





德鲁伊 oltp oltp
With the introduction of Microsoft’s new In-Memory OLTP engine (code name Hekaton) the familiar B-Tree indexes were not always the optimal solution. The target of the Hekaton project was to achieve 100 (hundred) times faster OLTP processing, and to help this a new index was introduced – the hash index.
随着Microsoft新的内存中OLTP引擎(代号Hekaton)的引入,熟悉的B-Tree索引并不总是最佳的解决方案。 Hekaton项目的目标是使OLTP处理速度提高100倍(一百倍),并为此目的引入了新的索引- 哈希索引。
The hash index is ideal solution to optimize queries scanning the indexed columns in result of a WHERE clause on exact equality on the index key column(s).
哈希索引是优化查询的最佳解决方案,该查询根据索引键列上完全相等的WHERE子句的结果扫描索引列。
SELECT LastName FROM EmpInformation
WHERE LastName = Bell
We will discuss the hash indexes, their internal structure (1), how they work with the standard data modification statements (2), and the important properties taken under consideration upon their creation (3).
我们将讨论散列索引,它们的内部结构(1),它们如何与标准数据修改语句一起工作(2)以及在创建它们时要考虑的重要属性(3)。
Simply explained, in the In-Memory OLTP Engine, hash indexes are collection of buckets organized in an array. Each bucket contains a pointer to a data row.
简而言之,在内存OLTP引擎中,哈希索引是按阵列组织的存储桶的集合。 每个存储桶都包含一个指向数据行的指针。
To start, let us review how a row looks like when stored in an in-memory table. It consists of system data holding the row timestamp and the index pointer and the second part with the user data.
首先,让我们回顾一下存储在内存表中的行的外观。 它由保存行时间戳和索引指针的系统数据以及带有用户数据的第二部分组成。
The timestamp contains a BeginTs timestamp showing us the “time” when a row was inserted (created) and an EndTs stamp showing the “time” when a row is no longer valid (deleted or updated). BeginTs and EndTs correspond to the Global Transaction Timestamp of the transaction that acted lastly on that row. In our case, the BeginTs is 10 and the EndTs is infinity – meaning that the row was inserted at time “10” and is valid until infinity or of course DML operations occurs.
时间戳包含一个BeginTs时间戳,向我们显示插入(创建)行时的“时间”,以及一个EndTs戳,显示行不再有效(删除或更新)时的“时间”。 BeginTs和EndTs对应于最后执行该行的事务的全局事务时间戳。 在我们的示例中,BeginTs为10,EndTs为无穷大–意味着该行在时间“ 10”插入,并且一直有效到无穷大或发生DML操作为止。

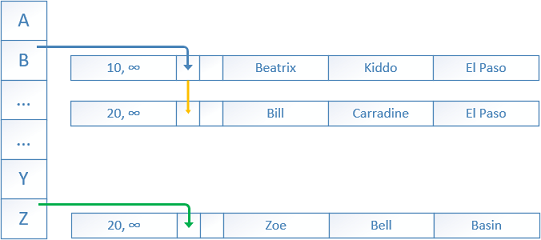
1. When a new row is inserted into the table a deterministic hash function maps the index key into the corresponding bucket within the hash index. In our case the hash index is on the column ‘FirstName’ and the value ‘Beatrix’ was put into hash bucket B (bucket is named ‘B’ this is for illustration purposes), a pointer is created linking the bucket and the row. The hash function is always deterministic which means that it provides the same hash result every time when given the same input – duplicate values will have the same hash value. The same hash function is used for each and every hash index. The result distribution is relatively random and on repeated calls, the outputs of the hash function tend to form a Poisson* or bell curve distribution, not a flat linear distribution. The hash function is similar to the HASHBYTES/CHECKSUM** T-SQL system functions.
