





 本文探讨了SQLServer中的聚集索引,包括其在查询性能中的关键作用,以及如何使用SQLServerManagementStudio创建和检查聚集索引。通过对比堆表和具有聚集索引的表,展示了聚集索引在提升查询效率方面的显著优势。
本文探讨了SQLServer中的聚集索引,包括其在查询性能中的关键作用,以及如何使用SQLServerManagementStudio创建和检查聚集索引。通过对比堆表和具有聚集索引的表,展示了聚集索引在提升查询效率方面的显著优势。
sql server 群集
This article targets the beginners and gives an introduction of the clustered index in SQL Server.
本文针对初学者,并介绍了SQL Server中的聚集索引。
介绍 (Introduction)
An index plays a crucial role in SQL Server query performance. Consider a book library with thousands of books.
索引在SQL Server查询性能中起着至关重要的作用。 考虑一个拥有数千本书的图书馆。

You want to search for a specific book that contains the keyword “adventure” in the title. The books in the library are unorganized.
您要搜索标题中包含关键字“冒险”的特定书籍。 图书馆里的书是杂乱无章的。
- You need to fetch each book from the shelf, read it and put it back if it does not satisfy your requirements 您需要从书架上拿起每本书,阅读并放回不符合您要求的书
- In a big library, it might take you a few days to find a single book 在大型图书馆中,可能需要几天的时间才能找到一本书
Suppose this library is a SQL table so in SQL Server terms, scanning all books in a library is known as table (index) scan.
假设此库是一个SQL表,那么用SQL Server术语来说,扫描库中的所有书籍称为表(索引)扫描。
Suppose you find two books for the “adventure” keyword and now you are interested in searching for another keyword in that book. Each book contains 2,000 pages.
假设您找到两本有关“冒险”关键字的书,现在您有兴趣在该书中搜索另一个关键字。 每本书包含2,000页。
Is it possible for you to search for a particular keyword in a book without reading it?
您是否可以在不阅读书的情况下搜索书中的特定关键字?
In a book, we use indexes for locating the page where you can find keywords. In SQL Server terms, we call it an index seek operation.
在书中,我们使用索引来定位可以找到关键字的页面。 用SQL Server术语来说,我们称它为索引查找操作。

We can visualize the table scan and index seek operation as per the following image:
我们可以根据下图可视化表扫描和索引查找操作:
We have mainly two types of indexes in SQL Server:
在SQL Server中,我们主要有两种类型的索引:
- Clustered index(CI) 聚集指数(CI)
- Non-clustered index 非聚集索引
SQL Server中的聚集索引概述 (Overview of a Clustered index in SQL Server)
SQL Server creates the index in a B-tree structure. SQL Server organizes data in this structure to quickly search for the required data instead of a table scan.
SQL Server以B树结构创建索引。 SQL Server以这种结构组织数据以快速搜索所需的数据,而不是进行表扫描。
As shown in the following image, we have three levels in a B-tree structure index:
如下图所示,我们在B树结构索引中分为三个级别:
根节点 (Root Node)
It is a top node and consists of a pointer for the intermediate index pages or leaf node (data pages).
它是一个顶部节点,由中间索引页或叶节点(数据页)的指针组成。
中级水平 (Intermediate level)
It consists of index key values along with pointers to the next intermediate level pages or the leaf data pages. It depends upon the size of the data for the number of intermediate levels.
它由索引键值以及指向下一个中级页面或叶数据页面的指针组成。 它取决于中间级别数的数据大小。
引导节点 (Lead Node)
It consists of actual data pages. Consider this as a point where actual data is stored in a clustered index in SQL Server.
