





介绍 (Introduction)
In the previous article of this series “An introduction to set-based vs procedural programming approaches in T-SQL”, we’ve seen from a simple example that we could find actual benefit from learning set-based approach when writing T-SQL code.
在本系列的上一篇文章“ T-SQL中基于集合的程序编程方法简介”中 ,我们从一个简单的示例中看到,在编写T-SQL代码时,我们可以从学习基于集合的方法中找到实际的好处。 。
In this article, we will carry on in this way by having a look at what a set is and what we can do with it in a mathematical point of view and how it’s implemented and provided to us in SQL Server. We will also have a look at more “realistic” examples using Microsoft’s AdventureWorks database.
在本文中,我们将以数学的方式看一下集合是什么以及我们可以用它做什么,以及如何在SQL Server中实现和提供给我们,以这种方式进行下去。 我们还将看一下使用Microsoft AdventureWorks数据库的更多“现实”示例。
集合论与基础 (Set Theory and fundamentals )
Set definition
集合定义
In mathematics, we define set theory is a branch of mathematics and more particularly mathematical logic that studies collections of objects we refer to as sets.
在数学中,我们将集合论定义为数学的一个分支,更具体地说,它是研究我们称为集合的对象集合的数学逻辑。
Don’t worry, we won’t do a lot of maths here as we will focus on practical aspects that we will use when writing T-SQL queries. Let’s just review some fundamentals of this theory:
不用担心,我们不会在这里做很多数学运算,因为我们将专注于编写T-SQL查询时将使用的实际方面。 让我们回顾一下该理论的一些基础知识:
- null set. Its notation is ∅ or { }. 空集。 其符号为∅或{}。
- A non-empty set contains the empty set plus one or more objects. This also means that a set can contain a set. 非空集包含空集以及一个或多个对象。 这也意味着一个集合可以包含一个集合。
- There is a fundamental binary relation between an object and a set: object to set membership. This is equivalent to the IN operation in a T-SQL query.
- 对象和set:对象之间存在基本的二进制关系以设置成员资格。 这等效于T-SQL查询中的IN操作。
- As a set can contain another set, last binary relation can be extended to set to set membership also known as subset relation or set inclusion. 当一个集合可以包含另一个集合时,最后的二进制关系可以扩展为集合,以集合成员身份,也称为子集关系或集合包含。
- Just like any arithmetic theory, set theory defines its own binary operations on sets. As an example, in number theory, we can find operations like addition or division. 就像任何算术理论一样,集合论在集合上定义了自己的二进制运算。 例如,在数论中,我们可以找到加法或除法之类的运算。
Graphical representation of a set
一组的图形表示
In order to graphically represent an operation on sets, it’s common to use Venn diagrams, which show all possible logical relations between a finite number of different sets.
为了以图形方式表示对集合的操作,通常使用维恩图,该图显示有限数量的不同集合之间的所有可能的逻辑关系。
You will find an example of representation for a single set and its objects in following figure. This set contains the following objects: A, B, D, L, o, Q and z.
您将在下图中找到单个集合及其对象的表示示例。 该集合包含以下对象:A,B,D,L,o,Q和z。
In following, we will use this representation in order to provide a good understanding of the product of each operation we will define.
接下来,我们将使用这种表示形式来更好地理解我们将定义的每个操作的结果。
在SQL Server中设置操作及其等效项 (Set operations and their equivalent in SQL Server)
Now, let’s talk about operations on two sets called A and B. We will also translate them to T-SQL statements where A and B will be either tables or the results of a query.
现在,让我们谈谈在称为A和B的两个集合上的运算。 我们还将它们转换为T-SQL语句,其中A和B将是表或查询结果。
As almost all readers should know, the way to get the content of either set A or set B is performed as followed using T-SQL (example with set A):
几乎所有读者都应该知道,获取集合A或集合B的内容的方法是使用T-SQL(例如,集合A )按以下步骤执行:
SELECT *
FROM A
Note
注意
In following, except where otherwise stipulated, T-SQL « sets » A and B have the same number of columns of same types. This is the reason why we used SELECT * notation above.
