






 本文介绍了如何使用SQL字符串函数进行数据处理,以减少数据准备时间。内容包括数据整理概念、SQL字符串函数的使用,如连接、子字符串、转换等,以及数据筛选和转换。SQL在数据科学中的重要性不言而喻,掌握这些函数能提高数据科学家的工作效率。
本文介绍了如何使用SQL字符串函数进行数据处理,以减少数据准备时间。内容包括数据整理概念、SQL字符串函数的使用,如连接、子字符串、转换等,以及数据筛选和转换。SQL在数据科学中的重要性不言而喻,掌握这些函数能提高数据科学家的工作效率。
sql用于字符串的聚合函数
In this article, you’ll learn the tips for getting started using SQL string functions for data munging with SQL Server. In many cases, Machine learning outcomes are only as good as the data they’re built on – but the work of preparing data for analytics (that is, data wrangling) can eat up as much as 80% of your project efforts.
在本文中,您将学习有关使用SQL字符串函数进行SQL Server数据处理的提示。 在许多情况下,机器学习的结果仅取决于其构建的数据,但是为分析准备数据(即数据整理)的工作可能会占用多达80%的项目工作量。
In this guide, we’ll see the following topics:
在本指南中,我们将看到以下主题:
- What is data munging? 什么是数据处理?
- How you can reduce your data preparation time 如何减少数据准备时间
- How to easily get started with SQL string functions 如何轻松开始使用SQL字符串函数
- How to process data using SQL string functions 如何使用SQL字符串函数处理数据
- And more… 和更多…
We’ll look at specific SQL string function examples including
我们将看一下特定SQL字符串函数示例,包括
- SQL concatenate string SQL连接字符串
- SQL Server substring functions SQL Server子字符串函数
- SQL string functions SQL字符串函数
- SQL Server convert string to date SQL Server将字符串转换为日期
- SQL replace string SQL替换字符串
- SQL convert INT to String SQL将INT转换为String
- SQL convert String to DateTime SQL将字符串转换为日期时间
- SQL string comparison SQL字符串比较
- And more … 和更多 …
数据整理 (Data Munging)
Data munging (or Wrangling) is the process of data transformation into various states so that it is easier to work and understand the data. The transformation may lead to manually convert or modify or merge the data in a certain format to generate well-defined streams of data which is ready for consumption by the data analysis tools and techniques.
数据处理(或争吵)是指将数据转换为各种状态的过程,以便更轻松地工作和理解数据。 转换可能导致以某种格式手动转换或修改或合并数据,以生成定义明确的数据流,这些数据流已准备好供数据分析工具和技术使用。
The various data-sources are
各种数据源是
- Metrics can be business data or KPI or collection of data within the sub-systems 指标可以是业务数据或KPI或子系统内的数据集合
- The use of existing data set for prediction 使用现有数据集进行预测
- Use of APIs to download the data 使用API下载数据
- Scraping the website data 抓取网站数据
- Creating data using third-party tools 使用第三方工具创建数据
You don’t have to be working in data science very long before you discover the importance of SQL. We can refer to the Kdnugget Software Poll, the top analytics, data mining, and data science software used in 2015 and look at the SQL’s place. In the survey of data professionals, SQL is placed third in terms of its usage. It’s also the first database tool on the list. Now, you see that R is right at the top.
