





In this article, we will briefly explain the SUBSTRING function and then focus on performance tips about it.
在本文中,我们将简要解释SUBSTRING函数,然后重点介绍有关它的性能提示。
SQL Server offers various built-in functions and these functions make complicated calculations easier for us. When we use these functions in the SELECT statement, performance impacts are mostly acceptable. However, scalar functions can affect query performances negatively when it uses after the WHERE clauses. The following rule is generally accepted as a performance practice to improve query performances.
SQL Server提供了各种内置函数 ,这些函数使我们更容易进行复杂的计算。 当我们在SELECT语句中使用这些功能时,性能影响通常是可以接受的。 但是,标量函数在WHERE子句之后使用时,可能会对查询性能产生负面影响。 以下规则通常被视为提高查询性能的一种性能实践。
- Note: Don’t use scalar-valued functions in the WHERE clause注意:不要在WHERE子句中使用标量值函数
The main idea behind this principle is, SQL Server can not know the result of the function without executing the scalar function. Therefore, SQL Server must perform the function individually for each row to find qualified data on the execution time. So, the data engine will read the entire index pages or the entire table rows so it causes more I/O activity.
该原理背后的主要思想是,SQL Server如果不执行标量函数就无法知道函数的结果。 因此,SQL Server必须为每一行单独执行该功能,以在执行时查找合格的数据。 因此,数据引擎将读取整个索引页或整个表行,从而导致更多的I / O活动。
SUBSTRING function is one of the built-in function and that helps to obtain a particular character data of the text data in the queries. This function is widely used by database developers in the queries, for this reason, we will focus on performance details of this function.
SUBSTRING函数是内置函数之一,它有助于获取查询中文本数据的特定字符数据。 数据库开发人员在查询中广泛使用此功能,因此,我们将重点介绍此功能的性能细节。
句法 (Syntax)
This is the syntax of the Substring() function – SUBSTRING(string, start, length)
这是Substring()函数的语法– SUBSTRING(字符串,开始,长度)
- string: The string expression, from which substring will be obtainedstring:字符串表达式,将从中获取子字符串
- start: The starting position of the value in which the substring will be extractedstart:将在其中提取子字符串的值的起始位置
- length: This parameter specifies how many characters will be extracted after the starting positionlength:此参数指定在起始位置之后将提取多少个字符
Now we will make a very straightforward example :
现在,我们将举一个非常简单的示例:
SELECT SUBSTRING('SAVE THE GREEN',6,3)
The following illustration represents how this function works for the above example.
下图说明了以上示例的功能。
This function also can be implemented with the SELECT statement that retrieves data from the tables. The following query returns a certain part of the PurchaseOrderNumber column values. In this usage of the SUBSTRING function, it starts to extract from the second character of the column values and continues until the seventh character. So that it extracts five characters as we specified in the length parameter of the function.
也可以使用SELECT语句来实现此功能,该SELECT语句从表中检索数据。 以下查询返回PurchaseOrderNumber列值的特定部分。 在SUBSTRING函数的这种用法中,它开始从列值的第二个字符中提取并继续到第七个字符。 这样就提取了我们在函数的length参数中指定的五个字符。
SELECT PurchaseOrderNumber,
SUBSTRING(PurchaseOrderNumber, 2, 5)
AS NewPOrderNumber
FROM Sales.SalesOrderHeader
WHERE SalesOrderID BETWEEN 43682 AND 43694
You can direct to this article, Substring function overview to learn more interesting facts about the Substring() function.
您可以直接转至本文Substring函数概述,以了解有关Substring()函数的更多有趣事实。
Now, let’s talk about the performance details of this function.
现在,让我们讨论一下该功能的性能细节。
先决条件 (Prerequisites)
In the following examples, we will use the AdventureWorks sample database and use an enlarging script (Create Enlarged AdventureWorks Tables ) which helps to create a large amount of data. When we execute this script it will create the SalesOrderDetailEnlarged and SalesOrderHeaderEnlarged tables under the Sales schema.
在以下示例中,我们将使用AdventureWorks示例数据库,并使用一个放大脚本( Create Enlarged AdventureWorks Tables ),该脚本有助于创建大量数据。 当我们执行此脚本时,它将在Sales模式下创建SalesOrderDetailEnlarged和SalesOrderHeaderEnlarged表。
计算标量运算符 (Compute Scalar Operator)
Compute scalar operator performs computation and returns the value of this computation. This operator represented with the following image on the execution plans. The property detail of this operator gives detailed information about the performed function to us.
