





In the previous articles of this series, we discussed a group of SQL Server Execution Plan operators that you will face when studying the SQL Execution Plan of different queries. We showed the Table Scan, Clustered Index Scan, Clustered Index Seek, the Non-Clustered Index Seek, RID Lookup, Key Lookup and Sort Execution Plan operators. In this article, we will discuss the third set of these SQL Execution Plan operators.
在本系列的前几篇文章中,我们讨论了在研究不同查询SQL执行计划时将面对的一组SQL Server执行计划操作符。 我们显示了表扫描,聚集索引扫描,聚集索引查找,非聚集索引查找,RID查找,键查找和排序执行计划运算符。 在本文中,我们将讨论这些SQL执行计划运算符的第三组。
At the beginning, we will implement a testing table with 3K records to be use it in the examples of this article. This demo table is created and filled with data using the T-SQL script below:
首先,我们将实现一个带有3K记录的测试表,以在本文的示例中使用它。 该演示表是使用以下T-SQL脚本创建的,并用数据填充:
CREATE TABLE ExPlanOperator_P3 (
ID INT IDENTITY(1, 1)
,STD_Name VARCHAR(50)
,STD_BirthDate DATETIME
,STD_Address VARCHAR(MAX)
,STD_Grade INT
)
GO
INSERT INTO ExPlanOperator_P3
VALUES (
'AA'
,'1998-05-30'
,'BB'
,93
) GO 1000
INSERT INTO ExPlanOperator_P3
VALUES (
'CC'
,'1998-10-13'
,'DD'
,78
) GO 1000
INSERT INTO ExPlanOperator_P3
VALUES (
'EE'
,'1998-06-24'
,'FF'
,85
) GO 1000
SQL Server聚合运算符–流聚合 (SQL Server Aggregate Operator – Stream Aggregate)
The Aggregate Operator is mainly used to calculate the aggregate expressions in the submitted query, by grouping the values of an aggregated column. The aggregate expressions include the MIN, MAX, COUNT, AVG, SUM operations. Let us run the below SELECT statement that retrieved the top 10 students who got the highest grade. And we will include the Actual SQL Execution Plan of the query. This can be achieved by aggregating the grades of the students to get the maximum grades using the MAX aggregate function. If all information about these top students is required, we should add all these columns in the GROUP BY clause, as shown below:
聚合运算符主要用于通过对聚合列的值进行分组来计算提交的查询中的聚合表达式。 聚合表达式包括MIN,MAX,COUNT,AVG,SUM操作。 让我们运行下面的SELECT语句,该语句检索成绩最高的前10名学生。 我们将包括查询的“实际SQL执行计划”。 这可以通过使用MAX汇总函数汇总学生的成绩以获得最高成绩来实现。 如果需要有关这些优秀学生的所有信息,则应在GROUP BY子句中添加所有这些列,如下所示:
SELECT TOP 10 ID
,STD_Name
,STD_BirthDate
,STD_Address
,MAX(STD_Grade)
FROM ExPlanOperator_P3
GROUP BY ID
,STD_Name
,STD_BirthDate
,STD_Address
