





In this article, we will explore the Composite Index SQL Server and the impact of key order on it. We will also view SQL Server update statistics to determine an optimized execution plan of the Compositive index.
在本文中,我们将探讨复合索引SQL Server以及键顺序对其的影响。 我们还将查看SQL Server更新统计信息,以确定组合索引的优化执行计划。
介绍 (Introduction)
SQL Server indexes are a vital factor in query performance and overall system performance. We use clustered and non-clustered indexes with different configurations. You should go through SQLShack articles category Indexes to get familiar with indexes in SQL Server.
SQL Server索引是查询性能和整体系统性能的重要因素。 我们使用具有不同配置的集群索引和非集群索引。 您应该阅读SQLShack文章类别“ 索引”以熟悉SQL Server中的索引。
I would list a few useful articles for reference purposes:
我将列出一些有用的文章以供参考:
- Overview of Non-Clustered indexes in SQL Server SQL Server中非聚集索引概述
- Overview of SQL Server Clustered indexes SQL Server群集索引概述
- Top five considerations for SQL Server index design SQL Server索引设计的五个主要注意事项
- Optimizing SQL Server index strategies 优化SQL Server索引策略
- Working with different SQL Server indexes types 使用不同SQL Server索引类型
复合索引概述SQL Server (Overview of Composite Indexes SQL Server)
We can use single or multiple columns while creating an index in SQL Server.
在SQL Server中创建索引时,我们可以使用单列或多列。
- Single Index: It uses a single column in the index key 单个索引:它在索引键中使用单个列
- Composite Index: If we use multiple columns in the index design, it is known as the Composite Index 复合索引:如果我们在索引设计中使用多个列,则称为复合索引
Let’s understand the composite index SQL Server using an example. For this demo, create the [EmpolyeeData] table with the below script:
让我们使用一个示例来了解复合索引SQL Server。 对于此演示,使用以下脚本创建[EmpolyeeData]表:
CREATE TABLE dbo.EmployeesData
(EmpId INT IDENTITY(1, 1) PRIMARY KEY CLUSTERED,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Country VARCHAR(50)
);
GO
It creates the primary clustered key index on the [EmpID] column. We can check the existing index on a table using the sp_helpindex system procedure. It is a single index because it uses a single column for the clustered index key.
它在[EmpID]列上创建主集群键索引。 我们可以使用sp_helpindex系统过程检查表上的现有索引。 它是单个索引,因为它对聚集索引键使用单个列。
As we can have one clustered index on a SQL table, let’s create a non-clustered index on the [FirstName] and [LastName] columns:
因为我们可以在SQL表上有一个聚集索引,所以让我们在[FirstName]和[LastName]列上创建一个非聚集索引:
CREATE NONCLUSTERED INDEX IX_Emp_NC_FirstName_LastName ON
dbo.EmployeesData(FirstName, LastName);
It is a composite non-clustered index because we use multiple columns in the index definition.
它是一个复合的非聚集索引,因为我们在索引定义中使用了多个列。
In the above composite index definition, we defined the order key as FirstName, LastName. Suppose you created the index with the order key as LastName, FirstName.
在上面的复合索引定义中,我们将顺序键定义为FirstName,LastName。 假设您创建的索引的顺序键为LastName,FirstName。
Do the column orders make any difference in the composite index? Let’s explore it using various examples.
列顺序对复合索引有什么影响吗? 让我们使用各种示例对其进行探索。
示例1:以相似的索引键顺序在Where子句中使用FirstName和LastName列 (Example 1: Use the FirstName and LastName columns in Where clause in a similar order of index keys)
In the below query, we use the columns in where condition similar to the index order keys. Before executing the query, press CTRL + M to enable the actual execution plan in SSMS:
在下面的查询中,我们使用where条件类似于索引顺序键的列。 执行查询之前,请按CTRL + M以启用SSMS中的实际执行计划:
SET STATISTICS IO ON;
SELECT EmpId,
FirstName,
LastName
FROM dbo.EmployeesData
WHERE FirstName = 'Ali'
AND LastName = 'Campbell';
It uses the non-clustered index (composite index) and index seek operator to filter the results.
