





 本文详细介绍了SQL Server聚集索引的结构、设计注意事项、数据类型选择及其对性能的影响。创建合适的聚集索引可以显著提升数据检索速度,减少资源消耗。设计时应考虑索引键的短小、静态、递增、唯一性和频繁访问等因素。选择正确的数据类型,如INT、BIGINT,避免使用GUID,可以提高查询效率。
本文详细介绍了SQL Server聚集索引的结构、设计注意事项、数据类型选择及其对性能的影响。创建合适的聚集索引可以显著提升数据检索速度,减少资源消耗。设计时应考虑索引键的短小、静态、递增、唯一性和频繁访问等因素。选择正确的数据类型,如INT、BIGINT,避免使用GUID,可以提高查询效率。
sql server 群集
In the previous articles of this series (see bottom for a full index), we described, in detail, the structure of SQL Server tables and indexes, the basics and guidelines that help us in designing a proper index and finally the list of operations that can be performed on the SQL Server indexes. In this article, we will see how we could design an effective clustered index that the SQL Server Query Optimizer will always take benefits from, in speeding up the data retrieval process, which is the main goal of building an index.
在本系列的前几篇文章(完整的索引请参见底部)中,我们详细介绍了SQL Server表和索引的结构,有助于我们设计适当索引的基础知识和指南,最后介绍了可以执行的操作列表可以在SQL Server索引上执行。 在本文中,我们将了解如何设计一种有效的聚集索引,SQL Server Query Optimizer将始终从中受益,以加快数据检索过程,这是建立索引的主要目标。
聚集索引结构概述 (Clustered index structure overview)
In a Clustered table, a SQL Server clustered index is used to store the data rows sorted based on the clustered index key values. SQL Server allows us to create only one Clustered index per each table, as the data can be sorted in the table using one order criteria. In the heap tables, the absence of the clustered index means that the data is not sorted in the underlying table.
在群集表中,SQL Server群集索引用于存储根据群集索引键值排序的数据行。 SQL Server允许我们在每个表中仅创建一个聚集索引,因为可以使用一个顺序条件在表中对数据进行排序。 在堆表中,不存在聚集索引意味着数据未在基础表中排序。
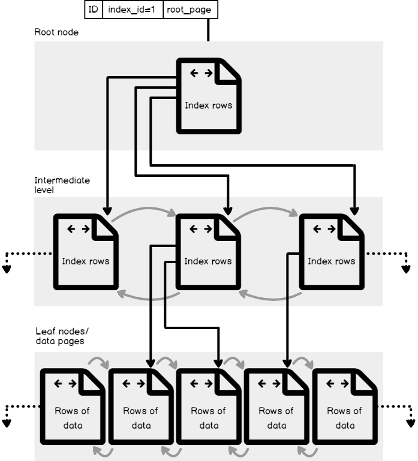
The clustered index is organized as 8KB pages using the B-tree structure, to enable the SQL Server Engine to find the requested rows associated with the index key values quickly. Each page in the index B-tree structure is considered as an index node. The top-level node is called the Root node and the bottom level nodes are called the Leaf nodes, where the table data pages are stored and sorted based on the index key values. All nodes that are located between the root and the leaf nodes are called the Intermediate level nodes. All pages located in the root and intermediate levels contain the sorted index key values with a pointer to the next intermediate level node or the data page in the index leaf level. In addition to sorting the data in the index pages based on the index key values, the pages itself will be sorted and linked in a doubly-linked list within the index. Any new value inserted into that index will follow the index key ordering sequence among the existing rows.