1.当在表中插入新行时,确定性哈希函数将索引键映射到哈希索引内的相应存储桶中。 在我们的例子中,哈希索引位于“ FirstName”列上 ,并将值“ Beatrix”放入哈希存储桶B中(存储桶被命名为“ B”,这是出于说明目的),创建了一个链接存储桶和行的指针。 哈希函数始终是确定性的,这意味着每次给定相同的输入时,它都会提供相同的哈希结果-重复值将具有相同的哈希值。 每个哈希索引都使用相同的哈希函数。 结果分布是相对随机的,并且在重复调用时,哈希函数的输出倾向于形成泊松*或钟形曲线分布,而不是平坦的线性分布。 哈希函数类似于HASHBYTES / CHECKSUM ** T-SQL系统函数。
2. A little later two more rows are inserted by another transaction at the “time” BeginTs 20.
2.再过一会儿,在“时间” BeginTs 20处,另一笔交易又插入了两行。
The first row has value ‘Bill’ that is placed again in the bucket ‘B’ by the hashing function.
第一行的值“ Bill”通过哈希函数再次放置在存储桶“ B”中。
A new pointer is created to that row from the previous one.
一个新的指针从上一个指针指向该行。
The second inserted row has a value ‘Zoe’ for ‘FirstName’ which is placed in the bucket ‘Z’ by the hashing function.
插入的第二行的'FirstName'值为'Zoe',该值由哈希函数放置在存储区'Z'中。
A new pointer is created to that row originating from the bucket.
将创建一个新的指针,指向该存储桶中的该行。
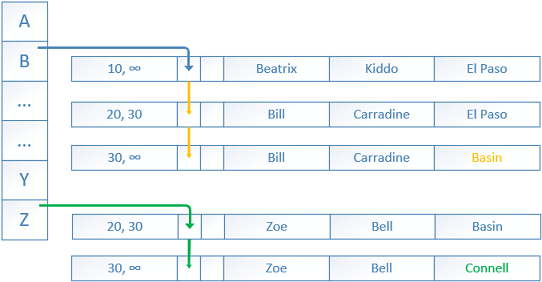
Next, an UPDATE transaction with BeginTs “time” of 30 needs to update two rows – Bill is moving to the city Basin, Zoe is moving to the city Connell.
接下来,BeginTs“时间”为30的UPDATE事务需要更新两行-Bill 正在搬到城市盆地 , Zoe正在搬到城市Connell 。
The current rows are updated only with an EndTs value of 30 showing that the rows are not the most recent anymore.
当前行仅更新为EndTs值为30,表明该行不再是最新的。
New rows are added with BeginTs of 30 and EndTs of infinity. New pointers are created from the previous rows to the new ones.
添加的新行的BeginT为30,EndT为无穷大。 从先前的行到新的行创建新的指针。
The old rows will be eventually unlinked and then deleted by the garbage collector.
最终,旧行将最终取消链接,然后由垃圾收集器删除。
The DELETE statement acts in the same manner, of course with the difference that it updates the EndTs without adding a new row.
DELETE语句的行为方式相同,当然不同之处在于它在不添加新行的情况下更新EndT。
If a new SELECT session starts with a Global Transaction Timestamp higher than 30 the old rows (20->30) will not be visible to it.
如果新的SELECT会话以高于30的全局事务时间戳开始,则旧行(20-> 30)将不可见。
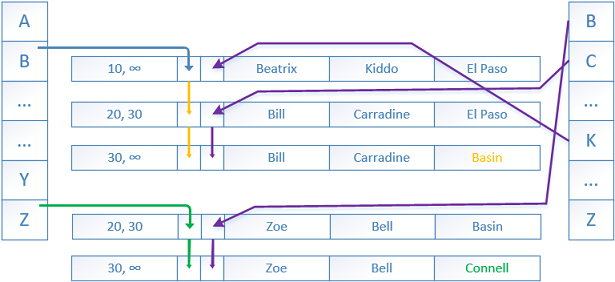
In-memory OLTP tables support more than one hash index, each of them with separate array of buckets and pointers.
内存OLTP表支持多个哈希索引,每个哈希索引都具有独立的存储桶和指针数组。
Here, the secondary index is created on the second column ‘LastName’. The rows are linked with pointers in a different order, but still following the versioning.
在这里,二级索引在第二列“ LastName”上创建。 这些行以不同的顺序与指针链接,但仍遵循版本控制。
Every memory optimized table should have at least one and up to eight indexes. A unique primary key should be defined as well, the primary key is counted as one of the eight-index limit and is not updatable.
每个内存优化表应至少具有一个索引,最多八个索引。 还应该定义一个唯一的主键,该主键被视为八索引限制之一,并且不可更新。
(3) Hash indexes can be created as a part of the in-memory OLTP table creation or added later using the ALTER statement.