接下来,除非另有说明,否则T-SQL«集» A和B具有相同数目的相同类型的列。 这就是为什么我们使用上面的SELECT *表示法的原因。
The union operation
工会行动
The union operation will produce set made up with all the objects from A and all objects from B. It’s denoted as A∪B.
联合操作将产生由A中的所有对象和B中的所有对象组成的集合。 记为A∪B。
For instance, if A is composed of {1,3,6} and B of {3,9,10} then A∪B is a set composed of {1,3,6,9,10}.
例如,如果A由{1,3,6}组成,B由{3,9,10}组成,则A∪B是由{1,3,6,9,10}组成的集合。
Graphical representation of A∪B is as follows. Set A is represented by red circle while green circle represents Set B. A∪B is the grayscaled parts of those circles. Further representations will use this color usage convention.
A∪B的图形表示如下。 集合A用红色圆圈表示,而绿色圆圈表示集合B。 A∪B是这些圆圈的灰度部分。 进一步的表示将使用此颜色使用约定。
In SQL Server, we will find an implementation of the UNION operator. You will find below an equivalent T-SQL statement to the A∪B set:
在SQL Server中,我们将找到UNION运算符的实现。 您将在下面找到与A∪B集等效的T-SQL语句:
SELECT *
FROM A
UNION
SELECT *
FROM B
There is a little difference between T-SQL and set theory: Microsoft provides the possibility for their user to keep duplicate records that should normally be erased by UNION operator. To do so, we will append the word ALL after UNION.
T-SQL与集合论之间有一些区别:Microsoft为用户提供了保留通常应由UNION操作员擦除的重复记录的可能性。 为此,我们将在UNION之后添加ALL 。
Back to the previous example using sets of numbers, the UNION ALL of set A with set B will generate following set:
回到使用数字集的上一个示例,集合A与集合B的UNION ALL将生成以下集合:
Now, let’s take an example using SQL Server and check that there is an actual difference between UNION and UNION ALL operators.
现在,让我们以使用SQL Server为例,检查UNION和UNION ALL运算符之间是否存在实际差异。
As we can see in the above example, UNION operation is translated to MERGE JOIN operator in SQL Server while UNION ALL operator simply takes up all rows from each set and concatenates it.
在上面的示例中可以看到, UNION操作被转换为SQL Server中的MERGE JOIN运算符,而UNION ALL运算符仅占用每个集合中的所有行并将其连接起来。
So far, we haven’t seen what a « join » is. Basically, a join is a way to get a set based on two or more tables. This results set has either the same columns as base tables or column from both tables implied in join operation.
到目前为止,我们还没有看到什么是“ join”。 基本上,联接是一种基于两个或多个表获取集合的方法。 该结果集具有与基本表相同的列,或者具有联接操作中隐含的两个表中的列。
The intersection operation
交叉口作业
The intersection of set A and set B is denoted A∩B and is the set of elements that can be found in both sets.
集A和集B的交集表示为A∩B,并且是在两个集中都可以找到的元素集。
Back to the example with numeric sets,
回到带有数字集的示例中,
- A = {1,3,6} A = {1,3,6}
- B = {3,9,10} B = {3,9,10}
- A∩B = {3} A∩B= {3}
Graphically, it looks like:
从图形上看,它看起来像:
In SQL Server, there is also an INTERSECT T-SQL operator that implements this set operation. You will find below an equivalent T-SQL statement to the A∪B set:
在SQL Server中,还有一个INTERSECT T-SQL运算符可以实现此设置操作。 您将在下面找到与A∪B集等效的T-SQL语句:
SELECT *
FROM A
INTERSECT
SELECT *
FROM B
Now, let’s look at a concrete T-SQL example where A is the set of persons with firstname starting with a « J » and B is the set of persons with lastname starting with a « E ». A∩B is the set of persons with « J. E. » as initials.
