





dta乱码
介绍 ( Introduction )
In a previous chapter, we learned how to use the Tuning Advisor to analyze queries and receive recommendations about indexes, partitions and statistics. In this new chapter, we will learn how to use the command line tool called DTA. The DTA is the command line of the Tuning Advisor.
在上一章中 ,我们学习了如何使用Tuning Advisor分析查询并接收有关索引,分区和统计信息的建议。 在这一新的章节中,我们将学习如何使用称为DTA的命令行工具。 DTA是Tuning Advisor的命令行。
The DTA is a very powerful tool that can be used to automate some tuning tasks. It can be used combined with the SQL Agent, SSIS, or customized and external tools like programs made in C# or Java.
DTA是一个非常强大的工具,可用于自动执行某些调整任务。 它可以与SQL Agent,SSIS或自定义的外部工具(如C#或Java程序)结合使用。
In this article, we will show how to use this tool.
在本文中,我们将展示如何使用此工具。
要求 ( Requirements )
- The Tuning Advisor, which is included in all the SQL Server Editions except in the Express editions Tuning Advisor,除Express版本外,所有SQL Server版本都包含
- We are using SQL Server 2014, but earlier versions can be used 我们正在使用SQL Server 2014,但是可以使用早期版本
select SERVERPROPERTY('Edition') AS Edition- You will also need the AdventureWorks database installed. In our example, the AdventureWorks2014 is being used 您还将需要安装AdventureWorks数据库。 在我们的示例中,正在使用AdventureWorks2014
入门 ( Getting started )
DROP INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person] GOSELECT BusinessEntityID, FirstName, MiddleName, LastName from Person.Person where LastName = 'Allison' SELECT COUNT(*) FROM Person.PersonNow open the command prompt (cmd):
现在打开命令提示符(cmd):
Figure 1. The command Prompt 图1.命令提示符 Run this query:
运行此查询:
dta -S ServerName -E -D AdventureWorks2014 -if c:\script2\input.sql -F -of c:\script2\scriptrec.sql -A 0 -fa IDX_IV -s Mysession
dta -S ServerName -E -D AdventureWorks2014 -if c:\ script2 \ input.sql -F -of c:\ script2 \ scriptrec.sql -A 0 -fa IDX_IV -s Mysession
We are now going to explain the arguments used.
现在,我们将解释所使用的参数。
-S – ServerName is used to connect to the SQL Server. ServerName is the name of the SQL Server instance. If your instance is not a default instance, use Servername\Instancename.
-S – ServerName用于连接到SQL Server。 ServerName是SQL Server实例的名称。 如果您的实例不是默认实例,请使用Servername \ Instancename。
-E – This argument is used to authenticate using Windows Authentication. It will use the current Windows user to connect to the database. If you want to use SQL Authentication, you can use the argument –U and specify the SQL Server Login and –P with the SQL Server Login password. For example, if the SQL Login is John and the password is M&%#1!aa, you will use the following arguments:
-E –此参数用于使用Windows身份验证进行身份验证。 它将使用当前的Windows用户连接到数据库。 如果要使用SQL身份验证,则可以使用参数–U并指定SQL Server登录名和–P以及SQL Server登录名密码。 例如,如果SQL登录名是John,密码是M&%#1!aa,则将使用以下参数:
-U John –P M&%#1!aa
-U John –P M&%#1 !aa
-D – Is used to specify the SQL Server database. In this example, the AdventureWorks2014 is used. If you want to set multiple databases, you can use the following arguments:
-D –用于指定SQL Server数据库。 在此示例中,使用AdventureWorks2014。 如果要设置多个数据库,则可以使用以下参数:
-D databasename1,databasename2,databasename3
-D databasename1 ,databasename2,databasename3
–if – This argument is used to specify the Workload file. We created a file in the step 2. This Workload file can be a .sql file like the one created in step 2 or it can be a trace file (see our article A great tool to create SQL Server Indexes for more information about trace files). IF means input file.
– 如果 –此参数用于指定工作负载文件。 我们在步骤2中创建了一个文件。该工作负载文件可以是.sql文件(类似于在步骤2中创建的文件),也可以是跟踪文件(有关跟踪文件的更多信息,请参阅文章“创建SQL Server索引的绝佳工具”)。 )。 IF表示输入文件。
-F – This argument is used to overwrite an existing output file.
-F –此参数用于覆盖现有的输出文件。
–of – This argument is used to specify the output path and file with the recommendations like indexes, partitions or statistics. In this example, we are storing the recommendations in the c:\script2\scriptrec.sql path. OF means output file.
