





In the previous articles of this series (see the full article TOC at bottom), we discussed the internal structure of both SQL Server tables and indexes, the main guidelines that you can follow to design a proper index, the list of operations that can be performed on the SQL Server indexes, and finally how to design effective Clustered and Non-clustered indexes that the SQL Server Query Optimizer will always take benefits from, in speeding up the data retrieval process, which is the main goal of creating an index. In this article, we will go through the different types of SQL Server indexes, above and beyond Clustered and Non-clustered indexes classification, and when to use them.
在本系列的前几篇文章中(请参见底部的完整文章TOC),我们讨论了SQL Server表和索引的内部结构,设计适当索引所遵循的主要准则,可以进行操作的操作列表。在SQL Server索引上执行的操作,最后是如何设计有效的群集索引和非群集索引,SQL Server Query Optimizer将始终从中受益,以加快数据检索过程,这是创建索引的主要目标。 在本文中,我们将介绍除群集索引和非群集索引分类之外的各种不同类型SQL Server索引,以及何时使用它们。
唯一索引 (Unique index)
A Unique index is used to maintain the data integrity of the columns on which it is created, by ensuring that there are no duplicate values in the index key, and the table rows, on which that index is created. This ensures data will be unique based on the index key, depending on the characteristics of the data that is stored in the index key column or list of columns. If the Unique index key consists of one column, SQL Server will guarantee that each value in the index key is unique. On the other hand, if the Unique index key consists of multiple columns, each combination of values in that index key should be unique. You can define both the Clustered and Non-clustered indexes to be unique, as long as the data in these index keys are unique.
通过确保唯一索引和在其上创建索引的表行中没有重复的值,唯一索引用于维护在其上创建列的数据完整性。 这样可确保根据索引键(取决于存储在索引键列或列列表中的数据的特性),数据将是唯一的。 如果唯一索引键由一列组成,则SQL Server将保证索引键中的每个值都是唯一的。 另一方面,如果唯一索引键由多个列组成,则该索引键中值的每个组合都应该是唯一的。 您可以将聚集索引和非聚集索引定义为唯一,只要这些索引键中的数据是唯一的即可。
A Unique index will be created automatically when you define a PRIMARY KEY or UNIQUE KEY constraints on the specified columns. In all cases, creating a Unique index on the unique data, instead of creating a non-unique index on the same data, is highly recommended, as it will help the SQL Server Query Optimizer to generate the most efficient execution plan based on the additional useful information provided by that index.
当您在指定的列上定义PRIMARY KEY或UNIQUE KEY约束时,将自动创建唯一索引。 在所有情况下,强烈建议在唯一数据上创建唯一索引,而不是在同一数据上创建非唯一索引,因为这将有助于SQL Server Query Optimizer根据附加数据生成最有效的执行计划。该索引提供的有用信息。
Assume that we need to create the below table, using the CREATE TABLE T-SQL statement below, without specifying any CREATE INDEX statement, as shown below:
假定我们需要使用下面的CREATE TABLE T-SQL语句创建下表,而无需指定任何CREATE INDEX语句,如下所示:
CREATE TABLE DiffIndexTypesDemo
( ID INT IDENTITY (1,1) PRIMARY KEY,
Name Varchar(50) CONSTRAINT UQ_Name UNIQUE,
ADDRESS NVARCHAR(MAX)
)
You will see that a Unique Clustered index will be created automatically on the ID column of that table, to enforce the PRIMARY KEY constraint, and a Unique Non-clustered index will be created automatically on the Name column to enforce the UNIQUE constraint, as shown below:
您将看到将在该表的ID列上自动创建一个唯一聚集索引以强制执行PRIMARY KEY约束,并在Name列上自动创建一个唯一非聚集索引以强制执行UNIQUE约束,如图所示下面:
Take into consideration that the index that is created automatically to enforce any constraint cannot be dropped using a DROP INDEX T-SQL statement. If we try to drop the Unique index created previously to enforce the UNIQUE constraint using the DROP INDEX T-SQL statement below:
请注意,不能使用DROP INDEX T-SQL语句删除为强制执行任何约束而自动创建的索引。 如果我们尝试使用以下DROP INDEX T-SQL语句删除先前创建的唯一索引以强制执行UNIQUE约束:
DROP INDEX UQ_Name ON DiffIndexTypesDemo
the statement will fail, showing that we cannot explicitly drop any index that is created automatically to enforce a constraint, as shown in the error message below:
该语句将失败,表明我们无法显式删除为强制执行约束而自动创建的任何索引,如以下错误消息所示:

To drop that index, we should drop the constraint that created the index, using the ALTER TABLE…DROP CONSTRAINT T-SQL statement below:
要删除该索引,我们应该使用下面的ALTER TABLE…DROP CONSTRAINT T-SQL语句删除创建索引的约束:
ALTER TABLE DiffIndexTypesDemo DROP CONSTRAINT UQ_Name
The Unique index can be also created manually, away from the constraint, by specifying the UNIQUE keyword in the Clustered or Non-Clustered index creation statement, as in the CREATE INDEX T-SQL statement below:
还可以通过在群集或非群集索引创建语句中指定UNIQUE关键字来手动创建不受约束的唯一索引,如下面的CREATE INDEX T-SQL语句所示:
CREATE UNIQUE NONCLUSTERED INDEX IX_DiffIndexTypesDemo_Name ON DiffIndexTypesDemo (NAME)
The previous CREATE INDEX statement can be used to create a Unique Non-Clustered index on the Name column, as shown below:
前面的CREATE INDEX语句可用于在“名称”列上创建唯一的非聚集索引,如下所示:
A Unique index is used to enforce the uniqueness of the index key values. For example, the previous index is used to make sure that no duplicate value for the Name column is available in that table. If we try to execute the below INSERT INTO statement that inserts two new records with the same Name values into that table:
唯一索引用于强制索引键值的唯一性。 例如,以前的索引用于确保该表中“名称”列没有重复值。 如果我们尝试执行下面的INSERT INTO语句,该语句将两个具有相同Name值的新记录插入到该表中:
INSERT INTO DiffIndexTypesDemo VALUES ('John', 'Amman'),
('John', 'Zarqa')
The statement will fail, showing that it is not allowed to insert duplicate values for the Name column, that is enforced by the created Unique index, providing the prevented duplicate values, as shown in the error message below:
该语句将失败,表明不允许为创建的唯一索引强制的“名称”列插入重复值,并提供被阻止的重复值,如以下错误消息所示:

If we try to drop the Unique index, using the DROP INDEX T-SQL statement below:
如果我们尝试删除唯一索引,请使用下面的DROP INDEX T-SQL语句:
DROP INDEX IX_DiffIndexTypesDemo_Name ON DiffIndexTypesDemo
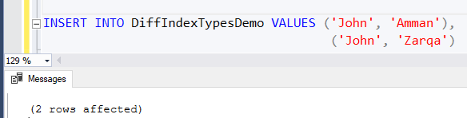
then execute the same INSERT INTO statement, you will see that the duplicate Name values will be inserted successfully, having no constraint or index that enforce the uniqueness of that column values, as shown clearly below:
然后执行相同的INSERT INTO语句,您将看到重复的Name值将被成功插入,没有任何约束或索引来强制该列值的唯一性,如下所示:
Now, if we try to create the Unique index again on that table, the CREATE INDEX statement will fail, as the table already have duplicate values in the Name column as shown below:
现在,如果我们尝试再次在该表上创建唯一索引,则CREATE INDEX语句将失败,因为该表在“名称”列中已经具有重复值,如下所示:

