





In this post, we are going to look at the new feature in SQL Server 2017 – interleaved execution. You need to install SQL Server 2017 CTP 1.3 to try it, if you are ready, let’s start.
在本文中,我们将研究SQL Server 2017中的新功能–交错执行。 您需要安装SQL Server 2017 CTP 1.3进行尝试,如果准备好了,那就开始吧。
Now, when a CTP 2.0 of SQL Server 2017 is out, you don’t need to turn on the undocumented TF described further, and the plans are also different, so the examples from this post use CTP.1.3, probably not actual at the moment (I was asked to hold this post, until the public CTP 2 is out, and interleaved execution is officially announced). However, the post demonstrates Interleaved execution details and might be still interesting.
现在,当SQL Server 2017的CTP 2.0发布时,您无需打开进一步描述的未记录的TF,并且计划也有所不同,因此本文中的示例使用的是CTP.1.3,可能不实际。时刻(要求我担任此职位,直到公开的CTP 2发布,并正式宣布交错执行)。 但是,该帖子演示了交错执行细节,可能仍然很有趣。
T-SQL多语句表值函数 (T-SQL Multistatement Table-valued Function)
Function is a convenient way to decompose program logic and reduce a code complexity. However, T-SQL functions in SQL Server may lead to some problems with the performance.
函数是分解程序逻辑并降低代码复杂性的便捷方法。 但是,SQL Server中的T-SQL函数可能会导致性能问题。
There are three types of T-SQL functions in SQL Server (excluding In-Memory OLTP and CLR):
SQL Server中有三种类型的T-SQL函数(不包括内存中OLTP和CLR):
- Transact-SQL Inline Table-Valued Function Transact-SQL内联表值函数
- Transact-SQL Scalar Function Transact-SQL标量函数
- Transact-SQL Multistatement Table-valued Function Transact-SQL多语句表值函数
Inline Table-Valued Function could contain only one root SELECT statement that is used to describe its result, to keep it simple, we may say that this is a parameterized and named subquery. This is good from an optimization prospective, because the Query Optimizer may inline a function’s text into a query and optimize a query as a whole. That means it can do a lot of optimization tricks as well as estimate cardinality much better. That type of function used to be recommended for the most cases. However, it cannot contain any flow control operators, declarations or other procedural language elements.
内联表值函数只能包含一个用于描述其结果的根SELECT语句,为简单起见,我们可以说这是一个参数化的命名子查询。 从优化预期的角度来看这是好的,因为查询优化器可以将函数的文本内联到查询中,并从整体上优化查询。 这意味着它可以做很多优化技巧,并且可以更好地估计基数。 在大多数情况下,建议使用这种功能。 但是,它不能包含任何流控制运算符,声明或其他过程语言元素。
Two other types of functions can contain procedural language elements and may implement more complex logic. We’ll leave scalar functions alone, because it is not the topic of this post, and focus on Multistatement table-valued functions (mTVF).
另外两种类型的功能可以包含过程语言元素,并且可以实现更复杂的逻辑。 我们将不理会标量函数,因为它不是本文的主题,而将重点放在多语句表值函数(mTVF)上。
The fact that mTVF can implement complex procedural logic makes it more powerful for the code reuse, however more challenging from the optimization prospective. It is hard or impossible to estimate how many rows a function will return, i.e. estimate cardinality, before you start executing it, but cardinality estimation is crucial during the query compilation if you want to get an adequate plan.
mTVF可以实现复杂的过程逻辑,这一事实使它对于代码重用更加强大,但是从优化的前景出发更具挑战性。 在开始执行函数之前,很难或不可能估计函数将返回多少行,即估计基数,但是如果要获得适当的计划,基数估计在查询编译期间至关重要。
In SQL Server 2012 and earlier, mTVF had a fixed estimate of 1 row, which sometimes lead to inefficient query plans. Starting from SQL Server 2014 the estimate was increased up to 100 rows but was still fixed.
在SQL Server 2012及更早版本中,mTVF的固定估计值为1行,这有时会导致查询计划效率低下。 从SQL Server 2014开始,估算值增加到最多100行,但仍是固定的。
定期执行mTVF (Regular mTVF Execution)
To demonstrate the estimation problem, we will use SQL Server 2017 CTP 1.3 and a sample AdvertureWorksDW database under the compatibility level (CL) 130.
为了演示估算问题,我们将使用SQL Server 2017 CTP 1.3和兼容级别(CL)130下的示例AdvertureWorksDW数据库。
We create a test mTVF function, that populates top N rows in its result table depending on the parameter @n, and join it with a table that has a clustered Columnstore index.
我们创建了一个测试mTVF函数,该函数根据参数@n填充结果表中的前N行,并将其与具有聚簇Columnstore索引的表联接。
Let’s clear a procedure cache, include actual execution plan and run the query:
让我们清除过程高速缓存,包括实际的执行计划并运行查询:
use AdventureworksDW2016CTP3;
go
-- Set compatibility level of SQL Server 2016
alter database AdventureworksDW2016CTP3 set compatibility_level = 130;
go
-- Create multistatement table-valued function
create or alter function dbo.uf(@n int)
returns @t table(SalesOrderNumber nvarchar(40), SalesOrderLineNumber tinyint)
with schemabinding
as
begin
insert @t(SalesOrderNumber, SalesOrderLineNumber)
select top(@n)
SalesOrderNumber,
SalesOrderLineNumber
from
dbo.FactResellerSalesXL_CCI;
return;
end
go
-- Clear procedure cache for DB
alter database scoped configuration clear procedure_cache;
go
-- Run the query with mTVF
set statistics xml on;
select
c = count_big(*)
from
dbo.FactResellerSalesXL_CCI c
join dbo.uf(10000) t on t.SalesOrderNumber = c.SalesOrderNumber and t.SalesOrderLineNumber = c.SalesOrderLineNumber
;
set statistics xml off;
go
We see the following query plan:
我们看到以下查询计划:
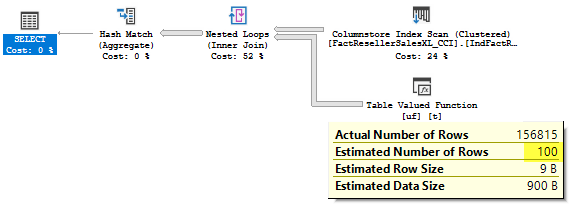
You see that a mTVF cardinality as well as the cardinality of the mTVF result table scan is estimated as 100 rows, as we have said earlier, this is a fixed estimate starting from 2014 (you may try USE HINT (‘FORCE_LEGACY_CARDINALITY_ESTIMATION’) to force the estimate before 2014 and observe 1 row estimate), but actually there were 10 000 rows.