– 个 –该参数用于指定输出路径和文件,并带有索引,分区或统计信息之类的建议。 在此示例中,我们将建议存储在c:\ script2 \ scriptrec.sql路径中。 OF表示输出文件。
-A – This is used to limit the time for tuning in minutes. If the workload is big, it can take a lot time to analyze the information. It is recommended to limit the time if the workload is high. Otherwise, the analysis will take forever. By default, the value is 0 which is an unlimited time.
-A –用于限制调整时间,以分钟为单位。 如果工作量很大,则可能需要很多时间来分析信息。 如果工作量很大,建议限制时间。 否则,分析将永远进行。 默认情况下,该值为0,这是无限时间。
–fa – When the workload is big, it is a good practice to filter by type of objects to check. In this example, we are using IDX_IV, which means index and index view. IDX means index only and IV index view only. Finally, the option NCL_IDX means non-cluster index only.
– fa –当工作量很大时,最好根据检查的对象类型进行过滤。 在此示例中,我们使用IDX_IV,这意味着索引和索引视图。 IDX仅表示索引,仅表示IV索引视图。 最后,选项NCL_IDX仅表示非群集索引。
-s – Is used to assign a session name.
-s –用于分配会话名称。
If you run the command line and everything is OK, you will receive a message that tuning session is successfully created:
如果您运行命令行并且一切正常,则会收到一条消息,说明已成功创建调整会话:
Figure 2. The command line results 图2.命令行结果 Once executed your command you can check the output file. In this example, the output file is the scriptrec.sql file:
执行命令后,您可以检查输出文件。 在此示例中,输出文件是scriptrec.sql文件:
Figure 3. 图3. The DTA Command line recommendation DTA命令行建议 - –– rlrl ALL to include all the reports. You can use the argument ALL包括所有报告。 您可以使用参数–– rlrl STMT_COST to see the statement cost report and –STMT_COST查看报表成本报告,以及– rlrl EVT_FREQ for the event frequency report. For a complete list of all the reports available, check the references.EVT_FREQ查看事件频率报告。 有关所有可用报告的完整列表,请检查参考。
In order to run the reports, run this query:
为了运行报告,请运行此查询:
dta -S ServerName -E -D AdventureWorks2014 -if c:\script2\input.sql -F -of c:\script2\scriptrec.sql -A 0 -fa IDX_IV -s Mysession2 –rl ALL
dta -S ServerName -E -D AdventureWorks2014 -if c:\ script2 \ input.sql -F -of c:\ script2 \ scriptrec.sql -A 0 -fa IDX_IV -s Mysession2 – rl ALL
Once you run you will have a message similar to this one:
运行后,您将收到类似于以下消息:
Figure 4. The report message 图4.报告消息 The command line will indicate where the reports were stored. The reports are stored in a txt file:
命令行将指示报告的存储位置。 报告存储在txt文件中:
Figure 5. 图5. The report file 报告文件 If you open the file, you will notice that it is an XML file:
如果打开文件,您会注意到它是一个XML文件:
Figure 6. The xml report information 图6. xml报告信息 If you have XML experience, it is very easy to read the XML file. The first report name is StatementCostReport. This report says that the query SELECT COUNT(*) from person.person will improve 32.38 % with the recommendation.
如果您有XML经验,那么阅读XML文件非常容易。 第一个报告名称是StatementCostReport。 该报告说,来自person.person的查询SELECT COUNT(*)使用该建议将提高32.38%。
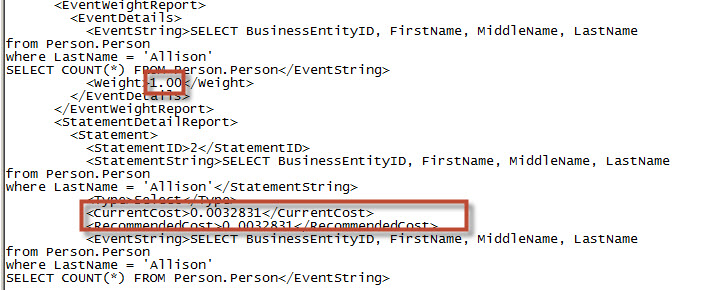
The second report in the same file is the Event Weight Report. It shows the weight of the queries, which is used to measure the frequency of use. The more frequency, the more recommendable to create the index. The other report is the Statement Detail Report. It shows the cost of the query. SQL Server measure the performance using the cost. The record shows the current cost and the recommended cost:
同一文件中的第二个报告是事件权重报告。 它显示查询的权重,用于衡量使用频率。 频率越高,创建索引越可取。 另一个报告是对帐单明细表。 它显示了查询的费用。 SQL Server使用成本来衡量性能。 该记录显示当前成本和建议成本:
Figure 7. More xml reports. 图7.更多xml报告。 select 'select count(*) as count'+[TABLE_NAME]+' from '+[TABLE_SCHEMA]+'.'+[TABLE_NAME] from [INFORMATION_SCHEMA].[TABLES]The query will generate a set of queries to get the number of rows of all the tables of a database:
该查询将生成一组查询,以获取数据库所有表的行数:
Figure 8. The queries generated 图8.生成的查询 If you copy the queries and run them, you will have the number of rows of each table:
如果复制查询并运行它们,则每个表的行数为:
Figure 9. The number of rows per table 图9.每个表的行数 - The tables with more than 100,000 rows are [Sales].[SalesOrderDetail] and [production].[TransactionHistory] 具有超过100,000行的表是[Sales]。[SalesOrderDetail]和[production]。[TransactionHistory]
Run this query to Analyze just the 2 tables detected in step 17:
运行此查询以仅分析在步骤17中检测到的2个表:
dta -S ServerName -E -D AdventureWorks2014 -if c:\script2\input.sql -F -of c:\script2\scriptrec3.sql -A 0 -fa IDX_IV -s Mysession21 -Tl [AdventureWorks2014].[Sales].[SalesOrderDetail],[AdventureWorks2014].[production].[TransactionHistory]
dta -S ServerName -E -D AdventureWorks2014 -if c:\ script2 \ input.sql -F -of c:\ script2 \ scriptrec3.sql -A 0 -fa IDX_IV -s Mysession21 -Tl [ Adventure W orks2014 ]。[销售]。[SalesOrderDetail],[ Adventure W orks2014 ]。[生产]。[TransactionHistory]
As you can see, you need to specify the database name, schema name, and the table name, and separate each table by commas.
如您所见,您需要指定数据库名称,架构名称和表名称,并用逗号分隔每个表。
其他常见论点 ( Other common arguments )
-a – If you want to apply the recommendations directly, you can use this argument, however it is not recommended. It is good to analyze the indexes before applying them. The indexes improve the performance in several cases, but it is a lot of work to maintain them and an excessive number of indexes can decrease the performance.
-a –如果要直接应用建议,则可以使用此参数,但是不建议使用。 最好在应用索引之前分析一下索引。 索引在某些情况下可以提高性能,但是要维护它们需要进行大量工作,并且过多的索引会降低性能。
-B – The recommendations usually need a lot of space. It is recommended to limit the maximum number of megabytes for the recommendations. For example, if you want to limit the recommendations to 500 MB, the argument will be –B 500.
-B –建议通常需要很多空间。 建议限制建议的最大兆字节数。 例如,如果要将建议限制为500 MB,则参数为–B 500。
For a complete list of all the arguments, see the references.
有关所有参数的完整列表,请参见参考。
典型错误 ( Typical errors )
A typical error message of the DTA is:
DTA的典型错误消息是:
Network Error Message:
网络 错误消息:
A network-related or instance-specific error occurred while establishing a connection to SQL Server. The server was not found or was not accessible. Verify the instance name is correct and that SQL Server is configured to allow remote connections. (provider: Named Pipes Provider, error: 40 – Could not open a connection to SQL Server)
建立与SQL Server的连接时发生与网络相关或特定于实例的错误。 服务器未找到或无法访问。 验证实例名称正确,并且已将SQL Server配置为允许远程连接。 (提供者:命名管道提供程序,错误:40 –无法打开与SQL Server的连接)
The network path was not found
找不到网络路径
Possible problems:
可能的 问题:
If you receive this error, verify:
如果收到此错误,请验证:
- That the instance name was written correctly. 实例名称已正确写入。
- That the SQL Server Service is started. SQL Server服务已启动。
That you have access to SQL Server.
您有权访问SQL Server。
The existing session name:
现有会话名称:
Session ‘sessionName’ already exists on the server. Please provide a unique session name.
服务器上已经存在会话“ sessionName”。 请提供一个唯一的会话名称。
Possible problems:
可能的问题:
If the session name already exists, specify another name for the argument –s and specify a new name.
如果会话名称已经存在,请为参数-s指定另一个名称,然后指定一个新名称。
结论 ( Conclusion )
In this chapter, we learned how to use the DTA. The DTA is a command line tool that is used to recommend indexes, partitions and statistics based on queries.
在本章中,我们学习了如何使用DTA。 DTA是一种命令行工具,用于根据查询推荐索引,分区和统计信息。
翻译自: https://www.sqlshack.com/dta-a-great-tool-to-automate-indexes/
dta乱码















 6591
6591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









