





In this article, we will explain batch mode on rowstore feature, which was announced with SQL Server 2019. The main benefit of this feature is that it improves the performance of analytical queries, and it also reduces the CPU utilization of these types of queries. Behind the scene, this performance enhancement uses the batch mode query processing feature for the data, which is stored in row format. Also, this feature has been using by columnstored indexes for a long time.
在本文中,我们将解释SQL Server 2019中宣布的行存储功能的批处理模式。此功能的主要好处是它可以提高分析查询的性能,还可以减少这些类型查询的CPU使用率。 在后台,此性能增强功能使用数据的批处理模式查询处理功能,该功能以行格式存储。 同样,列存储索引已使用此功能很长时间了。
Columnstore indexes have been announced with SQL Server 2012, and it offers two main benefits to us. These are:
SQL Server 2012宣布了列存储索引,它为我们提供了两个主要好处。 这些是:
- Reducing the I/O activity of the query due to using columnstore index structure 由于使用列存储索引结构,减少了查询的I / O活动
- More efficient CPU usage through the batch mode execution query processing method 通过批处理模式执行查询处理方法提高CPU使用率
However, using columnstore indexes is not well-suited for the OLTP database usage scenarios that are getting high Update and Delete workload because columnstore index usage adds extra overhead to the Delete and Update operations. For this reason, we need a way out that does not affect the performance of the Delete and Update operations, and it also improves the performance of the analytical queries. Using analytical queries and operational requirements at the same time is certainly a long-accepted approach.