聚集索引使用B树结构组织为8KB页面,以使SQL Server Engine能够快速查找与索引键值关联的请求行。 索引B树结构中的每个页面都被视为索引节点。 顶层节点称为“ 根”节点,底层节点称为“ 叶”节点,其中表数据页根据索引键值进行存储和排序。 位于根节点和叶节点之间的所有节点称为中间级别节点。 位于根级和中间级的所有页面都包含排序的索引键值,并带有指向下一个中间级节点或索引叶级中数据页的指针。 除了根据索引键值对索引页中的数据进行排序以外,还将对页面本身进行排序并在索引内的双向链接列表中进行链接。 插入该索引的任何新值将遵循现有行之间的索引键排序顺序。
A SQL Server clustered index contains one or more allocation units that are used to store and manage the stored data depending on the data types of the key columns in that index, with the IN_ROW_DATA allocation unit available in all clustered indexes. The LOB_DATA allocation unit will be used in the clustered index that has large object data (LOB) and ROW_OVERFLOW_DATA allocation unit for the variable length columns that exceed the 8,060-byte size limit of the row. The figure shown below from Microsoft Books Online summarizes the described structure of the clustered index in a single partition, that will always have an index_id value equal to 1 in the sys.partitions table:
SQL Server聚集索引包含一个或多个分配单元,用于根据该索引中键列的数据类型来存储和管理存储的数据,而IN_ROW_DATA分配单元在所有聚集索引中均可用。 LOB_DATA分配单元将用于具有大对象数据(LOB)的聚集索引,而ROW_OVERFLOW_DATA分配单元用于长度超过行的8,060字节大小限制的可变长度列。 Microsoft联机丛书下面显示的图总结了单个分区中聚集索引的描述结构,该分区在sys.partitions表中始终具有等于1的index_id值:
聚集索引设计注意事项 (Clustered index design considerations)
The clustered index can be beneficial for the queries that read large result sets of ordered sequential data. In this case, the SQL Server Engine will locate the row with the first requested value using the clustered index, and continue sequentially to retrieve the rest of rows that are physically adjacent within the index pages with the correct order, without consuming the SQL Server Engine time and resources in sorting the data that is already sorted in the clustered index, affecting the overall query performance positively. For example, if the query returns all rows with ID value large than 950, the SQL Server Engine will use the clustered index to locate the row with ID value equal to 950 and continue retrieving the rest of rows sequentially.
聚集索引对于读取大型 有序 顺序数据的结果集的查询可能是有益的。 在这种情况下,SQL Server引擎将使用聚簇索引查找具有第一个请求值的行,并继续顺序以正确顺序检索索引页内物理相邻的其余行,而不会消耗SQL Server引擎在聚簇索引中对已经排序的数据进行排序所需的时间和资源,从而对总体查询性能产生积极影响。 例如,如果查询返回ID值大于950的所有行,则SQL Server引擎将使用聚簇索引查找ID值等于950的行,并继续按顺序检索其余行。
The characteristics of the best clustering keys can be summarized in few points that are followed by most of the designers:
最佳的聚类键的特征可以归纳为大多数设计师所遵循的几点:
- Short: Although SQL Server allows us to add up to 16 columns to the clustered index key, with maximum key size of 900 bytes, the typical clustered index key is much smaller than what is allowed, with as few columns as possible. The wide Clustered index key will also affect all non-clustered indexes built over that clustered index, as the clustered index key will be used as a lookup key for all the non-clustered indexes pointing to it. 简短说明 :尽管SQL Server允许我们向聚簇索引键最多添加16列,最大键大小为900字节,但是典型的聚簇索引键比允许的小得多,列数尽可能少。 宽的聚集索引键还将影响在该聚集索引上构建的所有非聚集索引,因为聚集索引键将用作指向该索引的所有非聚集索引的查找键。
- Static: It is recommended to choose the columns that are not changed frequently in the clustered index key. Changing the clustered index key values means that the whole row will be moved to the new proper page to keep the data values in the correct order. 静态 :建议选择聚集索引键中不经常更改的列。 更改聚簇索引键值意味着整个行将被移至新的正确页面,以使数据值保持正确的顺序。
