





 本文介绍了如何使用SQL Server索引来调整查询性能。讨论了索引设计、查询优化以及何时使用索引。通过示例展示了索引在简单和复杂查询中的作用,强调了正确匹配索引和查询列排序的重要性,以及索引可能导致的额外开销。文章还提到了SQL Server Profiler和数据库引擎优化顾问在调优中的应用。
本文介绍了如何使用SQL Server索引来调整查询性能。讨论了索引设计、查询优化以及何时使用索引。通过示例展示了索引在简单和复杂查询中的作用,强调了正确匹配索引和查询列排序的重要性,以及索引可能导致的额外开销。文章还提到了SQL Server Profiler和数据库引擎优化顾问在调优中的应用。
In the previous articles of this series (see the full article TOC at bottom), we discussed the internal structure of the SQL Server tables and indexes, the best practices to follow when designing a proper index, the group of operations that you can perform on the SQL Server indexes, how to design effective Clustered and Non-clustered indexes and finally the different types of SQL Server indexes, above and beyond Clustered and Non-clustered indexes classification. In this article, we will discuss how to tune the performance of the bad queries using SQL Server Indexes.
在本系列的前几篇文章中(请参阅底部的完整文章TOC),我们讨论了SQL Server表和索引的内部结构,设计适当索引时应遵循的最佳实践,可以执行的操作组。 SQL Server索引,如何设计有效的聚集索引和非聚集索引,以及除聚集索引和非聚集索引分类之外的其他类型SQL Server索引。 在本文中,我们将讨论如何使用SQL Server索引来调整错误查询的性能。
Until this point, after getting full understanding about the SQL Server index concept, structure, design and types, we are ready to design the most effective SQL Server index that the SQL Server Query Optimizer will always take benefits from, in speeding up the data retrieval process on our queries, which is the main goal of creating an index, with the minimum disk I/O operations and the least system resources usage.
到目前为止,在充分了解了SQL Server索引的概念,结构,设计和类型之后,我们准备设计最有效SQL Server索引,SQL Server Query Optimizer将始终从中受益,以加速数据检索。处理查询,这是创建索引的主要目标,它具有最少的磁盘I / O操作和最少的系统资源使用。
Before designing an index, that helps the query processor to find the data quickly and touching the underlying table as few times as possible, you should have good understanding of the underlying data structure and usage, the type of queries reading that data and the frequency the queries are run. As a database administrator, you can use different tools and scripts to provide the system owners with the list of suggested indexes that may enhance the performance of their system queries. But depending on their understanding of system behavior, they should provide the final confirmation of creating such indexes, only after examining the performance of the query on the development environment before and after creating the suggested index.
在设计索引以帮助查询处理器快速查找数据并尽可能少地接触基础表之前,您应该对基础数据结构和用法,读取该数据的查询类型以及查询的频率有很好的了解。查询运行。 作为数据库管理员,您可以使用不同的工具和脚本为系统所有者提供建议索引的列表,这些索引可以增强其系统查询的性能。 但是根据他们对系统行为的理解,只有在创建建议的索引之前和之后检查开发环境上查询的性能之后,他们才应提供创建此类索引的最终确认。
Database administrators have to balance between creating too many indexes and too few indexes. For example, there is no need to index every column individually or involve the column in many overlapping indexes. They should also take into consideration that, the index that will enhance the performance of SELECT queries will also slow down the different DML operations, such as INSERT, UPDATE and DELETE queries.
数据库管理员必须在创建太多索引和索引太少之间取得平衡。 例如,不需要单独索引每列或使该列包含许多重叠索引。 他们还应考虑到,将增强SELECT查询性能的索引也会减慢不同的DML操作,例如INSERT,UPDATE和DELETE查询。
Another thing to consider is the tuning of the index itself, as the index that is working fine with your queries in the past may not fit the queries now, due to frequent changes in the table schema and data itself. This may require removing the index and create more effective one. We will discuss in detail in the next article, how to get information about index usage and decide if we need to keep or remove that index. On the other hand, the index may be suffering from fragmentation issues only due to changing the data very frequently, that can be resolved using the different index maintaining tasks, discussed deeply in the last article of this series.