Neither will using the IGNORE_DUP_KEY index creation option will not work with the UNIQUE index. If we try to enable that option, while creating the Unique index, in order to ignore the existing duplicate values, the statement will fail again, showing that we cannot create a Unique index with duplicate index key values available in the table, as shown in the error message below:
使用IGNORE_DUP_KEY索引创建选项都不会与UNIQUE索引一起使用。 如果我们尝试在创建唯一索引时启用该选项,则为了忽略现有重复值,该语句将再次失败,这表明我们无法使用表中可用的重复索引键值创建唯一索引,如下所示:下面的错误信息:

To be able to create the Unique index on the Name column, we should delete or update the duplicate values. In our case, we will update the second duplicate name using the UPDATE statement below:
为了能够在“名称”列上创建唯一索引,我们应该删除或更新重复的值。 在我们的情况下,我们将使用下面的UPDATE语句更新第二个重复名称:
SELECT * FROM DiffIndexTypesDemo
UPDATE DiffIndexTypesDemo SET Name='Jack' where ID=4
SELECT * FROM DiffIndexTypesDemo
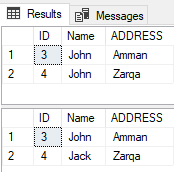
With the table rows before and after the UPDATE operation is shown below:
下表显示了UPDATE操作前后的表行:
Trying to create the Unique index after resolving the duplicate issue, the Unique index will be created successfully as shown below:
解决重复问题后尝试创建唯一索引,将成功创建唯一索引,如下所示:
We can include another column in the Unique index key to enforce the uniqueness of the combination of the two columns, rather than enforcing it on the Name column only. The below CREATE INDEX will be used to create a unique index that enforces the uniqueness of the ID and Name columns combination:
我们可以在“唯一”索引键中包含另一列,以强制两列组合的唯一性,而不是仅在“名称”列上强制它。 下面的CREATE INDEX将用于创建唯一索引,以强制执行ID和Name列组合的唯一性:
CREATE UNIQUE NONCLUSTERED INDEX IX_DiffIndexTypesDemo_Name ON DiffIndexTypesDemo (ID,NAME)
If we try to run the below INSERT INTO statement, that inserts two records with the same name, the records will be inserted successfully, as the ID column is IDENTITY column that will assign different values for each inserted row from the below:
如果我们尝试运行下面的INSERT INTO语句,该语句将插入两个具有相同名称的记录,则记录将被成功插入,因为ID列为IDENTITY列,将为下面的每个插入行分配不同的值:
筛选索引 (Filtered index)
A Filtered index is an optimized Non-Clustered index, introduced in SQL Server 2008, that uses a filter predicate to improve the performance of queries that retrieve a well-defined subset of rows from the table, by indexing the only portion of the table rows. The smaller size of the Filtered index, that consumes a small amount of the disk space compared with the full-table index size, and the more accurate filtered statistics, that cover the filtered index rows with only minimal maintenance cost, help in improving the performance of the queries by generating a more optimal execution plan.
筛选索引是SQL Server 2008中引入的一种优化的非簇索引,它使用筛选谓词通过对表行的仅一部分建立索引来提高从表中检索行的明确定义的子集的查询的性能。 。 与全表索引大小相比,筛选索引的大小较小,占用的磁盘空间较少,而筛选统计信息的准确性更高,可以以最小的维护成本覆盖筛选的索引行,从而有助于提高性能通过生成更优化的执行计划来进行查询。
An example of well-defined subsets of data, that can benefit from Filtered index performance gains is the Sparse columns with a large number of NULL values.
可以从筛选索引性能提高中受益的数据定义明确的子集的示例是具有大量NULL值的稀疏列。
For more information about the Sparse columns, check Optimize NULL values storage consumption using SQL Server Sparse Columns.
