





 本文介绍了逻辑复制,包括其异步性质、灵活性和在HA/DR、报告卸载及数据库升级中的应用。对比了物理复制,强调了逻辑复制的异构环境适应性和数据选择性。还探讨了IBM InfoSphere CDC、Quest SharePlex和Oracle GoldenGate等供应商的逻辑复制解决方案,并总结了SQL Server事务复制的架构、限制和未来趋势。
本文介绍了逻辑复制,包括其异步性质、灵活性和在HA/DR、报告卸载及数据库升级中的应用。对比了物理复制,强调了逻辑复制的异构环境适应性和数据选择性。还探讨了IBM InfoSphere CDC、Quest SharePlex和Oracle GoldenGate等供应商的逻辑复制解决方案,并总结了SQL Server事务复制的架构、限制和未来趋势。
介绍 (Introduction)
Data replication has been around for many decades. There are two primary types of data replication, logical and physical. This article covers a high-level view of logical replication, the differences between logical and physical replication and the specifics of SQL Server transactional replication.
数据复制已经存在了数十年。 数据复制有两种主要类型,逻辑复制和物理复制。 本文概述了逻辑复制,逻辑复制和物理复制之间的差异以及SQL Server事务复制的细节。
逻辑复制的共同特征 (Logical replication common characteristics)
Logical replication, also known as transactional replication, is a type of asynchronous replication and at a 10,000-foot level is very simple to understand. When two databases are set-up for replication, one being the source system and the other the target, selected Data Manipulation Language (DML – Inserts, Updates and Deletes) and in some cases Data Definition Language (DDL – Create Table, Truncate, etc.), through a series of processes and queues are read from the transaction log on the source system and then replayed on the target system. Hence, if performing an insert on the source system, that same insert is replayed on the target system. Also, selected DML or DDL, means you can pick and choose which tables to replicate, it does not have to be all the tables in the entire database.
逻辑复制,也称为事务复制,是一种异步复制,在10,000英尺的高度上非常容易理解。 设置两个数据库进行复制时,一个数据库是源系统,另一个数据库是目标数据库,选择数据操作语言(DML –插入,更新和删除),在某些情况下选择数据定义语言(DDL –创建表,截断等) 。),通过一系列过程和队列从源系统上的事务日志中读取,然后在目标系统上重播。 因此,如果在源系统上执行插入,则在目标系统上将重播相同的插入。 同样,选择DML或DDL,意味着您可以选择要复制的表,而不必是整个数据库中的所有表。
This concept is quite different than physical/block level replication, where any changed block on the source system is replicated to the target system (discussed later on in this article).
此概念与物理/块级复制完全不同,后者将源系统上任何更改的块复制到目标系统(本文稍后将讨论)。
The common characteristics of most, if not all, logical replication solutions is a process to read or scrape transactions from the transaction log (or make a call to a vendor- provided database API), store the transactions in either a dynamic memory queue, persistent queue at the file system level or an actual database, and then to have a process rebuild the transaction and apply it as a normal database user with the appropriate privileges for the tables being replicated to the target database.
大多数(如果不是全部)逻辑复制解决方案的共同特征是一种从事务日志中读取或抓取事务(或调用供应商提供的数据库API),将事务存储在动态内存队列中,持久化的过程。在文件系统级别或实际数据库中排队,然后让进程重建事务并将其作为普通数据库用户应用,并具有将表复制到目标数据库的适当特权。
There are many vendors in the replication space, which is discussed later in this article.
复制空间中有许多供应商,本文稍后将对此进行讨论。
逻辑复制用例 (Logical replication use cases)
Logical replication is a much more flexible solution than physical replication and offers many more use cases.
逻辑复制是比物理复制更加灵活的解决方案,并提供了更多的用例。
HA/DR (High Availability/Disaster Recovery)
HA / DR(高可用性/灾难恢复)
Logical replication is not bound by the same limitations as physical replication and can replicate between different hardware platforms, operating systems, database versions, and in some cases different databases.
逻辑复制不受与物理复制相同的限制,并且可以在不同的硬件平台,操作系统,数据库版本之间以及在某些情况下在不同的数据库之间进行复制。
Most database vendors provide an HA/DR solution with an enterprise license for their database and it makes sense to use it where possible. However, it may not support replication between different hardware platforms, operating systems or versions of the database. Use of a logical replication solution may need to be considered if the vendor- provided solution does not meet your requirements.