要考虑的另一件事是索引本身的调整,因为由于表模式和数据本身的频繁更改,过去与您的查询配合良好的索引现在可能不适合现在的查询。 这可能需要删除索引并创建更有效的索引。 在下一篇文章中,我们将详细讨论如何获取有关索引使用情况的信息,以及决定是否需要保留或删除该索引。 另一方面,索引可能仅由于频繁更改数据而遭受碎片问题,可以使用不同的索引维护任务来解决该问题,这在本系列的最后一篇文章中进行了深入讨论。
Let us start our demo to understand the performance tuning concept practically. We will create a new database, IndexDemoDB, that contains three tables; the STD_Info table that contains the students’ information, the Courses table that contains the list of available courses and finally the STD_Evaluation table that contains the grades of the registered students in the available courses. The STD_Evaluation table contains two foreign keys; the ID of the student that references the STD-Info table and the ID of the course that reference the Courses table. The T-SQL script below is used to create the database and the tables as described:
让我们开始演示,以实际了解性能调整的概念。 我们将创建一个新数据库IndexDemoDB,其中包含三个表。 包含学生信息的STD_Info表,包含可用课程列表的Courses表以及最后包含可用课程中已注册学生成绩的STD_Evaluation表。 STD_Evaluation表包含两个外键。 引用STD-Info表的学生的ID和引用Courses表的课程的ID。 下面的T-SQL脚本用于创建数据库和表,如下所述:
CREATE DATABASE IndexDemoDB
GO
CREATE TABLE STD_Info
( STD_ID INT IDENTITY (1,1) PRIMARY KEY,
STD_Name VARCHAR (50),
STD_BirthDate DATETIME,
STD_Address VARCHAR (500)
)
GO
CREATE TABLE Courses
( Course_ID INT IDENTITY (1,1) PRIMARY KEY,
Course_Name VARCHAR (50),
Course_MaxGrade INT
)
GO
CREATE TABLE STD_Evaluation
(
EV_ID INT IDENTITY (1,1),
STD_ID INT,
Course_ID INT,
STD_Course_Grade INT,
CONSTRAINT FK_STD_Evaluation_STD_Info FOREIGN KEY (STD_ID)
REFERENCES STD_Info (STD_ID),
CONSTRAINT FK_STD_Evaluation_Courses FOREIGN KEY (Course_ID)
REFERENCES Courses (Course_ID)
)
Once the database and the tables are created, with no index or key defined on the STD_Evaluation table, we will fill each table with 100K records, using ApexSQL Generate, as shown below:
创建数据库和表之后,在STD_Evaluation表上未定义索引或键,我们将使用ApexSQL Generate来向每个表填充100K条记录,如下所示:
调整一个简单的查询 (Tuning a simple query)
Reading from a table that has no index is similar to finding a word in a book by examining every single page in that book. If you try to execute the below SELECT query to retrieve data from the STD_Evaluation table, after enabling the TIME and IO statistics and including the execution plan, using the T-SQL statement below:
从没有索引的表中进行读取类似于通过检查书中的每一页来在书中查找单词。 如果您尝试执行以下SELECT查询以从STD_Evaluation表中检索数据,请在启用TIME和IO统计信息并包括执行计划之后,使用以下T-SQL语句:
SET STATISTICS TIME ON
SET STATISTICS IO ON
GO
SELECT * FROM [dbo].[STD_Evaluation] WHERE STD_ID < 1530
You will see from the execution plan, generated after executing the query, that SQL Server will perform a Table Scan operation against that table by examining all table rows to check if these rows achieve the WHERE condition, as shown in the execution plan below:
您将从执行查询后生成的执行计划中看到,SQL Server将通过检查所有表行以检查这些行是否满足WHERE条件来对该表执行表扫描操作,如以下执行计划所示:
You can see also from the TIME and IO statistics, that the query is executed within 655 ms, consuming 94 ms from the CPU time, as shown below:
您还可以从TIME和IO统计信息中看到,查询是在655 ms内执行的,从CPU时间开始消耗了94 ms ,如下所示:
Having an index in the front of the book will allow the reader finds their target faster. The same applies to the SQL Server tables; having an index on the table, will speed up the data retrieval process, providing the client with the requested data in shorter time, of course, if the index is designed properly.