它由实际数据页组成。 考虑到这一点,实际数据存储在SQL Server的聚集索引中。
Let’s imagine this b-tree for our library example. Suppose we have 10,000 books in the library and created CI on the bookid column of the library table:
让我们想象一下这个b树作为我们的库示例。 假设我们图书馆有10,000本书,并在图书馆表的bookid列上创建了CI:
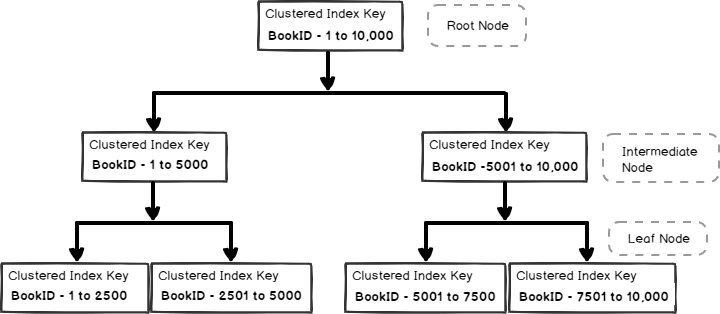
As shown in the above image, we defined the index on the bookid column of the library table. Now, if we want to retrieve a specific book say bookid 7579, SQL Server reads the following pages:
如上图所示,我们在库表的bookid列上定义了索引。 现在,如果我们要检索特定书籍,例如bookid 7579,SQL Server将读取以下页面:
- Root page: Root page points SQL Server for the intermediate node 5001 to 10,000 根页:根页将中间节点5001SQL Server指向10,000
- Intermediate Node: SQL Server reads the intermediate index page and gets a pointer for the actual data page in the leaf node 中间节点: SQL Server读取中间索引页并获取叶节点中实际数据页的指针
- Leaf node: SQL Server reads the data page in the leaf node as per our requirement
- 叶节点: SQL Server根据我们的要求读取叶节点中的数据页
As highlighted earlier, SQL Server reads the index page and returns the information. This process is known as Index seek. In certain situations, SQL Server reads all leaf-level data pages. It is known as an index scan. Undoubtedly, the index seek is faster than the index scan.
如前所述,SQL Server读取索引页并返回信息。 此过程称为索引查找。 在某些情况下,SQL Server读取所有叶级数据页。 这称为索引扫描。 毫无疑问,索引查找比索引扫描更快。
使用SSMS在SQL Server中创建聚簇索引 (Create a Clustered index in SQL Server using SSMS)
Let’s create a test table and create an index using SQL Server Management Studio GUI method:
让我们使用SQL Server Management Studio GUI方法创建测试表并创建索引:
CREATE TABLE dbo.bookstore
(book_id INT NOT NULL,
book_name VARCHAR(100)
);
Insert into dbo.bookstore values(1,'Learn ABC of SQL Server')
Insert into dbo.bookstore values(2,'Advanced troubleshooting step SQL Server')
We do not have any index on the table. A table without a CI is known as the heap table. You can read more about heap tables, and its performance issue in the article Forwarded Records Performance issue in SQL Server.
我们在桌上没有任何索引。 没有CI的表称为堆表。 您可以在SQL Server中的转发记录性能问题一文中了解有关堆表及其性能问题的更多信息。
Expand Databases and locate the table in which we want to define an index. Expand table and right-click on Indexes | New Index | Clustered Index:
展开数据库并找到我们要在其中定义索引的表。 展开表格并右键单击“ 索引” |“ 索引” 。 新索引 | 聚集索引 :
It opens the following New Index configuration window. It highlights an error message that at least one column should be there in an index:
它打开下面的“ 新建索引”配置窗口。 它突出显示了一条错误消息,即索引中至少应包含一列:
In the General page, it pre-populates the following pieces of information:
在“ 常规”页面中,它预先填充以下信息:
- Table name 表名
- Index name: By default, it gives index name in the format of ClusteredIndex-YYYYMMDD-HHMMSS. We should avoid using this name for the index. We should use a familiar name and define a naming convention for all indexes in our databases
- 索引名称:默认情况下,它以ClusteredIndex-YYYYMMDD-HHMMSS的格式提供索引名称。 我们应该避免使用该名称作为索引。 我们应该使用一个熟悉的名称,并为数据库中的所有索引定义一个命名约定
- Index Type: Clustered index 索引类型:聚集索引
