将比较表中发布者和订阅者之间的许多行,但不会验证数据的内容。 它被认为是验证发布者和订阅者之间行数的一种轻量级方法。
目的 (Objective)
实施“仅行计数”过程以比较发布者数据库与订阅者数据库之间的行数,并在发现表之间的行数差异时发送警报电子邮件。实施概述 (Overview of the implementation)
自动化 (Automation)
The steps to setup automation are as follows:
设置自动化的步骤如下:
Enable “Ad Hoc Distributed Queries” advanced configuration option
启用“ 临时分布式查询”高级配置选项
EXEC sp_configure 'show advanced options', 1 RECONFIGURE GO EXEC sp_configure 'ad hoc distributed queries', 1 RECONFIGURE GOUse OPENROWSET to query a remote SQL instance. To use the OPENROWSET ad hoc method, provide all the data source information in the connection string. For example, to run a remote query on XYZ server
使用OPENROWSET查询远程SQL实例。 要使用OPENROWSET ad hoc方法,请在连接字符串中提供所有数据源信息。 例如,在XYZ服务器上运行远程查询
- Use SQLNCLI provider 使用SQLNCLI提供程序
- Pass the <ServerName> as an input value to Server parameter 将<ServerName>作为输入值传递到Server参数
- Set the connection type. In this case, it’s trusted. So, its set to ‘yes’ 设置连接类型。 在这种情况下,它是受信任的。 因此,将其设置为“是”
- Pass T-SQL string 传递T-SQL字符串
SELECT q.* FROM OPENROWSET('SQLNCLI', 'Server=hqdbt01\SQL2017;Trusted_Connection=yes;', 'select * from [WideWorldImporters].[Sales].[Invoices]') as q;

Getting the row count of tables in the source database
获取源数据库中表的行数
There are several different ways get the row-count of the table in a database, but probably the fastest technique to get row count is by using system view sys.partitions.
有几种不同的方法来获取数据库中表的行数,但是获取行数的最快方法可能是使用系统视图sys.partitions 。
Using the following SQL, the row count of the table is listed.
使用以下SQL,列出表的行数。
SELECT Max(@@SERVERNAME) ServerName, Max(DB_NAME(DB_ID())) DatabaseName, sch.name AS SchemaName, st.Name AS TableName, SUM( CASE WHEN (p.index_id < 2) AND (a.type = 1) THEN p.rows ELSE 0 END ) AS Rows FROM sys.partitions p INNER JOIN sys.allocation_units a ON p.partition_id = a.container_id INNER JOIN sys.tables st ON st.object_id = p.object_id INNER JOIN sys.schemas sch ON sch.schema_id = st.schema_id GROUP BY st.name, sch.name
Getting the row count of tables in the remote database
获取远程数据库中表的行数
In order to do this, the OpenRowSet method is used. You can refer step2 for more information.
为此,使用了OpenRowSet方法。 您可以参考step2以获得更多信息。
SELECT a.* FROM OPENROWSET('SQLNCLI', 'Server=hqdbt01\SQL2017;Trusted_Connection=yes;', 'SELECT Max(@@SERVERNAME) ServerName, Max(DB_NAME(DB_ID(''WideWorldImporters''))) DatabaseName, sch.name AS SchemaName, st.Name AS TableName, SUM( CASE WHEN (p.index_id < 2) AND (a.type = 1) THEN p.rows ELSE 0 END ) AS Rows FROM WideWorldImporters.sys.partitions p INNER JOIN WideWorldImporters.sys.allocation_units a ON p.partition_id = a.container_id INNER JOIN WideWorldImporters.sys.tables st ON st.object_id = p.Object_ID INNER JOIN WideWorldImporters.sys.schemas sch ON sch.schema_id = st.schema_id GROUP BY st.name, sch.name') AS a;Compare the number of rows between source and Target
比较源和目标之间的行数
The step 3 sets up first part of the data set and step 4 defines the second data set. Both the result sets are captured in a table variable named @sourcedatabase and @targetDatabase.