在书前加一个索引将使读者更快地找到他们的目标。 这同样适用于SQL Server表。 如果在索引上进行了适当的设计,那么在表上具有索引将可以加快数据检索过程,并在较短的时间内为客户端提供所需的数据。
If we look at the surface of the previous SELECT query and decide to add an index on the STD_ID column mentioned in the WHERE clause of that query, using the CREATE INDEX T-SQL statement below:
如果我们看一下先前的SELECT查询的表面,并决定使用下面的CREATE INDEX T-SQL语句在该查询的WHERE子句中提到的STD_ID列上添加索引:
CREATE NONCLUSTERED INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation] (STD_ID)
Then execute the same SELECT statement:
然后执行相同的SELECT语句:
SELECT * FROM [dbo].[STD_Evaluation] WHERE STD_ID < 1530
You will see from the execution plan, generated after executing the query, that SQL Server performs again Table Scan operation, to retrieve the data from that table, without considering the created index, as shown in the execution plan below:
从执行查询后生成的执行计划中,您将看到SQL Server再次执行表扫描操作,以从该表中检索数据,而无需考虑创建的索引,如下面的执行计划所示:
Checking the TIME and IO statistics of the query, you will see that, the time required, and the CPU time consumed to execute the query is not very far from the previous SELECT statement without indexes, with tiny enhancement as shown below:
查看查询的TIME和IO统计信息,您会发现执行查询所需的时间和所用的CPU时间与没有索引的先前SELECT语句相距不远,并且具有很小的增强,如下所示:
Having an index created on that table does not mean that SQL Server will necessarily use it. In some situations, SQL Server finds that scanning the underlying table is faster than using the index, especially when the table is small, or the query returns most of the table records.
在该表上创建索引并不意味着SQL Server一定会使用它。 在某些情况下,SQL Server发现扫描基础表比使用索引要快,尤其是在表很小或查询返回大多数表记录时。
Let us have a second look at the previous execution plan, you will see a green message from the SQL Server that recommends an index to improve the performance of that query with 77.75%. Right-click on that execution plan and choose Missing Index Details option, to show the suggested index, as shown below:
让我们再次看一下先前的执行计划,您将看到来自SQL Server的绿色消息,该消息建议使用索引以77.75%的比率提高该查询的性能。 右键单击该执行计划,然后选择“ 缺少索引详细信息”选项,以显示建议的索引,如下所示:
The same index suggestion can be also found by querying the sys.dm_db_missing_index_details dynamic management view, that returns detailed information about missing indexes, excluding spatial indexes, as shown below:
通过查询sys.dm_db_missing_index_details动态管理视图,也可以找到相同的索引建议,该视图返回有关缺失索引的详细信息,不包括空间索引,如下所示:
SELECT * FROM sys.dm_db_missing_index_details
The previous query will suggest the same covering index, with the STD_ID that is used in the WHERE clause of the query as an index key and the rest of returned columns in the SELECT statement, EV_ID, Course_ID and STD_Course_Grade columns, as non-key columns in the INCLUDE clause of the index creation statement shown below:
上一个查询将建议相同的覆盖索引,其中在查询的WHERE子句中使用的STD_ID作为索引键,而SELECT语句中返回的其余列(EV_ID,Course_ID和STD_Course_Grade列)用作非关键列在索引创建语句的INCLUDE子句中,如下所示:

We will drop the wrong index created previously and create a new index that is suggested by the SQL Server using the T-SQL script below:
我们将删除先前创建的错误索引,并使用以下T-SQL脚本创建SQL Server建议的新索引:
USE [IndexDemoDB]
GO
DROP INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation]
GO
CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_STD_ID]
ON [dbo].[STD_Evaluation] ([STD_ID])
INCLUDE ([EV_ID],[Course_ID],[STD_Course_Grade])
GO
If you try to execute the same SELECT statement:
如果尝试执行相同的SELECT语句:
SELECT * FROM [dbo].[STD_Evaluation] WHERE STD_ID < 1530
Then check the execution plan, generated after executing the query, you will see that SQL Server will perform an Index Seek operation to retrieve the data to the user, as shown below:
然后检查执行查询后生成的执行计划,您将看到SQL Server将执行索引查找操作以将数据检索给用户,如下所示:
The TIME and IO statistics will show that the time required to execute the query decreased from 655ms to 554ms, with about 15% enhancement after adding the index, and the consumed CPU time reduced from 94ms to 31ms, with about 67% enhancement when using the index. You can imagine the enhancement that can be gained in the case of large tables, as shown below:
TIME和IO统计信息将显示执行查询所需的时间从655ms减少到554ms,添加索引后增加了约15% ,消耗的CPU时间从94ms减少到了31ms,在使用索引时增加了67%指数。 您可以想象在大型表的情况下可以获得的增强,如下所示:
The previous Non-clustered index is created over a heap table. We will drop the previously created Non-clustered index, create a Clustered index on the EV_ID column, then create the Non-clustered index again, using the T-SQL script below:
先前的非聚集索引是在堆表上创建的。 我们将删除先前创建的非聚集索引,在EV_ID列上创建一个聚集索引,然后使用下面的T-SQL脚本再次创建非聚集索引:
DROP INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation]
GO
CREATE CLUSTERED INDEX IX_Evaluation_EV_ID ON [STD_Evaluation] ([EV_ID])
GO
CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_STD_ID]
ON [dbo].[STD_Evaluation] ([STD_ID])
INCLUDE ([EV_ID],[Course_ID],[STD_Course_Grade])
Recall what we mentioned in the previous articles of this series that the Non-clustered index will be rebuilt automatically when creating a Clustered index on the table in order to point to the Clustered key instead of pointing to the base table. If we execute the same SELECT statement again:
回想一下我们在本系列前几篇文章中提到的,在表上创建聚簇索引时,非聚簇索引将自动重建,以便指向聚簇键而不是基表。 如果我们再次执行相同的SELECT语句:
SELECT * FROM [dbo].[STD_Evaluation] WHERE STD_ID < 1530
You will see that the same execution plan will be created without any change from the previous one, as shown below:
您将看到将在不改变前一个执行计划的情况下创建相同的执行计划,如下所示:
In addition, the TIME and IO statistics will show that the time required to execute the query and the CPU time consumed by the query is somehow similar to the previous result, with a small enhancement in reducing the IO operations performed to retrieve the data, due to working with a small table, as shown below:
此外,TIME和IO统计信息将显示执行查询所需的时间和查询所消耗的CPU时间在某种程度上与先前的结果相似,但由于减少了为检索数据而执行的IO操作,略有增强。使用一张小桌子,如下所示:
You may also think about replacing the Non-clustered index with a Clustered index on STD_ID column, taking into consideration that the Clustered index contains no INCLUDE clause. If we drop all indexes available on that table and replace it with only one Clustered index, using the T-SQL script below:
您还可以考虑使用STD_ID列上的聚簇索引替换非聚簇索引,同时考虑到聚簇索引不包含INCLUDE子句。 如果我们删除该表上所有可用的索引,并使用以下T-SQL脚本仅将其替换为一个聚集索引:
DROP INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation]
GO
DROP INDEX IX_Evaluation_EV_ID ON [STD_Evaluation]
GO
CREATE CLUSTERED INDEX IX_Evaluation_EV_ID ON [STD_Evaluation] ([STD_ID])
Then execute the same SELECT statement:
然后执行相同的SELECT语句:
SELECT * FROM [dbo].[STD_Evaluation] WHERE STD_ID < 1530
You will see from the generated execution plan, that a Clustered Index Seek operation will be performed to retrieve the requested data, as shown below:
您将从生成的执行计划中看到,将执行聚簇索引查找操作来检索请求的数据,如下所示:
With no noticeable enhancement in the TIME and IO statistics generated from executing the query, in the case of our small table, as shown below:
对于我们的小表,在执行查询时生成的TIME和IO统计信息没有明显增强,如下所示:
调优复杂的查询 (Tuning a complex query)
Let us try now to tune the performance of more complex query, that returns the name of the student, the name of the course, the maximum grade of the course and finally the grade of the student in that grade, by joining the three previously created tables together based on the common columns between each two tables, taking into consideration that the STD_Evaluation table has no index on it, as shown in the SELECT statement below:
现在让我们尝试调整更复杂的查询的性能,通过结合之前创建的三个查询,返回学生的姓名,课程的名称,课程的最高年级以及最终该年级的学生的成绩。 考虑到STD_Evaluation表上没有索引,这些表基于每两个表之间的公共列组合在一起,如下面的SELECT语句所示:
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade]
FROM [dbo].[STD_Info] ST
JOIN [dbo].[STD_Evaluation] EV
ON ST.STD_ID =EV.[STD_ID]
JOIN [dbo].[Courses] C
ON C.Course_ID= EV.Course_ID
WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320
If you check the execution plan generated after executing the query, you will see that, due to the fact that the STD_Evaluation has no index, SQL Server will scan all the STD_Evaluation table records to search for the rows that meet the WHERE clause condition, by performing a Table Scan operation. In addition, a green message will be displayed in the execution plan showing a suggested index from the SQL Server to enhance the performance of the query, as shown below:
如果检查执行查询后生成的执行计划,您将看到,由于STD_Evaluation没有索引,SQL Server将扫描所有STD_Evaluation表记录,以搜索符合WHERE子句条件的行。执行表扫描操作。 此外,执行计划中将显示绿色消息,其中显示来自SQL Server的建议索引,以增强查询的性能,如下所示:
Right-click on that execution plan and choose Missing Index Details option, to show the suggested index. The T-SQL statement that is used to create the new index, with the performance improvement percentage, which is 82% here, will be displayed in the appeared window, as shown below:
右键单击该执行计划,然后选择“缺少索引详细信息”选项,以显示建议的索引。 用于创建新索引的T-SQL语句(此处的性能提高百分比为82%)将显示在出现的窗口中,如下所示:
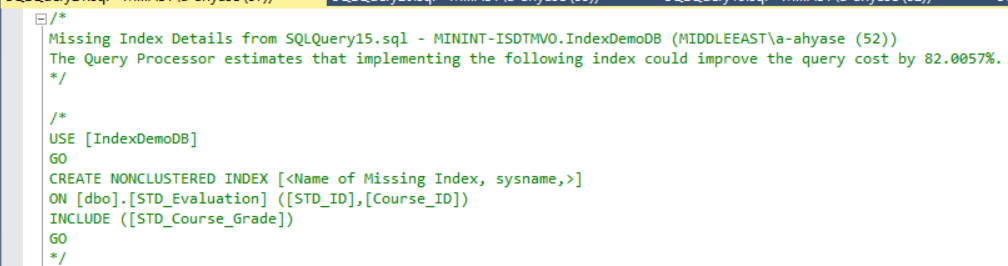
The TIME and IO statistics generated from executing the previous query shows that the SQL Server performs 310 logical reads, within 65ms and consumes 16ms from the CPU time in order to retrieve the data, as shown below:
通过执行上一个查询生成的TIME和IO统计信息表明,SQL Server在65ms内执行310次逻辑读取,并从CPU时间开始消耗16ms来检索数据,如下所示:
The same index suggestion can be also found by querying the sys.dm_db_missing_index_details dynamic management view, that returns detailed information about missing indexes, excluding spatial indexes, as shown below:
通过查询sys.dm_db_missing_index_details动态管理视图,也可以找到相同的索引建议,该视图返回有关缺失索引的详细信息,不包括空间索引,如下所示:

The performance of the query can be also tuned using the combination of the SQL Server Profiler and the Database Engine Tuning Advisor tools. Right-click on the query that you manage to tune and click on the Trace Query in SQL Server Profiler option, as shown below:
还可以结合使用SQL Server Profiler和数据库引擎优化顾问工具来调整查询的性能。 右键单击您要调整的查询,然后单击“ SQL Server Profiler中的跟踪查询”选项,如下所示:
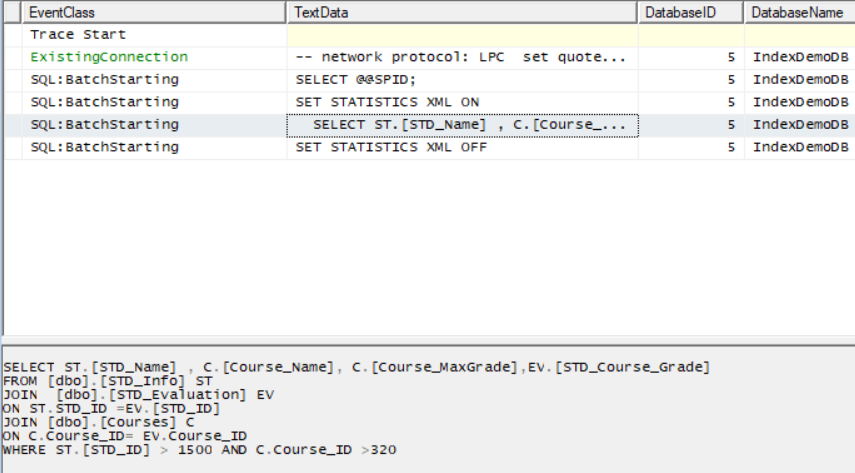
A new SQL Server Profiler session will be displayed. When you execute the query to be tuned, the query statistics will be caught in the opened SQL Server Profiler session, as shown in the snapshot below:
将显示一个新SQL Server Profiler会话。 当您执行要优化的查询时,查询统计信息将捕获到打开SQL Server Profiler会话中,如以下快照所示:
Save the previous trace in order to use it as the workload for the Database Engine Tuning Advisor. From the Tools menu of the SQL Server Management Studio, choose the Database Engine Tuning Advisor option, as shown below:
保存先前的跟踪,以便将其用作数据库引擎优化顾问的工作负载。 从SQL Server Management Studio的“ 工具”菜单中,选择“ 数据库引擎优化顾问”选项,如下所示:
From the opened Database Engine Tuning Advisor window, connect to the target SQL Server, the database from which the query will retrieve data and finally allocate the workload file that contains the query trace, then click on
在打开的数据库引擎优化顾问窗口中,连接到目标SQL Server,该查询将从该数据库中检索数据,并最终分配包含查询跟踪的工作负载文件,然后单击
Once the analysis operation completed successfully, recommendations that include indexes and statistics that could enhance the performance of the query, with the estimated enhancement percentage will be displayed on the generated report. In our case, the same previously suggested index will be displayed in the recommendations report, as shown below:
一旦分析操作成功完成,将在生成的报告中显示包含索引和统计信息的建议,这些建议和统计信息可以增强查询的性能,并带有估计的增强百分比。 在我们的情况下,建议报告中将显示以前建议的相同索引,如下所示:
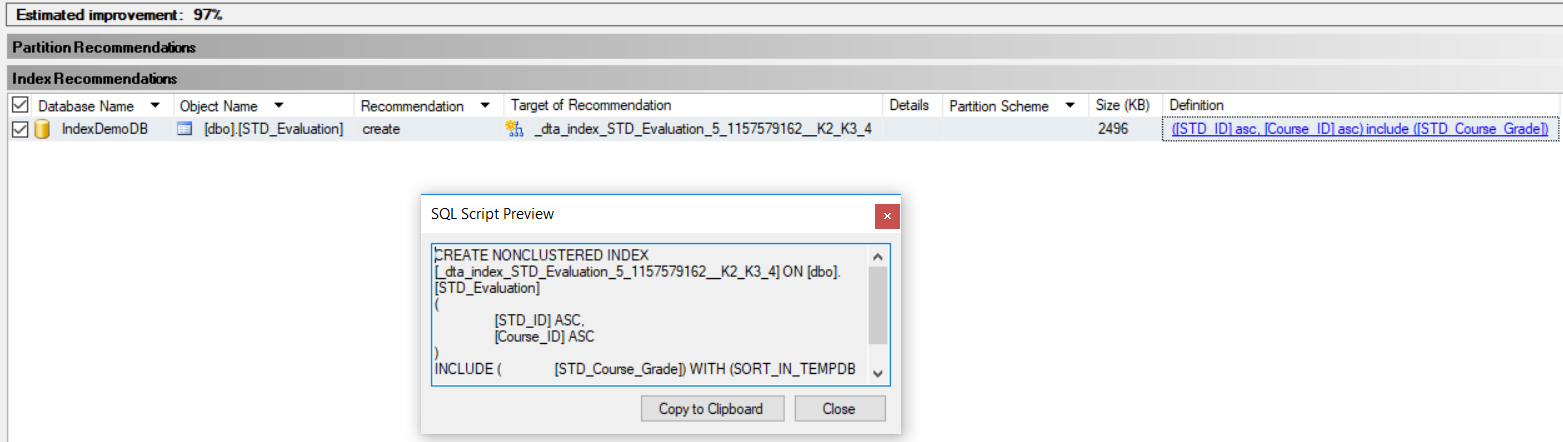
If we take the CREATE INDEX statement provided from the previous execution plan or from the Database Engine Tuning Advisor report and create that suggested index to enhance the query performance, as in the T-SQL statement below:
如果我们采用先前执行计划或数据库引擎优化顾问报告中提供的CREATE INDEX语句,并创建该建议的索引以增强查询性能,如下面的T-SQL语句所示:
USE [IndexDemoDB]
GO
CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_Course_ID]
ON [dbo].[STD_Evaluation] ([STD_ID],[Course_ID])
INCLUDE ([STD_Course_Grade])
GO
Then execute the same SELECT statement:
然后执行相同的SELECT语句:
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade]
FROM [dbo].[STD_Info] ST
JOIN [dbo].[STD_Evaluation] EV
ON ST.STD_ID =EV.[STD_ID]
JOIN [dbo].[Courses] C
ON C.Course_ID= EV.Course_ID
WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320
You will see from the generated execution plan, that the previous slow Table Scan operation changed to a fast Index Seek operation, as shown below:
您将从生成的执行计划中看到,以前的慢速表扫描操作已更改为快速索引查找操作,如下所示:
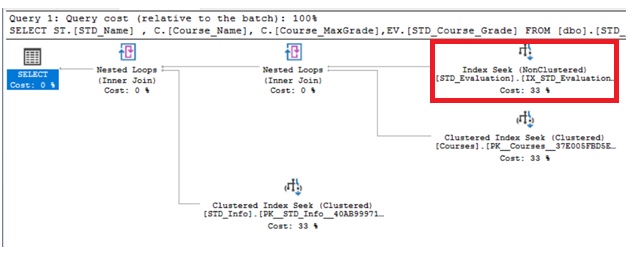
The TIME and IO statistics also shows that, after creating the suggested index, SQL Server performs only 3 logical rea operations, compared with 310 logical reads before creating the index, with about 91% enhancement, within 40ms, compared with the 65ms required to execute the query before creating the index, with about 39% enhancement, and consume no CPU time compared with the 16ms consumed before creating the index, as shown clearly below:
TIME和IO统计信息还显示,在创建建议的索引之后,SQL Server仅执行3次逻辑rea操作,而在创建索引之前进行310次逻辑读取,在40ms内增强了约91% ,而执行所需的时间为65ms创建索引之前的查询(增强了约39%) ,与创建索引之前的16ms相比, 不占用CPU时间,如下所示:
The previous Non-clustered index is created over a heap table. We will drop the previously created Non-clustered index, create a Clustered index on the EV_ID column, then create the Non-clustered index again, using the T-SQL script below:
先前的非聚集索引是在堆表上创建的。 我们将删除先前创建的非聚集索引,在EV_ID列上创建一个聚集索引,然后使用下面的T-SQL脚本再次创建非聚集索引:
USE [IndexDemoDB]
GO
DROP INDEX [IX_STD_Evaluation_Course_ID]
ON [dbo].[STD_Evaluation]