但是,由于列存储索引的使用给删除和更新操作增加了额外的开销,因此使用列存储索引并不适合更新和删除工作量较高的OLTP数据库使用情况。 因此,我们需要一种不影响Delete和Update操作性能的方法,并且还可以提高分析查询的性能。 同时使用分析查询和操作需求无疑是一种被广泛接受的方法。
The solution has come with SQL Server 2019 for these issues. Batch mode execution on the rowstore feature can solve these types of issues because it has multiple row handling capabilities at the same time instead of the traditional row-by-row processing method.
SQL Server 2019随附了针对这些问题的解决方案。 行存储功能上的批处理模式执行可以解决这些类型的问题,因为它同时具有多种行处理功能,而不是传统的逐行处理方法。
Before going through details of the batch mode on rowstore, we will take a glance at the batch mode execution.
在详细了解行存储上的批处理模式之前,我们将看一下批处理模式的执行情况。
批处理模式执行 (Batch mode execution)
Batch mode execution is a query processing method, and the advantage of this query processing method is to handle multiple rows at a time. This approach gains us performance enhancement when a query performs aggregation, sorts, and group-by operations on a large amount of data. Now we will analyze the following execution plan:
批处理模式执行是一种查询处理方法,这种查询处理方法的优点是可以一次处理多行。 当查询对大量数据执行聚合,排序和分组操作时,此方法可提高性能。 现在,我们将分析以下执行计划:
SELECT ModifiedDate,CarrierTrackingNumber,
SUM(OrderQty*UnitPrice) FROM Sales.SalesOrderDetailEnlarged
GROUP BY ModifiedDate,CarrierTrackingNumber
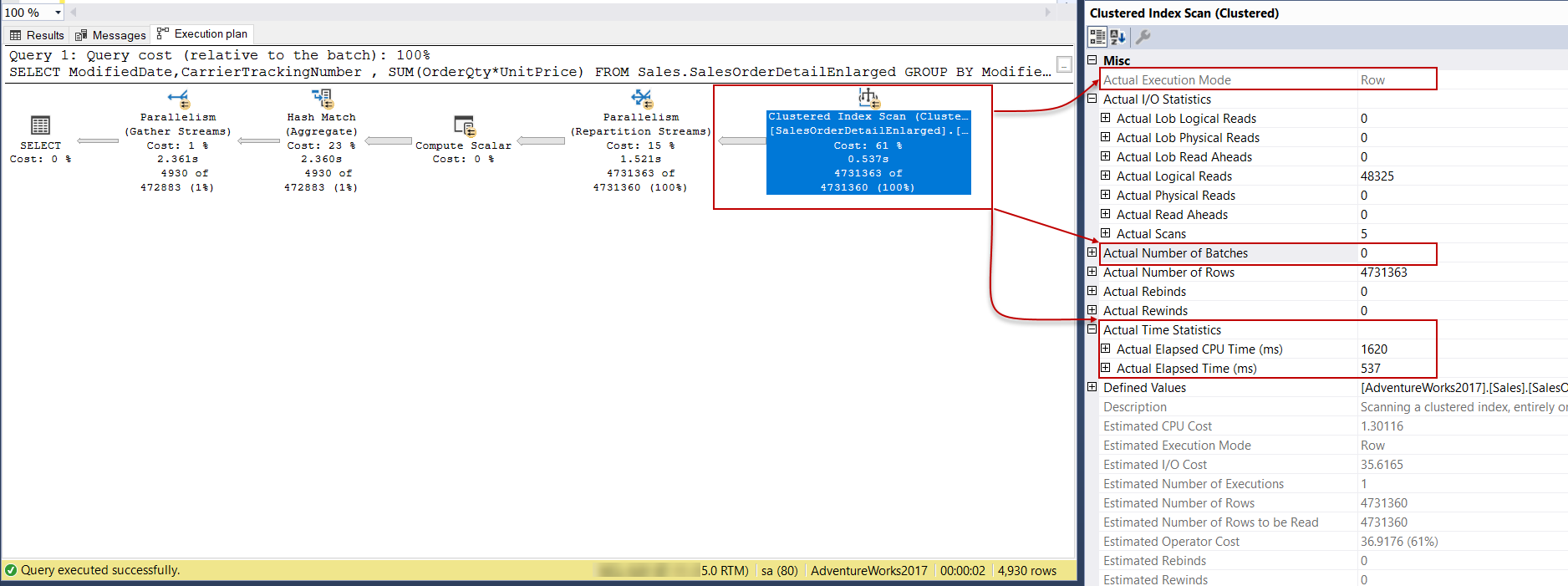
