



 本文深入探讨了SQL中的INFORMATION_SCHEMA数据库,解释了它如何作为数据库的数据库,存储了服务器上其他数据库的详细信息。通过实例展示了如何查询INFORMATION_SCHEMA来获取数据库结构信息,包括列出所有数据库、表和约束,以及如何使用这些信息进行自动化和控制数据库变更。
本文深入探讨了SQL中的INFORMATION_SCHEMA数据库,解释了它如何作为数据库的数据库,存储了服务器上其他数据库的详细信息。通过实例展示了如何查询INFORMATION_SCHEMA来获取数据库结构信息,包括列出所有数据库、表和约束,以及如何使用这些信息进行自动化和控制数据库变更。
The best way how to explain what the INFORMATION_SCHEMA database is would be – “This is the database about databases. It’s used to store details of other databases on the server”. What does that mean, how we can use it, and what we can do with this data is the topic of today’s article.
解释什么是INFORMATION_SCHEMA数据库的最佳方法是-“这是有关数据库的数据库。 它用于在服务器上存储其他数据库的详细信息。” 这是什么意思,我们如何使用它,以及我们如何使用这些数据是今天文章的主题。
该模型 (The Model)
As always, we’ll start with the data model first. This is the same model we’ve used so far in this series, so I won’t describe it again.
与往常一样,我们将首先从数据模型开始。 这是我们到目前为止在本系列中使用过的相同模型,因此我不再赘述。

Still, one thing is interesting. Today we won’t be interested in the data stored in tables, but rather how this model is described in the INFORMATION_SCHEMA database.
尽管如此,有一件事很有趣。 今天,我们将不再对表中存储的数据感兴趣,而是对如何在INFORMATION_SCHEMA数据库中描述此模型感兴趣。
什么是INFORMATION_SCHEMA数据库? (What is the INFORMATION_SCHEMA Database?)
The INFORMATION_SCHEMA database is an ANSI standard set of views we can find in SQL Server, but also MySQL. Other database systems also have either exactly such or similar database implemented. It provides the read-only access to details related to databases and their objects (tables, constraints, procedures, views…) stored on the server.
INFORMATION_SCHEMA数据库是ANSI标准视图集,我们可以在SQL Server和MySQL中找到这些视图。 其他数据库系统也具有完全相同或相似的数据库。 它提供对与存储在服务器上的数据库及其对象(表,约束,过程,视图等)相关的详细信息的只读访问。
You could easily use this data to:
您可以轻松地将此数据用于:
- Check what’s on the server and/or in the database 检查服务器和/或数据库中的内容
- Check if everything is as expected (e.g. compared to the last time you’ve performed this check) 检查一切是否符合预期(例如,与您上次执行此检查的时间相比)
- Automate processes and build some complex code (e.g. code generators – we’ll talk about this later) 自动化流程并构建一些复杂的代码(例如,代码生成器–我们稍后将讨论)
Therefore, this database could prove to be very useful in some cases, especially if you’re in the DBA role
因此,在某些情况下,尤其是当您担任DBA角色时,该数据库可能会非常有用。
列出所有数据库 (Listing All Databases)
Maybe the first logical thing to do is to list all databases which are currently on our server. We can do it in a few ways. While these two are not directly related to the usage of the INFORMATION_SCHEMA and are SQL Server-specific, let’s look at them first.
也许要做的第一件事是列出我们服务器上当前的所有数据库。 我们可以通过几种方式做到这一点。 虽然这两个与INFORMATION_SCHEMA的使用并不直接相关,并且是特定于SQL Server的,但让我们先来看一下它们。
SELECT * FROM sys.databases;
EXEC sp_databases;

You can easily notice that the first query returns many more details (several columns outside this pic) than the second query. It uses a SQL Server-specific sys object. While this works great, it’s very specific, so I’ll go into detail in a separate article. The second statement is the execution of the system stored procedure sp_databases which returns the predefined columns.