有关稀疏列的更多信息,请选中“ 使用SQL Server稀疏列优化NULL值存储消耗”。
If your queries are retrieving data from non-NULL rows, you can improve the query performance by creating a Filtered index that covers the rows with non-NULL values. Other examples of the well-defined subsets of data, that can benefit from a Filtered index are the columns that contain a distinct range of values or heterogeneous categorized data. To understand it practically, let us drop the previously created testing table and create a new one using the T-SQL script below:
如果查询是从非NULL行中检索数据,则可以通过创建一个过滤索引来覆盖非NULL值行来提高查询性能。 可以从筛选索引中受益的数据定义明确的子集的其他示例是包含不同范围的值或异类分类数据的列。 为了实际理解它,让我们删除之前创建的测试表,并使用下面的T-SQL脚本创建一个新的测试表:
DROP TABLE DiffIndexTypesDemo
GO
CREATE TABLE DiffIndexTypesDemo
( ID INT IDENTITY (1,1) PRIMARY KEY,
Name Varchar(50) ,
ADDRESS NVARCHAR(MAX)
)
GO
After creating the table, we will fill it with 10,100 records; providing only 100 values of the Name column value and 10K rows with NULL values for that column, using the INSERT INTO T-SQL statements below:
创建表格后,我们将为其填充10,100条记录; 使用下面的INSERT INTO T-SQL语句,仅提供100个Name列值的值以及该列的NULL值的10K行:
INSERT INTO DiffIndexTypesDemo VALUES ('John', 'Ramtha')
GO 100
INSERT INTO DiffIndexTypesDemo VALUES (NULL, 'Zarqa')
GO 10000
The Name column on the previous table can be considered a Sparse column, with about 99% of the data being NULL values. Before planning to create the index, we should understand the queries that are retrieving data from that table. Having all the queries search for the rows with non-NULL values for the Name column, then it will be beneficial to create a Filtered index on the Name column, that will be smaller and cost less to maintain as it contains less than 1% of the column’s values, compared with a full-table index that contains all values for the Name column. The following CREATE INDEX T-SQL command is used to create a Filtered index on the Name column, by providing a filtered predicate, as shown below:
上表中的“名称”列可以视为稀疏列,其中约99%的数据为NULL值。 在计划创建索引之前,我们应该了解正在从该表中检索数据的查询。 让所有查询针对“名称”列搜索具有非NULL值的行,然后在“名称”列上创建过滤索引将是有益的,因为它包含的索引少于1%,因此索引会更小且维护成本更低与包含“名称”列的所有值的全表索引相比,该列的值。 以下CREATE INDEX T-SQL命令用于通过提供过滤谓词在“名称”列上创建过滤索引,如下所示:
CREATE INDEX IX_DiffIndexTypesDemo_Name ON DiffIndexTypesDemo (Name) WHERE NAME IS NOT NULL
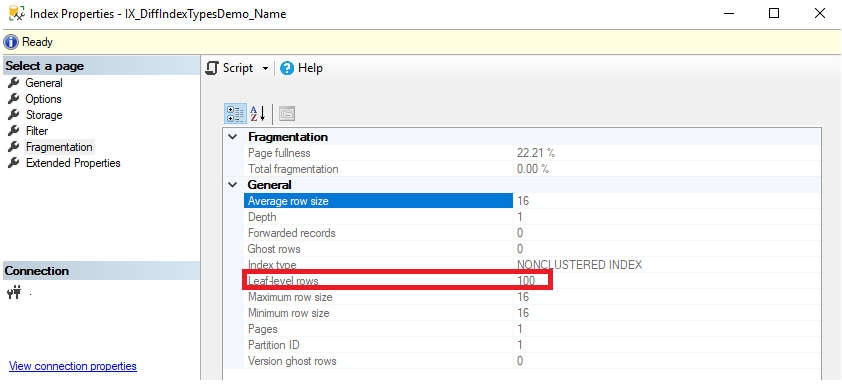
You can check the number of records included in that index from the Fragmentation tab of the index properties window shown below:
您可以从如下所示的索引属性窗口的“碎片”选项卡中检查该索引中包含的记录数:
The following query, that retrieves non-NULL values of the Name column, will obviously benefit from the Filtered index:
下面的查询检索Name列的非NULL值,显然将从过滤索引中受益:
SET STATISTICS TIME ON
SET STATISTICS IO ON
SELECT Name FROM [dbo].[DiffIndexTypesDemo] WHERE NAME ='John'
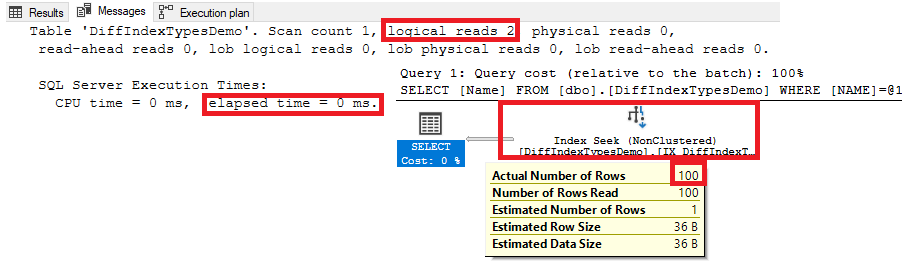