Specify an index name and click on Add to define the index key:
指定索引名称,然后单击添加以定义索引键:
It opens following window to select CI key column on a specified table:
它打开以下窗口,以在指定的表上选择CI键列:
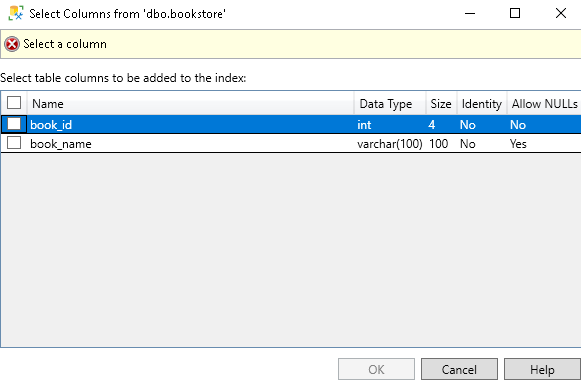
Once we select a column, it shows the status as Ready:
选择一列后,其状态将显示为Ready :
Click OK, and you can see the selected column in the Index key columns area:
单击“ 确定” ,您可以在“ 索引键列”区域中看到选定的列:
Under the Sort Order column, by default, it selects value Ascending. If we want to store the index key value in descending order, change the sort order as shown below:
默认情况下,在“ 排序顺序”列下,它选择值“ 升序”。 如果要按降序存储索引键值,请如下所示更改排序顺序:
Now click on Options, and you get a few configuration options for creating CI’s:
现在,单击Options ,您将获得一些用于创建CI的配置选项:
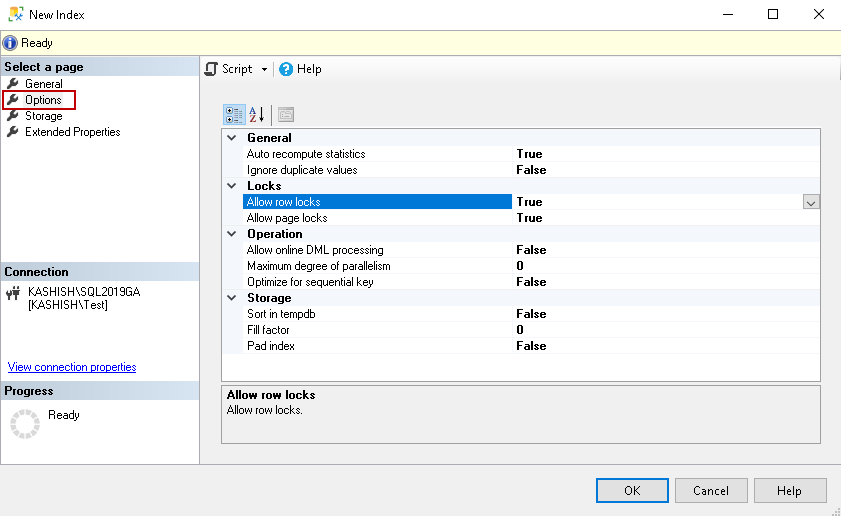
Few useful configuration options are as follows:
很少有有用的配置选项如下:
- Auto recompute statistics: By default, SQL Server recomputes the statistics based on pre-defined thresholds. We should not change its value unless required 自动重新计算统计信息:默认情况下,SQL Server根据预定义的阈值重新计算统计信息。 除非需要,否则我们不应更改其值
- Ignore duplicate values: Default value is false. We specify index behaviour for duplicate rows 忽略重复值 :默认值为false。 我们为重复的行指定索引行为
- IGNORE_DUP_KEY OFF: it gives an error message for duplicate row insertion IGNORE_DUP_KEY OFF:给出重复行插入的错误消息
- IGNORE_DUP_KEY ON: It ignores any duplicate data insertion and gives a warning message IGNORE_DUP_KEY ON:它将忽略任何重复的数据插入并给出警告消息
- Allow online DML processing: Using this option, we can allow concurrent users to access the table during the index operation. It is useful for a busy OLTP environment for performing online index maintenance 允许在线DML处理:使用此选项,我们可以允许并发用户在索引操作期间访问表。 对于繁忙的OLTP环境执行在线索引维护很有用
- Maximum degree of parallelism: We can limit the processors for parallel plan execution using this. We should make changes to this with proper testing 最大并行度:我们可以使用此限制处理器来执行并行计划。 我们应该通过适当的测试对此进行更改
- Sort in tempdb: We can specify this option for asking SQL Server to sort results during index creation in the tempdb. By default, SQL Server uses the source database in which the table exists 在tempdb中排序:我们可以指定此选项,要求SQL Server在tempdb中创建索引期间对结果进行排序。 默认情况下,SQL Server使用表所在的源数据库
- Fill factor: We can define a fill factor for the index. If we have specified this fil factor during index creation, it overrides the default value of the fill factor set at the instance level 填充因子:我们可以为索引定义填充因子。 如果我们在创建索引时指定了此填充因子,它将覆盖实例级别设置的填充因子的默认值
We have set the following options in my demo for the CI:
在我的CI演示中,我们设置了以下选项:
存储 (Storage)
In the Storage page, we can specify the filegroup for the index. By default, it uses the filegroup in which the table exists:
在“ 存储”页面中,我们可以为索引指定文件组。 默认情况下,它使用表所在的文件组:
Once you have set all required configurations, we can click OK, and it creates the CI for you. It is always advisable to configure the inputs and generate a script for the index. For a large table, sometimes the GUI method does not work correctly.