步骤3设置数据集的第一部分,而步骤4定义第二数据集。 这两个结果集都捕获在名为@sourcedatabase和@targetDatabase的表变量中。
DECLARE @SourceDatabase table ( Instance sysname, DB varchar(100), SchemaName VARCHAR(100), TableName VARCHAR(100), Rows INT ) INSERT INTO @SourceDatabase SELECT Max(@@SERVERNAME) ServerName, Max(DB_NAME(DB_ID())) DatabaseName, sch.name AS SchemaName, st.Name AS TableName, SUM( CASE WHEN (p.index_id < 2) AND (a.type = 1) THEN p.rows ELSE 0 END ) AS Rows FROM sys.partitions p INNER JOIN sys.allocation_units a ON p.partition_id = a.container_id INNER JOIN sys.tables st ON st.object_id = p.object_id INNER JOIN sys.schemas sch ON sch.schema_id = st.schema_id GROUP BY st.name, sch.name DECLARE @TargetDatabase table ( Instance sysname, DB varchar(100), SchemaName VARCHAR(100), TableName VARCHAR(100), Rows INT ) INSERT INTO @TargetDatabase SELECT a.* FROM OPENROWSET('SQLNCLI', 'Server=hqdbt01\SQL2017;Trusted_Connection=yes;', 'SELECT Max(@@SERVERNAME) ServerName, Max(DB_NAME(DB_ID(''WideWorldImporters''))) DatabaseName, sch.name AS SchemaName, st.Name AS TableName, SUM( CASE WHEN (p.index_id < 2) AND (a.type = 1) THEN p.rows ELSE 0 END ) AS Rows FROM WideWorldImporters.sys.partitions p INNER JOIN WideWorldImporters.sys.allocation_units a ON p.partition_id = a.container_id INNER JOIN WideWorldImporters.sys.tables st ON st.object_id = p.Object_ID INNER JOIN WideWorldImporters.sys.schemas sch ON sch.schema_id = st.schema_id GROUP BY st.name, sch.name') AS a;Join the two table variable using schema and tablename columns
使用schema和tablename列联接两个表变量
select s.Instance SourceInstance, t.Instance TargetInstance, s.DB SourceDatabase, t.DB TargetDatabase, s.SchemaName SourceSchemaName, t.SchemaName TargetSchemaName, s.TableName SourceTableName, t.TableName TargetTableName, s.rows as SourceRowCount, t.rows as DestRowCount, case when s.rows>t.rows then s.Rows-t.Rows else t.Rows-s.Rows end 'Missing Rows', case when s.rows>t.rows then '<=' when s.Rows=t.Rows then '=' else '=>' end 'Comparison' from @SourceDatabase s, @TargetDatabase t where s.SchemaName=t.SchemaName and s.TableName = t.TableName -- and --s.rows!=t.rowsYou can see the difference in number of rows in the following output
您可以在以下输出中看到行数的差异
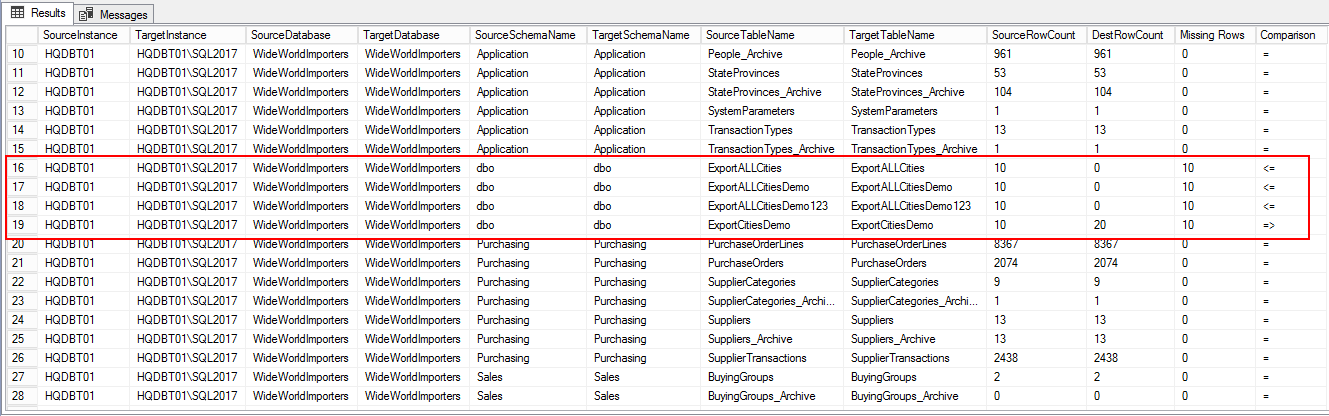
Prepare email alert
准备电子邮件警报
In this section, Let us make the necessary arrangement to wrap the values in the table data <TD> tag. This is the format needed to build HTML table tags. In this case, td is used as the column alias for all columns and specified by the ‘tr’ as the root element for each row. Then the concatenated output is sent as an HTML body using sp_send_dbmail option.