Which is clear from the generated execution plan, IO and Time statistics below. You will see that the SQL Server will retrieve the requested data in no time by seeking the Filtered index, as shown below:
从下面生成的执行计划,IO和时间统计信息中可以清楚地看出来。 您将看到SQL Server将通过查找Filtered索引立即检索请求的数据,如下所示:
It is recommended to include the smallest number of columns in the Filtered index that is absolutely required to cover the query. The column that is used in the Filtered index predicate can be added as a key or non-key column in the Filtered index if the query uses the same condition used in the Filtered index predicate and the query does not return that column with the query result. Otherwise, the column should be added as a key column in the Filtered index.
建议在涵盖查询的绝对索引中包含最少数量的列。 如果查询使用过滤索引谓词中使用的相同条件,并且查询未返回该列和查询结果,则可以将过滤索引谓词中使用的列添加为过滤索引中的键或非键列。 。 否则,应将该列添加为“已过滤”索引中的键列。
Take into consideration that the WHERE clause of the Filtered index will accept simple comparison operators only. If you need a filter expression that references multiple tables or has a complex predicate, you should create a view.
请注意,Filtered索引的WHERE子句将仅接受简单的比较运算符。 如果需要引用多个表或具有复杂谓词的过滤器表达式,则应创建一个视图。
For more information about the indexes views, check SQL Server indexed views.
有关索引视图的更多信息,请检查SQL Server索引视图。
On the other hand, If the Filtered index includes most of the rows in the table, it is recommended to use a full-table index instead of a Filtered index, as the Filtered index maintenance will be more expensive than the full-table index in this situation. The Filtered index creation depends mainly on your understanding for the data and the submitted queries and will not be found in the SQL Server missing indexes suggestions, except when using the Database Engine Tuning Advisor tool that can help in suggesting IS NOT NULL Filtered index.
另一方面,如果筛选索引包含表中的大多数行,则建议使用全表索引而不是筛选索引,因为筛选索引维护会比表中的全表索引昂贵这个情况。 筛选索引的创建主要取决于您对数据和提交的查询的理解,在SQL Server缺少索引的建议中将不会找到筛选索引,除非使用的数据库引擎优化顾问工具可以帮助建议IS NOT NULL筛选索引。
空间指数 (Spatial index)
Geometry and Geography spatial data types were introduced the first time in SQL Server 2008. The geometry data type is used to store geometric planner data such as point, lines, and polygons, where the geography data type is used to represent geographic objects on an area on the Earth’s surface, such as GPS latitude and longitude coordinates.
SQL Server 2008中首次引入了几何和地理空间数据类型。 几何数据类型用于存储几何规划器数据,例如点,线和面,其中地理数据类型用于表示区域中的地理对象在地球表面,例如GPS纬度和经度坐标。
A Spatial index is a special type of index, created on the columns that store spatial data, to improve the performance of the operations performed on the spatial columns, by reducing the number of objects on which relatively costly spatial operations need to be applied. Take into consideration that creating Spatial indexes require the table to have a clustered PRIMARY KEY.