- Increasing: Using an increasing column, such as the IDENTITY column, as a clustered index key will help in improving the INSERT process, that will directly insert the new values at the logical end of the table. This highly recommended choice will help in reducing the amount of memory required for the page buffers, minimize the need to split the page into two pages to fit the newly inserted values and the fragmentation occurrence, that required rebuilding or reorganizing the index again. 增加 :将增加的列(例如IDENTITY列)用作聚集索引键将有助于改善INSERT流程,该过程会将新值直接插入表的逻辑末尾。 强烈建议使用此选项,这将有助于减少页面缓冲区所需的内存量,最大程度地减少将页面分为两页以适应新插入的值和出现碎片的需求,而这需要重新构建或重新组织索引。
- Unique: It is recommended to declare the clustered index key column or combination of columns as unique to improve the queries performance. Otherwise, SQL Server will automatically add a uniqueifier column to enforce the clustered index key uniqueness. 唯一 :建议将聚集索引键列或列组合声明为唯一,以提高查询性能。 否则,SQL Server将自动添加一个Uniqueifier列以强制执行聚集索引键的唯一性。
- Accessed frequently: This is due to the fact that the rows will be stored in the clustered index in a sorted order based on that index key that is used to access the data. 频繁访问 :这是由于以下事实:行将基于用于访问数据的索引键以排序的顺序存储在聚簇索引中。
- Used in the ORDER BY clause: In this case, no need for the SQL Server Engine to sort the data in order to display it, as the rows are already sorted based on the index key used in the ORDER BY clause. 在ORDER BY子句中使用 :在这种情况下,SQL Server Engine无需对数据进行排序即可显示它,因为已经基于ORDER BY子句中使用的索引键对行进行了排序。
聚簇索引键适当的数据类型 (Clustered index key appropriate data types)
When designing a clustered index, you should consider that some data types are generally better than other data types to be used as clustering keys. For instance, the columns with SMALLINT, INT and BIGINT data types are the best choices as clustered index keys, especially when used in conjunction with the IDENTITY constraint, that enforces their values to increase sequentially. In addition, the IDENTITY integer values are narrow, due to its small size, unique, if you enforce the column uniqueness with a constraint, and static, as they are generated automatically by the system and not visible to the users.
在设计聚簇索引时,应考虑到某些数据类型通常比其他数据类型要好用作聚簇键。 例如,具有SMALLINT , INT和BIGINT数据类型的列是聚集索引键的最佳选择,尤其是与IDENTITY约束结合使用时,强制其值顺序增加。 此外,IDENTITY整数值由于其较小而很窄,如果您通过约束强制使用列唯一性,则该值是唯一的;而静态值是静态的,因为它们是系统自动生成的,对于用户不可见。
Although the GUIDs values, that are stored in the uniqueidentifier columns, are commonly used as clustered index key, there are some challenges that accompany that design. The main challenge that affects the clustered index key sorting performance is the nature of the GUID value that is larger than the integer data types, with 16 bytes size, and that it is generated in random manner, different from the IDENTITY integer values that are increasing continuously. The large size and randomness generation of the GUID values will always lead to the page splitting and index fragmentation problems, which negatively affect the clustered index usage performance.
尽管存储在uniqueidentifier列中的GUID值通常用作聚簇索引键,但是该设计伴随着一些挑战。 影响聚簇索引键排序性能的主要挑战是GUID值的性质,该值大于整数数据类型(具有16个字节的大小),并且以随机方式生成,不同于正在增加的IDENTITY整数值不断地。 GUID值的大尺寸和随机性生成将始终导致页面拆分和索引碎片化问题,从而对聚集索引的使用性能产生负面影响。
The Character data types can be also used, but not recommended, as clustered index keys. This is due to the limited sorting performance of the character data types, the large size, non-increasing values, non-static values that often tend to change in the business applications and not compared as binary values during the sorting process, as the characters comparison mechanism depends on the used collation. Even though the Date data types are not unique, it has a small size and provides good sorting performance, especially for the queries that search for data ranges.