Checking the SQL execution plan generated after executing that query, you will see that the SQL Server Engine will retrieve the rows from the table, then sort these values based on the columns specified in the GROUP BY clause and aggregate these values using the fastest aggregation method, which is the Stream Aggregate Operator. The Stream Aggregate operator is fast due to the fact that it requires the rows to be sorted based on the columns specified in the GROUP BY clause before aggregating these values. If the rows are not sorted in the Seek or Scan operator, the SQL Server Engine will force the use of the SORT operator, as shown below:
检查执行该查询后生成SQL执行计划,您将看到SQL Server Engine将检索表中的行,然后根据GROUP BY子句中指定的列对这些值进行排序,并使用最快的聚合方法对这些值进行聚合,这是流聚合运算符。 Stream Aggregate运算符之所以快速,是因为它要求在汇总这些值之前,必须根据GROUP BY子句中指定的列对行进行排序。 如果未在“搜索”或“扫描”运算符中对行进行排序,则SQL Server Engine将强制使用SORT运算符,如下所示:

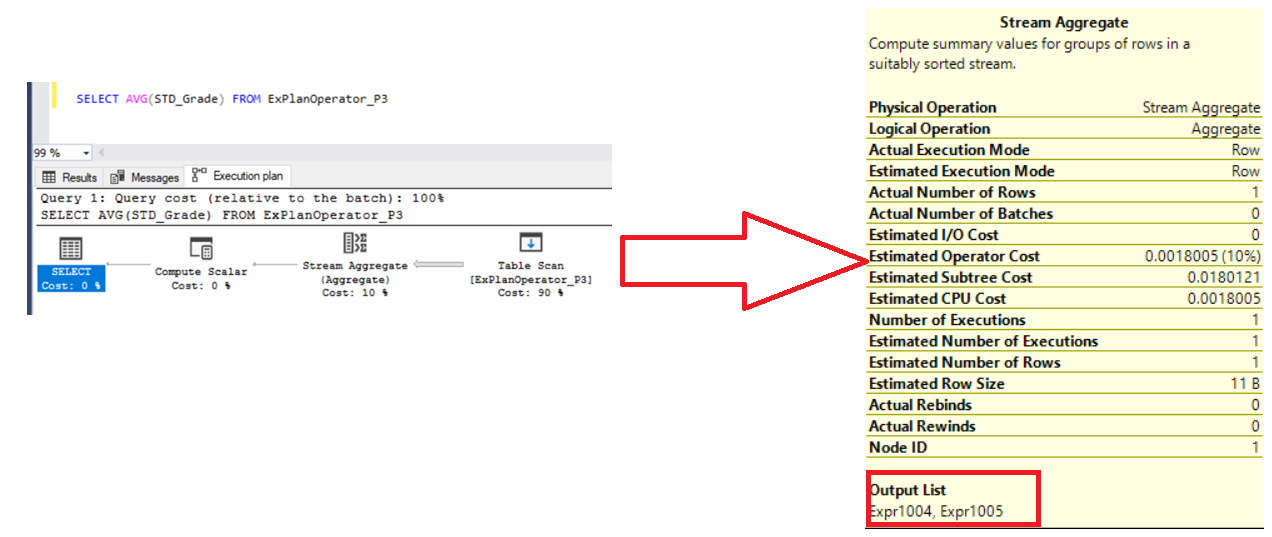
Another example for the Stream Aggregate operator is the AVG aggregate function order, that will compute the SUM and COUNT of the aggregated column and stored the values in Expr1004 and Expr1005 , in order to evaluate the AVG value, as shown below:
流聚合运算符的另一个示例是AVG聚合函数顺序,它将计算聚合列的SUM和COUNT并将值存储在Expr1004和Expr1005中,以便评估AVG值,如下所示:
SQL Server计算标量运算符 (SQL Server Compute Scalar Operator)
SQL Server Compute Scalar operator is used to calculate a new value from the existing row value by performing a scalar computation operation that results a computed value. These Scalar computations includes conversion or concatenation of the scalar value.
SQL Server 计算标量运算符用于通过执行产生计算值的标量计算操作,从现有行值中计算新值。 这些标量计算包括标量值的转换或串联。
Let us run the below SELECT T-SQL statement to generate a sentence that describes the grade for each student. And we will include the Actual SQL Execution Plan of the query:
让我们运行下面的SELECT T-SQL语句以生成一个描述每个学生成绩的句子。 我们将包括查询的“实际SQL执行计划”:
SELECT STD_Name + '_ has achieved _ ' + cast(STD_Grade AS VARCHAR(50)) AS STD_Result
FROM ExPlanOperator_P3
You will see from the execution plan, generated after executing the query, that the SQL Server Engine uses the Compute Scalar operator to perform a concatenation for the two specified columns to return a new scalar value, as shown below:
您将从执行查询后生成的执行计划中看到,SQL Server Engine使用Compute Scalar运算符对两个指定列执行串联以返回新的标量值,如下所示:

You can see from the previous SQL Execution Plan that the Compute Scalar operator is not an expensive operator, where it only costs 2% of the overall weight of our query, causing a minimal overhead.