您已经看到,mTVF基数以及mTVF结果表扫描的基数估计为100行,正如我们之前所说,这是从2014年开始的固定估计值(您可以尝试使用USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION')强制(2014年之前的估算值,并观察1行估算值),但实际上有10000行。
选项RECOMPILE修正估算值 (Option RECOMPILE to Fix the Estimate)
You may know that adding a query hint RECOMPILE to a query with a table variable allows the optimizer to sniff the actual number of rows and use this number to fix the cardinality estimate, see the following article for more details.
您可能知道,向带有表变量的查询中添加查询提示RECOMPILE允许优化器嗅探实际的行数并使用该数字来修正基数估计,有关更多详细信息,请参见以下文章 。
We may add the query hint to the query inside the mTVF or to the query itself, or to the both of them. Let’s try both of them.
我们可以将查询提示添加到mTVF内的查询或查询本身,或同时添加到这两者。 让我们尝试两者。
-- Create multistatement table-valued function
create or alter function dbo.uf(@n int)
returns @t table(SalesOrderNumber nvarchar(40), SalesOrderLineNumber tinyint)
with schemabinding
as
begin
insert @t(SalesOrderNumber, SalesOrderLineNumber)
select top(@n)
SalesOrderNumber,
SalesOrderLineNumber
from
dbo.FactResellerSalesXL_CCI
option(recompile);
return;
end
go
-- Clear procedure cache for DB
alter database scoped configuration clear procedure_cache;
go
-- Run the query with mTVF
set statistics xml on;
declare @n int = 10001
select
c = count_big(*)
from
dbo.FactResellerSalesXL_CCI c
join dbo.uf(10000) t on t.SalesOrderNumber = c.SalesOrderNumber and t.SalesOrderLineNumber = c.SalesOrderLineNumber
option(recompile)
;
set statistics xml off;
go
Unfortunately, the plan and estimates are the same:
不幸的是,计划和估计是相同的:
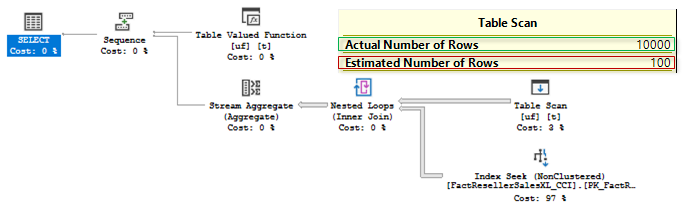
We can see that a regular trick with an OPTION (RECOMILE) is not helpful in this case. SQL Server 2017 may address this problem from the other angle under certain conditions.
我们可以看到带有OPTION(RECOMILE)的常规技巧在这种情况下没有帮助。 SQL Server 2017在某些情况下可能会从另一个角度解决此问题。
交错执行 (Interleaved Execution)
The idea of interleaved execution is to take a part of a query that might be executed independently, execute it, and then reuse the result and the result cardinality to recompile and execute the rest of the query. A good candidate for such approach is an mTVF that might be executed independently of the rest of a query, so it is taken as a first step in implementing the interleaved execution in a current CTP version of SQL Server 2017.
交错执行的思想是获取一部分可能独立执行的查询,然后执行该查询,然后重用结果和结果基数以重新编译并执行其余查询。 这种方法的一个很好的选择是mTVF,它可以独立于其余查询执行,因此它被视为在SQL Server 2017的当前CTP版本中实现交错执行的第一步。
To enable interleave execution in CTP 1.3 we should use an undocumented trace flag 11005, starting from CTP 2.0 we only need to switch DB CL to 140 (and the TF disables interleaved execution). Under the CL level 140, I’ll also use an undocumented query hint DISABLE_BATCH_MODE_ADAPTIVE_JOINS, to avoid adaptive join in a query plan, because it will be a topic for the next blog post.
为了在CTP 1.3中启用交错执行,我们应该使用未记录的跟踪标志11005 ,从CTP 2.0开始,我们只需要将DB CL切换到140(并且TF禁用交错执行)。 在CL级别140下,我还将使用未记录的查询提示DISABLE_BATCH_MODE_ADAPTIVE_JOINS,以避免在查询计划中进行自适应联接,因为它将成为下一篇博客文章的主题。
Let’s return function to the original state (without option recompile) and see, how the query plan will change if the interleaved execution feature is enabled.
让我们将函数返回到原始状态(不重新编译选项),看看启用交错执行功能后查询计划将如何变化。
alter database AdventureworksDW2016CTP3 set compatibility_level = 140;
go
-- Create multistatement table-valued function
create or alter function dbo.uf(@n int)
returns @t table(SalesOrderNumber nvarchar(40), SalesOrderLineNumber tinyint)
with schemabinding
as
begin
insert @t(SalesOrderNumber, SalesOrderLineNumber)
select top(@n)
SalesOrderNumber,
SalesOrderLineNumber
from
dbo.FactResellerSalesXL_CCI;
return;
end
go
-- Clear procedure cache for DB
alter database scoped configuration clear procedure_cache;
go
-- Run the query with mTVF
set statistics xml on;
select
c = count_big(*)
from
dbo.FactResellerSalesXL_CCI c
join dbo.uf(10000) t on t.SalesOrderNumber = c.SalesOrderNumber and t.SalesOrderLineNumber = c.SalesOrderLineNumber
option(use hint('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')) -- disable adaptive join
;
set statistics xml off;
go
The plan is now different:
现在的计划有所不同:
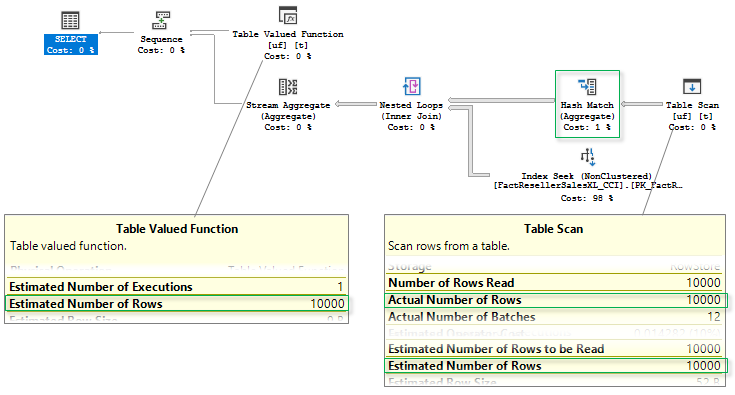
First of all, note that Estimated Number of Rows is 10 000 now, which is correct and equals Actual Number of Rows. Due to the correct estimate, the optimizer decided that there are enough rows to benefit from a partial (local/global) aggregation and introduced a partial Hash aggregate before the join.