设置完所有必需的配置后,我们可以单击OK ,它会为您创建CI。 始终建议配置输入并为索引生成脚本。 对于大表,有时GUI方法无法正常工作。
Click on Script | New Query Editor Window as shown in the following image:
单击脚本 | 新建查询编辑器窗口 ,如下图所示:
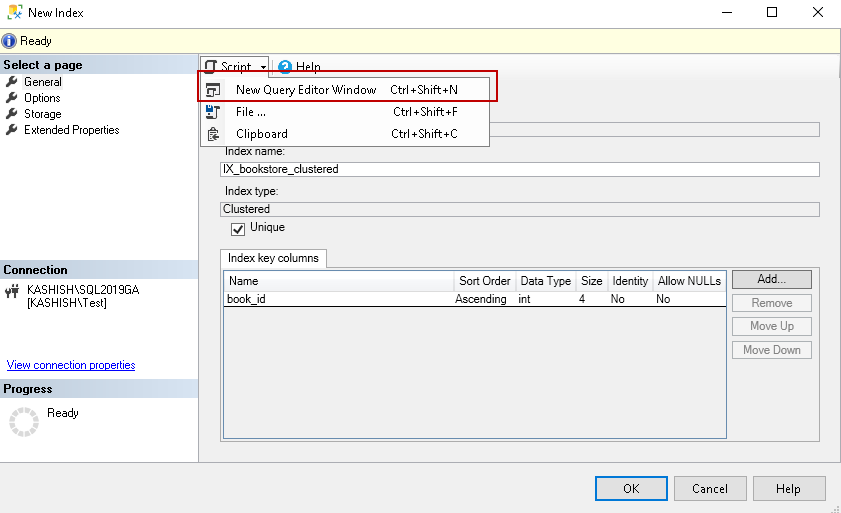
It gives the following script in a new query window:
它在新的查询窗口中提供以下脚本:
CREATE UNIQUE CLUSTERED INDEX [IX_bookstore_clustered] ON [dbo].[bookstore]
(
[book_id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = ON, IGNORE_DUP_KEY = OFF,
DROP_EXISTING = OFF, ONLINE = ON, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON,
OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
Execute the script, and you can see the index in Object Explorer:
执行脚本,您可以在对象资源管理器中看到索引:
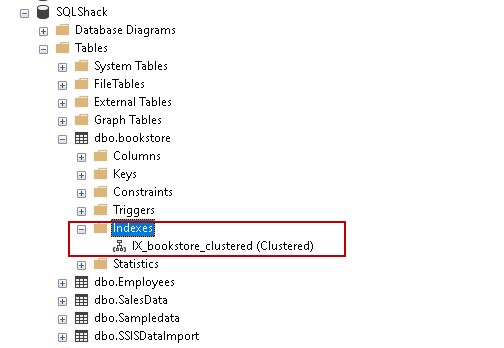
Note: If we define a primary key on a column, SQL Server automatically creates a CI on the primary key column
注意:如果我们在列上定义主键,SQL Server会在主键列上自动创建一个配置项
检查SQL Server中的群集索引级别 (Check Clustered index levels in SQL Server)
We can use DMV sys.dm_db_index_physical_stats for checking index fragmentation level, index levels for the CI. Insert a few records in the table and execute the following query:
我们可以使用DMV sys.dm_db_index_physical_stats检查索引碎片级别,即CI的索引级别。 在表中插入一些记录并执行以下查询:
SELECT
avg_page_space_used_in_percent,
avg_fragmentation_in_percent,
index_level,
record_count,
page_count,
fragment_count,
avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats(DB_ID('SQLShack'), OBJECT_ID('bookstore'), NULL, NULL, 'DETAILED');
GO
In the following screenshot, we have two levels of an index:
在以下屏幕截图中,我们有两个级别的索引:
在SQL Server中查看具有聚集索引的查询的执行计划 (View Execution plan for query with clustered index in SQL Server)
Let’s execute the following query and view the actual execution plan:
让我们执行以下查询并查看实际的执行计划:
SELECT *
INTO books_1
FROM bookstore;
SQL Server uses index seek for retrieving the records from bookstore table:
SQL Server使用索引查找从书店表中检索记录:
Let’s create a backup table using the following query:
让我们使用以下查询创建一个备份表:
SELECT *
INTO books_1
FROM bookstore;
This backup table has a similar structure and data as of the main table. The only difference is that the backup table does not have any index while our main table contains CI on the books_ID column.