您可以从以前SQL执行计划中看到,Compute Scalar运算符并不是昂贵的运算符,它仅占查询总权重的2%,因此开销最小。
SQL Server串联运算符 (SQL Server Concatenation Operator)
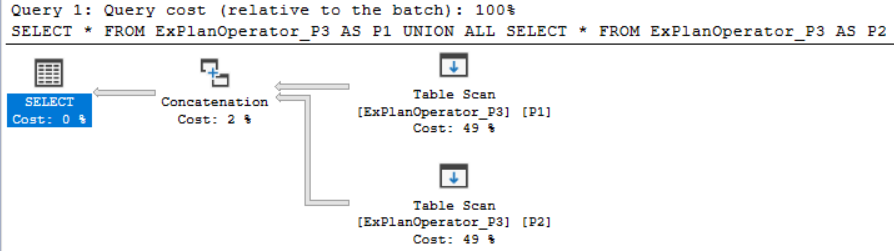
SQL Server Concatenation operator takes one or more sets of data in sequence and returns all records from each input data set. One of the most popular examples of this operator is the UNION ALL T-SQL statement. Let us run the below T-SQL statement that combines the result of two SELECT statement using the UNION ALL statement and we will include the Actual Plan of that query:
SQL Server 串联运算符按顺序获取一组或多组数据,并从每个输入数据集中返回所有记录。 该运算符最流行的示例之一是UNION ALL T-SQL语句。 让我们运行下面的T-SQL语句,该语句使用UNION ALL语句合并两个SELECT语句的结果,我们将包括该查询的实际计划:
SELECT *
FROM ExPlanOperator_P3 AS P1
UNION ALL
SELECT *
FROM ExPlanOperator_P3 AS P2
Then checking the Execution Plan generated after executing the query, you will see that the result returned from the two SELECT statements will be concatenated using the Concatenation operator to generate one result set, as showing below:
然后检查执行查询后生成的执行计划,您将看到将从两个SELECT语句返回的结果使用连接运算符进行连接以生成一个结果集,如下所示:
SQL Server断言运算符 (SQL Server Assert Operator )
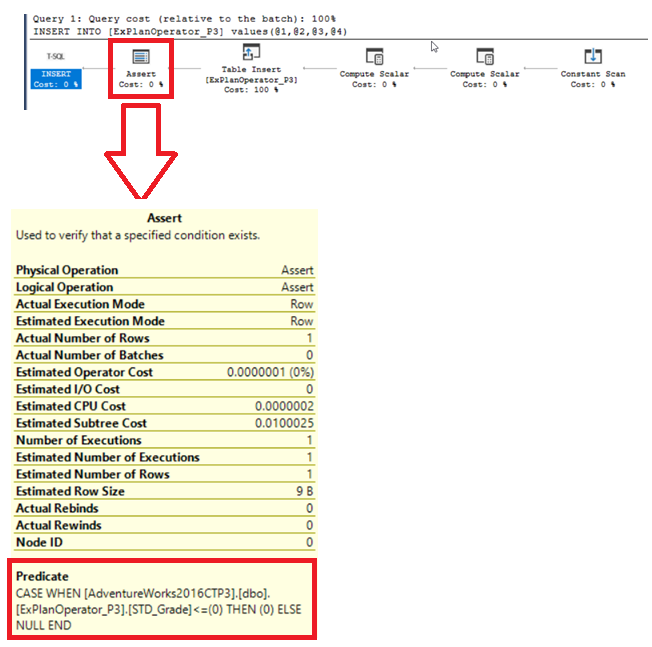
The SQL Server Assert operator is used to verify if the inserted values meet the previously defined CHECK or FOREIGN KEY constraints on the table. Assume that we have defined the below constraint on the demo table to ensure that only positive values are inserted into the STD_Grade column:
SQL Server Assert运算符用于验证插入的值是否满足表上先前定义的CHECK或FOREIGN KEY约束。 假设我们在演示表上定义了以下约束,以确保仅将正值插入STD_Grade列:
ALTER TABLE ExPlanOperator_P3 ADD CONSTRAINT CK_Grade_Positive CHECK (STD_Grade >0)
If you try to perform the below INSERT statement, including the Actual SQL Execution Plan of the query:
如果您尝试执行以下INSERT语句,包括查询的“实际SQL执行计划”:
INSERT INTO ExPlanOperator_P3 VALUES ('GG','1998-01-28','HH',74)
You will see from the SQL Execution Plan generated after executing the query, that the SQL Server Engine uses the ASSERT operator to validate if the inserted grade for that student meets the defined CHECK constraint, as shown below:
从执行查询后生成SQL执行计划中,您将看到SQL Server引擎使用ASSERT运算符来验证该学生的插入成绩是否满足定义的CHECK约束,如下所示:
SQL Server哈希匹配联接运算符 (SQL Server Hash Match Join Operator)
When joining two tables together, the SQL Server Engine divides the tables’ data into equally sized categories called buckets in order to access these data in a quick manner. This data structure is called a Hashing Table. It uses an algorithm to process the data and distribute it within the buckets. This algorithm called a Hashing Function.