在本节中,让我们进行必要的安排以将值包装在表数据<TD>标记中。 这是构建HTML表标签所需的格式。 在这种情况下,td用作所有列的列别名,并由'tr'指定为每一行的根元素。 然后,使用sp_send_dbmail选项将并置的输出作为HTML正文发送。
IF((Select count(*) from @SourceDatabase s, @TargetDatabase t where s.SchemaName=t.SchemaName and s.TableName = t.TableName and s.rows!=t.rows)>0) begin DECLARE @tableHTML NVARCHAR(MAX) ; SET @tableHTML = N'<H1>Row Comparison Report</H1>' + N'<table border="1">' + N'<tr><th>[Source Instance]</th> <th>[Target Instance]</th> <th>[Source DB] </th> <th>[Target DB]</th> <th>[Source Schema]</th> <th>[Target Schema]</th> <th>[Source Table]</th> <th>[Target Table]</th> <th>[Source RowCount]</th> <th>[Target RowCount]</th> <th> [Missing Rows]</th> <th> [Compariosn]</th> </tr>' + CAST ( ( select td=s.Instance ,' ', td=t.Instance ,' ', td=s.DB,' ', td=t.DB, ' ', td=s.SchemaName,' ', td=t.SchemaName,' ', td=s.TableName,' ', td=t.TableName, ' ', td=cast(s.rows as varchar(10)),' ', td=cast(t.rows as varchar(10)), ' ', td=case when s.rows>t.rows then cast((s.Rows-t.Rows) as varchar(10))else cast((t.Rows-s.Rows) as varchar(10)) end ,' ', td=case when s.rows>t.rows then '<=' when s.Rows=t.Rows then '=' else '=>' end, ' ' from @SourceDatabase s, @TargetDatabase t where s.SchemaName=t.SchemaName and s.TableName = t.TableName and s.rows!=t.rows FOR XML PATH('tr'), TYPE ) AS NVARCHAR(MAX) ) + N'</table>' ; EXEC msdb.dbo.sp_send_dbmail @recipients='pjayaram@SQL.com', @subject = 'Row Comparison Report', @profile_name='PowerSQL', @body = @tableHTML, @body_format = 'HTML' ; END
Output
输出量

结语 (Wrap Up)
So far, we’ve seen the steps to simulate “Row count only” option. In reality, there is no ideal method can be used to compare the results. If you’re working one of the very few tables, then tablediff is also an option. Also, you could rely on 3rd party tools such as ApexSQL Diff data compare option to validate a number of rows between the databases. I would leave this option open. What are your favorite methods? Please leave the feedback input in comments…
到目前为止,我们已经看到了模拟“仅行数”选项的步骤。 实际上,没有理想的方法可以用来比较结果。 如果您要处理的表很少,那么tablediff也是一种选择。 此外,你可以依靠第三方工具如ApexSQL DIFF数据比较选项以验证数字数据库之间的行。 我会将此选项保持打开状态。 您最喜欢的方法是什么? 请在评论中留下反馈意见…
That’s all for now…
目前为止就这样了…
附录 (Appendix)
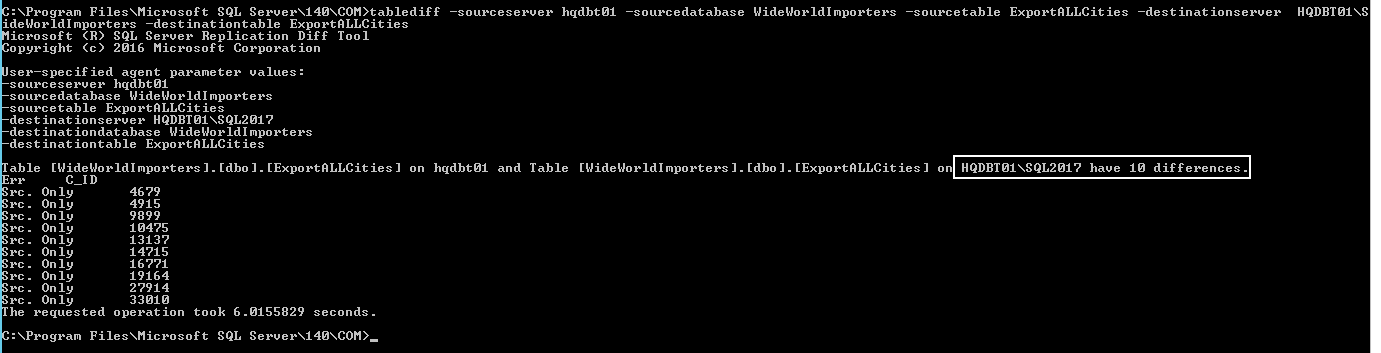
Another solution we can use is tablediff utility. For example, if you want to compare two tables (ExportALLCities) from two databases on two different servers, you run the following command
