





In this article, we will be discussing how Text Mining can be done in SQL Server. For text mining in SQL Server, we will be using Integration Services (SSIS) and SQL Server Analysis Services (SSAS). This is the last article of the Data Mining series during which we discussed Naïve Bayes, Decision Trees, Time Series, Association Rules, Clustering, Linear Regression, Neural Network, Sequence Clustering. Additionally, we discussed the way to measure the accuracy of the data mining models. In the last article, we discussed how models can be extracted from the Data query.
在本文中,我们将讨论如何在SQL Server中完成文本挖掘。 对于SQL Server中的文本挖掘,我们将使用Integration Services(SSIS)和SQL Server Analysis Services(SSAS)。 这是数据挖掘系列的最后一篇文章,在此期间我们讨论了朴素贝叶斯 , 决策树 , 时间序列 , 关联规则 , 聚类 , 线性回归 , 神经网络 , 序列聚类 。 此外,我们讨论了测量数据挖掘模型准确性的方法。 在上一篇文章中,我们讨论了如何从Data查询中提取模型。
为什么文本挖掘具有挑战性 (Why Text Mining is challenging)
During the previous discussions, we mainly discussed data mining modeling in structured relation data. However, since there is no structure to text data, there are a lot of challenges when it comes to modeling the text data. Apart from text data is unstructured, text data will have a large volume of data. Due to the different styles of writing, it may be difficult to analyze data.
在前面的讨论中,我们主要讨论了结构化关系数据中的数据挖掘建模。 但是,由于文本数据没有结构,因此在建模文本数据时会遇到很多挑战。 除了文本数据是非结构化的,文本数据还将具有大量数据。 由于写作风格不同,可能难以分析数据。
In this article, we are looking at how to overcome those challenges when performing Text Mining in SQL Server.
在本文中,我们正在研究在SQL Server中执行文本挖掘时如何克服这些挑战。
数据集 (Data Set)
Unlike the previous articles where we predominantly used AdventureworksDW as our sample database, in this article, we will be using more real-world scenarios. We will be using movie reviews data set at https://www.kaggle.com/nltkdata/movie-review. In this dataset, there are 1,000 each positively and negatively rated movies. Positively rated movies are in a folder named pos whereas negatively rated movies are in a folder called neg. Every review is in a text file as shown in the below screenshot.
与之前的文章主要使用AdventureworksDW作为示例数据库不同,在本文中,我们将使用更多实际场景。 我们将使用https://www.kaggle.com/nltkdata/movie-review上的电影评论数据集。 在此数据集中,每个有1,000部正面和负面评价的电影。 评级为正的电影在名为pos的文件夹中,而评级为负的电影在名为neg的文件夹中。 每个评论都在一个文本文件中,如下面的屏幕快照所示。
Every review is saved in a text file and that means that there is a total of 2,000 files, 1,000 for positive reviews and 1000 for negative reviews.
每个评论都保存在一个文本文件中,这意味着总共有2,000个文件,正面评论为1,000个,负面评论为1,000个。
Our first task is to extract these film reviews from the following table named Cinema.
我们的首要任务是从下表中的Cinema提取这些电影评论。
In the above table, FileID is configured for the auto-increment column and FileName is used to save the actual file name. The content column will be used to store the content of the review whereas the review category, negative or positive is stored in the Class column.
在上表中,为自动递增列配置了FileID ,并使用FileName保存了实际的文件名。 “ 内容”列将用于存储评论的内容,而“否”或“肯定”评论类别将存储在“ 类别”列中。
To extract all the 2,000 files to the Cinema table, the following SSIS is used.
要将所有2,000个文件提取到Cinema表中,请使用以下SSIS。
Execute SQL Task is used to truncate the Cinema table to facilitate multiple executions. For each loop container is used to traverse through the folder and get the file name. Following is the data flow task to write one file content to the table.
执行SQL任务用于截断Cinema表以促进多次执行。 对于每个循环容器,它都用于遍历文件夹并获取文件名。 以下是将一个文件内容写入表的数据流任务。
In this derived column is used to get the review class, positive or negative. Since files full path is D:\FilmReviews\review_polarity\txt_sentoken\neg\cv000_29416.txt in format, the last folder name is derived using following SSIS code to get the class.
在此派生列中,用于获取评论类(正面或负面)。 由于文件的完整路径为D:\ FilmReviews \ review_polarity \ txt_sentoken \ neg \ cv000_29416.txt ,因此,使用以下SSIS代码派生最后的文件夹名称以获取该类。
REVERSE(SUBSTRING(REVERSE(@[User::FN]),FINDSTRING(REVERSE(@[User::FN]),”\\”,1) + 1,3))
REVERSE(SUBSTRING(REVERSE(@ [User :: FN]),FINDSTRING(REVERSE(@ [User :: FN]),“ \\”,1)+ 1,3))
@[User::FN] is the variable for the Filename.