大多数数据库供应商都为HA / DR解决方案提供了其数据库的企业许可证,因此在可能的情况下使用它很有意义。 但是,它可能不支持在不同的硬件平台,操作系统或数据库版本之间进行复制。 如果供应商提供的解决方案不符合您的要求,则可能需要考虑使用逻辑复制解决方案。
Logical replication solution target databases are generally available for read and write, which is good if managed correctly. Generally speaking, DBAs manage the replication solution and will have direct access to both source and target systems along with system administrators. Most end-users do not access the data servers directly, but utilize an application that resides on a separate application server connected to a source data server as its repository. End-users accessing the application cause the application to make changes to the source data server repository, which is then replicated to the target server (See Figure 1). It is imperative that the DBA manages the target database so users cannot make any changes to the tables being replicated. In the case of an HA/DR scenario, all tables in the source database need to be replicated to the target.
逻辑复制解决方案目标数据库通常可用于读取和写入,如果管理得当,这很好。 一般而言,DBA管理复制解决方案,并将与系统管理员一起直接访问源系统和目标系统。 大多数最终用户不会直接访问数据服务器,而是利用驻留在连接到源数据服务器的单独应用程序服务器上的应用程序作为其存储库。 最终用户访问该应用程序会使该应用程序对源数据服务器存储库进行更改,然后将其复制到目标服务器(参见图1)。 必须由DBA管理目标数据库,以便用户不能对要复制的表进行任何更改。 对于高可用性/灾难恢复方案,需要将源数据库中的所有表复制到目标。
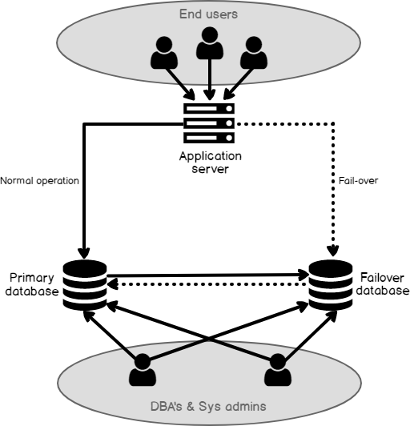
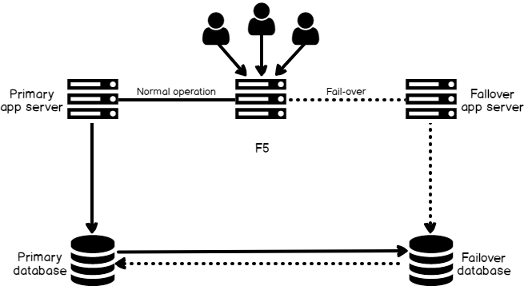
In an HA/DR scenario, the target system is an identical copy of the source system. If the source system goes down, the application server needs to be redirected to the target system, which will presume the role as the source system and start replicating back to the original source now acting as the target. Although the original source is down, logical replication solutions will store the changes until the source system recovers and then apply the queued changes when the database is accessible. Once everything gets caught up, the application server can be redirected back to the original source. Note that the redirecting of the application server is not managed by the replication solutions there are other solutions available to automate the fail-over process, such as F5, Big-IP, etc. (See Figure 2). Also, since the target system is available for read and write, reporting can be run off the target system to alleviate the load on the source system.
在HA / DR方案中,目标系统是源系统的相同副本。 如果源系统出现故障,则需要将应用程序服务器重定向到目标系统,该系统将假定该角色为源系统,并开始复制回到现在充当目标的原始源。 尽管原始源已关闭,但是逻辑复制解决方案将存储更改,直到源系统恢复为止,然后在可访问数据库时应用排队的更改。 一旦一切都准备就绪,就可以将应用程序服务器重定向回原始源。 请注意,应用程序服务器的重定向不受复制解决方案的管理,还有其他一些解决方案可用于自动执行故障转移过程,例如F5,Big-IP等(请参见图2)。 而且,由于目标系统可用于读取和写入,因此可以从目标系统运行报告,以减轻源系统的负担。
Off-load reporting
卸载报告
One of the most popular use cases for logical replication is off-loading of reporting to a target database. In a world of real-time, everyone wants current data. Hence the source on-line transaction processing system (OLTP) becomes the only source for live reporting, which can obviously cause performance issues.