首先,请注意,“估计行数”现在为10000,这是正确的,等于“实际行数”。 由于估算正确,优化器确定有足够的行可以从部分(本地/全局)聚合中受益,因此在连接之前引入了部分Hash聚合。
If you take a Profiler, enable events SP:StmtStarting, SP:StmtCompleted, SQL:StmtStarting, SQL:StmtCompleted and run the query without and with a TF, you’ll see what does it actually mean “interleaved” in terms of the execution sequence.
如果您使用探查器,则启用事件SP:StmtStarting,SP:StmtCompleted,SQL:StmtStarting,SQL:StmtCompleted并在不使用TF的情况下运行查询,而在使用TF的情况下运行查询,您将看到它在执行方面实际上意味着“交错”序列。
During the regular execution the query starts executing, then the function is executed, the query continues execution and finishes the execution. We see the following event sequence:
在常规执行期间,查询开始执行,然后执行函数,查询继续执行并完成执行。 我们看到以下事件序列:

During the interleaved execution, we see the following sequence:
在交错执行期间,我们看到以下序列:
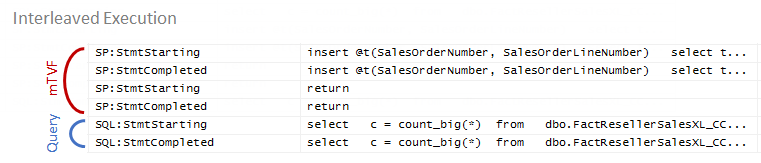
The execution of the mTVF and the query is interleaved, at first mTVF is executed, and then the query starts execution and reuses the mTVF result.
mTVF和查询的执行交织在一起,首先执行mTVF,然后查询开始执行并重用mTVF结果。
交错执行过程 (Interleaved Execution Process)
To look at the interleaved execution process in more details, we will use extended events. We enable the following known extended events:
为了更详细地了解交错执行过程,我们将使用扩展事件。 我们启用以下已知的扩展事件:
- query_post_compilation_showplan – Occurs after a SQL statement is compiled. This event returns an XML representation of the estimated query plan that is generated when the query is compiled. query_post_compilation_showplan –在编译SQL语句之后发生。 此事件返回在编译查询时生成的估计查询计划的XML表示形式。
- query_post_execution_showplan – Occurs after a SQL statement is executed. This event returns an XML representation of the actual query plan. query_post_execution_showplan –在执行SQL语句之后发生。 此事件返回实际查询计划的XML表示形式。
- sp_cache_insert – Occurs when a stored procedure is inserted into the procedure cache. sp_cache_insert –将存储过程插入到过程高速缓存中时发生。
- sp_cache_miss – Occurs when a stored procedure is not found in the procedure cache. sp_cache_miss –在过程高速缓存中未找到存储过程时发生。
- sp_statement_starting – Occurs when a statement inside a stored procedure has started. sp_statement_starting –在存储过程中的语句开始时发生。
- sp_statement_completed – Occurs when a statement inside a stored procedure has completed. sp_statement_completed –在存储过程中的语句完成时发生。
- sql_batch_starting – Occurs when a Transact-SQL batch has started executing. sql_batch_starting –在Transact-SQL批处理开始执行时发生。
- sql_batch_completed – Occurs when a Transact-SQL batch has finished executing. sql_batch_completed –在Transact-SQL批处理完成执行时发生。
- sql_statement_starting – Occurs when a Transact-SQL statement has started. sql_statement_starting –在Transact-SQL语句启动时发生。
- sql_statement_completed – Occurs when a Transact-SQL statement has completed. sql_statement_completed –在Transact-SQL语句完成时发生。
- sql_statement_recompile – Occurs when a statement-level recompilation is required by any kind of batch. sql_statement_recompile –在任何种类的批处理中需要语句级重新编译时发生。
And some new extended events related to an interleaved execution in particular.
特别是一些新的扩展事件与交错执行有关。
- interleaved_exec_stats_update – Event describe the statistics updated by interleaved execution. interleaved_exec_stats_update –事件描述通过交错执行更新的统计信息。
- estimated_card – Estimated cardinality Estimated_card –估计基数
- actual_card – Updated actual cardinality actual_card –更新的实际基数
- estimated_pages – Estimate pages Estimate_pages –估算页面
- actual_pages – Updated actual pages Actual_pages –更新的实际页面
- interleaved_exec_status – Event marking the interleaved execution in QO. interleaved_exec_status –在QO中标记交错执行的事件。
- operator_code – Op code of the starting expression for interleaved execution. operator_code –交错执行的起始表达式的操作码。
- event_type – Whether this is a start of the end of the interleaved execution event_type –这是否是交错执行结束的开始
- time_ticks – Time of this event happens time_ticks –事件发生的时间
- recompilation_for_interleaved_exec – Fired when recompilation is triggered for interleaved execution. recompilation_for_interleaved_exec –触发交错执行的重新编译时触发。
- current_compile_statement_id – Current compilation statement’s id in the batch. current_compile_statement_id –批处理中当前编译语句的ID。
- current_execution_statement_id – Current execution statement’s id in the batch. current_execution_statement_id –批处理中当前执行语句的ID。
I have also added a few additional columns: event_sequence, session_id and sql_text, and a filter by session_idequals SPID. The full script of the session definition is provided at the end of the post.
我还添加了一些其他列:event_sequence,session_id和sql_text,以及按session_idequals SPID进行的筛选。 文章末尾提供了会话定义的完整脚本。
Let’s clear DB cache, turn on the session, click “Watch Live Data” in SSMS, run previous query, then stop the session and look what do we have in a Live data grid (I have chosen 5 columns to be displayed in the grid: event_sequence, name, object_type, sql_text and statement for sql_statement_… event, the rest of the columns will be available in the event details below).