计算标量运算符执行计算并返回此计算的值。 该操作员在执行计划中用以下图像表示。 该运算符的属性详细信息向我们提供了有关已执行功能的详细信息。
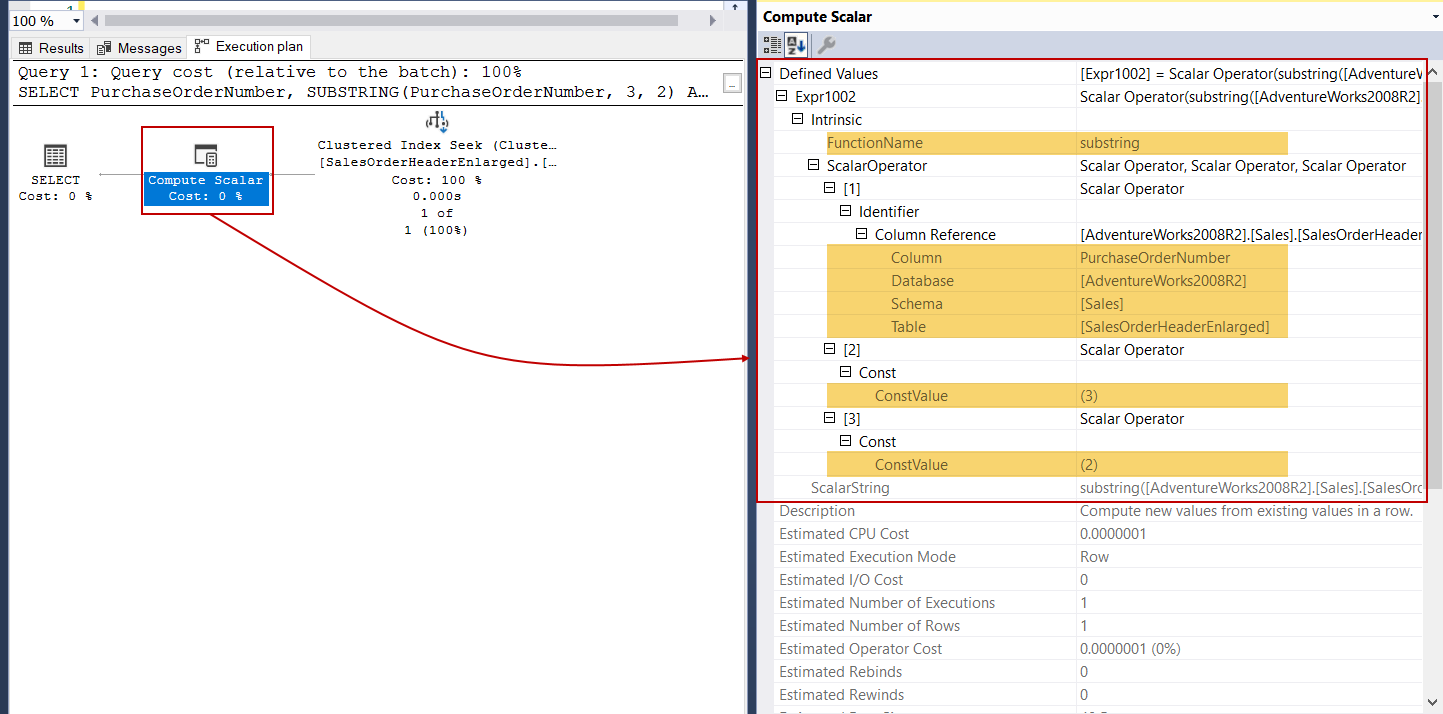
Now we will execute the following query and analyze the property details of the compute scalar operator. Defined Values subattribute shows every detail about the performed scalar-valued function for the following query on the execution plan.
现在,我们将执行以下查询并分析计算标量运算符的属性详细信息。 “定义值”子属性显示有关执行计划中以下查询的已执行标量值函数的每个详细信息。
SELECT PurchaseOrderNumber,
SUBSTRING(PurchaseOrderNumber, 3, 2)
AS NewPOrderNumber
FROM Sales.SalesOrderHeaderEnlarged
WHERE SalesOrderID = 43682
The LEFT function extracts the given character starting from the left side of the input string. Now we will execute the following query that includes the LEFT function and analyze the execution plan.