@ [User :: FN]是文件名的变量。
The following screenshot shows the sample data set for the cinema table after data is extracted to it from the text files.
下面的屏幕截图显示了从文本文件中提取数据后,电影院表的示例数据集。
术语提取 (Term Extraction)
The next operation is Term Extraction for which we will be using Term Extraction transformation control in SSIS. In this control, there are three important configurations, Term Extraction Exclusion and Advanced. Detailed discussion on this can be found at Term Extraction Transformation in SSIS article.
下一个操作是术语提取,我们将在SSIS中使用术语提取转换控制。 在此控件中,有三个重要的配置,术语提取排除和高级。 有关此问题的详细讨论,请参见SSIS中的术语提取转换 。
For the Term Extraction, we will be using the Cinema table as the source of data as presented in the below screenshot.
对于术语提取,我们将使用Cinema表作为数据源,如下面的屏幕快照所示。
Next is configuring the exclusion list. Words like, the, a, and, will not make any value. Therefore, those words should be eliminated for better results and better performance.
接下来是配置排除列表。 像、、、和等词将没有任何价值。 因此,应删除这些词以取得更好的结果和更好的性能。
The exclusion table contains an only column that is ExclusionTerm. Next is to configure Advanced options as shown below.
排除表仅包含ExclusionTerm列。 接下来是配置高级选项,如下所示。
We have used TFIDF, Term Frequency Inverse Document Frequency for the score type. TFIDF of a selected term t = (frequency of t) * log ( (number of rows in Input) / (number of rows having t) ) .
我们已将TFIDF(术语频率倒排文档频率)用于评分类型。 选定项t的 TFIDF =(t的频率)* log((Input中的行数)/(t的行数)) 。
Following is the output of the above transformation stored in a table named, TermScore.
以下是存储在名为TermScore的表中的上述转换的输出。
From the above data set, we can identify what are the most important terms as the high value of a score means it has higher importance.
从以上数据集中,我们可以确定最重要的术语,因为分数的高值意味着其重要性更高。
术语查询 (Term Lookup)
After finding the terms of the entire data set, next is to find out how each document has each term. For that, we will be utilizing the Term Lookup transformation in SSIS.
找到整个数据集的术语之后,接下来是找出每个文档的每个术语的方式。 为此,我们将利用SSIS中的术语查找转换。
TermScore is used as a reference table as presented in the above screenshot.
TermScore用作上述屏幕快照中提供的参考表。
Then we will be doing a term lookup against the initial cinema dataset. This will give you the number of occurrences for terms against each document that will be saved in the DocumentTerms tables as shown in the below screenshot.
然后,我们将针对初始的电影数据集进行术语查找。 这将为您提供每个文档中术语的出现次数,这些术语将保存在DocumentTerms表中,如下面的屏幕快照所示。
期限文档事件矩阵 (Term Document Incident Matrix)
Term Document Incident Matrix is a basic matrix that is used for modeling in Text Mining. Text Mining in SQL Server does not provide off the shelf option to create a term document incident matrix.
术语文档事件矩阵是用于文本挖掘中建模的基本矩阵。 SQL Server中的文本挖掘没有提供现成的选项来创建术语文档事件矩阵。
The following screenshot shows the Term Document Incident Matrix for each file.
以下屏幕截图显示了每个文件的术语文档事件矩阵。
For example, FileID 1 has 3 terms of movie and 1 term for film and the FileID 2 has 5 terms of movie and 8 terms of character.
例如,FileID 1具有3个电影术语和1个电影术语,而FileID 2具有5个电影术语和8个字符术语。
The above matrix is created from the following stored procedure.