它使用非聚集索引(复合索引)和索引查找运算符来过滤结果。
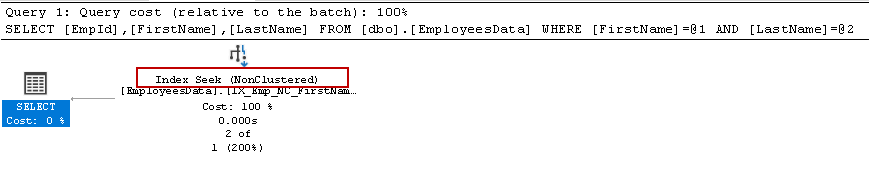
In the index seeks operator, we can see the seek operation using the same index key order.
在索引搜索操作符中,我们可以看到使用相同索引键顺序的搜索操作。
Now, switch to the messages tab, and you see it used 4 logical reads for the entire query.
现在,切换到消息选项卡,您会看到它对整个查询使用了4个逻辑读取。
示例2:以相反的顺序使用Where子句中的FirstName和LastName列 (Example 2: Use the FirstName and LastName columns in Where clause in reverse order of index keys)
In this example, we reverse the column order in the Where clause compared to the index key orders. It gives the same results but let’s view the actual execution plan:
在此示例中,我们将Where子句中的列顺序与索引键顺序进行了反转。 它给出了相同的结果,但让我们查看实际的执行计划:
SET STATISTICS IO ON;
SELECT EmpId,
FirstName,
LastName
FROM dbo.EmployeesData
WHERE LastName = 'Campbell'
AND FirstName = 'Ali';
We see a similar index seek operator using the composite index SQL Server.
我们看到了使用复合索引SQL Server的类似索引查找运算符。

No difference in the logical reads as well. Both queries use the 4 logical reads.
逻辑读取也没有差异。 这两个查询都使用4个逻辑读取。
In the seek predicates of an index seek, we see it using the column order similar to the composite index key.
在索引查找的查找谓词中,我们使用类似于复合索引键的列顺序来查看它。
示例3:在where子句中使用复合索引SQL Server的第一键列 (Example 3: Use the first key column of the composite index SQL Server in Where clause)
In this example, we want to filter records based on the [FirstName] column. It is the first index key column defined in the composite index:
在此示例中,我们要基于[FirstName]列过滤记录。 它是组合索引中定义的第一个索引键列:
SET STATISTICS IO ON;
SELECT EmpId,
FirstName,
LastName
FROM dbo.EmployeesData
WHERE FirstName = 'Ali';
It still uses the same execution plan with an index seek operator on the composite index SQL Server.
它仍然对复合索引SQL Server使用与索引查找运算符相同的执行计划。
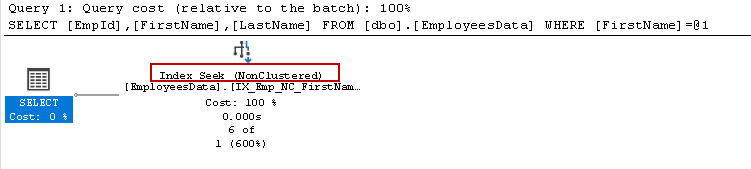
It retrieved 6 records compared to 2 records in the previous examples (1&2) but still using the 4 logical reads for the result.
与先前示例(1&2)中的2条记录相比,它检索了6条记录,但仍使用4个逻辑读取作为结果。
No differences, right! It means you can use columns in any order in the composite index SQL Server. Wait. Let’s look at the next example before making the decision.
没有差异,对! 这意味着您可以在复合索引SQL Server中以任何顺序使用列。 等待。 在做出决定之前,让我们看下一个例子。
It uses seek predicates for the [FirstName] columns, and it is the first column specified in composite index SQL Server.
