





sql 数据表归档
We manage data in a growing environment where our clients query some of our data, and on occasion will query past data. We do not have an environment that scales and we know that we need to archive some of our data in a way that allows clients to access it, but also doesn’t interfere with current data clients are more interested in querying. With the current data in our environment and new data sets will be using in the future, what are some ways we can archive and scale our environment?
我们在不断增长的环境中管理数据,在这种环境中,客户查询我们的一些数据,有时还会查询过去的数据。 我们没有一个可扩展的环境,我们知道我们需要以允许客户端访问它的方式来归档一些数据,同时也不会干扰客户端对查询更感兴趣的当前数据。 在我们环境中的当前数据以及将来将使用新数据集的情况下,我们可以通过哪些方式归档和扩展环境?
总览 (Overview)
With large data sets, scale and archiving data can function together, as thinking in scale may assist later with archiving old data that users seldom access or need. For this reason, we’ll discuss archiving data in a context that includes scaling the data initially, since environments with archiving needs tend to be larger data environments.
对于大型数据集,规模数据和归档数据可以一起工作,因为规模化思维可能会在以后帮助归档用户很少访问或需要的旧数据时提供帮助。 出于这个原因,我们将在包括最初扩展数据的上下文中讨论归档数据,因为有归档需求的环境往往是更大的数据环境。
开始就要考虑如何结束 (Begin with the end in mind)
One of the most popular archiving techniques with data that includes date and time information is to archive data by a time window, such as a week, month or year. This provides a simple example of designing with an end in mind from the architectural side, as this becomes much easier to do if our application considers the time in which a query or process happens. We can scale from the beginning using the time rather than later migrating data from a database. Consider the below two scenarios as a comparison:
包含日期和时间信息的数据的最流行归档技术之一是按时间窗口(例如,一周,一个月或一年)归档数据。 这提供了一个从体系结构方面着眼于最终目的的简单示例,因为如果我们的应用程序考虑查询或过程发生的时间,这将变得更加容易。 我们可以从一开始就使用时间进行扩展,而不是稍后从数据库中迁移数据。 考虑以下两种情况作为比较:
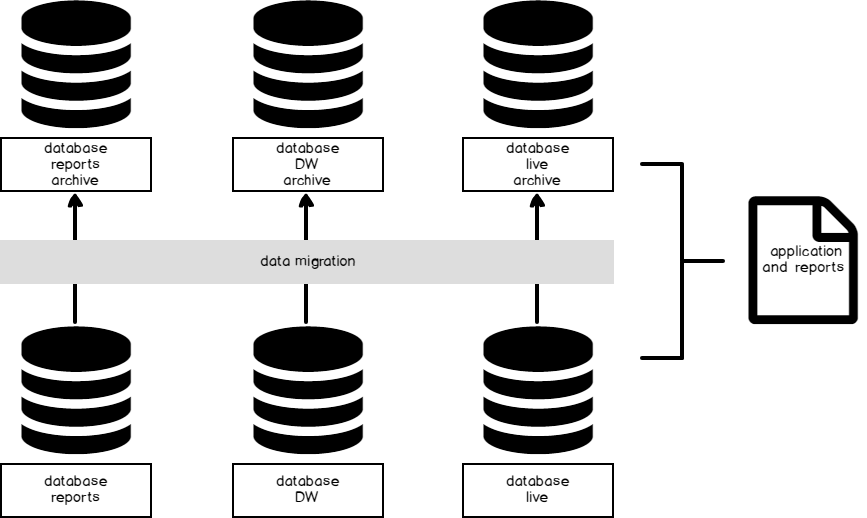
- Scenario 1: We add, transform and feed data to reports from a database or set of databases. The application and reports point to these databases. When we need to archive data, we migrate data in the form of inserts and deletes from these databases to another database where we store historic data. If a user needs to access historic data, the queries run against this historic environment. 方案1:我们向一个数据库或一组数据库添加,转换数据并将其提供给报告。 该应用程序和报告指向这些数据库。 当我们需要归档数据时,我们以插入和删除的形式将数据从这些数据库迁移到另一个存储历史数据的数据库。 如果用户需要访问历史数据,则针对此历史环境运行查询。
- Scenario 2: We add, transform and feed data to reports from multiple databases (or tables) created by the time window from the application in which the data are received (or required for clients) and stored for that time, such as all data for 2017 being stored in a 2017 database only. Because there’s a time window, the databases do not grow like in Scenario 1. The time window for this database (or table structure) determines what data are stored and no archiving is necessary, as we can simply backup and restore the database on a separate server if we need to migrate the data. 方案2:我们将数据添加,转换并馈送到由时间窗口从应用程序中创建的多个数据库(或表)的报告中,该应用程序在该时间中接收到数据(或客户端需要)并存储了该时间,例如2017仅存储在2017数据库中。 由于存在一个时间窗口,因此数据库不会像方案1中那样增长。此数据库(或表结构)的时间窗口确定了要存储的数据,并且无需存档,因为我们可以简单地在单独的数据库上备份和还原数据库服务器,如果我们需要迁移数据。
数据提要 (Data feeds)
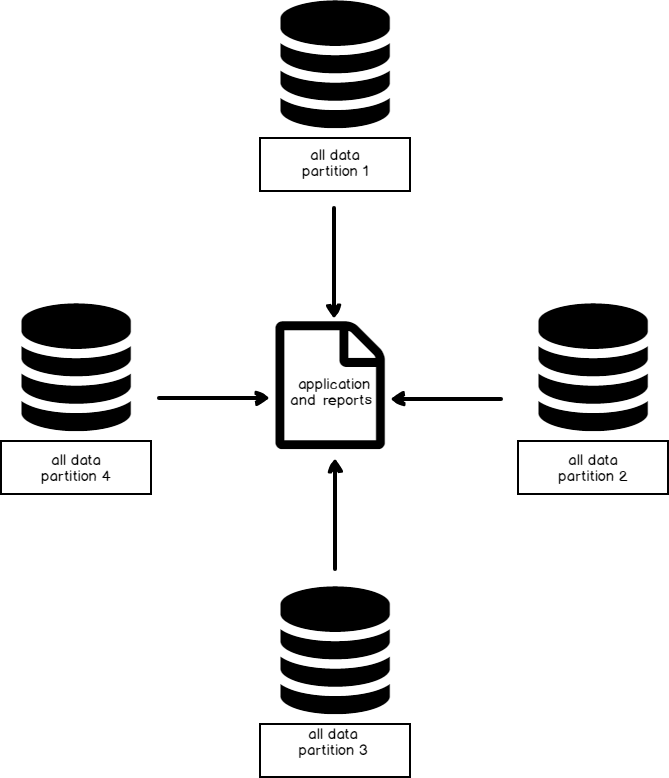