逻辑复制最流行的用例之一是将报告卸载到目标数据库。 在实时世界中,每个人都需要最新数据。 因此,源在线事务处理系统(OLTP)成为实时报告的唯一源,这显然会导致性能问题。
The source OLTP system is usually very light on indexing. Indexing is not good for a database that gets a lot of inserts, update and delete activity, hence developers use as few indexes as possible. On the other hand, indexing is great for running queries. So you have a situation where queries are run against a database with little indexing which compounds the performance problems.
源OLTP系统通常在索引编制方面很轻。 索引对于具有大量插入,更新和删除活动的数据库不利,因此开发人员使用的索引越少越好。 另一方面,索引对于运行查询非常有用。 因此,您遇到的情况是,对数据库执行的查询几乎没有索引,这使性能问题更加复杂。
Replicating just the needed tables for reporting to a target system is a very valuable solution. Most logical replication solutions have the ability not only to pick and choose which tables to replicate, but can also apply “where clauses” to limit the data, and even choose which columns to replicate. Also, many solutions have the ability to do row level transformations including column concatenation, date manipulation, string manipulation, etc. Lastly, because it is a logical solution, the target system can be indexed as desired to improve query efficiency.
仅复制所需的表以报告给目标系统是非常有价值的解决方案。 大多数逻辑复制解决方案不仅具有选择要选择要复制的表的能力,而且还可以应用“ where子句”来限制数据,甚至可以选择要复制的列。 同样,许多解决方案都具有进行行级转换的能力,包括列串联,日期操作,字符串操作等。最后,由于这是一种逻辑解决方案,因此可以根据需要对目标系统进行索引,以提高查询效率。
Zero downtime migrations, database upgrades and application upgrades
零停机迁移,数据库升级和应用程序升级
This particular topic can be an article in its own. Many organizations have a “five nine’s” uptime requirement on their applications which is 99.99999% uptime, less than 6 minutes downtime per year. Hence, they need a technology that can allow them to perform patches, migrations, database upgrades, etc., with little to no downtime.
该特定主题可以是单独的文章。 许多组织的应用程序正常运行时间要求为“九五”,即正常运行时间为99.99999%,每年停机时间不到6分钟。 因此,他们需要一种允许他们执行补丁程序,迁移,数据库升级等,而停机时间很少甚至没有的技术。
Performing zero downtime migrations and database upgrades are not terribly complex but very procedural and must be done in an exact order. Performing zero downtime application upgrades, on the other hand, is a complex beast. It requires one to know the physical, as well as, logical differences between the current version of the application repository and the upgraded version so they differences can be mapped and transformed accordingly.
执行零宕机时间迁移和数据库升级并不是很复杂,但是程序性很强,必须按照确切的顺序进行。 另一方面,执行零停机应用程序升级是一件复杂的事情。 它要求人们知道应用程序存储库的当前版本和升级版本之间的物理差异和逻辑差异,以便可以相应地映射和转换它们之间的差异。
This use case is very valuable to organizations with tight uptime service level agreements (SLAs).
对于具有严格的正常运行时间服务水平协议(SLA)的组织,此用例非常有价值。
Active – active replication
主动-主动复制
Active – Active replication, also known as, Peer-to-Peer replication is by far the most complex replication use case. Since logical replication solutions are read/write, this becomes a valid use case in situations where organizations want to write to both systems and replicate back and forth for geographical reasons, such as the source server residing in New York and the target server in Los Angeles. In this type of scenario, active-active makes sense. The biggest issue with this use case is that applications are not designed to be Active – Active and will most likely need to be altered in some fashion to make this type of replication possible. The second biggest issue is managing conflicts, such as two users updating the same record at the same time. Some logical replications solutions provide for conflict resolution and detection (CDR), others do not.