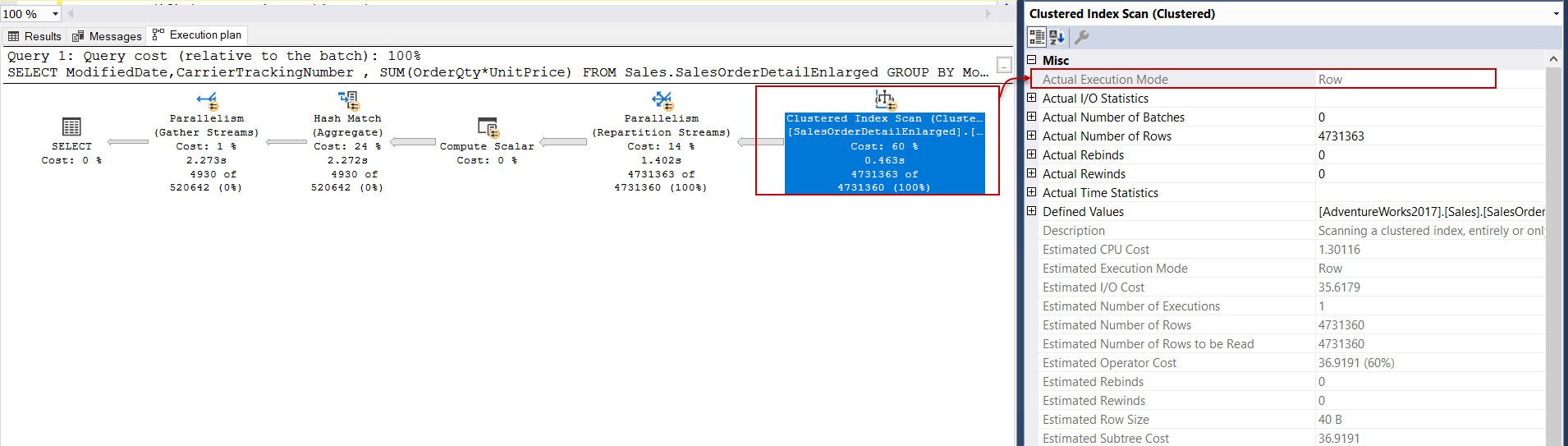
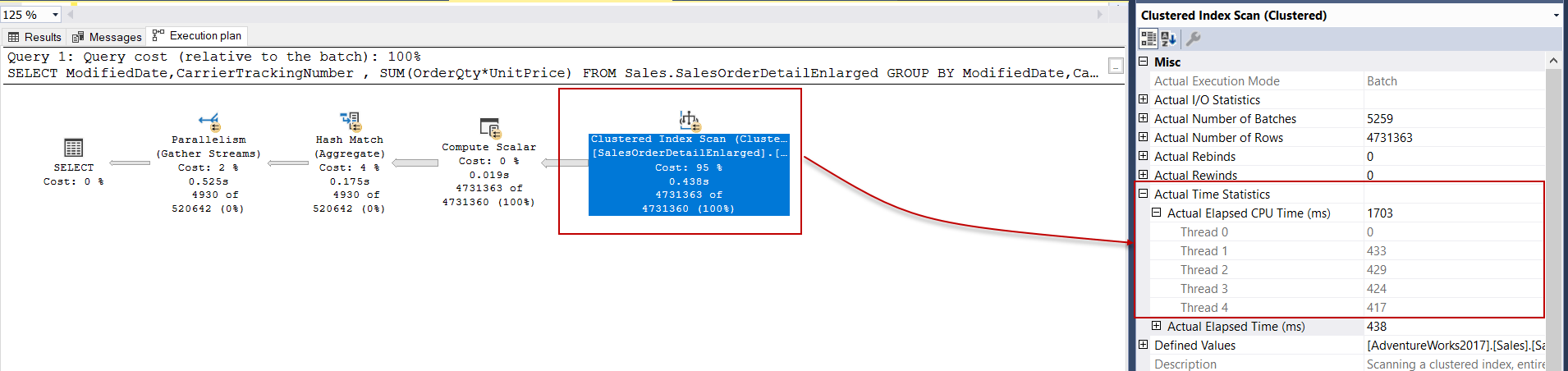
This clustered index scan operator execution mode is the row, and it handles the rows one by one. The following execution plan illustrates the execution plan of the same query, but the clustered index has replaced with the clustered columnstore index:
这种聚集索引扫描运算符的执行模式是row ,它逐行处理行。 以下执行计划说明了同一查询的执行计划,但是聚簇索引已替换为聚簇列存储索引:
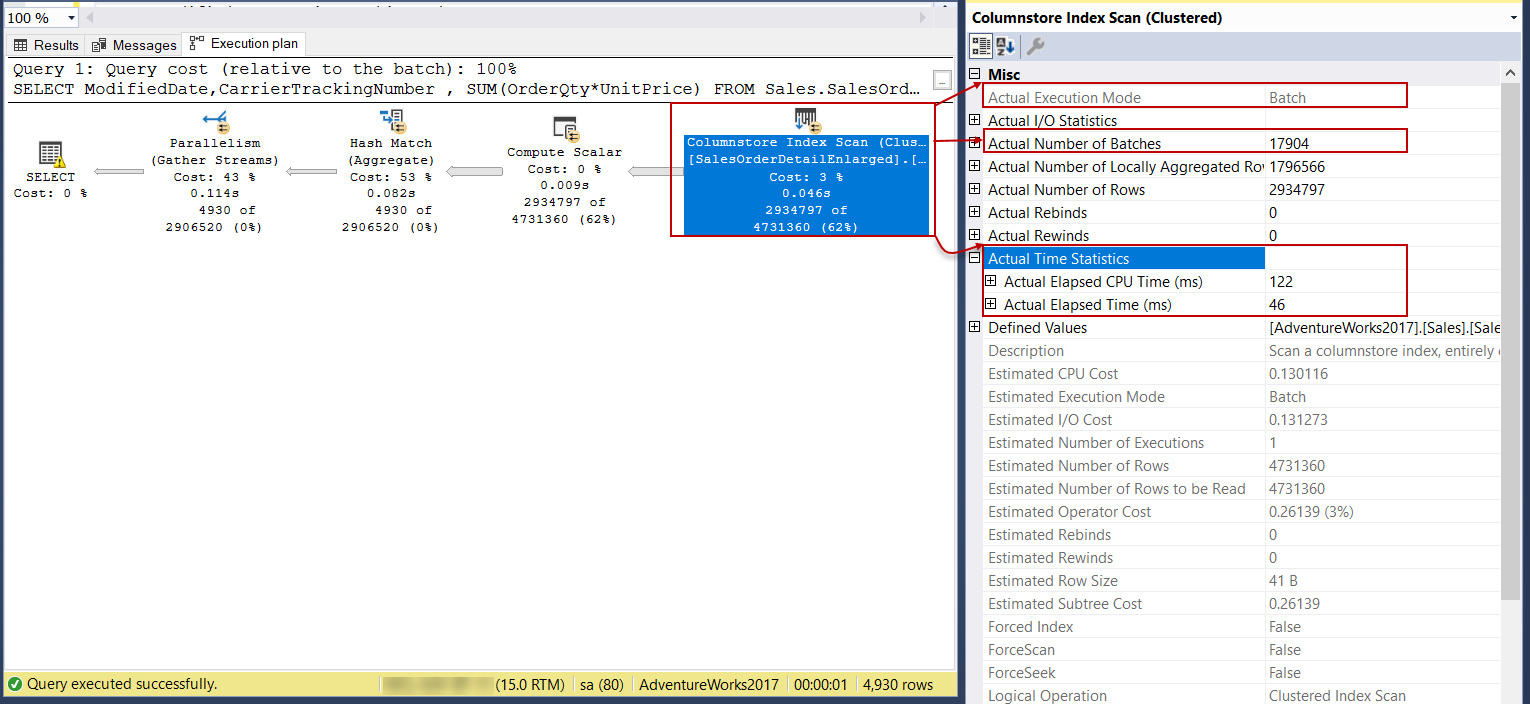
In this execution plan, we can see that the batch mode query processing had been performed by the columnstore index scan operator. The dramatic performance difference between row mode and batch mode query processing in terms of the CPU times can be seen. Batch mode query processing can boost the performance of the analytical queries because it processes multiple rows at once. This is the main idea behind the batch execution mode query processing method. In the next sections, we will learn how this mechanism works for the data where is stored in row structure.
在该执行计划中,我们可以看到,列存储索引扫描运算符已执行了批处理模式查询处理。 可以看到,在行模式和批处理模式查询处理之间,就CPU时间而言,性能存在显着差异。 批处理模式查询处理可以一次处理多行,因此可以提高分析查询的性能。 这是批处理执行模式查询处理方法背后的主要思想。 在下一节中,我们将学习这种机制如何处理存储在行结构中的数据。
前提条件 (Pre-requirements )
In the following examples, we will use the AdventureWorks sample database. At first, we will switch compatibly level to 150, so we will be able to take advantage of all the features of the SQL Server 2019.