LEFT函数从输入字符串的左侧开始提取给定的字符。 现在,我们将执行以下包含LEFT函数的查询,并分析执行计划。
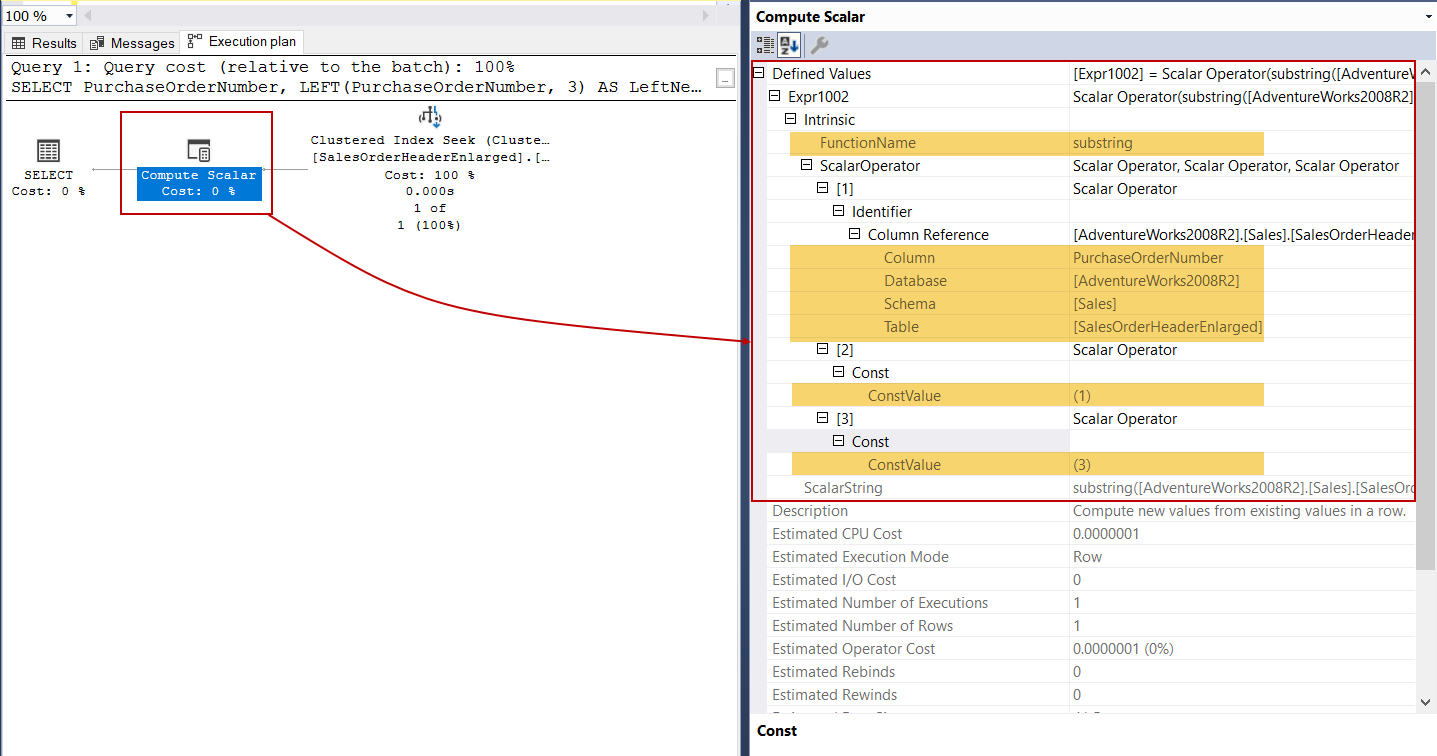
As we can see clearly, the LEFT function is an implementation of the SUBSTRING function. Obviously, using the SUBSTRING function to compute the LEFT function is a very logical approach. For example, the following two functions will return the same values.
我们可以清楚地看到,LEFT函数是SUBSTRING函数的实现。 显然,使用SUBSTRING函数计算LEFT函数是一种非常合乎逻辑的方法。 例如,以下两个函数将返回相同的值。
SELECT PurchaseOrderNumber,
SUBSTRING(PurchaseOrderNumber, 1, 3)
AS NewPOrder,
LEFT(PurchaseOrderNumber, 3)
AS LeftNewPOrder
FROM Sales.SalesOrderHeaderEnlarged
WHERE SalesOrderID = 43682
The RIGHT function performs the opposite of the LEFT function and it extracts the given character starting from the right side of the input string. However, it doesn’t use the SUBSTRING function on its calculations. Now we will execute the following query and analyze the execution plan.