我们可以使用的另一个解决方案是tablediff实用程序。 例如,如果要比较两个不同服务器上的两个数据库中的两个表(ExportALLCities),请运行以下命令
C:\Program Files\Microsoft SQL Server\140\COM>tablediff -sourceserver hqdbt01 -sourcedatabase WideWorldImporters -sourcetable ExportALLCities -destinationserver HQDBT01\SQL2017 -destinationdatabase WideWorldImporters -destinationtable ExportALLCities
C:\ Program Files \ Microsoft SQL Server \ 140 \ COM> tablediff -sourceserver hqdbt01 -sourcedatabase WideWorldImporters -sourcetable ExportALLCities -destinationserver HQDBT01 \ SQL2017 -destinationdatabase WideWorldImporters -destinationtable ExportALLCities
T-SQL Script
T-SQL脚本
EXEC sp_configure 'show advanced options', 1
RECONFIGURE
GO
EXEC sp_configure 'ad hoc distributed queries', 1
RECONFIGURE
GO
DECLARE @SourceDatabase table
(
Instance sysname,
DB varchar(100),
SchemaName VARCHAR(100),
TableName VARCHAR(100),
Rows INT
)
INSERT INTO @SourceDatabase
SELECT
Max(@@SERVERNAME) ServerName,
Max(DB_NAME(DB_ID())) DatabaseName,
sch.name AS SchemaName,
st.Name AS TableName,
SUM(
CASE
WHEN (p.index_id < 2) AND (a.type = 1) THEN p.rows
ELSE 0
END
) AS Rows
FROM sys.partitions p
INNER JOIN sys.allocation_units a ON p.partition_id = a.container_id
INNER JOIN sys.tables st ON st.object_id = p.object_id
INNER JOIN sys.schemas sch ON sch.schema_id = st.schema_id
GROUP BY st.name, sch.name
DECLARE @TargetDatabase table
(
Instance sysname,
DB varchar(100),
SchemaName VARCHAR(100),
TableName VARCHAR(100),
Rows INT
)
INSERT INTO @TargetDatabase
SELECT a.*
FROM OPENROWSET('SQLNCLI', 'Server=hqdbt01\SQL2017;Trusted_Connection=yes;',
'SELECT
Max(@@SERVERNAME) ServerName,
Max(DB_NAME(DB_ID(''WideWorldImporters''))) DatabaseName,
sch.name AS SchemaName,
st.Name AS TableName,
SUM(
CASE
WHEN (p.index_id < 2) AND (a.type = 1) THEN p.rows
ELSE 0
END
) AS Rows
FROM WideWorldImporters.sys.partitions p
INNER JOIN WideWorldImporters.sys.allocation_units a ON p.partition_id = a.container_id
INNER JOIN WideWorldImporters.sys.tables st ON st.object_id = p.Object_ID
INNER JOIN WideWorldImporters.sys.schemas sch ON sch.schema_id = st.schema_id
GROUP BY st.name, sch.name') AS a;
select
s.Instance SourceInstance,
t.Instance TargetInstance,
s.DB SourceDatabase,
t.DB TargetDatabase,
s.SchemaName SourceSchemaName,
t.SchemaName TargetSchemaName,
s.TableName SourceTableName,