主动式–主动式复制,也称为对等复制,是迄今为止最复杂的复制用例。 由于逻辑复制解决方案是可读写的,因此在组织出于地理原因要写入两个系统并来回复制的情况下(例如,位于纽约的源服务器和位于洛杉矶的目标服务器),这成为有效的用例。 。 在这种情况下,主动-主动是有意义的。 此用例的最大问题是应用程序并非设计为活动的-活动的,并且很可能需要以某种方式进行更改才能使这种复制成为可能。 第二大问题是管理冲突,例如两个用户同时更新同一记录。 一些逻辑复制解决方案提供了冲突解决和检测(CDR)功能,另一些则没有。
Regardless if CDR is provided with the replication solution, here are some general rules that need to be followed when configuring for this use case (this is for two servers in an active – active scenario):
无论复制解决方案是否提供了CDR,在配置此用例时(在活动-活动方案中用于两个服务器),都需要遵循一些通用规则:
- All tables need to have a primary key. 所有表都必须有一个主键。
- The primary keys’ values, as well as, unique index values must be unique to each system. Insert conflicts cannot really be managed at all and must be avoided. Uniquely generating primary key values and unique index values on each system avoid all insert conflicts. 主键的值以及唯一的索引值对于每个系统必须是唯一的。 插入冲突根本无法真正解决,必须避免。 在每个系统上唯一生成主键值和唯一索引值可避免所有插入冲突。
- If using sequences or identity columns, they must be offset or ranged. Offset is the preferred method where sequences or identity columns are odd values on one system and even on the other. 如果使用序列或标识列,则它们必须是偏移量或带范围的。 偏移是一种首选方法,其中序列或标识列在一个系统上甚至在另一个系统上都是奇数。
If the replication solution being used has CDR rules built in, then these rules will need to be configured for update/update conflicts, delete/delete conflicts and update/delete conflicts. If the solution does not have CDR rules, then conflicts must be avoided by making sure that from the system where the row originated, it can only be updated or deleted from that same system.
如果使用的复制解决方案内置了CDR规则,则将需要针对更新/更新冲突,删除/删除冲突和更新/删除冲突配置这些规则。 如果解决方案没有CDR规则,则必须通过确保只能从同一行更新或删除该行所在的系统来避免冲突。
Replication to big data
复制到大数据
With the growing popularity of Big Data, several of the major players in the logical replication arena have added Big Data to their list of replication targets.
随着大数据的日益普及,逻辑复制领域的一些主要参与者已将大数据添加到其复制目标列表中。
Several companies can now replicate DML one-way to Hadoop, HDFS, Hive, Kafka, Hbase, etc.
现在有多家公司可以将DML单向复制到Hadoop,HDFS,Hive,Kafka,Hbase等。
物理复制与逻辑复制 (Physical replication versus Logical replication)
Physical or block level replication is also an option in the replication space. Hardware vendors, such as EMC, Veritas, etc., have been providing this type of solution for many years. Here are the pros and cons of logical verse physical replication.
物理或块级复制也是复制空间中的一个选项。 多年以来,EMC,Veritas等硬件供应商一直在提供这种解决方案。 这是逻辑诗句物理复制的利弊。
Physical replication is generally implemented as synchronous replication, which requires a two-phase commit with a zero data loss recovery point objective (RPO). Even the fastest logical replication solutions will have some lag time, and since they are asynchronous it is not possible to guarantee a zero data loss RPO. Also, physical replication replicates any block that changes on the source system keeping everything in sync, not just the database. These two characteristics of block-level replication are its biggest advantage. However, physical replication does come with its downside.
物理复制通常以同步复制的形式实现,这需要具有零数据丢失恢复点目标(RPO)的两阶段提交。 即使最快的逻辑复制解决方案也会有一些滞后时间,并且由于它们是异步的,因此无法保证零数据丢失RPO。 此外,物理复制会复制源系统上所有更改的块,从而使所有内容保持同步,而不仅仅是数据库。 块级复制的这两个特征是其最大的优势。 但是,物理复制确实有其缺点。
Physical replication must be a completely homogeneous environment. The source and target systems need to be the same hardware platform, operating system, database version, etc. There is no sub-setting of the data or table selection, everything gets replicated. There is no transformation capability, hence, block level replication fits one use case, HA/DR. The target system is not open for reads or writes, which makes Active – Active and reporting off the system not possible. Also, because it is synchronous replication, geographical limits will most likely apply due to network constraints. Lastly, when switching to the target system for fail-over, the target database needs to be recovered. If there are stringent SLAs on uptime, one or two fail-overs in a given year may exceed the SLA for uptime.
