





azure blob
In continuation to our hybrid deployment series, we will check few more options in order to integrate on-premises and Azure, using of course SQL Server.
在我们的混合部署系列的延续中,我们将使用SQL Server检查更多选项,以集成本地和Azure。
In the last article we talked about Azure Blob Storage and how to use this service to store a SQL Server database entirely there. Meaning that we can have our instance in our datacenter, see the server in front of you, and still have your database stored in the cloud, with your data and log files out of your disks.
在上一篇文章中,我们讨论了Azure Blob存储以及如何使用此服务将SQL Server数据库完全存储在其中。 这意味着我们可以在数据中心中拥有我们的实例,可以看到您面前的服务器,并且仍可以将您的数据库存储在云中,而数据和日志文件则不在磁盘中。
As I said in the other article, this would be a good idea for databases with not too many concurrent sessions and/or not critical in the performance point of view. Remember that you will be working in a database that is mounted in the “local” server, but to access the data you will need to travel across the network/internet and this may bring a lot of small challenges, as you are adding the network connection between your instance and your files.
就像我在另一篇文章中所说的那样,这对于并发会话不太多和/或对性能而言不是很关键的数据库是一个好主意。 请记住,您将在“本地”服务器中安装的数据库中工作,但是要访问数据,您将需要跨网络/互联网传输,这可能会带来很多小挑战,因为您要添加网络。您的实例和文件之间的连接。
Looking to this feature as is, discourages a lot of people, however we can take advantage of this in another way… As soon as we can have files in the cloud the fun begins! So I will present two awesome options to make your environment really hybrid, providing a good service without spend much money.
照原样使用此功能会令很多人望而却步,但是我们可以通过另一种方式来利用它……一旦我们将文件存储在云中,乐趣就开始了! 因此,我将提出两个很棒的选择,以使您的环境真正实现混合,无需花费大量金钱即可提供优质的服务。
混合数据库作为归档解决方案 ( Hybrid database as archival solution )
The Hybrid Database Archival solution is nothing more than an old strategy under a new possibility: store database files in Azure! But what is this?
混合数据库存档解决方案无非是一种新的可能性下的旧策略:将数据库文件存储在Azure中! 那是什么
Well, let’s pretend that you have a very large database, with a lot of historical data and you want to get rid of this. But… yes, there’s always a but… The application owner said that this data needs to stay there for some special reason, even if not too much people is using it.
好吧,让我们假设您有一个非常大的数据库,其中包含许多历史数据,而您想要摆脱它。 但是……是的,总会有一个……应用程序所有者表示,出于某些特殊原因,即使没有太多人在使用它,该数据也需要保留在其中。
This old and ugly data is already causing problems, your disk is full, the performance is not acceptable as before, the backups are huge, etc… What to do here?
这些陈旧而丑陋的数据已经引起了问题,磁盘已满,性能不如以前那样,备份很大,等等。。。在这里做什么?
Normally in situations like that, the strategy is create a new Filegroup and either create a historical table, to move that old data, or implement partitioning in the table and send all the old data to the newly create Filegroup.
通常,在这种情况下,策略是创建一个新的文件组,然后创建一个历史表,以移动该旧数据,或者在表中实施分区,然后将所有旧数据发送到新创建的文件组中。
Let’s take the second option: Use table partitioning. The strategy will be create two partitions: Current Data and Historical Data. The partition with Current Data will be stored in SSD drives, with an excellent response time. In other hands the historical data will be stored in an old disk, with poor performance and lots of storage capacity – as the performance is not the goal here.
让我们采用第二个选项:使用表分区。 该策略将创建两个分区:当前数据和历史数据。 具有当前数据的分区将以出色的响应时间存储在SSD驱动器中。 另一方面,历史数据将存储在性能不佳且存储容量很大的旧磁盘中,因为性能不是此处的目标。
By implementing this we will be able to solve part of the problem: The performance and costs to maintain a good disk to store both current and old data. However there are other factors here:
通过执行此操作,我们将能够解决部分问题:维护良好的磁盘以存储当前数据和旧数据的性能和成本。 但是,这里还有其他因素:
- The backup is still huge 备份仍然很大
- The maintenance operations are still taking a lot of time 维护操作仍然需要很多时间
- The old disk may fail and compromise the database availability 旧磁盘可能会发生故障并损害数据库可用性
About the backup and maintenance, we can workaround by adapting the backup plan and index maintenance to the new Filegorup strategy. There’s another option for this, but we will approach this more ahead.
关于备份和维护,我们可以通过使备份计划和索引维护适应新的Filegorup策略来解决。 对此还有另一种选择,但是我们将更进一步地解决这个问题。
What about the possible disk issues? Here is where I want to reach. We can use Azure for it. How? By simply creating a file stored in the Azure Blog Storage service. This way you will have part of your database on-premises and the historical data in the cloud. Like described in the following picture:
那么可能的磁盘问题呢? 这是我想到达的地方。 我们可以使用Azure。 怎么样? 通过简单地创建存储在Azure博客存储服务中的文件。 这样,您将拥有部分本地数据库以及云中的历史数据。 如下图所示:

The concept is simple and is already used, but adapted to be a Hybrid solution. This way you will have the current data with the best performance and the old data will be store in Azure, with a not so good performance, but in a place where the cost per GB is very low, the allocated size limit is very high, the data is geo-replicated and there’s no physical disk to be maintained.
这个概念很简单,已经使用过,但已成为混合解决方案。 这样,您将拥有性能最佳的当前数据,而旧数据将以不太好的性能存储在Azure中,但是在每GB成本非常低的地方,分配的大小限制非常高,数据已进行地理复制,并且没有要维护的物理磁盘。
Looking to the table perspective, we will have the following:
从表的角度来看,我们将获得以下内容:
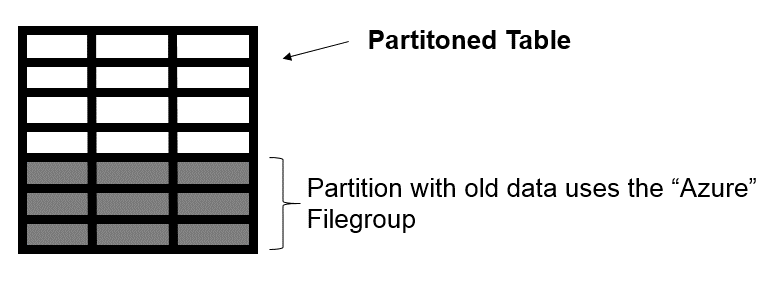
The white area represents the current data, in the partition where the respective files are stored on-premises. The gray area represents the historical data stored in a file in Azure Blob Storage.
白色区域表示在本地存储各个文件的分区中的当前数据。 灰色区域表示存储在Azure Blob存储中文件中的历史数据。
We can easily replicate this scenario…First of all we need to make sure that the credentials are created, as explained in the previous article. Having this, we are good to go ahead and create the database with a file store in the cloud:
我们可以轻松地复制这种情况……首先,我们需要确保已创建凭据,如上一篇文章中所述。 有了这个,我们很高兴继续在云中创建带有文件存储的数据库:
CREATE DATABASE [HybridTableDemo] ON PRIMARY (
NAME = N'HybridTableDemo',
filename =
N'E:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\HybridTableDemo.mdf'
),
filegroup [FGAzure] (
NAME = N'HybridTableDemoAzure',
filename =
N'https://tdcspdemo.blob.core.windows.net/dbfiles1/HybridTableDemoAzure.ndf'
)
log ON (
NAME = N'HybridTableDemo_log',
filename =
N'E:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\HybridTableDemo_log.ldf'
)
go
Now that we have the database, with the Azure file creates, we can create the partition function, partition scheme and the partitioned table:
现在我们有了数据库,并创建了Azure文件,我们可以创建分区功能,分区方案和分区表:
-- Create partition function
CREATE partition FUNCTION pfbirthdate(int) AS range LEFT FOR VALUES ( 2000 )
go
-- Create partition scheme
CREATE partition scheme psbirthdate AS partition pfbirthdate TO ([FGAzure],
[PRIMARY] )
go
CREATE TABLE dbo.birthdaytable
(
NAME VARCHAR(50) NOT NULL,
birthdate INT NOT NULL
)
ON psbirthdate(birthdate)
go
ALTER TABLE dbo.birthdaytable
ADD CONSTRAINT pk_birthdaytable PRIMARY KEY NONCLUSTERED ( NAME, birthdate )
WITH( statistics_norecompute = OFF, ignore_dup_key = OFF, allow_row_locks = on
, allow_page_locks = on) ON [PRIMARY]
go
This is a very simple example, where we have a table to store a “Name” and a birthday date as an integer. This birth date is the partition column, and all the rows with a birth day before 2000 will be “archived” in Azure.
这是一个非常简单的示例,其中我们有一个表以整数形式存储“名称”和生日。 该生日是分区列,所有生日在2000年之前的行都将在Azure中“存档”。
Now we need to test, so let’s add some data (Download the file and execute into the created database):
现在我们需要测试,因此让我们添加一些数据(下载文件并执行到创建的数据库中):
Running the following query, we can verify that the data is, in fact, spread into Azure and local drive.
运行以下查询,我们可以验证数据实际上是否已散布到Azure和本地驱动器中。
SELECT $partition.Pfbirthdate(birthdate) AS PARTITIONID,
Count(*) AS ROW_COUNT
FROM dbo.birthdaytable
GROUP BY $partition.Pfbirthdate(birthdate)
ORDER BY partitionid
With this simple strategy we were able to take advantage of Azure, saving cost with disk maintenance and stored data costs, as well as accomplish the requirement of keep the historical data, without compromise the performance.
通过这种简单的策略,我们能够利用Azure,在磁盘维护和存储数据成本方面节省成本,并满足保留历史数据的要求,而不会影响性能。
In the continuation of this article, we will see another feature that Microsoft implemented for the next version of SQL Server, to do more or less the same but in another way, with even more advantages!
在本文的续篇中,我们将看到Microsoft为下一版本SQL Server实现的另一个功能,或多或少都以相同的方式做,但具有更多的优势!
Thank you for reading 🙂
谢谢您阅读🙂
翻译自: https://www.sqlshack.com/azure-blob-storage-literally-a-hybrid-database-deployment/
azure blob















 4921
4921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