上面的矩阵是根据以下存储过程创建的。
CREATE PROCEDURE [dbo].[usp_TermDocumentIncidenceMatrix]
AS
BEGIN
SET NOCOUNT ON
IF EXISTS (
SELECT 1
FROM sys.tables
WHERE NAME = 'TermDocumentIncidenceMatrix'
)
DROP TABLE TermDocumentIncidenceMatrix
DECLARE @Statment AS VARCHAR(8000)
SET @Statment = ' '
SELECT TOP 250 @Statment = @Statment + ' [' + [Term] + '] float,'
FROM [TestDB].[dbo].[TermScore]
ORDER BY score DESC
SET @Statment = 'CREATE TABLE TermDocumentIncidenceMatrix (FileID INT PRIMARY KEY,' + @Statment
SET @Statment = SUBSTRING(@Statment, 1, LEn(@Statment) - 1) + ')'
EXECUTE (@Statment)
SET @Statment = 'INSERT INTO dbo.TermDocumentIncidenceMatrix SELECT [FileID]' + REPLICATE(',0', 250) + ' FROM [dbo].[Cinema]'
EXECUTE (@Statment)
DECLARE @Term VARCHAR(4000)
DECLARE @stat VARCHAR(4000)
SELECT TOP 250 [Term]
,0 STATUS
INTO #Terms
FROM [TestDB].[dbo].[TermScore]
ORDER BY score DESC
WHILE (
SELECT COUNT(1)
FROM #Terms
WHERE STATUS = 0
) > 0
BEGIN
SELECT TOP 1 @Term = [Term]
FROM #Terms
WHERE STATUS = 0
SELECT @stat = 'UPDATE TDIM SET [' + @Term + ']= Dt.Frequency FROM TermDocumentIncidenceMatrix TDIM INNER JOIN [dbo].[DocumentTerms] DT ON TDIM.FileID = DT.FileID WHERE Dt.[Term] = ''' + @Term + ''''
EXECUTE (@stat)
UPDATE #Terms
SET STATUS = 1
WHERE [Term] = @Term
END
END
GO
For the above procedure, 250 terms of highest scores are used for the Term Document Incident Matrix. Now we have prepared the relevant data set and ready to create the data models for Text Mining in SQL Server.
对于上述过程,术语文档事件矩阵使用了250个得分最高的术语。 现在,我们已经准备了相关的数据集,并准备为SQL Server中的文本挖掘创建数据模型。
关联挖掘模型 (Association Mining Model)
Let us look at what are the common terms that are used. For this, we will be using the Association Mining rule. The following Data source view is used for the association rule mining.
让我们看看使用了哪些常用术语。 为此,我们将使用关联挖掘规则。 以下数据源视图用于关联规则挖掘。
Since there is an already foreign key defined between Cinema and DocumentTerms table, there is no need to define the relationship in SSAS modeling.
由于在Cinema和DocumentTerms表之间已经定义了外键,因此无需在SSAS建模中定义关系。
In this data set, Cinema is selected as the case table whereas the documentterms table is selected as the nested table.
在此数据集中,Cinema被选择为案例表,而documentterms表被选择为嵌套表。
The following are the configuration of Key, Input and Prediction columns.
以下是“关键字”,“输入”和“预测”列的配置。
Let us look at the associate rule outcomes after processing the data mining model.
让我们看一下处理数据挖掘模型后的关联规则结果。
The above screenshot shows that when the text life and character exist the class is positive with a probability of 63.5%.
上面的屏幕截图显示,当存在文字和字符时,该类别为正,概率为63.5%。
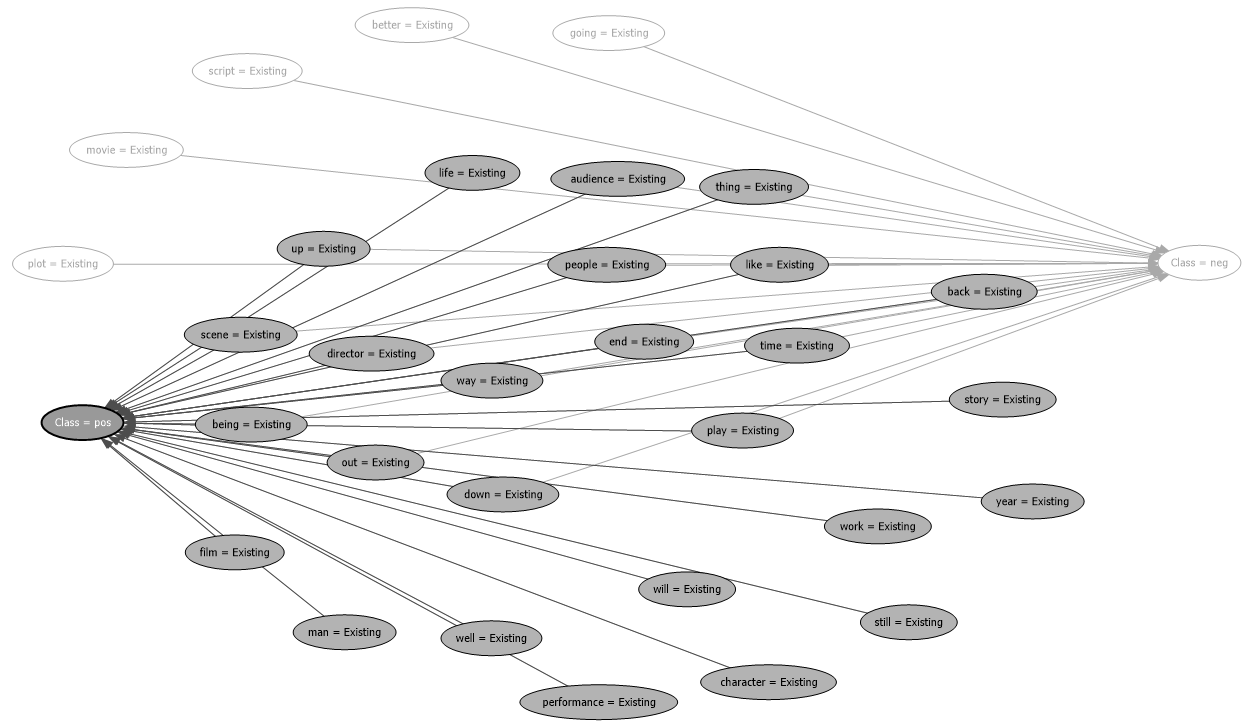
The above diagram shows the relationship diagram for the positive class.