RIGHT函数执行与LEFT函数相反的操作,它从输入字符串的右侧开始提取给定字符。 但是,它在计算中不使用SUBSTRING函数。 现在,我们将执行以下查询并分析执行计划。
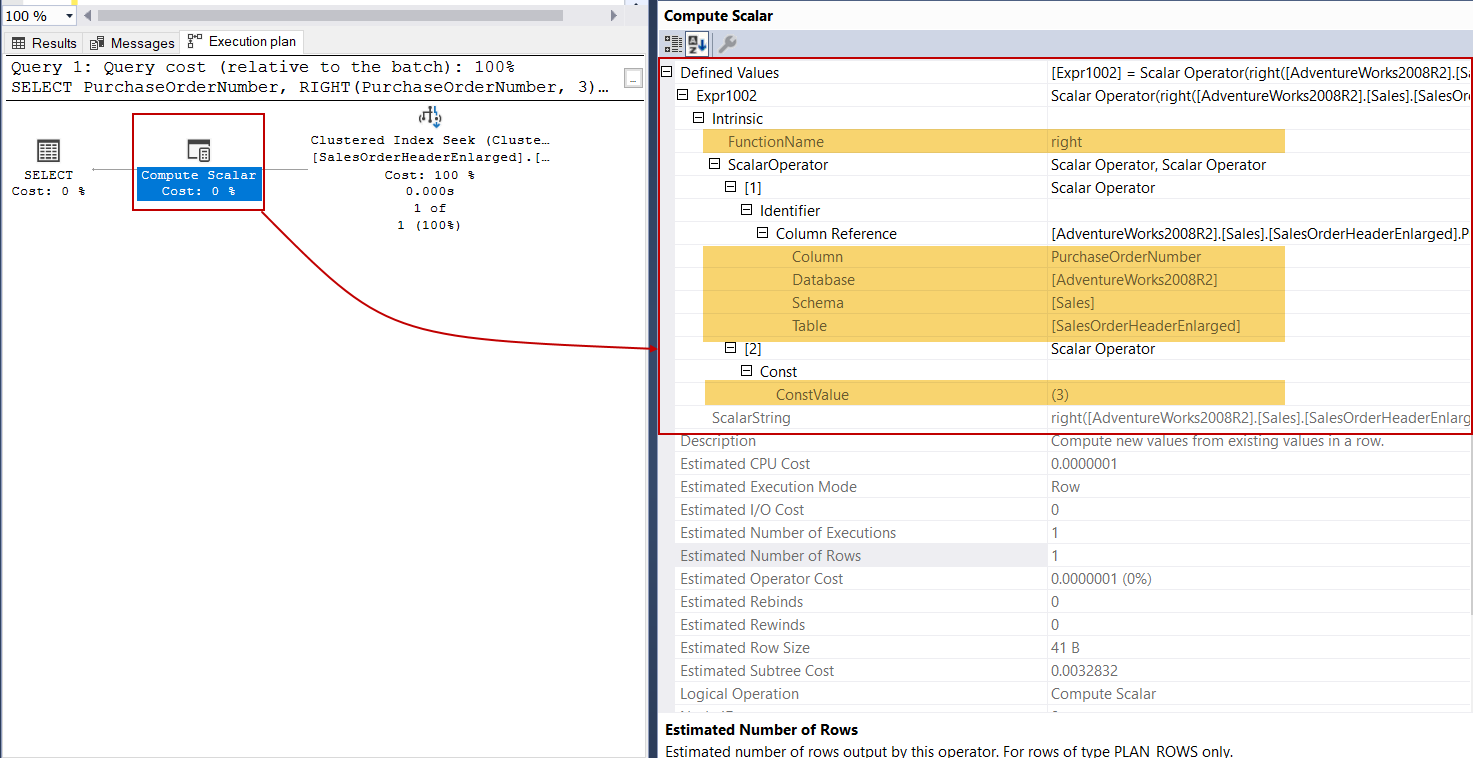
This execution plan has shown us that the RIGHT function characteristic differs from the LEFT function because the FunctionName property indicates the right value.
该执行计划向我们展示了RIGHT函数的特性不同于LEFT函数,因为FunctionName属性指示正确的值。
如何提高SUBSTRING函数的性能? (How to improve the performance of the SUBSTRING function?)
Now, let’s remember and open up the subject that we stated at the beginning of the article about the scalar-valued functions.
现在,让我们记住并打开我们在本文开头所述的有关标量值函数的主题。
- Note: Don’t use scalar-valued functions in the WHERE clause注意:不要在WHERE子句中使用标量值函数
At first, we will execute the following query and analyze the execution plan carefully.