让我们清除数据库缓存,打开会话,在SSMS中单击“观看实时数据”,运行上一个查询,然后停止会话并查看实时数据网格中的内容(我选择了5列以显示在网格中:event_sequence,名称,object_type,sql_text和sql_statement_…事件的语句,其余列将在下面的事件详细信息中提供。
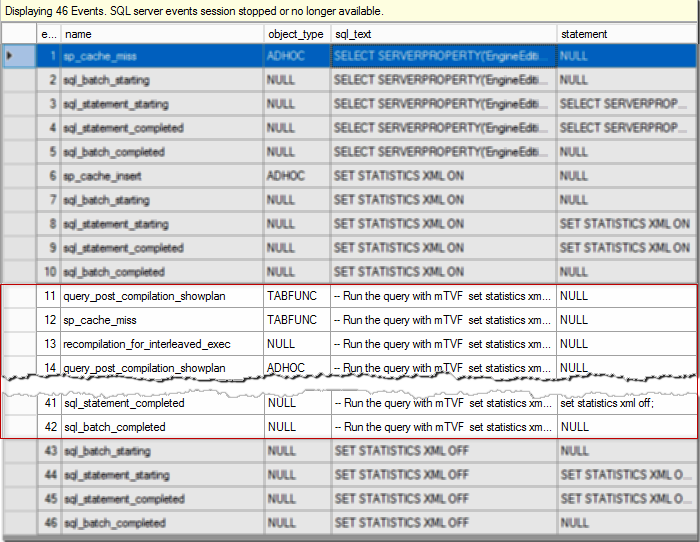
First 10 events and last 4 events are not interesting for us here, they are fired because SSMS issue some commands internally to run the query, get a plan, etc. We will focus on the events from 11 to 42 and look at them step by step in details to see what’s going on.
前10个事件和后4个事件在这里对我们来说并不有趣,它们被触发是因为SSMS在内部发出了一些命令来运行查询,获取计划等。我们将重点关注11到42之间的事件,并逐步研究它们详细了解发生了什么。
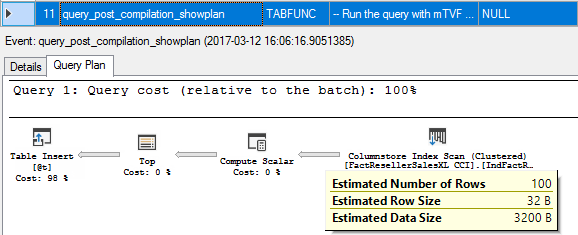
11. query_post_compilation_showplan
11. query_post_compilation_showplan
We start compiling our batch with compiling our mTVF. Note the estimated number of rows is 100.
我们从编译mTVF开始编译批处理。 请注意,估计的行数为100。
12. sp_cache_miss
12. sp_cache_miss
We have cleared the procedure cache before running the query so there is no plan for the mTVF and we see a cache miss.
在运行查询之前,我们已经清除了过程高速缓存,因此没有针对mTVF的计划,并且我们看到高速缓存未命中。

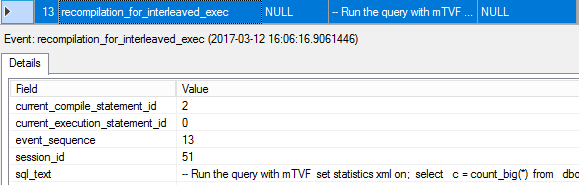
13. recompilation_for_interleaved_exec
13. recompilation_for_interleaved_exec
SQL Server recognized that there is an mTVF in the batch, it might be executed independently of the rest of the query and the query is executed under a TF that enables interleaved execution, so the query may benefit from it and the optimizer marks the statement for recompilation.
SQL Server认识到批处理中有一个mTVF,它可能与其余查询无关地执行,并且查询是在允许交错执行的TF下执行的,因此查询可能会从中受益,并且优化器将语句标记为重新编译。
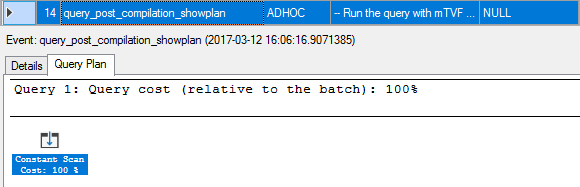
14. query_post_compilation_showplan
14. query_post_compilation_showplan
SQL Server tries to compile our query; however, it is marked for a recompilation due to the interleaved execution on the previous step, so it inserts a kind of a plan stub instead of fully compiling the query.
SQL Server尝试编译我们的查询; 但是,由于在上一步中执行了交错执行,因此将其标记为重新编译,因此它插入一种计划存根,而不是完全编译查询。
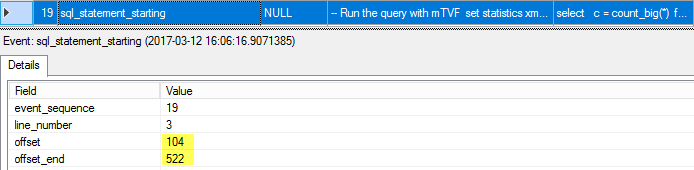
You may identify that this is a plan for our select query statement if you look into the event details offset columns.
如果您查看事件详细信息偏移量列,则可以确定这是我们的select查询语句的计划。
Number 104 is the position when our select statement starts and 522 is the position where it ends.
104是我们的select语句开始的位置,而522是它结束的位置。
15. sp_cache_insert
15. sp_cache_insert
This plan stub is also inserted into a cache. Now we have our batch compiled and may start executing it.
该计划存根也插入到缓存中。 现在,我们已经编译了批处理,并可能开始执行它。
16. sql_batch_starting
16. sql_batch_starting
Starting execution of the batch.
开始执行批处理。
17, 18. sql_statement_starting, sql_statement_completed
17,18. sql_statement_starting,sql_statement_completed
These events are fired because of the execution of the first statement in our batch, which sets a statistics xml mode on.
由于执行了我们批处理中的第一条语句而触发了这些事件,该语句将统计信息xml模式设置为on。
19. sql_statement_starting
19. sql_statement_starting
Now we start executing the second statement in the batch – our query. Note the offsets of the statement, 104 and 522, we have seen them already, when a plan stub for the statement was created.