When we consider the end use of our data, we may discover that modeling our data from feeds will help our clients and assist us with scale. Imagine a report where people select from a drop-down menu the time frame in which they want to query data – whether in years, months or days. Behind the scenes, the query determines what database or databases are used (or tables, if we scale by tables). We treat the time in this case as the variable that determines the feed, such as 2017 being the data feed for all from the year of 2017.
当我们考虑数据的最终用途时,我们可能会发现,根据提要对数据进行建模将有助于我们的客户并帮助我们扩展规模。 想象一下一个报告,人们可以从下拉菜单中选择要查询数据的时间范围(以年,月或天为单位)。 在后台,查询确定使用哪个数据库(如果使用表扩展,则使用表)。 在这种情况下,我们将时间视为确定Feed的变量,例如2017是2017年以来所有数据的Feed。
We can apply this to other variables outside of time, such as an item in a store, a stock symbol, or a geographical location if we prefer to archive our data outside of using time. For instance, geographical data may change in time (often long periods of time) and feeding data for the purpose of archiving and scaling by region may be more appropriate. Stocks symbols also provide another example of this: people may only subscribe to a few symbols and this can be scaled early as separate feeds from different tables or databases. Archiving data becomes easier since each symbol is demarcated from others and reports generate faster for the user.
如果我们希望在使用时间以外的时间对数据进行归档,则可以将其应用于时间以外的其他变量,例如商店中的商品,库存代号或地理位置。 例如,地理数据可能会随时间(通常是很长一段时间)而变化,而出于按区域存档和缩放的目的而馈送数据可能更合适。 股票符号也提供了另一个例子:人们只能订阅几个符号,并且可以作为来自不同表或数据库的单独提要进行早期缩放。 归档数据变得更加容易,因为每个符号都与其他符号分开了,并且报告为用户生成的更快。
Our data feeds solve a possible scaling problem and resolve the question of how to archive historic data that may need to be accessed by clients.
我们的数据馈送解决了一个可能的扩展问题,并解决了如何存档客户可能需要访问的历史数据的问题。
得出有意义的数据 (Deriving meaningful data)
We may be storing data that we are unable to archive, or that querying and application use limit our ability to migrate data. We may also be able to archive data, but find that this adds limitations, such as performance limitations or storage limitations. In these situations, we can evaluate using data summaries through deriving data to reduce the amount of data stored. Consider an example with loan data where we keep the entire loan history and how we may be able to summarize these data in meaningful ways to our clients. Suppose that our client’s concern involves the total number of payments required on a loan, the total number of payments that’s currently happened, the late and early payments, and the current payment streak. The below image with a table structure is an example of this that summarizes loan data:
我们可能正在存储无法归档的数据,或者查询和应用程序使用限制了我们迁移数据的能力。 我们也许也可以归档数据,但是发现这增加了一些限制,例如性能限制或存储限制。 在这些情况下,我们可以通过导出数据以减少存储的数据量来评估使用数据摘要。 考虑一个关于贷款数据的示例,其中我们保留了整个贷款历史记录,以及如何能够以有意义的方式向客户总结这些数据。 假设我们的客户关心的是一笔贷款所需的总付款额,当前发生的总付款额,延迟付款和早期付款以及当前的付款方式。 下图以表格结构为例,它总结了贷款数据:
Relative to what our client needs, this may offer a meaningful summary that eliminates our need to store date and time information on the payments. Using data derivatives can save us time, provided that we know what our clients want to query and we aren’t removing anything they find meaningful. If our clients want detailed information, we may be limited with this technique and design for scale, such as using a loan number combination for scale in the above example.