首先,我们将执行以下查询并仔细分析执行计划。
SELECT AccountNumber,
PurchaseOrderNumber
FROM Sales.SalesOrderHeaderEnlarged
WHERE SUBSTRING(AccountNumber, 4, 4) = '4020'
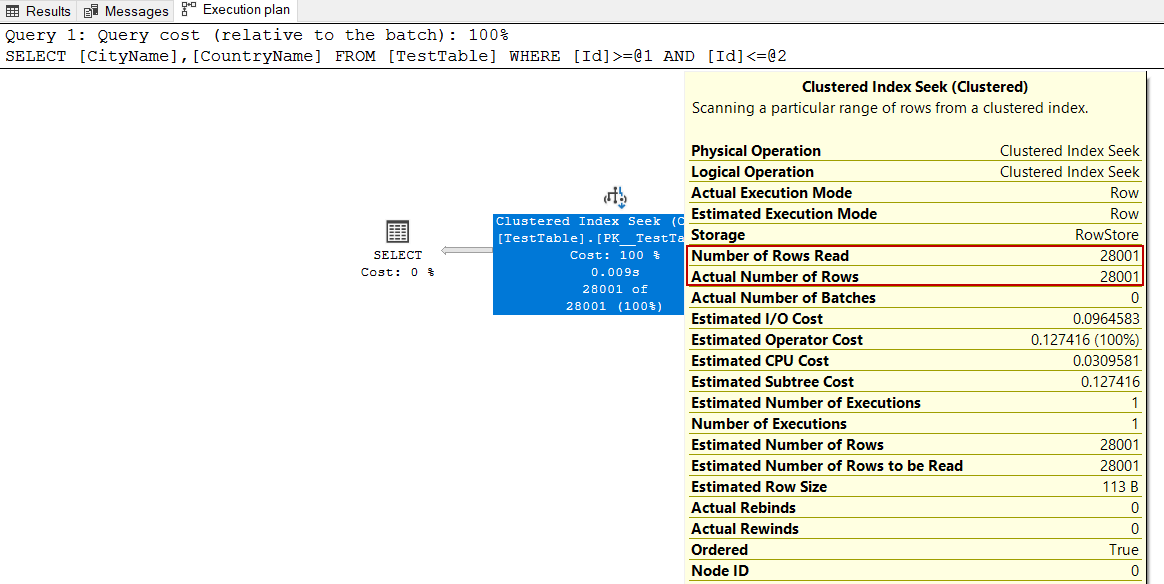
The Number of Rows Read option shows how many rows have been read by the operator and for this example Clustered Index Scan operator has read the whole table and this situation is not a good option for the performance. Actual Number of Rows indicates how many rows transferred to the next operator. For this execution plan, this value is 148434.
“ 读取的行数”选项显示操作员已读取了多少行,对于本示例,“ 聚集索引扫描”操作员已读取了整个表,这种情况对于性能而言不是一个好的选择。 实际行数指示转移到下一个运算符的行数 。 对于此执行计划,此值为148434。
When we right-click on the Clustered Index Scan operator and expand the Actual I/O Statistics property and find out the I/O measurement of this operator.
当我们右键单击“聚集索引扫描”运算符并展开“ 实际I / O统计信息”属性,并找到该运算符的I / O度量时。
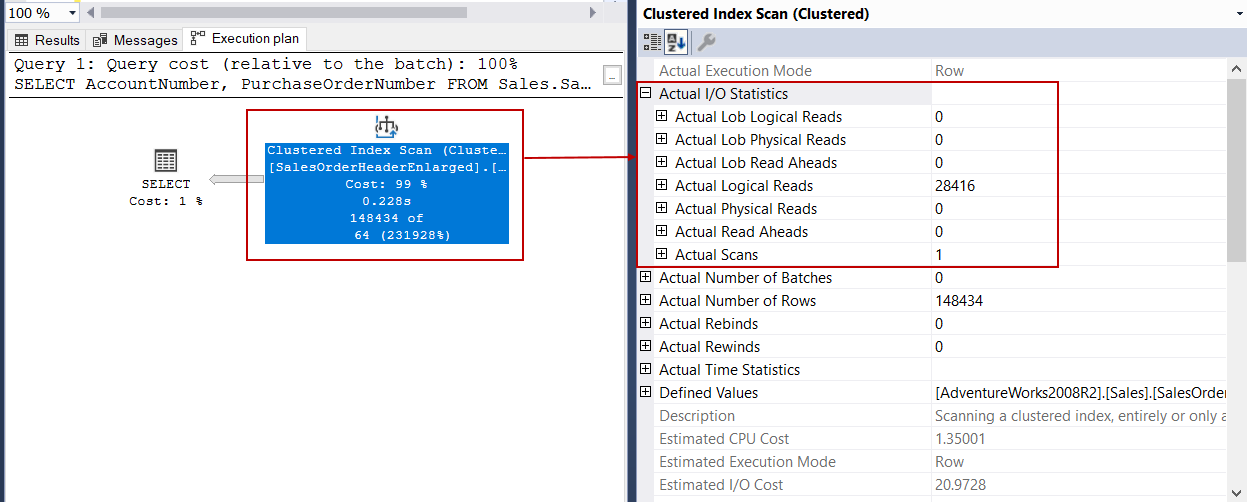
Actual Logical Reads value indicates how many pages read from the buffer pool. Now we will make a very simple calculation for this value:
实际逻辑读取值指示从缓冲池读取的页面数。 现在,我们将对该值进行非常简单的计算:
1 Logical I/O read indicates a reading of a data page and a data page stores 8 kb data. So the total read amount equals 28416*8KB = 227.328 KB and it approximately 227 MB. This amount is not small for a query.