现在,我们开始执行批处理中的第二条语句-查询。 注意,在为语句创建计划存根时,已经看到了语句104和522的偏移量。
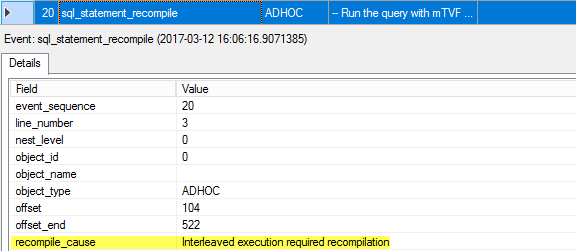
20. sql_statement_recompile
20. sql_statement_recompile
We still have no plan for the statement (because it was marked for the interleaved execution at step 13), but only a plan stub, we need to recompile a statement. Note the reason for the recompilation – it is an “Interleaved execution required recompilation”.
我们仍然没有该语句的计划(因为它已在步骤13中标记为交错执行),但是只有一个计划存根,我们需要重新编译一条语句。 请注意重新编译的原因-这是“需要交错执行的重新编译”。
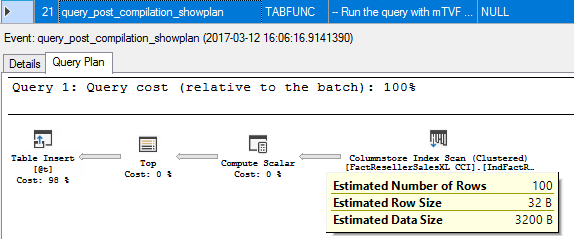
21. query_post_compilation_showplan
21. query_post_compilation_showplan
At first, we recompile the mTVF module and we see the compiled plan, the estimated number of rows is 100.
首先,我们重新编译mTVF模块,然后看到已编译的计划,估计的行数为100。
22. sp_cache_miss
22. sp_cache_miss
New recompiled plan is not cached, so there is a cache miss for table function.
新的重新编译计划未缓存,因此表功能存在缓存未命中的情况。
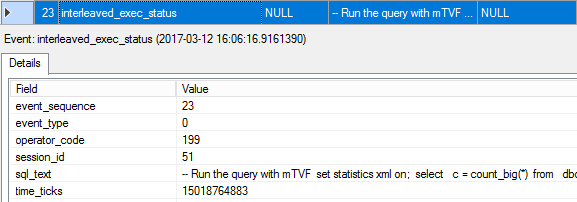
23. interleaved_exec_status
23. interleaved_exec_status
This is the event that is marking the interleave execution; note the event type is 0, which stands for start interleaved execution. The operator_code is the internal class number, 199 stands for mTVF.
这是标记交错执行的事件。 请注意,事件类型为0,表示开始交错执行。 operator_code是内部类号,199表示mTVF。
24. query_post_compilation_showplan
24. query_post_compilation_showplan
Identical plans, but different details: nest_level and a plan_handle.
计划相同,但细节不同:nest_level和plan_handle。
25. sp_cache_miss
25. sp_cache_miss
There is no such plan in the cache also.
缓存中也没有这样的计划。

26. query_post_compilation_showplan
26. query_post_compilation_showplan
Finally, we have a plan that is compiled with a sniffed value 10 000 due to a recompilation, note the number of estimated rows is now 10 000. This plan is used for the mTVF execution, but the value 10 000 from this plan is not used to optimize the rest of the query, because a post execution plan with an actual cardinality is used for that purpose.
最后,我们有一个计划,由于重新编译,该计划的嗅探值为10,000,请注意,现在估计的行数为10,000。该计划用于mTVF执行,但该计划中的值10,000不是用于优化其余查询,因为具有实际基数的后执行计划用于该目的。
27. sp_cache_insert
27. sp_cache_insert
This plan is cached for a later reuse.
该计划被缓存以备后用。

28. sp_statement_starting
28. sp_statement_starting
At this point, we have a plan for the mTVF and ready to execute it. The first statement in mTVF is an INSERT statement and it starts executing.
至此,我们已经为mTVF制定了一个计划,并准备执行它。 mTVF中的第一个语句是INSERT语句,它开始执行。

29. query_post_execution_showplan
29. query_post_execution_showplan
The first statement of mTVF is executed and we see an actual, post execution plan with an actual number of rows. The actual number of rows for Columnstore Index Scan is slightly more than 10 000, which is because it is executed in a Batch Mode, there are 12 batches (you may see it in the plan), each batch may be up to 900 rows, and so 900*12 gives us 10800. That is not a problem, because the Top operator will take only first 10 000 and insert them in the result table.
mTVF的第一条语句已执行,我们看到了一个实际的后期执行计划,其中包含实际的行数。 列存储索引扫描的实际行数略大于10000,这是因为它以批处理模式执行,共有12个批处理(您可能会在计划中看到它),每个批处理最多可以有900行,所以900 * 12给我们10800。这不是问题,因为Top运算符只会取前10000并将其插入结果表。
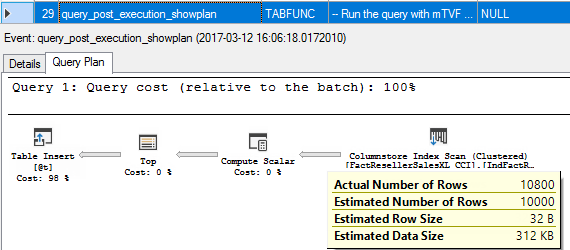
30. sp_statement_completed
30. sp_statement_completed
The execution of the first statement of the mTVF is completed.
mTVF的第一条语句的执行完成。

31, 32. sp_statement_starting, sp_statement_completed
31,32. sp_statement_starting,sp_statement_completed
The second statement in the mTVF is a RETURN statement. It is executed so we see the “starting” and “completed” events.
mTVF中的第二条语句是RETURN语句。 它已执行,因此我们看到了“开始”和“完成”事件。

33. interleaved_exec_status
33. interleaved_exec_status
One more event about the interleaved execution status is fired; the event_type equals 1, which stands for “ready to execute the main query”.
触发了另一个有关交错执行状态的事件; event_type等于1,代表“准备执行主查询”。
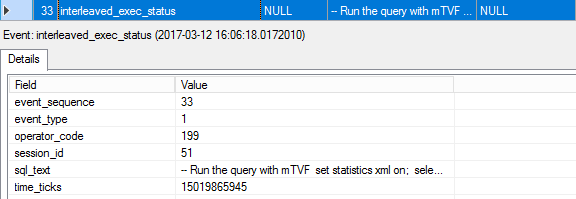
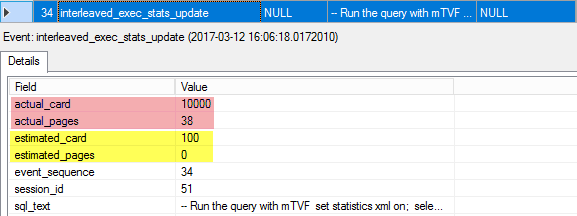
34. interleaved_exec_stats_update
34. interleaved_exec_stats_update
This event describes the statistics that was updated for the interleaved execution. You may see the initial estimated cardinality and the number of pages, as well as the actual number of rows and pages. Those actual values will be used to optimize the rest of the query.