(3)哈希索引可以在内存中OLTP表创建中创建,也可以稍后使用ALTER语句添加。
The most important parameter is the BUCKET_COUNT, for SQL Server 2016. It can subsequently be changed using the ALTER TABLE EmpInformation … ALTER INDEX REBUILD syntax.
对于SQL Server 2016,最重要的参数是BUCKET_COUNT。随后可以使用ALTER TABLE EmpInformation…ALTER INDEX REBUILD语法对其进行更改。
CREATE TABLE EmpInformation
(
EmpID int NOT NULL IDENTITY(1,1)
PRIMARY KEY NONCLUSTERED,
FirstName nvarchar(25) NOT NULL,
LastName nvarchar(25) NOT NULL,
City nvarchar(25) NULL,
INDEX IX_Hash_FirstName
HASH (FirstName) WITH (BUCKET_COUNT = 100000)
)
WITH (
MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_AND_DATA);
GO
ALTER TABLE EmpInformation
ADD INDEX IX_Hash_LastName
HASH (LastName) WITH (BUCKET_COUNT = 80000);
-- Setting BUCKET_COUNT 80000 will result in 131072 buckets
(rounded by the SQL Server to next power of two)
The number of buckets and the amount of data within the index directly affects performance. The buckets are an 8 byte object which stores a link pointer to the key entries of the rows. Each row that is part of an index is linked by one parent and is pointing to a single child, this is known as a chain.
存储桶的数量和索引中的数据量直接影响性能。 存储桶是一个8字节的对象,它存储指向行的键条目的链接指针。 属于索引的每一行都由一个父级链接,并指向一个孩子,这称为链。
If you are working with a high number of data rows and low number of buckets, the chains will be longer and scan operations will require numerous steps resulting in performance degradation. Note that scan operations are also required to locate the row in order to update the EndTs when UPDATE or DELETE statement is performed. And of course high number of buckets and low number of data rows affects negatively full table scans and of course reserves and waste memory.
如果您要处理大量的数据行和少量的存储桶,则链会更长,并且扫描操作将需要许多步骤,从而导致性能下降。 请注意,执行UPDATE或DELETE语句时,还需要执行扫描操作来定位行,以便更新EndT。 当然,大量的存储桶和少量的数据行也会对全表扫描产生负面影响,当然也会影响保留和浪费内存。
There is no formula or golden ratio which should be followed when choosing the bucket count. It is recommended by Microsoft**** to have a BUCKET_COUNT between one and two times the number of distinct values in the index. Example is if you are having a table dbo.Orders with 100 000 distinct order IDs the bucket count should be between 100 000 and 200 000. Here it is most important to take under consideration the future growth due to the nature of the table.
选择存储桶数时,没有公式或黄金比例。 Microsoft ****建议将BUCKET_COUNT设置为索引中不同值的数量的一到两倍。 例如,如果您有一个表dbo。具有10万个不同订单ID的订单的存储桶数应在10万到20万之间。由于表的性质,考虑未来的增长是最重要的。
Remember that hash indexes are not optimal when working with a column containing high number of duplicates. The duplicate values generate the same hash which results in a very long chains. Generally, if the ratio of all values versus the distinct ones is higher than 10 you should consider a range index instead.
An example is if you have 100 000 total employees in a table and the distinct job titles shared between them is 300, this leads to a ratio of ~333 (100 000 / 300), meaning you should consider range index instead. When considering the cardinality of the data, ratio of 10 and lower is considered optimal.
请记住,当使用包含大量重复项的列时,哈希索引不是最佳的 。 重复的值生成相同的哈希,这导致链很长。 通常,如果所有值与不同值之比大于10,则应考虑使用范围索引。
例如,如果您在一个表中有10万名员工,而他们之间共享的不同职称是300,这导致〜333(100 000/300)的比率,这意味着您应该考虑使用范围索引。 考虑数据的基数时,比率10和更低被认为是最佳的。
翻译自: https://www.sqlshack.com/deep-dive-hash-indexes-memory-oltp-tables/
德鲁伊 oltp oltp















 574
574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