物理复制必须是完全同质的环境。 源系统和目标系统必须具有相同的硬件平台,操作系统,数据库版本等。没有数据或表选择的子设置,所有内容都可以复制。 没有转换功能,因此,块级复制适合一种用例HA / DR。 目标系统未打开以进行读取或写入,这将导致“活动”-“活动”和无法向系统报告。 另外,由于它是同步复制,因此由于网络限制,很可能会应用地理限制。 最后,当切换到目标系统以进行故障转移时,需要恢复目标数据库。 如果对正常运行时间有严格的SLA,则给定年份中的一两次故障转移可能会超出正常运行时间的SLA。
Thus, choosing between logical or physical replication really depends on the particular environment, use case, SLAs and geographical location of servers.
因此,在逻辑或物理复制之间进行选择实际上取决于特定的环境,用例,SLA和服务器的地理位置。
供应商 (Vendors )
There are many vendors in the logical replication space; however, three stand out as the most predominant.
逻辑复制空间中有许多供应商。 但是,三个是最主要的。
IBM purchased DataMirror several years ago and re-branded their replication solution as IBM InfoSphere CDC. DataMirror was a heterogeneous logical replication solution that had a niche for DB2 I series, so the acquisition made a lot of sense for IBM. IBM InfoSphere CDC can replicate cross platform, cross database and integrates with IBM’s ETL solution, DataStage. It supports Active-Active replication and has limited conflict detection and resolution (CDR).
IBM几年前购买了DataMirror,并将其复制解决方案更名为IBM InfoSphere CDC。 DataMirror是一种异构逻辑复制解决方案,在DB2 I系列中占有一席之地,因此,此次收购对IBM来说意义非凡。 IBM InfoSphere CDC可以复制跨平台,跨数据库,并与IBM的ETL解决方案DataStage集成。 它支持主动-主动复制,并且具有有限的冲突检测和解决方案(CDR)。
Quest Software has expanded SharePlex to somewhat heterogeneous database replication by supporting SQL Server in addition to Oracle. It can also replicate to Big Data and supports Active-Active replication with CDR. Shareplex uses dynamic memory queues to queue transactions.
Quest Software通过支持SQL Server和Oracle,将SharePlex扩展到某种程度上的异构数据库复制。 它还可以复制到大数据,并支持带CDR的主动-主动复制。 Shareplex使用动态内存队列来使事务排队。
Prior to the acquisition of a small San Francisco based company called GoldenGate several years ago, Oracle had the following replication solutions:
几年前,在收购旧金山一家名为GoldenGate的小型公司之前,Oracle具有以下复制解决方案:
Oracle Advanced Replication
Physical DataGuard
Logical DataGuard
Streams
Active DataGuard
Oracle高级复制
物理数据卫士
逻辑数据卫士
流
主动式DataGuard
Advanced Replication was Oracle’s first trigger-based solution that does still exist, but has been deprecated.
Advanced Replication是Oracle的第一个基于触发器的解决方案,该解决方案仍然存在,但已被弃用。
All other solutions are still supported except Streams (replacement for advanced replication), which has been deprecated due to the GoldenGate acquisition.
除Streams(用于高级复制的替代)外,其他所有解决方案仍受支持,该流由于收购GoldenGate而已被弃用。
Oracle GoldenGate (OGG) can replicate cross platform, cross database and integrates with Oracle’s ETL solution ODI (Oracle Data Integrator). It supports Active-Active replication and has complete CDR. It can also replicate to Big Data. OGG uses persistent queues at the file system level to queue transactions.
Oracle GoldenGate(OGG)可以跨平台,跨数据库复制并与Oracle ETL解决方案ODI(Oracle Data Integrator)集成。 它支持主动-主动复制,并具有完整的CDR。 它还可以复制到大数据。 OGG在文件系统级别使用持久队列对事务进行排队。
SQL Server复制概述和限制 (SQL Server replication overview and limitations)
Much like Oracle, SQL Server has multiple types of replication solutions including Snapshot, Merge and Transactional replication (see related links for a brief description of each).