空间索引是在存储空间数据的列上创建的一种特殊类型的索引,可通过减少需要在其上应用相对昂贵的空间操作的对象数量来提高在空间列上执行的操作的性能。 考虑到创建空间索引需要表具有群集的PRIMARY KEY。
Assume that we have recreated the previous table by changing the Address column data type to be geometry spatial, as shown below:
假定我们通过将“地址”列的数据类型更改为几何空间来重新创建了上一个表,如下所示:
DROP TABLE DiffIndexTypesDemo
GO
CREATE TABLE DiffIndexTypesDemo
( ID INT IDENTITY (1,1) PRIMARY KEY,
Name Varchar(50) ,
ADDRESS geometry
)
GO
Now, we can easily create a Spatial index on the created table, as it meets the two requirements for creating a Spatial index; there is a column with spatial data type and a Clustered PRIMARY KEY on that table.
现在,我们可以轻松地在创建的表上创建一个空间索引,因为它满足了创建空间索引的两个要求: 该表上有一列具有空间数据类型和Clustered PRIMARY KEY的列。
A Spatial index can be created on the geometry column using CREATE SPATIAL INDEX T-SQL command by providing the Spatial index name, the name of the table on which the index will be created, the spatial column, the tessellation schema and the bounding box.
通过提供空间索引名称,将在其上创建索引的表的名称,空间列,细分模式和边界框,可以使用CREATE SPATIAL INDEX T-SQL命令在几何列上创建空间索引。
The below CREATE SPATIAL INDEX T-SQL statement is used to create a Spatial index on the demo table using the default tessellation schema with a specific bounding box. The bounding box is numeric four-tuple values that define the four coordinates of the bounding box: the x-min and y-min coordinates of the lower, left corner, and the x-max and y-max coordinates of the upper right corner.
下面的CREATE SPATIAL INDEX T-SQL语句用于使用带有特定边界框的默认镶嵌模式在演示表上创建空间索引。 边界框是数字四元组值,它定义了边界框的四个坐标:左下角的x-min和y-min坐标以及右上角的x-max和y-max坐标。
CREATE SPATIAL INDEX SIX_DiffIndexTypesDemo_Address
ON DiffIndexTypesDemo(Address)
WITH ( BOUNDING_BOX = ( 0, 0, 500, 200 ) );
XML索引 (XML index)
An XML index is a special type of index that is created on XML binary large objects (BLOBs) in the XML data type columns, to enhance the performance of the queries that are retrieving data from that table, by indexing all tags, values, and paths over the XML instances in that column.
XML索引是一种特殊类型的索引,它是在XML数据类型列中的XML二进制大对象(BLOB)上创建的,以通过对所有标记,值和索引建立索引来增强从该表检索数据的查询的性能。该列中XML实例的路径。
There are two types of XML indexes; the Primary XML index and the Secondary XML index, with the ability to create up to 249 XML index on each table. The Primary XML index is the first Clustered XML index created on the table, with the clustered key consists of the clustering of the user table and an XML node identifier. After creating the Primary XML index, different types of Secondary XML indexes can be created on the table, such as PATH, VALU, and PROPERTY, to improve the performance of the submitted queries, depending on the type of there queries.
XML索引有两种类型: 主要 XML索引和次要 XML索引,并能够在每个表上最多创建249个XML索引。 主XML索引是在表上创建的第一个集群XML索引,集群键由用户表的集群和XML节点标识符组成。 创建主XML索引后,可以根据表中的查询类型在表上创建不同类型的辅助XML索引,例如PATH,VALU和PROPERTY,以提高提交查询的性能。
The Secondary VALUE XML index represents the node value and path of the primary XML index. The Secondary PATH XML index built on the path values and the node values in the primary XML index, allowing efficient seeks when searching for paths. The Secondary PROPERTY XML index contains the base table Primary Key, the path and the node value of the Primary XML index.