字符数据类型也可以用作聚簇索引键,但不建议使用。 这是由于字符数据类型的排序性能有限,大尺寸,非递增值,非静态值,这些值在业务应用程序中往往会发生变化,并且在排序过程中不作为二进制值与字符进行比较比较机制取决于所使用的排序规则。 即使Date数据类型不是唯一的,它也具有较小的大小并提供良好的排序性能,尤其是对于搜索数据范围的查询。
聚集索引的实现 (Clustered index implementation)
When you create a PRIMARY KEY constraint on a table, a unique clustered index will be created automatically on the column or columns that participate in that constraint to enforce the PRIMARY KEY constraint, given the same name as the constraint name, unless you already defined a clustered index on the same table. SQL Server allows you to specify the type of the index that will be created automatically when you create a UNIQUE constraint to be clustered index, if there is no clustered index created on that table, due to the fact that, only one clustered index can be created per each table. You can also create the clustered index independently from the constraints if a non-clustered index is used to enforce the PRIMARY KEY constraint.
在表上创建PRIMARY KEY约束时,将在参与约束的一个或多个列上自动创建一个唯一的聚集索引,以强制执行PRIMARY KEY约束(给定的名称与约束名称相同),除非您已经定义了同一表上的聚集索引。 SQL Server允许您指定在创建要作为聚集索引的UNIQUE约束时将自动创建的索引的类型,如果在该表上没有创建聚集索引,由于以下事实,即只能创建一个聚集索引每个表创建一个。 如果使用非聚集索引来强制执行PRIMARY KEY约束,则也可以独立于约束来创建聚集索引。
A clustered index can be created using SQL Server Management Studio or using CREATE CLUSTERED INDEX T-SQL command. To be able to create a clustered index, the user should be a member of db_owner and db_ddladmin fixed database roles or member of sysadmin fixed server role.
可以使用SQL Server Management Studio或使用CREATE CLUSTERED INDEX T-SQL命令创建聚簇索引。 为了能够创建聚集索引,用户应该是db_owner和db_ddladmin固定数据库角色的成员或sysadmin固定服务器角色的成员。
Let us create a new table to be used in our demo, in which the PRIMARY KEY constraint will use a non-clustered index to enforce it, using the CREATE TABLE T-SQL statement below:
让我们创建一个用于演示的新表,其中PRIMARY KEY约束将使用以下非聚集索引来强制执行该表,请使用以下CREATE TABLE T-SQL语句:
USE SQLShackDemo
GO
CREATE TABLE ClusteredIndexDemo
(
ID INT IDENTITY (1,1) NOT NULL,
GUID uniqueidentifier NOT NULL,
EmployeeName NVARCHAR(200) NOT NULL,
BirthDate DATETIME NOT NULL,
EmployeeAddress NVARCHAR(MAX),
CONSTRAINT PK_ClusteredIndexDemo_GUID PRIMARY KEY NONCLUSTERED (GUID)
)
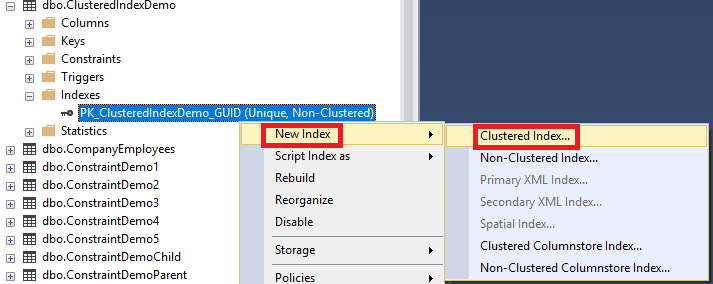
Having no clustered index defined in the previous table, we can create a clustered index using the SQL Server Management Studio by browsing the table on which we need to create the clustered index on, then right-click on the Indexes node under that table and from the New Index option choose the clustered index type, as shown below:
在上一个表中没有定义聚簇索引的情况下,我们可以使用SQL Server Management Studio创建聚簇索引,方法是浏览需要在其上创建聚簇索引的表,然后右键单击该表下的Indexes节点,然后从New Index选项选择聚簇索引类型,如下所示:
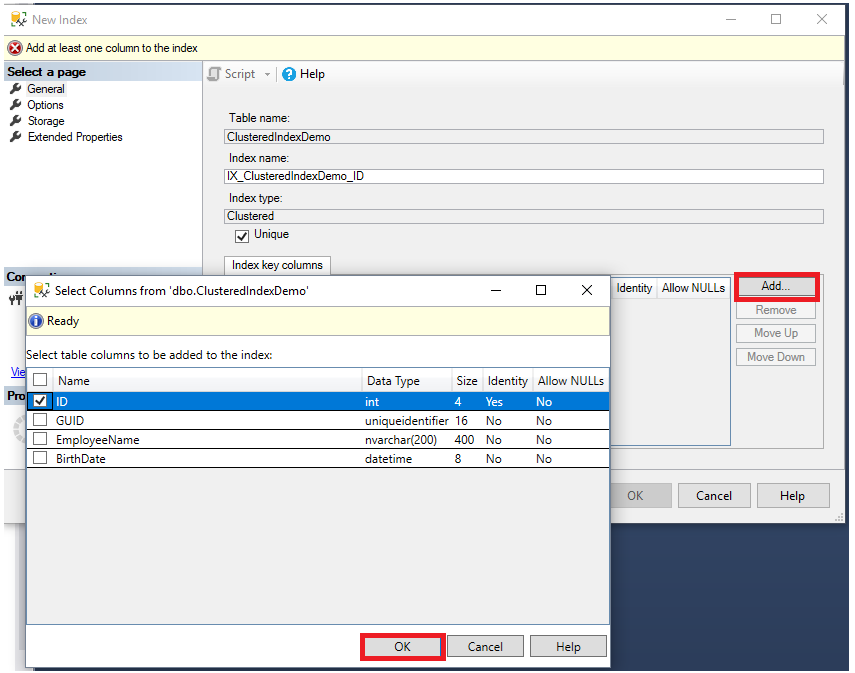
From the displayed New Index dialog box, the name of the table on which the index will be created, and the type of the index will be filled automatically. You need to provide the name of the index, following your company naming convention, the uniqueness of that index key values and from the Add button you can choose the column or list of columns that will participate in that index key, as shown below:
在显示的“新建索引”对话框中,将在其上创建索引的表的名称以及索引的类型将自动填充。 您需要按照公司命名约定,该索引键值的唯一性来提供索引的名称,然后从“ 添加”按钮中选择将参与该索引键的列或列列表,如下所示:
You can also perform the same task from the Table Designer, by right-clicking on the table on which the index will be created and choose Design option as below:
您还可以在表设计器中执行相同的任务,方法是右键单击将在其上创建索引的表,然后选择“设计”选项,如下所示:
On the displayed Table Designer window, right-click on the empty space and choose Indexes/Keys option shown below:
在显示的“表格设计器”窗口上,右键单击空白区域,然后选择“索引/键”选项,如下所示:
From the appeared dialog box, click on the Add bottom to add a new clustered index, by setting Create As Clustered to Yes, Specify the index name, the clustered index key uniqueness and the list of columns, with the proper sorting order, that will be included in the clustered index key, as shown below:
在出现的对话框中,单击“添加”底部以添加新的聚簇索引,方法是将“创建为聚簇”设置为“是”,指定索引名称,聚簇索引键的唯一性以及具有正确排序顺序的列列表,包含在聚集索引键中,如下所示:
The clustered index can be also created using the CREATE CLUSTERED INDEX T-SQL command, by specifying the index name, the name of the table on which the index will be created, the clustered index key values uniqueness and the list of columns that will be included to the clustered index key, as shown below:
还可以使用CREATE CLUSTERED INDEX T-SQL命令创建聚簇索引,方法是指定索引名称,将在其上创建索引的表的名称,聚簇索引键值的唯一性以及将要创建的列的列表。包含在聚集索引键中,如下所示:
CREATE UNIQUE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo
(
ID ASC
) WITH( SORT_IN_TEMPDB = ON, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY]
GO
Consider taking benefits from the list of index creation options specified in the previous CREATE INDEX statement, especially when creating a clustered index on large tables, in order to improve the performance of the index creation process.