1逻辑I / O读取表示读取数据页,并且数据页存储8 kb数据。 因此,总读取量等于28416 * 8KB = 227.328 KB,大约为227 MB。 对于查询来说,这个数目不小。
SQL Server does not support function-based indexes so it is a bit complicated to improve the performance of the queries that include scalar-valued function in the WHERE clauses. However, we can create computed columns and create indexes for the computed columns. So that we can improve the performance of these types of queries.
SQL Server不支持基于函数的索引,因此要提高在WHERE子句中包含标量值函数的查询的性能,会有些复杂。 但是,我们可以创建计算列并为计算列创建索引。 这样我们就可以提高这些类型的查询的性能。
Now we will apply this solution method to our example and observe performance improvement. At first, we will add a computed column to the SalesOrderHeaderEnlarged table.
现在,我们将此解决方案方法应用于示例并观察性能的提高。 首先,我们将一个计算列添加到SalesOrderHeaderEnlarged表中。
ALTER TABLE Sales.SalesOrderHeaderEnlarged
ADD SmallAccountNumber AS SUBSTRING(AccountNumber, 4, 4)
After the calculated column is created we will replace the SUBSTRING expression with the new computed column after the WHERE clause.
创建计算列后,我们将在WHERE子句之后用新的计算列替换SUBSTRING表达式。
SELECT AccountNumber,
PurchaseOrderNumber
FROM Sales.SalesOrderHeaderEnlarged
WHERE SmallAccountNumber = '4020'
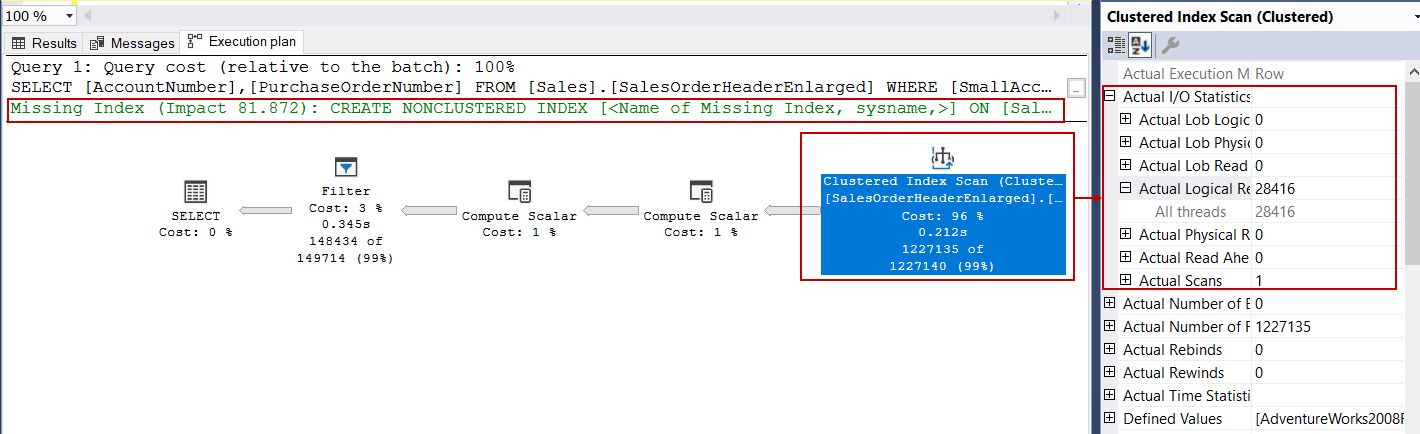
I/O statistics of the Clustered Index Operator do not change but query optimizer surprises us and offers a missing index that can improve the performance query. When we open the details of the index recommendation, it has a very pretentious proposal. Did you notice, the missing index says that this index will increase the performance of the query by 81%. It is worth trying.
聚集索引运算符的I / O统计信息不会改变,但是查询优化器使我们感到惊讶,并提供了可以改善性能查询的缺失索引。 当我们打开索引建议的细节时,它有一个非常自命不凡的建议。 您是否注意到,缺失索引表明该索引将使查询性能提高81%。 值得尝试。
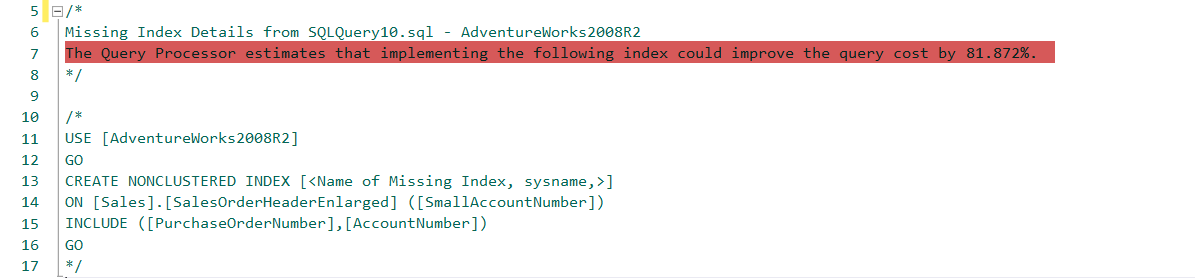
We will give a name to index and create it.