次要VALUE XML索引表示主要XML索引的节点值和路径。 辅助PATH XML索引建立在主XML索引中的路径值和节点值的基础上,从而在搜索路径时实现了有效的查找。 辅助PROPERTY XML索引包含基本表主键,主XML索引的路径和节点值。
Let us redesign the previous table by changing the Address column data type to be XML, as shown below:
让我们通过将“地址”列数据类型更改为XML来重新设计上一个表,如下所示:
DROP TABLE DiffIndexTypesDemo
GO
CREATE TABLE DiffIndexTypesDemo
( ID INT IDENTITY (1,1) PRIMARY KEY,
Name Varchar(50) ,
ADDRESS XML
)
GO
In order to enhance the performance of the queries that retrieve XML values, we will create a Primary XML index on the Address column, using the CREATE PRIMARY XML INDEX T-SQL statement below:
为了提高检索XML值的查询的性能,我们将使用下面的CREATE PRIMARY XML INDEX T-SQL语句在Address列上创建Primary XML索引:
CREATE PRIMARY XML INDEX PXML_DiffIndexTypesDemo_Address
ON DiffIndexTypesDemo (Address);
GO
Then create a PATH Secondary XML index on that column using the CREATE XML INDEX T-SQK statement shown below:
然后使用如下所示的CREATE XML INDEX T-SQK语句在该列上创建PATH二级XML索引:
CREATE XML INDEX ISXML_DiffIndexTypesDemo_Address_Path
ON DiffIndexTypesDemo (Address)
USING XML INDEX PXML_DiffIndexTypesDemo_Address FOR PATH;
GO
其他索引特殊类型 (Other index special types)
Columnstore index: The Columnstore index is a feature in which the data will be physically organized in columnar data format, unlike traditional row-store technology, with the row-wise format, that is used for storing, managing and retrieving large data using a columnar data format. A Columnstore index works well for data warehousing workloads that perform bulk loads and read-only queries, achieving up to 7x data compression over the uncompressed data size.
列存储索引 :列存储索引是一项功能,其中数据将以列数据格式进行物理组织,这与传统的行存储技术不同,具有逐行格式,该格式用于按列存储,管理和检索大型数据数据格式。 列存储索引非常适合执行批量加载和只读查询的数据仓库工作负载,在未压缩的数据大小上,数据压缩率最高可达到7倍。
For more information about Columnstore index, check How to Create a Clustered Columnstore Index on a Memory-Optimized Table.
有关Columnstore索引的更多信息,请参见如何在内存优化表上创建群集的Columnstore索引 。
Full-text index: This is a special type of token-based functional index, that is built and maintained by the SQL Server Full-Text Engine, to enhance the performance of character string data search. For more information about the Full-Text search, check Full-Text Index Population.
全文索引 :这是一种特殊的基于令牌的功能索引,由SQL Server全文引擎构建和维护,以增强字符串数据搜索的性能。 有关全文搜索的更多信息,请检查全文索引填充 。
Hash index: This is a special type of index used in Memory-Optimized tables, to access the data through an in-memory hash table, consuming a fixed amount of memory, specified by the bucket count.
哈希索引 :这是在“内存优化”表中使用的一种特殊类型的索引,用于通过内存中的哈希表访问数据,消耗固定数量的内存(由存储桶计数指定)。
For more information about Memory-Optimized tables, check In-Memory OLTP Enhancements in SQL Server 2016.
有关内存优化表的更多信息,请检查SQL Server 2016中的内存中OLTP增强功能 。
Stay tuned for the next article, in which we will discuss how to enhance the performance of queries by using the appropriate type of index.
请继续阅读下一篇文章,我们将在其中讨论如何通过使用适当的索引类型来增强查询的性能。
目录 (Table of contents)
翻译自: https://www.sqlshack.com/working-with-different-sql-server-indexes-types/















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