与Oracle一样,SQL Server具有多种类型的复制解决方案,包括快照复制,合并复制和事务复制(请参阅相关链接以获取每种的简要说明)。
The rest of the article will focus on transactional replication. SQL Server has the same components as all logical replication solutions. It just uses different terminology that is defined in the next section of this article. SQL Server transactional replication does have some heterogeneous capability, but it appears that feature will be deprecated in future releases (see related links for publishers and subscribers).
本文的其余部分将重点介绍事务复制。 SQL Server具有与所有逻辑复制解决方案相同的组件。 它仅使用本文下一节中定义的不同术语。 SQL Server事务复制确实具有某些异构功能,但是似乎该功能在以后的版本中将被弃用(请参阅有关发布者和订阅者的相关链接)。
It appears transactional replication going forward with the next release will be for SQL Server to SQL Server with support for Active – Active with no CDR, which means, as discussed above, all conflicts must be avoided. This is done by making sure that from the system where the row originated, it can only be updated or deleted from that same system. Also, SQL Server Transactional replication has no capability to replicate to Big Data.
从下一个版本开始,事务复制似乎是从SQL Server到支持Active –不带CDR的ActiveSQL Server,这意味着,如上所述,必须避免所有冲突。 这是通过确保只能从该行所在的系统中对其进行更新或删除来完成的。 此外,SQL Server事务复制没有能力复制到大数据。
Lastly, only tables with primary keys can be replicated with SQL Server Transactional replication. Other solutions allow for replication of tables with no primary key. However, on update and delete operations the entire row is considered the primary key and all columns will be used in the where clause (except LOB data types), which is not very efficient.
最后,只有具有主键的表才能使用SQL Server事务复制进行复制。 其他解决方案允许不使用主键复制表。 但是,在执行更新和删除操作时,整个行均被视为主键,并且所有列都将用于where子句(LOB数据类型除外),这不是很有效。
SQL Server事务复制体系结构 (SQL Server transactional replication architecture)
SQL Server transactional replication uses a publish/subscribe paradigm. Publications (source systems) define what articles to replicate and an article is merely a table. Typical to most logical replications solutions, you can pick and choose what tables, columns and records (via a where clause) to replicate within a source database. Once articles to replicate have been defined, a process called the log reader agent reads the transaction log and captures changes made to the articles (tables) that have been defined in the publication. When it finds the changes, it writes them to a database called the distribution database, which can reside on the publishing server or on a middle tier server, which is the recommended approach. Then finally, there’s a process called the distribution agent which reads from the distribution database and applies the transactions to the subscribers which are the articles (tables) in the target databases. The distribution agent can apply the transactions to multiple subscribers (see Figure 3).
SQL Server事务复制使用发布/订阅范例。 出版物(源系统)定义了要复制的文章,而文章只是一个表。 对于大多数逻辑复制解决方案而言,典型的做法是,您可以选择(通过where子句)在源数据库中复制哪些表,列和记录。 一旦定义了要复制的项目,称为日志读取器代理的过程将读取事务日志并捕获对出版物中已定义的项目(表)所做的更改。 找到更改后,它将它们写入名为分发数据库的数据库中,该数据库可以驻留在发布服务器或中间层服务器上,这是推荐的方法。 最后,有一个称为分发代理的过程,该过程从分发数据库中读取并将事务应用于目标数据库中商品(表)的订户。 分发代理可以将事务应用于多个订户(请参见图3)。
Before a new transactional replication Subscriber can receive changes from the distribution agent, the Subscriber must be seeded with tables with the same schema and data as the tables at the Publisher. The initial dataset can be created by a process called the Snapshot Agent and be applied by the Distribution Agent. The initial dataset can also be created through a SQL Server database backup.
在新的事务复制订阅服务器可以从分发代理接收更改之前,必须使用与发布服务器上的表具有相同架构和数据的表为订阅服务器添加种子。 初始数据集可以由称为快照代理的过程创建,并由分发代理应用。 也可以通过SQL Server数据库备份来创建初始数据集。
摘要 (Summary)
I hope this article has enlightened you on the architecture and use cases of transactional/logical replication and has given you a basic understanding of the architecture of SQL Server transactional replication.
我希望本文对事务/逻辑复制的体系结构和用例有所启发,并让您对SQL Server事务复制的体系结构有基本的了解。















 1669
1669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