GO
CREATE CLUSTERED INDEX IX_Evaluation_EV_ID ON [STD_Evaluation] ([EV_ID])
GO
CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_Course_ID]
ON [dbo].[STD_Evaluation] ([STD_ID],[Course_ID])
INCLUDE ([STD_Course_Grade])
GO
If you execute the same SELECT statement again:
如果再次执行相同的SELECT语句:
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade]
FROM [dbo].[STD_Info] ST
JOIN [dbo].[STD_Evaluation] EV
ON ST.STD_ID =EV.[STD_ID]
JOIN [dbo].[Courses] C
ON C.Course_ID= EV.Course_ID
WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320
The same execution plan will be generated as shown below:
将生成相同的执行计划,如下所示:
In addition, the TIME and IO statistics will show a slight enhancement in the logical reads number and the time required to execute the query, as we are working with a small table, as shown below:
另外,由于我们正在使用一张小表,因此TIME和IO统计信息将在逻辑读取数和执行查询所需的时间方面略有增强,如下所示:
In the previous articles of this series, we mentioned that the sorting order of the columns in the index key should match the same order of the columns in the query that the index will cover. To understand the reason in practical terms, let us perform the below two examples.
在本系列的前几篇文章中,我们提到了索引键中列的排序顺序应与索引将覆盖的查询中列的顺序匹配。 为了实际理解原因,让我们执行以下两个示例。
In the previously created index, the sorting order of the STD_ID and Course_ID columns is the default ASC sorting order. If we modify the SELECT query to sort the returned rows based on the STD_ID and Course_ID columns DESC, which is totally opposite to the columns order in the index, as shown in the T-SQL query below:
在先前创建的索引中,STD_ID和Course_ID列的排序顺序是默认的ASC排序顺序。 如果我们修改SELECT查询以根据STD_ID和Course_ID列DESC对返回的行进行排序,这与索引中的列顺序完全相反,如下面的T-SQL查询所示:
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade]
FROM [dbo].[STD_Info] ST
JOIN [dbo].[STD_Evaluation] EV
ON ST.STD_ID =EV.[STD_ID]
JOIN [dbo].[Courses] C
ON C.Course_ID= EV.Course_ID
WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320
ORDER BY ST.[STD_ID] DESC,C.[Course_ID] DESC
You will see from the generated execution plan, that nothing will be changed, except for the Scan Direction of the Non-Clustered index that will be Backward, that can be viewed from the Index Seek node properties window. This means that, rather than reading the index from the top to the bottom, SQL Server will read the data from that index from the bottom to the top, without the need to sort the data again, as shown clearly below:
从生成的执行计划中您将看到,除了非聚集索引的“ 扫描方向 ”将为Backward之外,其他什么都不会改变,可以从“索引寻找”节点属性窗口中查看。 这意味着,SQL Server将从而不是从上至下读取索引,而是从下至上从该索引读取数据,而无需再次对数据进行排序,如下所示:
With the minimal backward reading overhead, the statistics are shown below:
通过最小的后向读取开销,统计信息如下所示:
Things will be different when modifying the query to retrieve the rows in an order that is very far from the sorting order in the index key. For example, if we modify the SELECT query to retrieve the data sorted based on the STD_ID column in ASC order and based on the Course_ID column in DESC order, as shown in the T-SQL statement below:
修改查询以与索引键中的排序顺序相距甚远的顺序检索行时,情况将有所不同。 例如,如果我们修改SELECT查询以检索基于ASC顺序的STD_ID列和基于DESC顺序的Course_ID列排序的数据,如下面的T-SQL语句所示:
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade]
FROM [dbo].[STD_Info] ST
JOIN [dbo].[STD_Evaluation] EV
ON ST.STD_ID =EV.[STD_ID]
JOIN [dbo].[Courses] C