现在,让我们看一个具体的T-SQL示例,其中A是姓氏以«J»开头的人员集合, B是姓氏以«E»开头的人员集合。 A∩B是以“ JE”为缩写的人的集合。
SELECT BusinessEntityID,PersonType,FirstName,MiddleName,LastName
FROM [Person].[Person]
WHERE FirstName LIKE 'J%'
INTERSECT
SELECT BusinessEntityID,PersonType,FirstName,MiddleName,LastName
FROM [Person].[Person]
WHERE LastName LIKE 'E%'
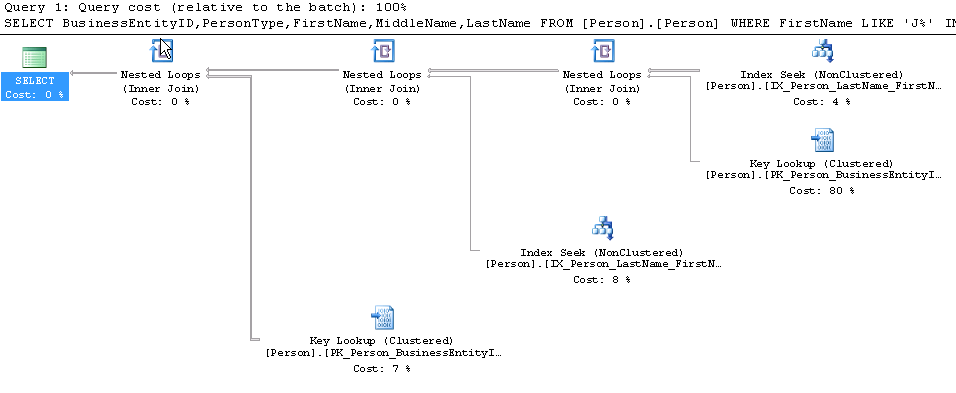
The execution plan for this particular query does not represent the equivalent operator in SQL Server database engine. As we can see, the INTERSECT operation is translated into a chain of Nested Loop operators as we have a WHERE clause in each sub-query.
此特定查询的执行计划不代表SQL Server数据库引擎中的等效运算符。 正如我们所看到的,因为我们在每个子查询中都有一个WHERE子句,所以INTERSECT操作被转换为嵌套循环运算符链。
If we comment those WHERE clauses, we will get following execution plan, that uses a MERGE JOIN operator, like for the UNION operation but in an « inner join » mode:
如果我们注释那些WHERE子句,我们将获得以下执行计划,该计划使用MERGE JOIN运算符,与UNION操作类似,但处于«内部联接 »模式:
Set difference operation
设定差运算
The difference between a set A and a set B is denoted A \ B and will take all the elements composing set A that are not in set B.
集A和集B之间的差表示为A \ B,并将采用组成集A的所有不在集B中的元素。
Back to the example with numeric sets,
回到带有数字集的示例中,
- A = {1,3,6} A = {1,3,6}
- B = {3,9,10} B = {3,9,10}
- A \ B = {1,6} A \ B = {1,6}
Graphically, it looks like:
从图形上看,它看起来像:
In SQL Server, this operation is also implemented and available to users via EXCEPT operator. You will find below an equivalent T-SQL statement to the A \ B set:
在SQL Server中,该操作也已实现,并且可以通过EXCEPT运算符供用户使用。 您将在下面找到与A \ B集等效的T-SQL语句:
SELECT *
FROM A
EXCEPT
SELECT *
FROM B
So, if we want to get a concrete example, let’s say we want to get the identifier of all persons that do not have a contact phone number. To do this, we will take table Person.Person as set A and Person.PersonPhone table as set B. This gives us following statement:
因此,如果我们想举一个具体的例子,假设我们要获得所有没有联系电话号码的人的标识符。 为此,我们将表Person.Person作为集合A并将Person.PersonPhone表作为集合B。 这给我们以下声明:
SELECT BusinessEntityID
FROM [Person].[Person]
EXCEPT
select BusinessEntityID
from Person.PersonPhone
If we take a look at its execution plan, we see that the operator used by SQL Server is called « Hash Match (Left Anti Semi Join) ».