我们将给索引命名并创建它。
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeaderEnlarged_SmallAccountNumber]
ON [Sales].[SalesOrderHeaderEnlarged] ([SmallAccountNumber])
INCLUDE ([PurchaseOrderNumber],[AccountNumber])
Now we will execute the same query after the index creation and analyze the execution plan.
现在,我们将在创建索引后执行相同的查询并分析执行计划。
SELECT AccountNumber,
PurchaseOrderNumber
FROM Sales.SalesOrderHeaderEnlarged
WHERE SmallAccountNumber = '4020'
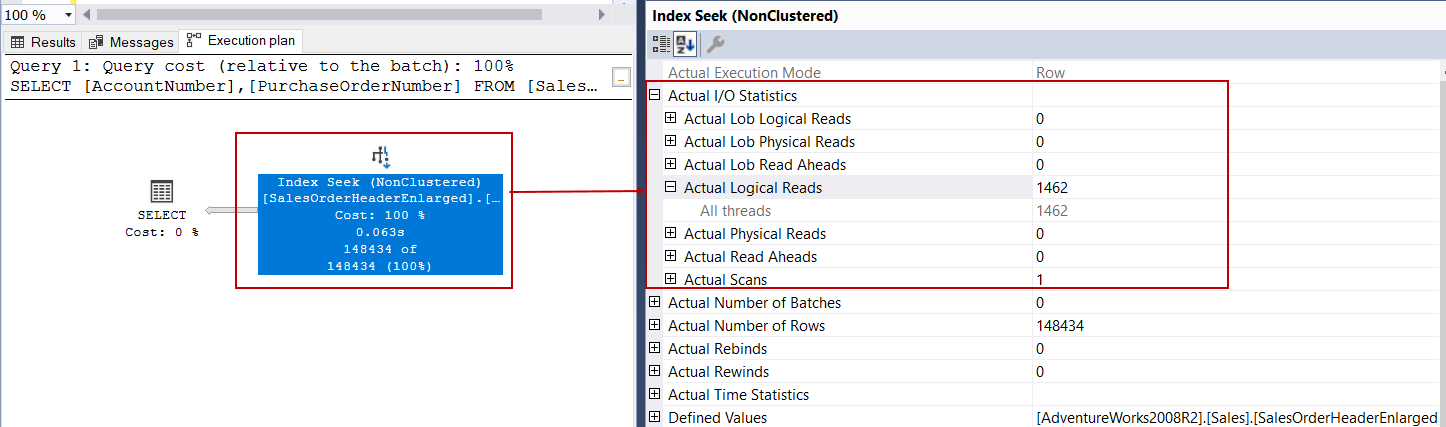
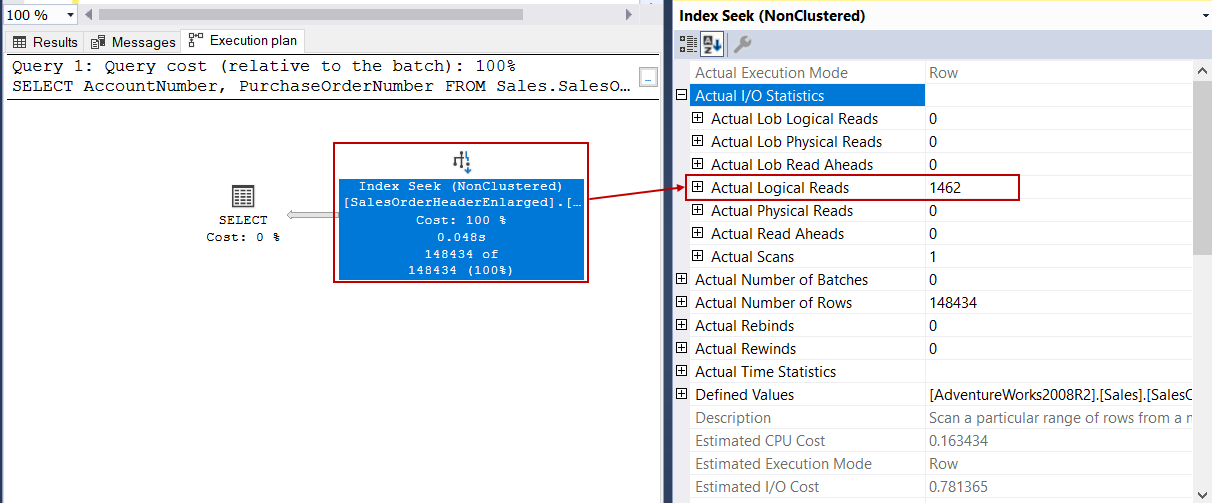
On the above execution plan, the index scan operator has given its place to an index seek operator and it performed only 1462 logical reads. So 1462*8KB = 11,696 KB and it approximately 11 MB. Now we will make a little magic and execute the original query which includes SUBSTRING function and analyze the execution plan.