t.TableName TargetTableName,
s.rows as SourceRowCount,
t.rows as DestRowCount,
case when s.rows>t.rows then s.Rows-t.Rows else t.Rows-s.Rows end 'Missing Rows',
case when s.rows>t.rows then '<='
when s.Rows=t.Rows then '='
else '=>' end 'Comparison'
from
@SourceDatabase s, @TargetDatabase t
where
s.SchemaName=t.SchemaName and
s.TableName = t.TableName
and
s.rows!=t.rows
IF((Select count(*) from
@SourceDatabase s, @TargetDatabase t
where
s.SchemaName=t.SchemaName and
s.TableName = t.TableName
and
s.rows!=t.rows)>0)
begin
DECLARE @tableHTML NVARCHAR(MAX) ;
SET @tableHTML =
N'<H1>Row Comparison Report</H1>' +
N'<table border="1">' +
N'<tr><th>[Source Instance]</th>
<th>[Target Instance]</th>
<th>[Source DB] </th>
<th>[Target DB]</th>
<th>[Source Schema]</th>
<th>[Target Schema]</th>
<th>[Source Table]</th>
<th>[Target Table]</th>
<th>[Source RowCount]</th>
<th>[Target RowCount]</th>
<th> [Missing Rows]</th>
<th> [Compariosn]</th>
</tr>' +
CAST ( (
select
td=s.Instance ,' ',
td=t.Instance ,' ',
td=s.DB,' ',
td=t.DB, ' ',
td=s.SchemaName,' ',
td=t.SchemaName,' ',
td=s.TableName,' ',
td=t.TableName, ' ',
td=cast(s.rows as varchar(10)),' ',
td=cast(t.rows as varchar(10)), ' ',
td=case when s.rows>t.rows then cast((s.Rows-t.Rows) as varchar(10))else cast((t.Rows-s.Rows) as varchar(10)) end ,' ',
td=case when s.rows>t.rows then '<='
when s.Rows=t.Rows then '='
else '=>' end, ' '
from
@SourceDatabase s, @TargetDatabase t
where
s.SchemaName=t.SchemaName and
s.TableName = t.TableName
and
s.rows!=t.rows
FOR XML PATH('tr'), TYPE
) AS NVARCHAR(MAX) ) +
N'</table>' ;
EXEC msdb.dbo.sp_send_dbmail @recipients='pjayaram@SQL.com',
@subject = 'Row Comparison Report',
@profile_name='PowerSQL',
@body = @tableHTML,
@body_format = 'HTML' ;
END
目录 (Table of contents)
| SQL Server复制:组件和拓扑概述 |
| SQL复制:基本设置和配置 |
| 如何从SQL Server中的现有出版物中添加/删除文章 |
| 如何对两个大型SQL Server数据库中的数据进行快速估计比较,以查看它们是否相等 |
| SQL Server事务复制:如何使用SQL Server数据库备份重新初始化订阅 |
| 如何使用中央订阅服务器和多个发布者数据库设置自定义SQL Server事务复制模型 |
| 如何使用中央发布者和多个订阅者数据库设置自定义SQL Server事务复制 |
| 如何设置DDL和DML SQL Server数据库事务复制解决方案 |
| 如何在Linux上为数据库报告设置跨平台事务SQL Server复制 |
| SQL Server数据库迁移,数据丢失为零,停机时间为零 |
| 使用事务数据复制来重放和测试登台服务器上的生产负载 |
| 如何为报表服务器设置SQL Server数据库复制 |
| SQL Server事务复制:如何使用“仅复制支持” –TBA重新初始化订阅 |
| 使用PowerShell –TBASQL Server复制监视和设置警报 |















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