它对[FirstName]列使用查找谓词,并且它是复合索引SQL Server中指定的第一列。
示例4:在where子句中使用复合索引SQL Server的第二个键列 (Example 4: Use the second key column of the composite index SQL Server in Where clause)
In this example, we want to filter records based on the [LastName] column. It is the second index key column defined in the composite index:
在此示例中,我们要基于[LastName]列过滤记录。 这是复合索引中定义的第二个索引键列:
SET STATISTICS IO ON;
SELECT EmpId,
FirstName,
LastName
FROM dbo.EmployeesData
WHERE LastName = 'Campbell';
It is using the same composite index, but this time Index seeks converts into the Index scan. You might know that an index scan is a costly operator compare to an index seek in most cases.
它使用相同的复合索引,但是这次索引寻求转换为索引扫描。 您可能知道,与大多数情况下的索引搜索相比,索引扫描是一项代价高昂的操作员。
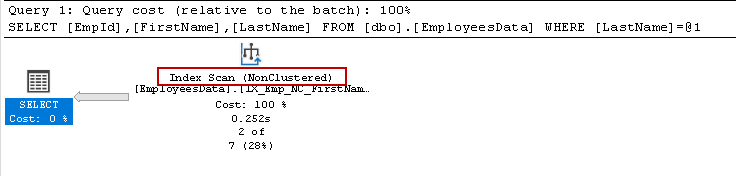
Let’s switch to the Messages tab and look at the impact of it. It retrieves two rows, but logical reads jump to 3641 compared to 4 logical reads in the previous examples.
让我们切换到“消息”选项卡并查看它的影响。 它检索两行,但逻辑读取跃升到3641,而之前的示例中为4逻辑读取。
We do not see index seek predicates because it was using the index scan operator.
我们没有看到索引查找谓词,因为它正在使用索引扫描运算符。
Now, execute all queries together in a single query window. It shows the query cost compared to other queries:
现在,在一个查询窗口中一起执行所有查询。 它显示了与其他查询相比的查询成本:
SELECT EmpId,FirstName,LastName FROM dbo.EmployeesData
WHERE FirstName = 'Ali' AND LastName = 'Campbell';
Go
SELECT EmpId,FirstName,LastName FROM dbo.EmployeesData
WHERE LastName = 'Campbell' AND FirstName = 'Ali';
Go
SELECT EmpId,FirstName,LastName FROM dbo.EmployeesData
WHERE FirstName = 'Ali';
Go
SELECT EmpId,FirstName,LastName FROM dbo.EmployeesData
WHERE LastName = 'Campbell'
Go
In the below query execution plan, we can note the following:
在下面的查询执行计划中,我们可以注意以下几点:
- The query that uses the first column [FirstName] in the where clause is optimized correctly and cause 0% cost 使用where子句中第一列[FirstName]的查询已正确优化,导致成本为0%
- The query that uses the second column [LastName] in the where clause is costliest with 100% cost comparatively 使用where子句中第二列[LastName]的查询成本最高,相对而言成本为100%

了解列顺序对复合索引SQL Server的查询的影响 (Understand the column order impact on your query for a composite index SQL Server)
SQL Server uses available statistics to determine the optimized query execution plan. This optimized query plan has operators such as index seeks and index scans. You should go through SQL Server Statistics and how to perform Update Statistics in SQL article to understand SQL Server update statistics.
SQL Server使用可用的统计信息来确定优化的查询执行计划。 这种优化的查询计划具有诸如索引查找和索引扫描之类的运算符。 您应阅读SQL文章中SQL Server统计信息以及如何执行更新统计信息,以了解SQL Server更新统计信息。
Expand the SQL table [EmployeeData] and look at the statistics. It shows you the following statistics.
展开SQL表[EmployeeData]并查看统计信息。 它向您显示以下统计信息。
主键SQL Server统计信息 (Primary key SQL Server statistics )
SQL Server creates it once we define a primary key column. Right-click on the primary key statistic (PK__Employee__AF2DBB99D43A3022) and verify that it using the primary key column, i.e. [EmpID] in my example.