将两个表连接在一起时,SQL Server引擎将表的数据分为大小相等的类别(称为存储桶),以便快速访问这些数据。 该数据结构称为哈希表 。 它使用一种算法来处理数据并将其分布在存储桶中。 该算法称为哈希 函数 。
Assume that we have created a new table that follows the absence of the students and fill it as below:
假设我们创建了一个新表,该表将根据学生的缺席情况进行填写,如下所示:
CREATE TABLE ExPlanOperator_JOIN (
STD_ID INT
,STD_AbsenceDays INT
)
INSERT INTO ExPlanOperator_JOIN
VALUES (
1
,5
) GO 100
INSERT INTO ExPlanOperator_JOIN
VALUES (
10
,2
) GO 100
After that, we will run the below SELECT statement that joins the base Students table with the Absence table, including the Actual SQL Execution plan of that query:
之后,我们将运行下面的SELECT语句,该语句将基本的Student表与Absence表连接在一起,包括该查询的实际SQL执行计划:
SELECT STD_Name
,STD_Grade
,STD_AbsenceDays
FROM ExPlanOperator_P3 P3
INNER JOIN ExPlanOperator_JOIN AB ON P3.ID = AB.STD_ID
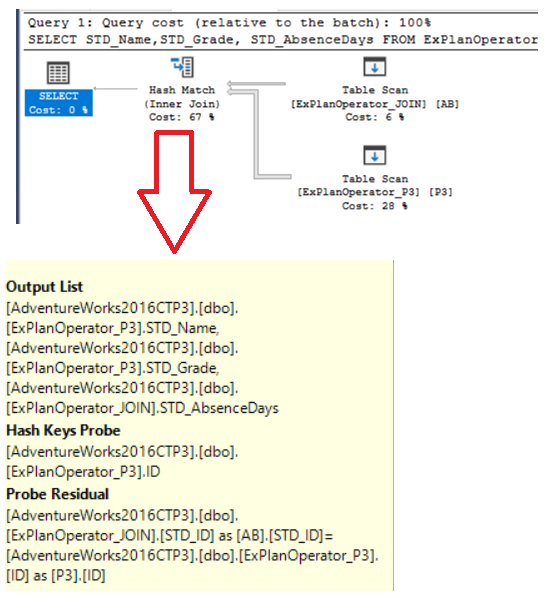
You will see from the Execution Plan generated after executing the query that, after reading data from the two joined table, the SQL Server Engine uses the Hash Match Join operator, in which it fills the hash table with data from the small, also called Probe table, then process the second large table, also called Build table, depending on the hash table values, to speed up the access to the requested data, as shown below:
您将从执行查询后生成的执行计划中看到,在从两个联接表中读取数据之后,SQL Server引擎使用哈希匹配联接运算符,在该运算符中,哈希表中的数据来自较小的数据(也称为探针)表,然后根据哈希表的值处理第二个大表(也称为生成表),以加快对请求数据的访问,如下所示:
SQL Server哈希匹配聚合运算符 (SQL Server Hash Match Aggregate operator)
SQL Server Hash Match Aggregate operator is used to process the large tables that are not sorted using an index. It builds a hash table in the memory, calculates a hash value for each record, then scan all other records for that hash key. If the value is not existing in the hash table, it will create a new entry in that hash table. In this way, the SQL Server Engine will guarantee that there is only one record for each group of data.