您可以轻松地注意到,第一个查询比第二个查询返回的详细信息更多(此图片之外的几列)。 它使用特定于SQL Server的sys对象 。 尽管效果很好,但它非常具体,因此我将在另一篇文章中详细介绍。 第二条语句是系统存储过程 sp_databases的执行,该过程返回预定义的列。
使用INFORMATION_SCHEMA访问表数据 (Using INFORMATION_SCHEMA to Access Tables Data)
Since this database is an ANSI standard, the following queries should work in other DBMS systems as well. We’ll list all tables in the database we’ve selected and also all constraints. To do that, we’ll use the following queries:
由于此数据库是ANSI标准,因此以下查询也应在其他DBMS系统中工作。 我们将列出我们选择的数据库中的所有表以及所有约束。 为此,我们将使用以下查询:
USE our_first_database;
-- list of all tables in the selected database
SELECT *
FROM INFORMATION_SCHEMA.TABLES;
-- list of all constraints in the selected database
SELECT *
FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS;
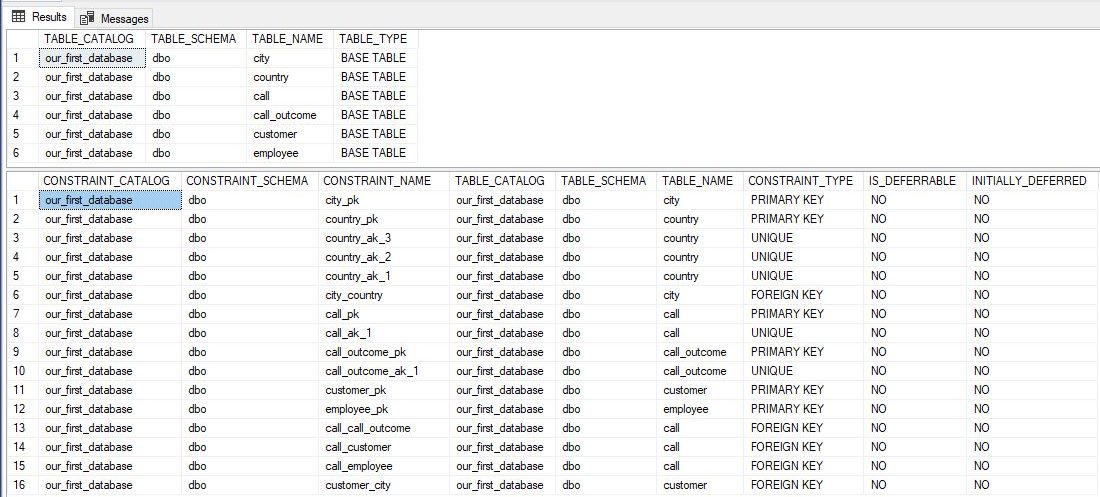
The first important thing is that, after the keyword USE, we should define the database we want to run queries on. The result is expected. The first query lists all tables from our database, while the second query returns all constraints, we’ve defined when we created our database. In both of these, besides their name and the database schema they belong to, we can see many other details.
首先重要的是,在关键字USE之后 ,我们应该定义要在其上运行查询的数据库。 结果是预期的。 第一个查询列出了数据库中的所有表,而第二个查询返回了所有约束,这是我们在创建数据库时定义的。 在这两者中,除了它们的名称和它们所属的数据库模式之外,我们还可以看到许多其他细节。
It’s important to notice that in constraints we also have the TABLE_NAME column, which tells us which table this constraint is related to. We’ll use that fact to relate tables INFORMATION_SCHEMA.TABLES and INFORMATION_SCHEMA.TABLE_CONSTRAINTS to create our custom query. Let’s take a look at the query as well as its’ result.
重要的是要注意,在约束中我们还有TABLE_NAME列,它告诉我们该约束与哪个表有关。 我们将使用该事实来关联表INFORMATION_SCHEMA.TABLES和INFORMATION_SCHEMA.TABLE_CONSTRAINTS以创建我们的自定义查询。 让我们看一下查询及其结果。
USE our_first_database;
-- join tables and constraints data
SELECT
INFORMATION_SCHEMA.TABLES.TABLE_NAME,
INFORMATION_SCHEMA.TABLE_CONSTRAINTS.CONSTRAINT_NAME,
INFORMATION_SCHEMA.TABLE_CONSTRAINTS.CONSTRAINT_TYPE
FROM INFORMATION_SCHEMA.TABLES
INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS ON INFORMATION_SCHEMA.TABLES.TABLE_NAME = INFORMATION_SCHEMA.TABLE_CONSTRAINTS.TABLE_NAME
ORDER BY
INFORMATION_SCHEMA.TABLES.TABLE_NAME ASC,
INFORMATION_SCHEMA.TABLE_CONSTRAINTS.CONSTRAINT_TYPE DESC;
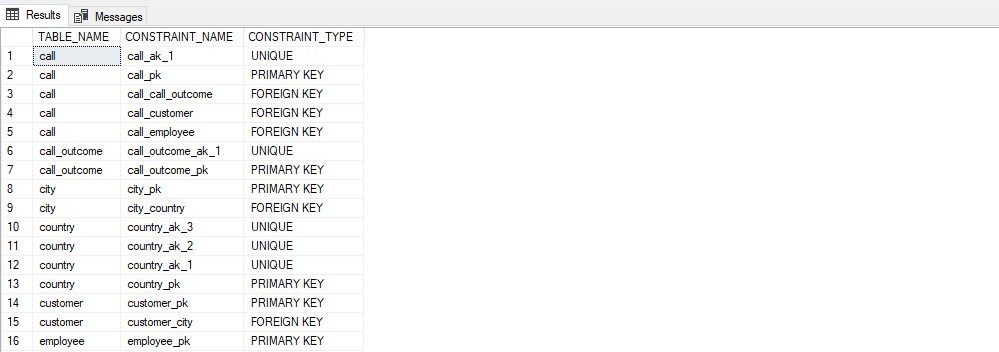
No doubt this query looks cool. Still, let’s comment on a few things. With this query, we’ve:
毫无疑问,此查询看起来很酷。 不过,让我们对一些事情发表评论。 通过此查询,我们已经:
- Again, we’ve pointed out which database we are using. This could have been avoided if you write <database_name> each time before INFORMATION_SCHEMA, e.g. our_first_database.INFORMATION_SCHEMA.TABLES.TABLE_NAME. I don’t prefer it that way 再次,我们指出了我们正在使用哪个数据库。 如果您每次在INFORMATION_SCHEMA之前都写<database_name>,例如避免使用our_first_database.INFORMATION_SCHEMA.TABLES.TABLE_NAME,则可以避免这种情况。 我不喜欢那样
- Joined two tables, in the same manner, we would join two “regular” database tables. This is good to know, but, as we’ll see later, you can join many things (system tables, subqueries) and not only “regular” tables 以相同的方式联接两个表,我们将联接两个“常规”数据库表。 很高兴知道这一点,但是,正如我们稍后将要看到的,您可以联接很多东西(系统表,子查询),而不仅仅是“常规”表
- We have also ordered our result so we can easily notice all the constraints on each table 我们还对结果进行了排序,以便我们可以轻松注意到每个表上的所有约束
Maybe you’re asking yourself why would you do something like this. Well, with minor modifications to this query, you can easily count a number of keys in each table. Let’s do that.
也许您是在问自己为什么要这样做。 好吧,只需对该查询进行较小的修改,就可以轻松计算每个表中的键数。 来做吧。
USE our_first_database;
-- join tables and constraints data
SELECT
INFORMATION_SCHEMA.TABLES.TABLE_NAME,
SUM(CASE WHEN INFORMATION_SCHEMA.TABLE_CONSTRAINTS.CONSTRAINT_TYPE = 'PRIMARY KEY' THEN 1 ELSE 0 END) AS pk,
SUM(CASE WHEN INFORMATION_SCHEMA.TABLE_CONSTRAINTS.CONSTRAINT_TYPE = 'UNIQUE' THEN 1 ELSE 0 END) AS uni,
SUM(CASE WHEN INFORMATION_SCHEMA.TABLE_CONSTRAINTS.CONSTRAINT_TYPE = 'FOREIGN KEY' THEN 1 ELSE 0 END) AS fk
FROM INFORMATION_SCHEMA.TABLES
LEFT JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS ON INFORMATION_SCHEMA.TABLES.TABLE_NAME = INFORMATION_SCHEMA.TABLE_CONSTRAINTS.TABLE_NAME
GROUP BY
INFORMATION_SCHEMA.TABLES.TABLE_NAME
ORDER BY
INFORMATION_SCHEMA.TABLES.TABLE_NAME ASC;

From the result, we can now easily notice the number of keys/constraints in all tables. This way we could find tables:
从结果中,我们现在可以轻松注意到所有表中的键/约束的数量。 这样我们可以找到表:
- Without a primary key. This could be the result of an error in the design process 没有主键。 这可能是设计过程中错误的结果
- Without foreign keys. Tables without foreign keys should be only dictionaries or some kind of reporting table. In all other cases, we should have a foreign key 没有外键。 没有外键的表应该只是字典或某种形式的报告表。 在所有其他情况下,我们应该有一个外键
- While UNIQUE shouldn’t be related to errors, in most cases we can expect that the table will have only 0 or 1 UNIQUE values. In case there is more, we could check why is that 尽管UNIQUE不应与错误相关,但在大多数情况下,我们可以预期该表将只有0或1个UNIQUE值。 如果还有更多,我们可以检查为什么
Queries like this one could be a part of controls checking is everything ok with your database. You could complicate things even more and use this query as a subquery for a more complex query that will automatically test predefined errors/alerts/warnings.