此事件描述为交错执行更新的统计信息。 您可能会看到初始的估计基数和页面数,以及实际的行数和页面数。 这些实际值将用于优化其余查询。
35. query_post_compilation_showplan
35. query_post_compilation_showplan
The plan for the rest of the query is compiled, note this is a post compilation plan, but it has 10 000 rows estimate for the mTVF and the result table scan.
其余查询的计划已编译,请注意,这是一个后期编译计划,但它为mTVF和结果表扫描估计有10000行。

36. sql_statement_starting
36. sql_statement_starting
At this point we have a compiled plan for the whole query and we are ready to start executing the rest of the query. Note, the mTVF is not executed the second time, the results saved to the mTVF table are reused. Also, note that a state of the query is “Recompiled”, because it was marked for recompilation due to the interleaved execution (step 13).
至此,我们已经为整个查询制定了计划,并且可以开始执行其余的查询了。 注意,第二次不执行mTVF,保存到mTVF表中的结果将被重用。 另外,请注意,查询的状态为“已重新编译”,因为由于交错执行而将其标记为重新编译(步骤13)。
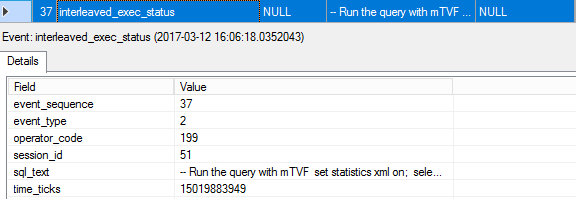
37. interleaved_exec_status
37. interleaved_exec_status
We saw the interleaved status event the last time in this execution; the event_type is 2, which says that the interleaved execution has finished.
在上一次执行中,我们看到了交错状态事件。 event_type为2,表示交错执行已完成。
38. query_post_execution_showplan
38. query_post_execution_showplan
Finally, we get a post execution actual plan of the whole query.
最后,我们获得了整个查询的执行后实际计划。
39, 40, 41, 42. sql_statement_completed, sql_statement_starting, sql_statement_completed, sql_batch_completed
39、40、41、42。sql_statement_completed,sql_statement_starting,sql_statement_completed,sql_batch_completed
The last events fired for the query completed, “set statistics xml off” completed and the whole batch is completed.
为查询触发的最后一个事件已完成,“将统计信息xml关闭”已完成,并且整个批次已完成。
实际基数 (Actual Cardinality is taken)
I would like to repeat the idea of the interleaved execution one more time; we take an actual cardinality from the part of the query. We have seen the event interleaved_exec_stats_update at the step 34, which showed us that operator statistics was updated.
我想再说一次交错执行的想法; 我们从查询部分获取实际基数。 我们已经在步骤34看到了事件interleaved_exec_stats_update,该事件向我们显示了操作员统计信息已更新。
However, the estimated number of rows in the post compilation plan at the step 29 is also 10 000, so I’d like to take one more experiment to see that an actual cardinality was really picked for the query optimization. For that purpose, let’s introduce an expression in a Top operator, which includes some calculation, for example like this.
但是,在步骤29中,后编译计划中的估计行数也是10000,因此我想再做一次实验,以查看是否为查询优化选择了实际的基数。 为此,让我们在Top运算符中引入一个表达式,其中包括一些计算,例如这样。
-- Create multistatement table-valued function
create or alter function dbo.uf(@n int)
returns @t table(SalesOrderNumber nvarchar(40), SalesOrderLineNumber tinyint)
with schemabinding
as
begin
insert @t(SalesOrderNumber, SalesOrderLineNumber)
select top(@n + datepart(ms,getdate()))
SalesOrderNumber,
SalesOrderLineNumber
from
dbo.FactResellerSalesXL_CCI;
return;
end
go
In that case, the Top expression with a runtime constant function GETDATE prevents the optimizer from estimating the correct number of rows, if you rerun the query with the extended events trace enabled, you will see the post compilation query plan difference at the step 26, it is now 100 rows guess estimate.
在这种情况下,带有运行时常数函数GETDATE的Top表达式会阻止优化器估计正确的行数,如果在启用了扩展事件跟踪的情况下重新运行查询,则会在步骤26中看到编译后查询计划的差异,现在是100行猜测估计。
When the function is executed and there is a post execution plan (step 29), you may see that the Top expression is calculated and some value (876) is added to a 10 000 constant, so you see the actual number of rows is now 10 876, though, the estimated is 100.
当函数被执行并且有一个后执行计划时(步骤29),您可能会看到计算了Top表达式并将一些值(876)添加到10,000常量中,因此您现在看到的实际行数是10 876,但是,估计是100。
If you then look at the post execution plan (step 38) for the whole query, you will see, that an actual number of rows is 10 876, but the estimated number of rows is also 10 876, which means 10 876 was really used to estimate a cardinality.
然后,如果您查看整个查询的执行计划(步骤38),则会看到实际行数是10 876,但是估计的行数也是10 876,这意味着确实使用了10 876估计基数。
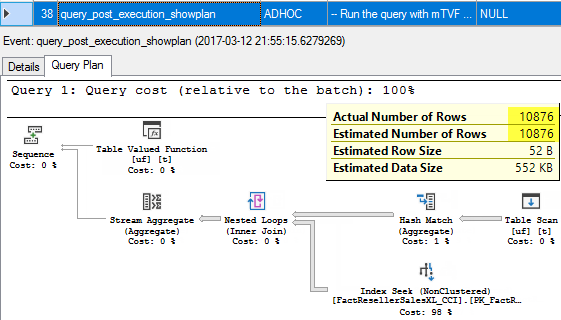
If you run the query a couple of times, each time you will see the new estimated value, depending, on what second’s portion is added to a top expression and what is the actual number of rows in the mTVF plan. As we can see the actual number of rows from the function is really used to estimate cardinality.