请考虑从上一个CREATE INDEX语句中指定的索引创建选项列表中获益,尤其是在大型表上创建聚簇索引时,以提高索引创建过程的性能。
性能比较 (Performance comparison)
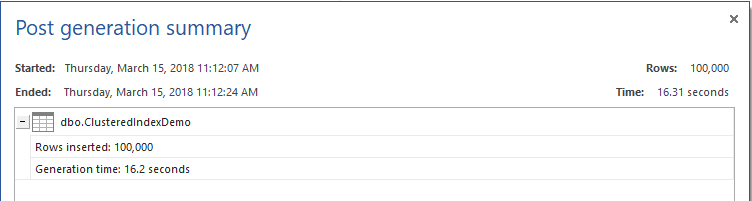
To proceed with the demo, let us fill the created table with 100K records, using ApexSQL Generate, as shown below:
为了继续演示,让我们使用ApexSQL Generate ,用10万条记录填充创建的表,如下所示:
Until this point, the table is filled and sorted based on the ID column. If we execute the below SELECT query that searches based on the ID column and check the TIME and IO statistics generated by executing the query:
到此为止,表格已根据ID列进行填充和排序。 如果我们执行下面的基于ID列进行搜索的SELECT查询,并检查通过执行查询生成的TIME和IO统计信息:
SET STATISTICS TIME ON
SET STATISTICS IO ON
SELECT * FROM [dbo].[ClusteredIndexDemo]
WHERE ID>1000 and [EmployeeAddress] LIKE '%Hillcrest%'
The generated statistics will show that 1075 logical read operations are performed to retrieve the requested data, 203ms consumed from the CPU time and 255ms taken to execute the query, as shown below:
生成的统计信息将显示执行了1075个逻辑读取操作来检索请求的数据,从CPU时间消耗了203ms的消耗,而执行查询花费了255ms的花费,如下所示:

If we drop the clustered index and create a new one using the GUID column:
如果我们删除聚集索引并使用GUID列创建一个新索引:
DROP INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo
GO
CREATE UNIQUE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo
(
GUID ASC
) WITH( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY]
GO
And execute the below SELECT statement that searches based on the GUID column values:
并执行以下基于GUID列值进行搜索的SELECT语句:
SELECT * FROM [dbo].[ClusteredIndexDemo]
WHERE GUID <> 'CB2F45A0-185F-9884-88EB-B7C497AB61EA' and [EmployeeAddress] LIKE '%Hillcrest%'
The generated Time and IO statistics will show that 1196 logical read operations are performed to retrieve the requested data based on the GUID column values, 2018ms consumed from the CPU time and 276ms taken to execute the query. All counters show that using the GUID column as clustered index key is worse than using the ID column, as shown below:
生成的时间和IO统计信息将显示,根据GUID列值,CPU时间消耗的2018ms和执行查询所花费的276ms,执行了1196次逻辑读取操作以检索请求的数据。 所有计数器都显示,使用GUID列作为聚集索引键比使用ID列更糟糕,如下所示:

DROP INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo
GO
CREATE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo
(
EmployeeName ASC
) WITH( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY]
GO
Then execute the below SELECT statement that searches based on the EmployeeName column values:
然后执行以下基于EmployeeName列值进行搜索的SELECT语句:
SELECT * FROM [dbo].[ClusteredIndexDemo]
WHERE [EmployeeName] <> 'Gianna' and [EmployeeAddress] LIKE '%Hillcrest%'
You will see from the generated Time and IO statistics that, 1287 logical read operations are performed to retrieve the requested data based on the EmployeeName values, 2018ms consumed from the CPU time and 289ms taken to execute the query. All counters again indicate that using the EmployeeName character column as clustered index key is worse than using the ID and the GUID columns, as shown below:
您将从生成的时间和IO统计信息中看到,根据EmployeeName值,CPU时间消耗的2018ms和执行查询所花费的289ms,执行了1287个逻辑读取操作来检索请求的数据。 所有计数器再次表明,将EmployeeName字符列用作聚集索引键比使用ID和GUID列更糟糕,如下所示:

If we drop the clustered index and create a new one using the BirthDate datetime column:
如果我们删除聚集索引并使用BirthDate datetime列创建一个新索引:
DROP INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo
GO
CREATE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo
(
BirthDate ASC
) WITH( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY]
GO
And execute the below SELECT statement that searches based on the BirthDate column values:
并执行以下基于BirthDate列值进行搜索的SELECT语句:
SELECT * FROM [dbo].[ClusteredIndexDemo]
WHERE BirthDate BETWEEN '1950-01-01' AND '1950-12-31' AND [EmployeeAddress] like '%Hillcrest%'
The Time and IO statistics generated after executing the query will show that only 7 logical read operations are performed to retrieve the requested data based on the BirthDate range values, 0ms consumed from the CPU time and 47ms taken to execute the query. It is clear from the result that, using the BirthDate Datetime column as clustered index key is the best choice when searching based on date range, as shown below:
执行查询后生成的时间和IO统计信息将显示,仅根据BirthDate范围值(从CPU时间消耗的0毫秒和执行查询所用的47毫秒)执行7次逻辑读取操作来检索请求的数据。 从结果可以明显看出,使用BirthDate Datetime列作为聚簇索引键是基于日期范围进行搜索时的最佳选择,如下所示:
Finally, if you try to drop the clustered index and create a new one using the EmployeeAddress character column:
最后,如果您尝试删除聚集索引并使用EmployeeAddress字符列创建一个新索引:
DROP INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo
GO
CREATE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo
(
EmployeeAddress ASC
) WITH( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY]
GO
The CREATE INDEX statement will fail, showing that the NVARCHAR(MAX) data type is not allowed as a clustered index key, as shown in the error message below:
CREATE INDEX语句将失败,表明不允许将NVARCHAR(MAX)数据类型用作聚集索引键,如以下错误消息所示:

As you can from the previous results, a clustered index that is designed properly can reduce the I/O and CPU resources consumption amount, therefore improving the queries and overall system performance. The SQL Server Query Optimizer decides to use the clustered index to retrieve the requested data, as it is more efficient, much faster and fewer resources consumer than scanning the whole table, in addition to having the data sorted in the index pages.
从前面的结果中可以看出,设计合理的聚集索引可以减少I / O和CPU资源消耗量,从而改善查询和整体系统性能。 SQL Server查询优化器决定使用聚簇索引来检索请求的数据,因为它比扫描整个表更有效,更快,资源消耗更少,而且可以在索引页中对数据进行排序。
Take into consideration that, when you create a clustered index on a table, all non-clustered indexes created on that heap table will be rebuilt to replace the row identifier (RID) with the clustered index key. So that, it is better always to start with creating the clustered index then proceed with creating the non-clustered index over it.
In this article, we tried to cover all aspects of the clustered index design subject. In the next article of this series, we will discuss how to design an effective and optimal Non-clustered index. Stay tuned!考虑到在表上创建聚簇索引时,将重建在该堆表上创建的所有非聚簇索引,以用聚簇索引键替换行标识符(RID)。 因此,最好始终从创建聚簇索引开始,然后再在其上创建非聚簇索引。
在本文中,我们试图涵盖聚集索引设计主题的所有方面。 在本系列的下一篇文章中,我们将讨论如何设计有效且最佳的非聚集索引。 敬请关注!目录 (Table of contents)
翻译自: https://www.sqlshack.com/designing-effective-sql-server-clustered-indexes/
sql server 群集















 508
508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