如果看一下它的执行计划,就会发现SQL Server使用的运算符称为“ 哈希匹配(左反半连接) ”。
The Cartesian product operation
笛卡尔积运算
Operation explanation
操作说明
The Cartesian product is denoted A × B and is the set made up with all possible ordered pairs (a,b) where a is member of set A and b is member of set B.
笛卡尔积表示为A×B,它是由所有可能的有序对(a,b)组成的集合,其中a是集合A的成员, b是集合B的成员。
Back to our example using numbers where:
回到我们使用数字的示例,其中:
- A = {1,3,6} A = {1,3,6}
- B = {3,9,10} B = {3,9,10}
In order to get the elements of A × B, we can make a table with an element of A by row and an element of B by column. Each combination of row and column values will be an element of A × B.
为了获得A×B的元素,我们可以创建一个表,其中A元素按行,B元素按列。 行和列值的每种组合都是A×B的元素。
| Elements of set B | |||
| Elements of set A | 3 | 9 | 10 |
| 1 | (1,3) | (1,9) | (1,10) |
| 3 | (3,3) | (3,9) | (3,10) |
| 6 | (6,3) | (6,9) | (6,10) |
| B集元素 | |||
| 集A的元素 | 3 | 9 | 10 |
| 1个 | (1,3) | (1,9) | (1,10) |
| 3 | (3,3) | (3,9) | (3,10) |
| 6 | (6,3) | (6,9) | (6,10) |
So, A × B = {(1,3),(1,9),(1,10),(3,3),(3,9),(3,10),(6,3),(6,9),(6,10)}
因此,A×B = {(1,3),(1,9),(1,10),(3,3),(3,9),(3,10),(6,3),( 6,9),(6,10)}
Well, we might be very confused when seeing this operation and be asking ourselves « what the hell can I do with that? ». Actually, this operation is very useful in a wealth of situations and we will use it extensively in last article of this series.
好吧,当看到此操作并问自己«我们该怎么办? »。 实际上,此操作在很多情况下都非常有用,我们将在本系列的最后一篇文章中广泛使用它。
We will first have a look at the way to run a cross join using T-SQL.
我们首先来看看使用T-SQL运行交叉联接的方式。
Corresponding implementation in SQL Server
SQL Server中的相应实现
In SQL Server, we can write a Cartesian product using CROSS JOIN command as follows.
在SQL Server中,我们可以使用CROSS JOIN命令编写笛卡尔乘积,如下所示。
SELECT *
FROM A
CROSS JOIN B
Note:
注意事项 :
- A and from A和B B中的所有列
- A with itself, we would get following error message except if we provide an alias for at least one of table A自身,则会收到以下错误消息,除非我们为表A occurrences. A出现的至少其中之一提供别名。
Alternatively, we can simply use a comma to replace CROSS JOIN notation:
另外,我们可以简单地使用逗号替换CROSS JOIN表示法:
SELECT *
FROM A, B
Cross join real life application example usages
交叉连接现实应用程序示例用法
Now we know how to write a query using a cross join or Cartesian product, well, we should know in which cases we could use it.
现在,我们知道了如何使用交叉联接或笛卡尔积来编写查询,我们应该知道在哪种情况下可以使用它。
Example 1: Compute/Generate all possible cases for a particular situation
示例1:计算/生成特定情况下的所有可能情况
Let’s assume we are in a clothing factory and we want to know how many different kinds of pieces we can create and at which cost, based on clothing size and clothing color.
假设我们在一家服装工厂中,我们想根据服装的大小和颜色,知道可以制造多少种不同的作品,以及以多少成本制作。
If we have a ClothingSizes and a ClothingColors tables, then we can take advantage of CROSS JOIN operation as follows.