SQL Server哈希匹配聚合运算符用于处理未使用索引排序的大型表。 它在内存中构建一个哈希表,为每个记录计算一个哈希值,然后扫描所有其他记录以查找该哈希键。 如果该值在哈希表中不存在,它将在该哈希表中创建一个新条目。 这样,SQL Server引擎将保证每组数据只有一条记录。
Let us run the below SELECT statement that returns the number of duplicates for each ID value. And we will include the Actual SQL Execution Plan of the query:
让我们运行下面的SELECT语句,该语句返回每个ID值的重复次数。 我们将包括查询的“实际SQL执行计划”:
SELECT ID
,COUNT(*)
FROM ExPlanOperator_P3
GROUP BY ID
You will see from the SQL Execution plan generated after executing the query that, the SQL Server Engine will use the Hash Match Aggregate operator to perform and speed up the COUNT aggregation operation, as shown below:
从执行查询后生成SQL执行计划中可以看到,SQL Server引擎将使用哈希匹配聚合运算符来执行和加快COUNT聚合运算,如下所示:
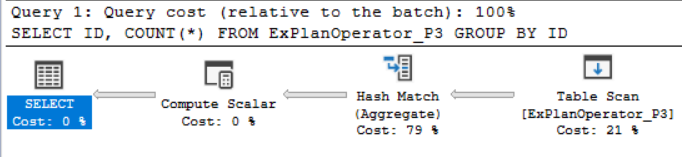
SQL Server合并联接运算符 (SQL Server Merge Join Operator)
SQL Server Merge Join operator is used with the different types of the JOIN operation, but only when the two JOIN data sets are sorted according to the join predicate. In this case, the Merge Join operator will read from the two input data sets at the same time, compare it then return the matched results.
SQL Server合并联接运算符与JOIN操作的不同类型一起使用,但是仅当两个JOIN数据集根据联接谓词排序时才使用。 在这种情况下,“合并联接”运算符将同时从两个输入数据集中读取,进行比较,然后返回匹配的结果。
Let us run the below query that joins the ExPlanOperator_P3 table with itself, and include the Actual SQL Execution Plan of the query:
让我们运行下面的查询,该查询将ExPlanOperator_P3表与其自身连接起来,并包括查询的“实际SQL执行计划”:
SELECT *
FROM ExPlanOperator_P3 E1
INNER JOIN ExPlanOperator_P3 E2 ON E1.ID = E2.ID
You will see from the SQL Execution Plan generated after executing the query that, the SQL Server Engine will scan each input, sort the data based on the ID column, as there is no index created on that table yet, then join the two inputs, that are sorted now based on the JOIN predicate using the fast Merge Join operator, as shown below:
从执行查询后生成SQL执行计划中可以看到,SQL Server引擎将扫描每个输入,根据ID列对数据进行排序,因为该表上尚未创建索引,然后将两个输入合并在一起,现在使用快速合并联接运算符基于JOIN谓词对它们进行排序,如下所示:
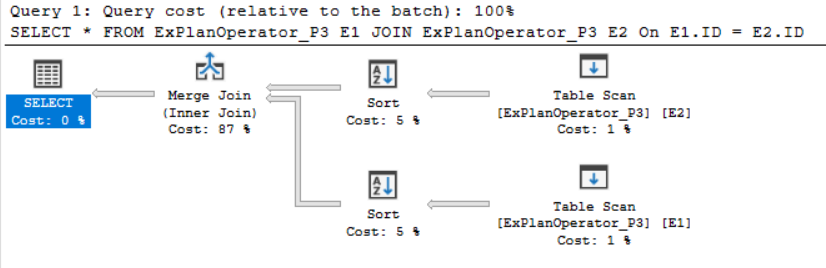
Although the Merge Join operator joins the sorted tables very fact, there still be an overhead, as both inputs will be loaded in memory for comparison purpose. The cost of the Merge Join operator is the sum of the two operator inputs.
尽管合并联接运算符实际上是联接已排序的表的,但是仍然存在开销,因为两个输入都将被加载到内存中以进行比较。 合并联接运算符的成本是两个运算符输入的总和。
SQL Server嵌套循环联接运算符 (SQL Server Nested Loops Join Operator)
The SQL Server Nested Loops Operator is used to join the upper input, also known as the outer input, by executing it one time, with the lower input, also known as the inner input, by executing it number of times equal to the number of records that matched the outer input. The SQL Server Query Optimizer decides to use the Nested Loops Join operator only when the outer input table is small, and the inner input table has an index created on the join predicate key.