一旦定义主键列,SQL Server就会创建它。 右键单击主键统计信息(PK__Employee__AF2DBB99D43A3022),然后使用主键列(例如,在我的示例中为[EmpID])验证其是否正确。
复合索引SQL Server的复合键统计信息 (Composite key statistics for composite index SQL Server)
We created a non-clustered index with a composite key. SQL Server creates the statistics for this index.
我们使用复合键创建了非聚集索引。 SQL Server为此索引创建统计信息。
To verify, view the following statistics columns screenshot as well.
要进行验证,请同时查看以下统计信息列的屏幕截图。
Let’s understand this statistic further. Click on the Details page. It gives you information about index density and histogram steps.
让我们进一步了解该统计信息。 单击详细信息页面。 它为您提供有关索引密度和直方图步长的信息。
SQL Server stores the first key column of the index in the histogram. As you can see above, histogram steps RANGE_HI_KEY showing values from the [FirstName] column.
SQL Server将索引的第一键列存储在直方图中。 如上所示,直方图显示了[FirstName]列中的值的RANGE_HI_KEY直方图 。
SQL Server uses the left-based subset for other key columns we defined in the composite index SQL Server. If we do not filter the results based on the first index key, it might not help query optimizer to choose the proper index or operator. You might see an index scan in comparison to an index seek operator as we saw in previous examples.
SQL Server对合成索引SQL Server中定义的其他关键列使用基于左数的子集。 如果我们不基于第一个索引键过滤结果,则可能无法帮助查询优化器选择适当的索引或运算符。 与前面示例中看到的索引搜索操作符相比,您可能会看到索引扫描。
自动创建的关键SQL Server统计信息 (Auto-created key SQL Server statistics )
As we know now that SQL Server uses the first key for the histogram. In this case, we filtered records on [LastName] column, so it creates a new statistic for it. You can see auto-created statistics starting from _WA_sys. We can verify from the below screenshot that It created statistics for the [LastName] column.
众所周知,SQL Server使用第一个键表示直方图。 在这种情况下,我们过滤了[LastName]列上的记录,因此它为其创建了一个新的统计信息。 您可以看到从_WA_sys开始的自动创建的统计信息。 我们可以从下面的屏幕截图中验证它是否为[姓氏]列创建了统计信息。
In the details, you can verify that histogram takes data from the LastName column values.
在详细信息中,您可以验证直方图是否从LastName列值中获取数据。
Now, in the actual execution plan, right-click and click on Show Execution Plan XML. It gives you plan in an XML format. It is comparatively complex to understand an XML plan. In this plan, we can see that query optimizer decides to create the new statistics for the [EmployeeData] table based on the where clause column.
现在,在实际的执行计划中,右键单击并单击“ 显示执行计划XML”。 它为您提供XML格式的计划。 了解XML计划比较复杂。 在该计划中,我们可以看到查询优化器决定基于where子句列为[EmployeeData]表创建新的统计信息。
<OptimizerStatsUsage>
<StatisticsInfo Database="[SQLShack]" Schema="[dbo]" Table="[EmployeesData]" Statistics="[_WA_Sys_00000003_53D770D6]" ModificationCount="0" SamplingPercent="22.6649" LastUpdate="2020-05-13T21:29:48.49" />
</OptimizerStatsUsage>
In the output, it retrieves the columns we require as result of table scan operation.
在输出中,它检索表扫描操作所需的列。

结论 (Conclusion)
In this article, we explored the impact of column orders in the composite index SQL Server. We also looked at the SQL Server update statistics to determine the optimized execution plan. It depends upon the workload, and you need to design your index keys depending upon the requirement. It might require testing in a lower environment with production workload simulation.
在本文中,我们探讨了列索引对复合索引SQL Server的影响。 我们还查看了SQL Server更新统计信息,以确定优化的执行计划。 这取决于工作量,您需要根据需求设计索引键。 它可能需要在较低的环境中通过生产工作负载模拟进行测试。
翻译自: https://www.sqlshack.com/impact-of-the-column-order-in-composite-index-sql-server/















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