如果我们有ClothingSizes和ClothingColors表,则可以利用CROSS JOIN操作,如下所示。
-- Create ClothingSizes table
CREATE TABLE ClothingSizes (
SizeDisplay VARCHAR(32),
Need4FabricUnits INT
);
INSERT INTO ClothingSizes
VALUES
('Small',1), ('Medium',2),('Large',3),('Extra Large',4)
;
-- Create ClothingColors table
CREATE TABLE ClothingColors (
ColorName VARCHAR(32),
ColorPrice INT
);
-- Generate all combinations
INSERT INTO ClothingColors
VALUES
('White',10),
('Gray',12),
('Red',15),
('Yellow',20),
('Black',10)
;
SELECT
cs.SizeDisplay,
cc.ColorName,
cc.ColorPrice * cs.Need4FabricUnits as ManufactoringPrice
FROM ClothingSizes cs,
ClothingColors cc
-- cleanups
DROP TABLE ClothingColors;
DROP TABLE ClothingSizes;
The results:
结果:
Example 2: Generate test data
示例2:生成测试数据
With the example above, you can imagine a solution with a list of first names and a list of last names. When performing a cross join on both, we would get candidates for a Contact or a Person table. This can also be extended to addresses and any kinds of data. Your imagination is the limit.
在上面的示例中,您可以想象一个解决方案,其中包含一个名字列表和一个姓氏列表。 在两者上进行交叉联接时,我们将获得联系人或人员表的候选人。 这也可以扩展到地址和任何类型的数据。 您的想象力是极限。
Example 3: Generate charts data (X axis)
示例3:生成图表数据(X轴)
This example is part of an advanced example for set-based approach so it won’t be developed in details here. We will just present the situation. Let’s say we have a tool that logs any abnormal behavior with timestamp inside a SQL Server table but does not log anything when everything works like expected. In such a case, if we want, for instance, to plot number of abnormalities occurrences by day, we will face a problem as there are « holes » in data.
该示例是基于集合的方法的高级示例的一部分,因此此处将不对其进行详细开发。 我们将介绍情况。 假设我们有一个工具可以在SQL Server表中记录带有时间戳的任何异常行为,但是当一切都按预期运行时不记录任何东西。 在这种情况下,例如,如果我们想按天绘制异常发生的次数,我们将面临一个问题,因为数据中存在“漏洞”。
So, we cannot plot a chart directly and we have to first generate a timeline with the appropriate step (here hours). To generate this timeline, we would need to use CROSS JOIN.
因此,我们不能直接绘制图表,而必须首先以适当的步骤(此处为小时)生成时间表。 要生成此时间轴,我们需要使用CROSS JOIN 。
In summary, we would consider a set containing short dates of interest, then cross join them with a collection of 24 numbers from 0 to 23, representing hours in a day.
总而言之,我们将考虑一组包含感兴趣的短日期的集合,然后将它们与24个从0到23的数字集合交叉连接,代表一天中的小时数。
If we would need to report by minutes in a day, we would add another CROSS JOIN operation with a collection of 60 numbers from 0 to 59 representing minutes in an hour.
如果需要在一天中以分钟为单位进行报告,则可以添加另一个CROSS JOIN操作,该操作集合了从0到59的60个数字,代表一个小时的分钟数。
Mathematical operations with no equivalent in SQL Server
SQL Server中没有等效项的数学运算
These set operations are not that easy to implement so that it will work for every single case in an efficient manner. I think that’s the reason why Microsoft did not implement them.
这些设置操作不是那么容易实现,因此它将以有效的方式适用于每种情况。 我认为这就是Microsoft不实施它们的原因。
In following, we will present the operation itself, an example use case where they could be useful and an implementation specific to this use case.
接下来,我们将介绍操作本身,可能有用的示例用例以及特定于该用例的实现。
The symmetric difference operation
对称差运算
Symmetric difference operation is equivalent to a logical XOR. It’s denoted as A⊕B and contains all the elements that are in set A but not in set B and those that are in set B but not in set A.