ON C.Course_ID= EV.Course_ID
WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320
ORDER BY ST.[STD_ID] ASC,C.[Course_ID] DESC
SQL Server cannot derive benefit from the sorting order of the columns in the index, as it is very far from the requested order in the query, but still can still benefit from the index to retrieve the data, using Index Seek operation, then it should sort the rows returned from the index using the expensive Sort operation, as shown in the generated execution plan below:
SQL Server无法从索引中列的排序顺序中受益,因为它与查询中的请求顺序相距甚远,但仍可以从索引中受益,使用Index Seek操作检索数据,则它应该使用昂贵的Sort操作对从索引返回的行进行排序 ,如以下生成的执行计划中所示:
You can see from the TIME statistics that the expensive Sort operation will slow down the query execution with a noticeable amount. This is why we keep saying that it is really important to match the sorting order of the columns in the index and the query that will take benefits from that index. The extra time overhead of the Sort operation is shown clearly below:
从TIME统计信息中可以看到,昂贵的Sort操作将使查询的执行速度显着降低。 这就是为什么我们一直在说,使索引中的列的排序顺序与从该索引中受益的查询相匹配非常重要。 排序操作的额外时间开销如下所示:
It is important to mention here that, indexing the columns individually may not be the optimal solution to enhance the performance of the query. Assume that we plan to index both the STD_ID and Course_ID columns that are used in the WHERE and JOIN conditions in the previous query, taking into consideration that the STD_Evaluation table has no index created on it, using the T-SQL script below:
在这里重要的是要提到,单独索引各列可能不是增强查询性能的最佳解决方案。 假设考虑到STD_Evaluation表上没有创建索引 ,我们计划使用下面的T-SQL脚本索引上一个查询中WHERE和JOIN条件中使用的STD_ID和Course_ID列。
CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_STD_ID]
ON [dbo].[STD_Evaluation] ([STD_ID])
GO
CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_Course_ID]
ON [dbo].[STD_Evaluation] (Course_ID)
GO
If you execute the same SELECT statement:
如果执行相同的SELECT语句:
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade]
FROM [dbo].[STD_Info] ST
JOIN [dbo].[STD_Evaluation] EV
ON ST.STD_ID =EV.[STD_ID]
JOIN [dbo].[Courses] C
ON C.Course_ID= EV.Course_ID
WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320
You will see from the execution plan, generated after executing the query that, the created indexes do not cover the previous query, that requires the SQL Server to perform an extra Key Lookup operation to retrieve the rest of columns that are not included in the created indexes from the base table, as shown below:
您将从执行查询后生成的执行计划中看到,创建的索引不覆盖先前的查询,这需要SQL Server执行额外的键查找操作以检索未包含在创建的索引中的其余列。基表中的索引,如下所示:
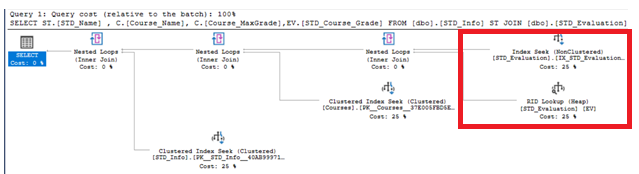
And the expensive cost of the Key Lookup operation will be translated into extra TIME cost as shown in the statistics below:
密钥查找操作的昂贵成本将转换为额外的TIME成本,如以下统计数据所示:

In this article, we translated the index design tips and tricks mentioned in the previous articles of this series in practical terms. Staty tuned for the next article, in which we will check the index information to keep the useful indexes and drop the bad ones.
在本文中,我们以实用的术语翻译了本系列前几篇文章中提到的索引设计技巧和窍门。 下一篇文章将调整Staty,在这篇文章中,我们将检查索引信息以保留有用的索引,并删除不良的索引。
目录 (Table of contents)
翻译自: https://www.sqlshack.com/tracing-and-tuning-queries-using-sql-server-indexes/















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