如果您多次运行该查询,则每次您都会看到新的估计值,具体取决于添加到顶部表达式中的秒部分以及mTVF计划中的实际行数。 如我们所见,该函数的实际行数确实用于估计基数。
相关参数 (Correlated Parameters)
Let’s introduce some correlated parameters in our function and provide values from the outer query.
让我们在函数中引入一些相关参数,并从外部查询中提供值。
-- Create multistatement table-valued function
create or alter function dbo.uf(@n int, @SalesOrderNumber nvarchar(40))
returns @t table(SalesOrderNumber nvarchar(40), SalesOrderLineNumber tinyint)
with schemabinding
as
begin
insert @t(SalesOrderNumber, SalesOrderLineNumber)
select top(@n)
SalesOrderNumber,
SalesOrderLineNumber
from
dbo.FactResellerSalesXL_CCI
where
SalesOrderNumber = @SalesOrderNumber;
return;
end
go
-- Clear procedure cache for DB
alter database scoped configuration clear procedure_cache;
go
-- Run the query with mTVF
set statistics xml on;
select
c = count_big(*)
from
dbo.FactResellerSalesXL_CCI c
cross apply dbo.uf(5, c.SalesOrderNumber) t
where
c.DueDate > '20150101'
;
set statistics xml off;
go
You may see, the plan shape is different now.
您可能会看到,现在的计划形状有所不同。
We don’t have a Sequence operator any more, the part of the query can’t be executed independently and there is no interleaved execution and no interleaved execution extended events. In the current version of SQL Server 2017, this query pattern is not supported.
我们不再有Sequence运算符,查询的一部分不能独立执行,也没有交错执行和交错执行扩展事件。 在当前版本SQL Server 2017中,不支持此查询模式。
参数嗅探 (Parameter Sniffing)
To look at how the interleaved execution works with parameters we make a simple procedure and put our query inside it.
为了查看交错执行如何与参数一起使用,我们制作了一个简单的过程,并将查询放入其中。
-- Procedure with the query with mTVF and enabled interleaved execution
create or alter proc dbo.p (@n int)
as
select
c = count_big(*)
from
dbo.FactResellerSalesXL_CCI c
join dbo.uf(@n) t on t.SalesOrderNumber = c.SalesOrderNumber and t.SalesOrderLineNumber = c.SalesOrderLineNumber
option(use hint('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')) -- disable adaptive join
;
go
Now let’s clear procedure cache, run this procedure with different parameters and look at the query plans.
现在,让我们清除过程高速缓存,使用不同的参数运行该过程并查看查询计划。
set statistics xml on;
exec dbo.p 1;
exec dbo.p 10000;
exec sp_recompile 'dbo.p';
exec dbo.p 10000;
set statistics xml off;
go
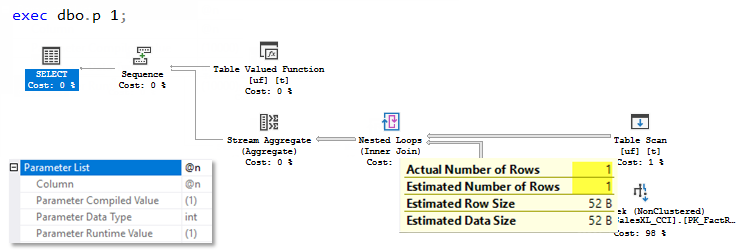
During the first execution, there was no plan in the cache so the procedure was compiled. The parameter value 1 was sniffed and then used during the interleaved execution. You may see that Estimated Number of Rows equals Actual Number of rows and equals 1 row.
在第一次执行期间,缓存中没有计划,因此已编译了该过程。 嗅探参数值1,然后在交错执行期间使用。 您可能会看到估计的行数等于实际行数并等于1行。
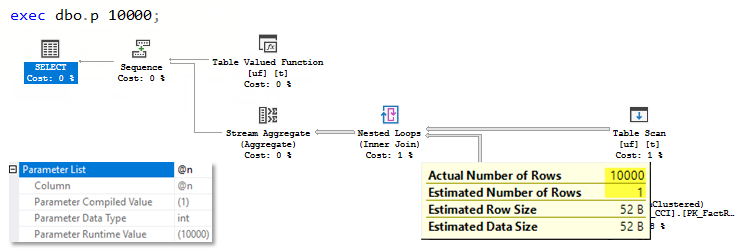
During the second execution, the plan is already cached and it is simply reused without any recompilation and interleaved execution. You may observe the Actual Number of Rows is 10 000, while the Estimated Number of Rows is still 1 row and the plan has no partial Hash aggregate.
在第二次执行期间,该计划已被缓存,可以简单地重用,而无需任何重新编译和交错执行。 您可能会看到“实际行数”为10000,而“估计行数”仍为1行,并且该计划没有部分哈希集合。
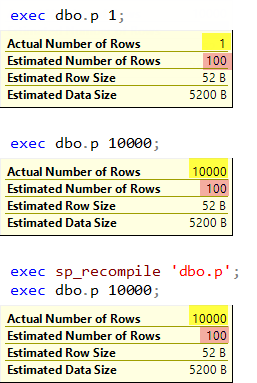
When we marked the procedure for a recompilation and executed it, the recompilation and the interleaved execution occurred, the new value 10 000 was sniffed and used to optimize the query. You may see the actual and the estimated number of rows equals 10 000 and we see a Hash aggregate in the plan.
当我们标记了要重新编译的过程并执行了该过程时,便发生了重新编译和交错执行,新值10000被嗅出并用于优化查询。 您可能会看到实际的行数和估计的行数等于10000,并且我们在计划中看到了哈希汇总。

This example shows that interleaved execution uses sniffed parameter value during the compilation. That means that a bad parameter sniffing problem applies to the interleaved execution as well, as to the other cases also.
此示例说明,交错执行在编译期间使用嗅探到的参数值。 这就意味着一个糟糕的参数嗅探问题同样适用于交错执行,也适用于其他情况。
禁用参数嗅探 (Disabling Parameter Sniffing)
Now let’s try to disable parameter sniffing, we have several ways to do this:
现在让我们尝试禁用参数嗅探,我们有几种方法可以做到这一点:
- Query hint USE HINT (‘DISABLE_PARAMETER_SNIFFING’) 查询提示USE HINT('DISABLE_PARAMETER_SNIFFING')
- Query hint OPTIMIZE FOR UNKNOWN or value 查询提示OPTIMIZE FOR UNKNOWN或值
- Trace Flag 4136 跟踪标志4136
- Disabling at the DB level with a SCOPED CONFIGURATION options 使用SCOPED CONFIGURATION选项在数据库级别禁用
Let’s modify our procedure and add a USE HINT to the query.