像这样的查询可能是控件检查的一部分,数据库的一切正常。 您甚至可以使事情变得更加复杂,并将此查询用作更复杂查询的子查询,该查询将自动测试预定义的错误/警报/警告。
INFORMATION_SCHEMA表 (The INFORMATION_SCHEMA Tables)
It would be hard to try out every single table and show what it returns. At least, that would be hard to put into one readable article. I strongly encourage you to play with the INFORMATION_SCHEMA database and explore what is where. The only thing I’ll do here is to list all the tables (views) you have at disposal. They are:
尝试每个表并显示其返回结果将很困难。 至少,很难将其放入一篇可读文章中。 我强烈建议您使用INFORMATION_SCHEMA数据库并探究何处。 我在这里要做的唯一一件事就是列出您可以使用的所有表(视图)。 他们是:
- CHECK_CONSTRAINTS – details related to each CHECK constraint CHECK_CONSTRAINTS –与每个CHECK约束有关的详细信息
- COLUMN_DOMAIN_USAGE – details related to columns that have an alias data type COLUMN_DOMAIN_USAGE –与具有别名数据类型的列有关的详细信息
- COLUMN_PRIVILEGES – columns privileges granted to or granted by the current user COLUMN_PRIVILEGES –当前用户授予或授予的列特权
- COLUMNS – columns from the current database COLUMNS-当前数据库中的列
- CONSTRAINT_COLUMN_USAGE – details about column-related constraints CONSTRAINT_COLUMN_USAGE –有关与列相关的约束的详细信息
- CONSTRAINT_TABLE_USAGE – details about table-related constraints CONSTRAINT_TABLE_USAGE –有关表的约束的详细信息
- DOMAIN_CONSTRAINTS – details related to alias data types and rules related to them (accessible by this user) DOMAIN_CONSTRAINTS –与别名数据类型有关的详细信息以及与其相关的规则(可由该用户访问)
- DOMAINS – alias data type details (accessible by this user) DOMAINS –别名数据类型的详细信息(可由该用户访问)
- KEY_COLUMN_USAGE – details returned if the column is related with keys or not KEY_COLUMN_USAGE –列是否与键相关的详细信息
- PARAMETERS – details related to each parameter related to user-defined functions and procedures accessible by this user 参数–与每个参数有关的详细信息,这些参数与该用户可访问的用户定义功能和过程有关
- REFERENTIAL_CONSTRAINTS – details about foreign keys REFERENTIAL_CONSTRAINTS –有关外键的详细信息
- ROUTINES –details related to routines (functions & procedures) stored in the database 例程–有关存储在数据库中的例程(功能和过程)的详细信息
- ROUTINE_COLUMNS – one row for each column returned by the table-valued function ROUTINE_COLUMNS –表值函数返回的每一列一行
- SCHEMATA – details related to schemas in the current database SCHEMATA –与当前数据库中的架构有关的详细信息
- TABLE_CONSTRAINTS – details related to table constraints in the current database TABLE_CONSTRAINTS –与当前数据库中的表约束有关的详细信息
- TABLE_PRIVILEGES –table privileges granted to or granted by the current user TABLE_PRIVILEGES –当前用户授予或授予的表特权
- TABLES –details related to tables stored in the database TABLES –与数据库中存储的表相关的详细信息
- VIEW_COLUMN_USAGE – details about columns used in the view definition VIEW_COLUMN_USAGE –有关视图定义中使用的列的详细信息
- VIEW_TABLE_USAGE – details about the tables used in the view definition VIEW_TABLE_USAGE –有关视图定义中使用的表的详细信息
- VIEWS – details related to views stored in the database VIEWS –与数据库中存储的视图有关的详细信息
结论 (Conclusion)
Querying the INFORMATION_SCHEMA database provides you with a lot of options on how to control the changes in the structure of your database as well to implement some level of automation on the database layer. In order to achieve these two, you should follow some rules, like naming convention, internal data modeling rules, etc. You could also exploit it to document your database. Later in this series, we’ll talk more about that.
查询INFORMATION_SCHEMA数据库为您提供了许多有关如何控制数据库结构更改以及如何在数据库层上实现一定程度的自动化的选项。 为了实现这两个,您应该遵循一些规则,例如命名约定,内部数据建模规则等。您还可以利用它来记录数据库。 在本系列的后面,我们将进一步讨论。
目录 (Table of contents)
翻译自: https://www.sqlshack.com/learn-sql-the-information_schema-database/

















 2114
2114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