在您发现SQL的重要性之前,您不必在数据科学领域工作很久。 我们可以参考Kdnugget Software Poll ,这是2015年使用的顶级分析,数据挖掘和数据科学软件,并了解SQL的位置。 在对数据专业人员的调查中,SQL的使用率排名第三。 它也是列表中的第一个数据库工具。 现在,您会看到R在顶部。
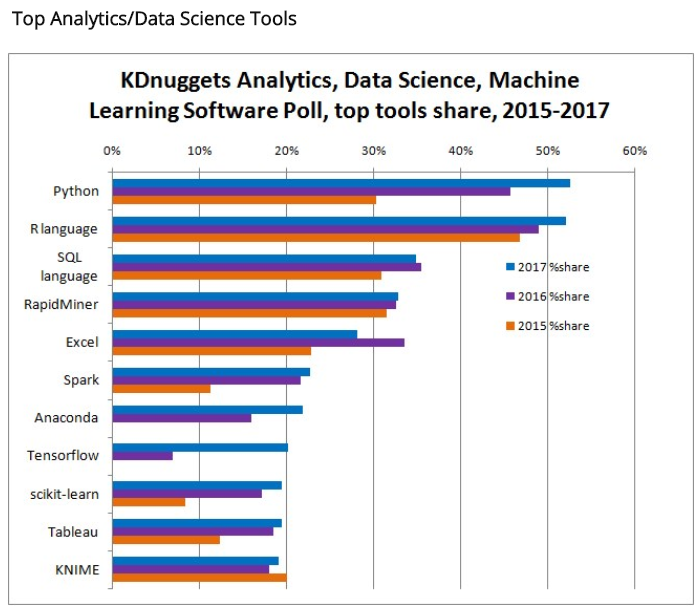
Note: The above picture is a reference from the following website. www.kdnuggets.com
注意:上图是来自以下网站的参考。 www.kdnuggets.com
入门 (Getting started)
Let now take a deep dive into SQL string functions to see the different phases of data munging
现在让我们深入研究SQL字符串函数,以查看数据处理的不同阶段
SQL is further classified into Data Manipulation Language (DML) and Data Definition Language (DDL). These commands are used to work with data-sets more efficiently. We’ll take a look at DML commands at later part of the article.
SQL进一步分为数据处理语言(DML)和数据定义语言(DDL)。 这些命令用于更有效地处理数据集。 我们将在本文的后面部分介绍DML命令。
Now, let’s discuss and analyze some of the SQL commands and understand why data-scientist needs to know these commands to do their work efficiently. In most cases, a majority portion of their work is about data gathering, data preparation, data cleaning, and data restructuring. After the data preparation phase, the scientist can move forward with the data analysis. In some scenarios, it’s been assumed that about 70% to 80% of the time on the data science project is spent on data manipulation; if this is the case then most of that time is spent working with SQL queries.
现在,让我们讨论和分析一些SQL命令,并理解为什么数据科学家需要了解这些命令才能有效地完成其工作。 在大多数情况下,他们的大部分工作都与数据收集,数据准备,数据清理和数据重组有关。 在数据准备阶段之后,科学家可以继续进行数据分析。 在某些情况下,假设在数据科学项目上约有70%到80%的时间用于数据处理。 如果是这种情况,则大部分时间都花在处理SQL查询上。
The data cleansing is an art in data science; we often tend to collect data from multiple data sources. Many times the same data is stored differently in multiple systems. Let us classify the data munging process into the following categories:
数据清理是数据科学中的一门艺术。 我们通常倾向于从多个数据源收集数据。 很多时候,同一数据在多个系统中的存储方式不同。 让我们将数据处理过程分为以下几类:
- Data reformatting 数据重新格式化
- Data extracting 数据提取
- Data filtering 资料筛选
- Data converting 资料转换
数据重构 (Data refactoring)
As a basic principle, whenever we start working with a new data set, it is recommended to spend more time to understand the type and nature of the data.
作为基本原则,每当我们开始使用新数据集时,建议您花更多的时间来了解数据的类型和性质。
For example, one couple of data-sets may use abbreviations for departments and in some other datasets it may spell out the full name. We need to reformat data to get it into a consistent format.
例如,一对数据集可以使用部门的缩写,而在其他一些数据集中则可以拼写全名。 我们需要重新格式化数据以使其成为一致的格式。
| Character | Description | Example |
| ASCII | The ASCII() SQL String function servers as a characters encoding standard format. | In the following example, the ASCII values are returned for the given input |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3528
3528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