该备份表的结构和数据与主表相似。 唯一的区别是,备份表没有任何索引,而我们的主表在books_ID列上包含CI。
Let’s execute the following queries in a separate window and compare the execution plan:
让我们在单独的窗口中执行以下查询,并比较执行计划:
SELECT *
FROM book_1
WHERE book_ID = 10000;
SELECT *
FROM bookstore
WHERE book_ID = 10000;
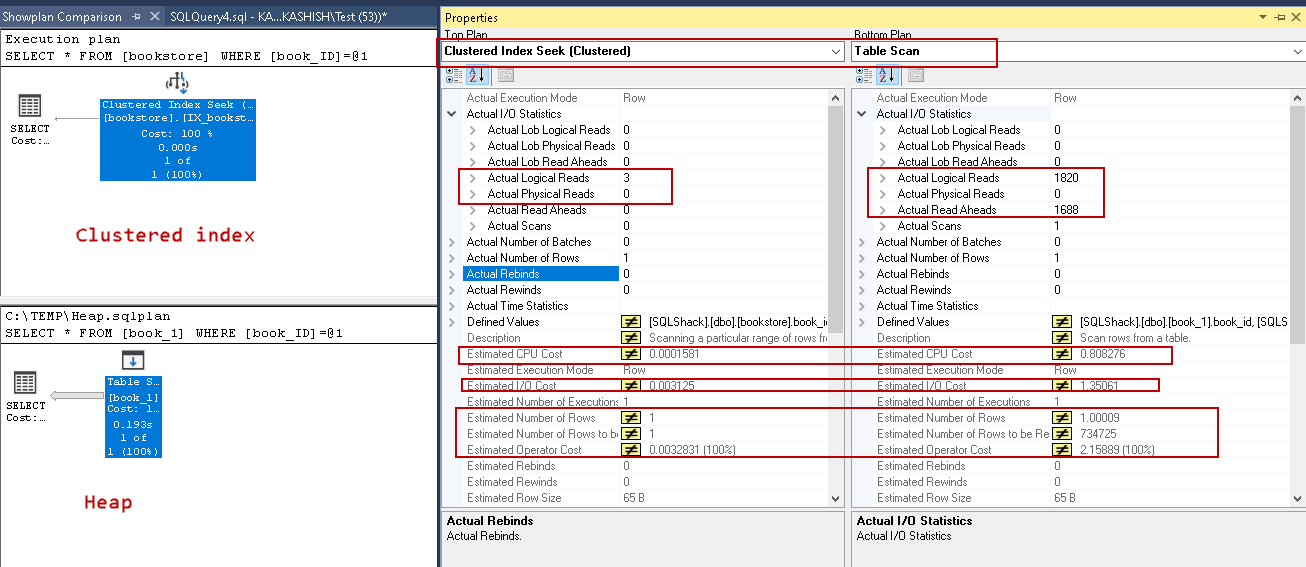
In the above screenshot, note the following differences. We can quickly figure out the performance comparison between a heap and a table with a clustered index:
在上面的屏幕截图中,请注意以下差异。 我们可以快速找出堆和具有聚簇索引的表之间的性能比较:
| Heap Table | Table with a clustered index in SQL | |
| Logical Operation | Table Scan | Clustered seek |
| Logical reads | 1820 | 3 |
| Physical reads | 1688 | 0 |
| Estimated number of rows to be read | 734725 | 1 |
| Estimated operator cost | 2.15889 | 0.0032831 |
| Estimated IO Cost | 1.35061 | 0.003125 |
| Estimated CPU Cost | 0.808276 | 0.0001581 |
| Number of rows read | 734725 | 1 |
堆表 | 在SQL中具有聚集索引的表 | |
逻辑运算 | 表扫描 | 聚簇寻道 |
逻辑读取 | 1820 | 3 |
物理阅读 | 1688 | 0 |
预计要读取的行数 | 734725 | 1个 |
估计运营商成本 | 2.15889 | 0.0032831 |
估计IO成本 | 1.35061 | 0.003125 |
估计的CPU成本 | 0.808276 | 0.0001581 |
读取的行数 | 734725 | 1个 |
结论 (Conclusion )
In this article, we explored the clustered index in SQL Server along with GUI and t-SQL method to create it. We also learned the performance comparison between the heap and CI key table. You should define a CI as per the requirement for better query performance.
在本文中,我们探索了SQL Server中的聚集索引以及GUI和t-SQL方法来创建聚集索引。 我们还学习了堆和CI密钥表之间的性能比较。 您应该根据要求定义CI,以提高查询性能。
翻译自: https://www.sqlshack.com/overview-of-sql-server-clustered-index/
sql server 群集















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