对称差运算等效于逻辑XOR。 它表示为A⊕B,包含集合A中但不在集合B中的所有元素以及集合B中但不在集合A中的所有元素。
Graphically, this operation can be represented as:
以图形方式,此操作可以表示为:
We can implement it in different ways:
我们可以通过不同的方式实现它:
Implementation 1 – simply like its definition
实现1 –就像它的定义一样
(
SELECT *
FROM A
EXCEPT
SELECT *
FROM B
) UNION ALL (
SELECT *
FROM B
EXCEPT
SELECT *
FROM B
)
Implementation 2 – Using IN operator for key columns
实施2 –对关键列使用IN运算符
SELECT *
FROM A
WHERE A_Keys NOT IN ( SELECT B_Keys FROM B)
UNION ALL
SELECT *
FROM B
WHERE B_Keys NOT IN (SELECT A_Keys FROM A)
The power set operation
功率设定操作
Power set of a set A is the set composed of all possible subsets of set A.
集合A的幂集是由集合A的所有可能子集组成的集合。
In our former example using sets of numbers, A = {1,3,6}. This means that the power set of A is composed of following elements:
在我们前面的使用数字集的示例中,A = {1,3,6}。 这意味着A的幂集由以下元素组成:
- The empty set 空集
- Sets of one element {1}{3}{6} 一个元素{1} {3} {6}的集合
- Sets of two elements {1,3}{1,6}{3,6} 两个元素{1,3} {1,6} {3,6}的集合
- A). A )。
I haven’t found any particular reason to use this set operation in real life, but feel free to contact me if you find one!
我还没有发现在现实生活中使用此设置操作的任何特殊原因,但是如果您发现有此设置,请随时与我联系!
摘要 (Summary)
In this article, we’ve seen that SQL Server implements most of mathematical operations on sets. We can add the set operators defined here on the right of the table create in previous article of this series –“An introduction to set-based vs procedural programming approaches in T-SQL”. As a reminder, this table summarizes instructions and objects we can use in both procedural and set-based approaches.
在本文中,我们已经看到SQL Server在集合上实现了大多数数学运算。 我们可以在本系列前一篇文章中创建的表的右侧添加此处定义的集合运算符- “ T-SQL中的基于集合与过程编程方法的介绍” 。 提醒一下,此表总结了可在过程方法和基于集合的方法中使用的指令和对象。
| Procedural Approach | Set-Based Approach |
| SELECT and other DML operations, WHILE, BREAK, CONTINUE, IF…ELSE, TRY…CATCH Cursors (OPEN, FETCH, CLOSE) DECLARE | SELECT and other DML operations, Aggregate functions (MIN, MAX, AVG, SUM…) UNION and UNION ALL EXCEPT and INTERSECT CROSS JOIN |
| 程序方法 | 基于集合的方法 |
| SELECT和其他DML操作, 当 , BREAK , 继续 , 如果...否则 , 试着抓 游标 ( OPEN , FETCH , CLOSE ) 宣布 | SELECT和其他DML操作, 汇总函数 (MIN,MAX,AVG,SUM…) UNION和UNION ALL 例外与相交 交叉加入 |
进一步阅读 (Further readings)
This finishes this second article, but there is a third and last one to the series. In next article, we will see focus on different kinds of joins and on a SQL standard feature called Common Tabular Expression. We will then use all the information developed across this series to provide set-based solution to some real-life problems I faced as a DBA.
这是第二篇文章的结尾,但是本系列文章的第三篇也是最后一篇。 在下一篇文章中,我们将关注于不同类型的联接以及称为Common Tabular ExpressionSQL标准功能。 然后,我们将使用本系列中开发的所有信息来为我作为DBA面临的一些现实问题提供基于集合的解决方案。
Other articles in this series:
本系列的其他文章:
- An introduction to set-based vs procedural programming approaches in T-SQL T-SQL中基于集合的程序编程方法简介
- T-SQL as an asset to set-based programming approach T-SQL是基于集合的编程方法的资产
翻译自: https://www.sqlshack.com/mathematics-sql-server-fast-introduction-set-theory/















 400
400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