相对于我们客户的需求,这可能会提供有意义的摘要,从而消除了我们在付款中存储日期和时间信息的需要。 使用数据导数可以节省我们的时间, 前提是我们知道客户想要查询的内容,并且不会删除他们认为有意义的任何内容 。 如果我们的客户需要详细的信息,我们可能会受到这种技术和规模设计的限制,例如在上面的示例中使用贷款号码组合作为规模。
80-20归档数据规则 (The 80-20 rule for archiving data)
In most data environments, we see a Pareto distribution of data that clients query where the distribution may be similar to the 80-20 rule or another distribution: the majority of queries will run against the minority of data. Historic data tends to demand fewer queries, in general, though some exceptions exist. If we are limited in scaling our data from the beginning to assist with automatic archiving and we’re facing resource limitations, we have other options to design our data to with frequency of access in mind.
在大多数数据环境中,我们会看到客户查询的Pareto数据分布,其分布可能类似于80-20规则或其他分布:大多数查询将针对少数数据。 通常,历史数据往往要求较少的查询,尽管存在一些例外。 如果我们从一开始就无法扩展数据以协助自动归档,并且我们面临资源限制,那么我们还有其他选择可以考虑访问频率来设计数据。
- We will use resource saving techniques with data that clients don’t query often, such as row or page compressions, clustered column store indexes (later versions of SQL Server), or data summaries. 我们将对客户端不经常查询的数据使用资源节省技术,例如行或页面压缩,群集列存储索引(SQL Server的更高版本)或数据摘要。
- If we only have the budget for fewer servers, we’ll scale less-accessed data to servers with fewer resources while retaining highly-accessed data on servers with many resources. 如果我们只有较少服务器的预算,那么我们会将访问量较少的数据扩展到资源较少的服务器上,同时在资源丰富的服务器上保留访问量较高的数据。
- Finally, in situations where we are very restricted by resources, we can use backup-restore techniques for querying, such as keeping old data on backups by copying the data quickly to a database, backing up the database, and keeping it on file for restoring. Since this will slow the querying down if the data are necessary, as the data must first be restored, we would only use this option in environments where we faced significant resource limitations. The below example with comments shows the steps of this process using one table of data that is backed up and restored by a time window. 最后,在资源非常有限的情况下,我们可以使用备份-还原技术进行查询,例如通过将数据快速复制到数据库,备份数据库并将其保留在文件中以进行还原来将旧数据保留在备份中。 。 由于这将在需要数据时减慢查询速度,因为必须首先还原数据,所以我们仅在面临大量资源限制的环境中使用此选项。 下面的示例带有注释,显示了使用一个由时间窗口备份和还原的数据表来执行此过程的步骤。
---- First we copy our data we'll archive to another database
SELECT *
INTO Data2017.dbo.tblMeasurements
FROM tblMeasurements
---- The where clause would specify the window of data we want to archive - in this case on year
WHERE YEAR(DateMeasurement) = '2017'
---- We backup the database for later restore, if data are needed
BACKUP DATABASE Data2017
TO DISK = 'E:\Backups\Data2017.BAK'
---- For a report, we would restore, query, and drop
RESTORE DATABASE Data2017
FROM DISK = 'E:\Backups\Data2017.BAK'
WITH MOVE 'Data2017' TO 'D:\Data\Data2017.mdf'
, MOVE 'Data2017_log' TO 'F:\Log\Data2017_log.ldf'
---- Report Query
SELECT
MONTH(DateMeasurement) MonthMeasure
, AVG(Measurement) AvgMeasure
, MIN(Measurement) MinMeasure
, MAX(Measurement) MaxMeasure
FROM tblMeasurements
GROUP BY MONTH(DateMeasurement)
---- Remove the database
DROP DATABASE Data2017
This latter example heavily depends on the environment’s limitations and assumes that clients seldom access the data stored. If we’re accessing the data frequently for reports, we would move it back with the other data we keep for frequent access.
后一个示例在很大程度上取决于环境的限制,并假定客户端很少访问存储的数据。 如果我们经常访问报表数据,则将其与其他经常访问的数据一起移回。
参考资料 (References)
- Partitioning data in SQL Server using the built-in partition functions使用内置分区功能在SQL Server中对数据进行分区
- Enable Compression on a Table or Index在表或索引上启用压缩
- Copy all data in a table to another table using T-SQL (very useful in automating data delineated backups)使用T-SQL将一个表中的所有数据复制到另一个表中(在自动执行数据描述的备份中非常有用)
翻译自: https://www.sqlshack.com/archive-sql-server-data-scale/
sql 数据表归档















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