让我们修改过程,并将USE HINT添加到查询中。
-- Procedure with the query with mTVF, enabled interleaved execution and disabled parameter sniffing
create or alter proc dbo.p (@n int)
as
select
c = count_big(*)
from
dbo.FactResellerSalesXL_CCI c
join dbo.uf(@n) t on t.SalesOrderNumber = c.SalesOrderNumber and t.SalesOrderLineNumber = c.SalesOrderLineNumber
option(use hint ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS','disable_parameter_sniffing'))
;
go
If we rerun procedures from the previous step, we’ll see that the estimate is 100 rows guess in all three cases (I’ll post only the estimates of the mTVF table scan from the plans to save space).
如果我们从上一步重新运行过程,我们将看到在所有三种情况下估计都是100行猜测(我将仅从计划中发布mTVF表扫描的估计,以节省空间)。
Also, if you enable an extended events trace you will not see any interleaved execution events.
另外,如果启用扩展事件跟踪,则不会看到任何交错的执行事件。
The same behavior is for all the other options, all of them disable interleaved execution, even if you write, for example, option (optimize for (@n = 5000)) – the estimated number of rows would be 100 and there will be no interleaved execution.
所有其他选项的行为相同,即使您编写了选项(针对(@n = 5000)优化),所有其他选项都禁用了交错执行–估计的行数将为100,而没有行交错执行。
Interesting to note, that disabling interleaved execution with all these methods also works if you take a query out of a stored procedure.
有趣的是,如果您从存储过程中删除查询,则禁用所有这些方法的交错执行也是可行的。
选项重新编译 (Option Recompile)
As a final step, we will find out, how the interleaved execution works with a RECOMPILE hint. Again, we will modify our stored procedure and run it with the different parameter values.
作为最后一步,我们将发现交错执行如何与RECOMPILE提示一起工作。 同样,我们将修改存储过程并使用不同的参数值运行它。
create or alter proc dbo.p (@n int)
as
select
c = count_big(*)
from
dbo.FactResellerSalesXL_CCI c
join dbo.uf(@n) t on t.SalesOrderNumber = c.SalesOrderNumber and t.SalesOrderLineNumber = c.SalesOrderLineNumber
option(recompile, use hint ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'))
;
go
-- Clear procedure cache for DB
alter database scoped configuration clear procedure_cache;
go
-- Run procedure with different parameters
set statistics xml on;
exec dbo.p 1;
exec dbo.p 1000;
exec dbo.p 10000;
set statistics xml off;
go
The estimates of the mTVF table scan from the plans are:
根据计划,mTVF表扫描的估计值为:

As you can see, the estimates equal actual and you may also observe interleaved extended events every time you run a procedure, so the option RECOMPILE works nicely with the interleaved execution.
如您所见,估计值等于实际值,并且您每次运行过程时也可能会观察到交错的扩展事件,因此选项RECOMPILE与交错执行非常有效。
As my last experiment with option RECOMPILE I tried to pass a 0 value as a parameter. You may probably know, that if you run a query, for example: “declare @n int = 0; select top (@n) * from dbo. FactResellerSalesXL_CCI option (recompile);” – the value 0 will be embedded into the query and optimized as a top (0), and top (0) will be simplified out by the optimizer at the simplification stage of the query compilation. As a result, you will get a simple “Constant Scan” plan, and that’s it. Unfortunately, this doesn’t work in this case (even if you add an option recompile inside a function also).
作为我最后一次使用RECOMPILE选项的实验,我尝试将0值作为参数传递。 您可能知道,如果您运行查询,例如:“ declare @n int = 0; 从dbo选择顶部(@n)*。 FactResellerSalesXL_CCI选项(重新编译);” –值0将被嵌入查询中,并被优化为top(0),并且在查询编译的简化阶段,优化器将top(0)简化。 结果,您将获得一个简单的“恒定扫描”计划,仅此而已。 不幸的是,这在这种情况下不起作用(即使您还在函数内部添加了选项重新编译)。
其他问题 (Other Questions)
A few other questions that have come to my mind while experimenting with this new feature. I tested them, but won’t post the scripts, because I don’t want to make this long post even longer.
在尝试此新功能时,我想到了其他一些问题。 我对其进行了测试,但不会发布脚本,因为我不想将这篇较长的帖子加长。
Should be a function defined with schema_binding?
No, not necessary.
应该是使用schema_binding定义的函数吗?
不,不是必需的。
Are there any other operators available for the interleave execution?
No, the first implementation of the interleaved execution includes only mTVF.
交错执行还有其他运算符吗?
不,交错执行的第一个实现仅包括mTVF。
Will it work with a table variable?
No, however, for better cardinality estimation of a table variable you may use a regular approach, like option RECOMPILE or trace flag 2453.
它可以与表变量一起使用吗?
不,但是,为了更好地估计表变量的基数,您可以使用常规方法,例如选项RECOMPILE或跟踪标志2453。
Will it work in a Row Mode?
Yes, it works in a Row, Batch or mixed mode.
它可以在行模式下工作吗?
是的,它可以在行,批处理或混合模式下工作。
结论 (Conclusion)
The Query Processor of SQL Server is getting smarter from version to version; in this post, we have tried a new feature – interleaved execution, which is a part of the adaptive query processing features family. I believe this feature will increase performance of existing solutions with mTVFs and make mTVF functions more usable in terms of performance in general. Will look at how this approach will evolve in future, probably for some other operators.
SQL Server的查询处理器在各个版本之间越来越智能; 在本文中,我们尝试了一项新功能–交错执行,这是自适应查询处理功能家族的一部分。 我相信此功能将提高mTVF的现有解决方案的性能,并使mTVF的功能在整体性能上更加可用。 将研究这种方法在将来可能会如何演变,可能对其他一些运营商而言。
I would like to thank Joe Sack from MSFT (t) for reviewing this post and providing invaluable help.
我要感谢MSFT( t )的Joe Sack审阅了这篇文章并提供了宝贵的帮助。
Thank you for reading!
感谢您的阅读!
目录 (Table of contents)
翻译自: https://www.sqlshack.com/sql-server-2017-interleaved-execution-for-mtvf/

















 333
333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