在上述执行计划中,索引扫描运算符已将其位置赋予了索引查找运算符,并且仅执行了1462个逻辑读取。 因此1462 * 8KB = 11,696 KB,大约11 MB。 现在,我们将进行一些魔术操作,并执行包含SUBSTRING函数的原始查询并分析执行计划。
SELECT AccountNumber,
PurchaseOrderNumber
FROM Sales.SalesOrderHeaderEnlarged
WHERE SUBSTRING(AccountNumber, 4, 4) = '4020'
As a result, we understood that adding a computed column and creating an index for this computed column will improve the performance of the queries which are including the SUBSTRING after the WHERE clause. The most important point here is that we can accomplish this performance improvement without any code changing.
结果,我们了解到添加一个计算列并为此计算列创建索引将提高查询的性能,这些查询在WHERE子句之后包括SUBSTRING。 这里最重要的一点是,我们可以在不更改任何代码的情况下完成此性能改进。
在计算列上创建索引 (Create indexes on computed columns)
Creating an index on these columns has some limitations. The first one is determinism. Deterministic functions always return the same when they execute any time with the same parameters. For eg: the GETDATE() is a nondeterministic function, because it always returns different values. Now we will prove this concept.
在这些列上创建索引有一些限制。 第一个是确定性。 确定性函数在任何时候使用相同参数执行时总是返回相同的结果。 例如:GETDATE()是一个不确定函数,因为它总是返回不同的值。 现在我们将证明这个概念。
ALTER TABLE Sales.SalesOrderHeaderEnlarged
ADD CDateNow AS GETDATE()
Through the following query, we try to create a non-clustered index for this column.
通过以下查询,我们尝试为该列创建一个非聚集索引。
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeaderEnlarged_CDateNow ]
ON [Sales].[SalesOrderHeaderEnlarged] (CDateNow )
As we can see, the index creation returned an error because of determinism.
如我们所见,由于确定性,索引创建返回了错误。
The second limitation to create an index on the computed columns is the precision. It means that the computed column’s expression should be precise so the expression must not contain any FLOAT or REAL data types.
在计算列上创建索引的第二个限制是精度。 这意味着计算列的表达式应精确,因此表达式不得包含任何FLOAT或REAL数据类型。
We can use the following query to understand which computed column is suitable to create an index.
我们可以使用以下查询来了解哪个计算列适合创建索引。
SELECT object_id,
name,
definition,
CASE is_persisted
WHEN 0
THEN 'No'
ELSE 'Yes'
END AS is_persisted,
CASE COLUMNPROPERTY(computed_col.object_id, name, 'IsDeterministic')
WHEN 0
THEN 'No'
ELSE 'Yes'
END AS IsDeterministic,
CASE COLUMNPROPERTY(computed_col.object_id, name, 'IsIndexable')
WHEN 0
THEN 'No'
ELSE 'Yes'
END AS IsIndexable,
CASE COLUMNPROPERTY(computed_col.object_id, name, 'IsPrecise')
WHEN 0
THEN 'No'
ELSE 'Yes'
END AS IsPrecise
FROM sys.computed_columns computed_col
WHERE object_id = (SELECT obj.object_id
FROM sys.objects obj
WHERE obj.name = 'SalesOrderHeaderEnlarged');

结论 (Conclusion)
In this article, we explained the SUBSTRING function usage basics and also learned how to improve the performance of this function if it uses after the WHERE clause. We can create an index on computed columns to improve the performance of queries with scalar functions after the WHERE clause. However, creating an index on the computed columns have some limitations (determinism and precision) and if we want to create an index for the computed columns, these requirements must be met by the computed column.
在本文中,我们解释了SUBSTRING函数的使用基础,还学习了如何在WHERE子句之后使用该函数来提高其性能。 我们可以在计算列上创建索引,以提高WHERE子句后面带有标量函数的查询的性能。 但是,在计算列上创建索引有一些限制(确定性和精度),如果我们要为计算列创建索引,则计算列必须满足这些要求。
翻译自: https://www.sqlshack.com/sql-substring-function-and-its-performance-tips/















 2762
2762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