上图显示了阳性类别的关系图。
分类挖掘模型 (Classification Mining Model)
For the Classification model, we will look at the TermDocumentIncidenceMatrix table. In this modeling, classification variable is class, pos or neg. Since it is in the Cinema table we need to create a view. For this classification model, we will be using a view that is combined with two tables TermDocumentIncidenceMatrix and Cinema as shown in the below script.
对于分类模型,我们将查看TermDocumentIncidenceMatrix表。 在此建模中,分类变量是class,pos或neg。 由于它在Cinema表中,因此我们需要创建一个视图。 对于此分类模型,我们将使用结合两个表TermDocumentIncidenceMatrix和Cinema的视图,如以下脚本所示。
CREATE VIEW [dbo].[vw_Cinema]
AS
SELECT dbo.TermDocumentIncidenceMatrix.*, dbo.Cinema.Class
FROM dbo.Cinema INNER JOIN
dbo.TermDocumentIncidenceMatrix
ON dbo.Cinema.FileID = dbo.TermDocumentIncidenceMatrix.FileID
GO
This view is added to data source view.
该视图已添加到数据源视图。
Like we did in the accuracy measurement, we will create four models for classification, Decision Trees, Naive Bayes, Neural Network and Logistics Regression as shown below. In all these models, the classification or prediction column is the class.
就像我们在准确性测量中所做的一样,我们将创建四个分类模型,决策树,朴素贝叶斯,神经网络和物流回归,如下所示。 在所有这些模型中,分类或预测列都是类别。
Please note that all the terms will have continuous data type and better if we can convert them to a discrete data type.
请注意,所有术语都将具有连续数据类型,如果我们可以将它们转换为离散数据类型,则更好。
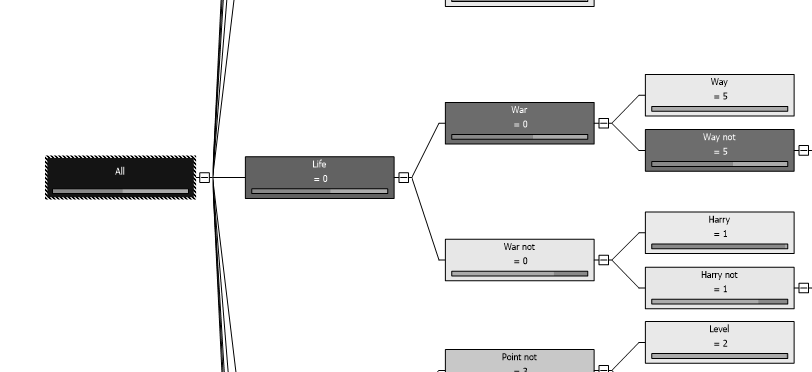
Let us look at few classification models and the following is the model for decision trees.
让我们看几个分类模型,以下是决策树模型。
Let us look at the accuracies of these models from the confusion matrix as presented below.
让我们从如下所示的混淆矩阵中查看这些模型的准确性。
Let us calculate the accuracy of each model.
让我们计算每个模型的准确性。
| Algorithm | Accuracy |
| Decision Trees | 56.00 % |
| Naïve Base | 57.83 % |
| Neural Network | 60.67 % |
| Logistic Regression | 61.33 % |
算法 | 准确性 |
决策树 | 56.00% |
幼稚基地 | 57.83% |
神经网络 | 60.67% |
逻辑回归 | 61.33% |
For this data set, Logistic Regression is a better algorithm.
对于此数据集,逻辑回归是一种更好的算法。
结论 (Conclusion)
In this last article of the series, we discussed Text Mining in SQL Server. We have used SSIS and SSAS tools in the Microsoft BI family. SSIS is used to Extract terms and perform term lookups. From SSAS, we have used Association and classification techniques to perform text mining.
在本系列的最后一篇文章中,我们讨论了SQL Server中的文本挖掘。 我们在Microsoft BI系列中使用了SSIS和SSAS工具。 SSIS用于提取术语并执行术语查找。 从SSAS,我们已使用关联和分类技术来执行文本挖掘。















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