SQL Server嵌套循环运算符用于通过一次执行将上部输入(也称为外部输入)与下部输入(也称为内部输入)联接,方法是执行等于或等于匹配外部输入的记录。 仅当外部输入表较小且内部输入表具有在联接谓词键上创建的索引时,SQL Server查询优化器才决定使用嵌套循环联接运算符。
Assume that we have created the below two indexes on our demo tables, as shown below:
假设我们在演示表上创建了以下两个索引,如下所示:
CREATE INDEX IX_ExPlanOperator_P3_ID ON ExPlanOperator_P3 (ID)
GO
CREATE INDEX IX_ExPlanOperator_JOIN ON ExPlanOperator_JOIN (
STD_ID
,STD_AbsenceDays
)
WITH (DROP_EXISTING = ON)
Then run the below SELECT statement that returns the students who missed the classes more than days, by joining the two demo tables together, including the Actual SQL Execution Plan of the query:
然后,通过将两个演示表(包括查询的“实际SQL执行计划”)结合在一起,运行下面的SELECT语句,返回错过了几天以上课程的学生:
SELECT E1.ID
FROM ExPlanOperator_P3 E1
INNER JOIN ExPlanOperator_JOIN E2 ON E1.ID = E2.STD_ID
WHERE E2.STD_AbsenceDays > 4
From the SQL Execution Plan, generated after executing the query, you can see that the SQL Server Engine joins the two tables using the Nested Loops Join operator, but performing an Index Scan operation for the outer input one time then performing an Index Seek operation 100 times for the inner input, as shown below:
从执行查询后生成SQL执行计划中,您可以看到SQL Server Engine使用嵌套循环联接运算符将两个表联接在一起,但是对外部输入执行一次索引扫描操作,然后执行一次索引查找操作100内部输入的时间,如下所示:
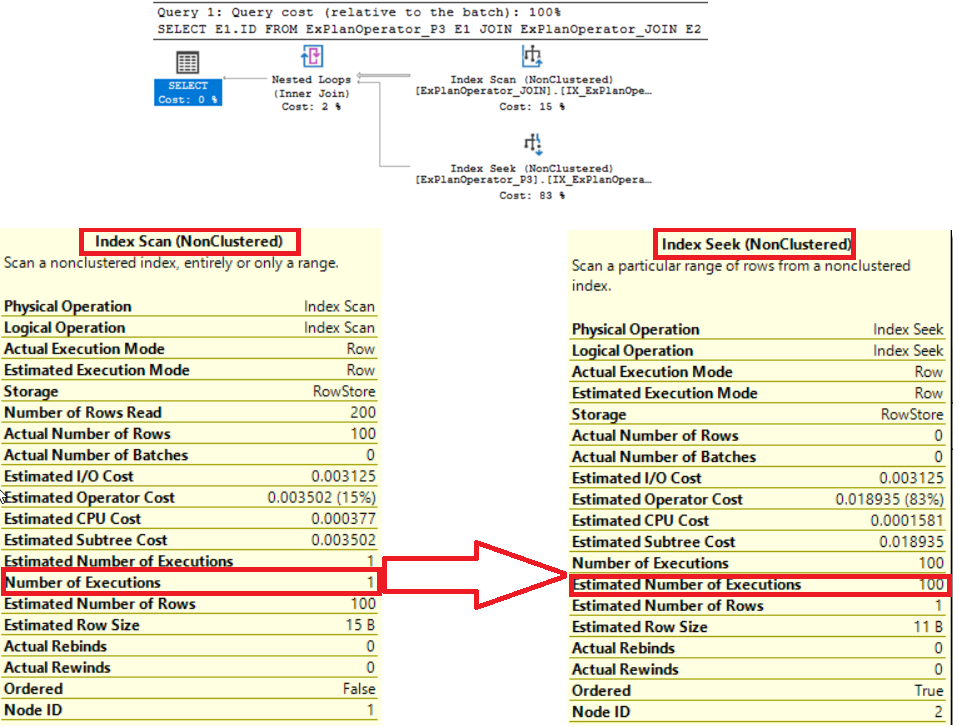
Again, although the cost of the Nested Loops operator is low compared to the overall weight of the query, you need to consider that the cost of that operator is highly depends on the multiplication of size of the outer input table and the size of the inner input table.
同样,尽管与查询的整体权重相比,嵌套循环运算符的成本较低,但您需要考虑到该运算符的成本很大程度上取决于外部输入表的大小与内部输入表的大小的乘积输入表。
Stay tuned for the next article in which we will discuss the fourth set of the SQL Server Execution Plan operators.
请继续关注下一篇文章,在该文章中我们将讨论第四组SQL Server执行计划操作符。
目录 (Table of contents)
翻译自: https://www.sqlshack.com/sql-server-execution-plan-operators-part-3/















 1319
1319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