在以下示例中,我们将使用AdventureWorks示例数据库。 首先,我们将兼容级别切换到150,因此我们将能够利用SQL Server 2019的所有功能。
ALTER DATABASE AdventureWorks2008R2 SET COMPATIBILITY_LEVEL = 150
On the other hand, we should work large tables to perform straightforward examples. For this reason, we will use an enlarging script (Create Enlarged AdventureWorks Tables ), which helps to create a large amount of data. This script is going to create the SalesOrderDetailEnlarged and SalesOrderHeaderEnlarged tables under the Sales schema:
另一方面,我们应该使用大型表来执行简单的示例。 因此,我们将使用一个放大脚本( Create Enlarged AdventureWorks Tables ),该脚本有助于创建大量数据。 该脚本将创建SalesOrderDetailEnlarged和SalesOrderHeaderEnlarged表 在销售模式下:
RowStore上的批处理模式 (Batch Mode on RowStore)
As we mentioned, the batch mode query processing method is boosting the performance of the analytical queries. With SQL Server 2019, we can take advantage of this option for the tables that do not contain any columnstore indexes. The batch mode on rowstore feature can be enabled by switching the database to the latest compatibility level, which is 150.
如前所述,批处理模式查询处理方法正在提高分析查询的性能。 使用SQL Server 2019,我们可以对不包含任何列存储索引的表利用此选项。 通过将数据库切换到最新的兼容级别150,可以启用行存储上的批处理模式功能。
Now we will execute the following query and enable the actual execution plan:
现在,我们将执行以下查询并启用实际的执行计划:
SELECT ModifiedDate,CarrierTrackingNumber ,
SUM(OrderQty*UnitPrice) FROM Sales.SalesOrderDetailEnlarged
GROUP BY ModifiedDate,CarrierTrackingNumber
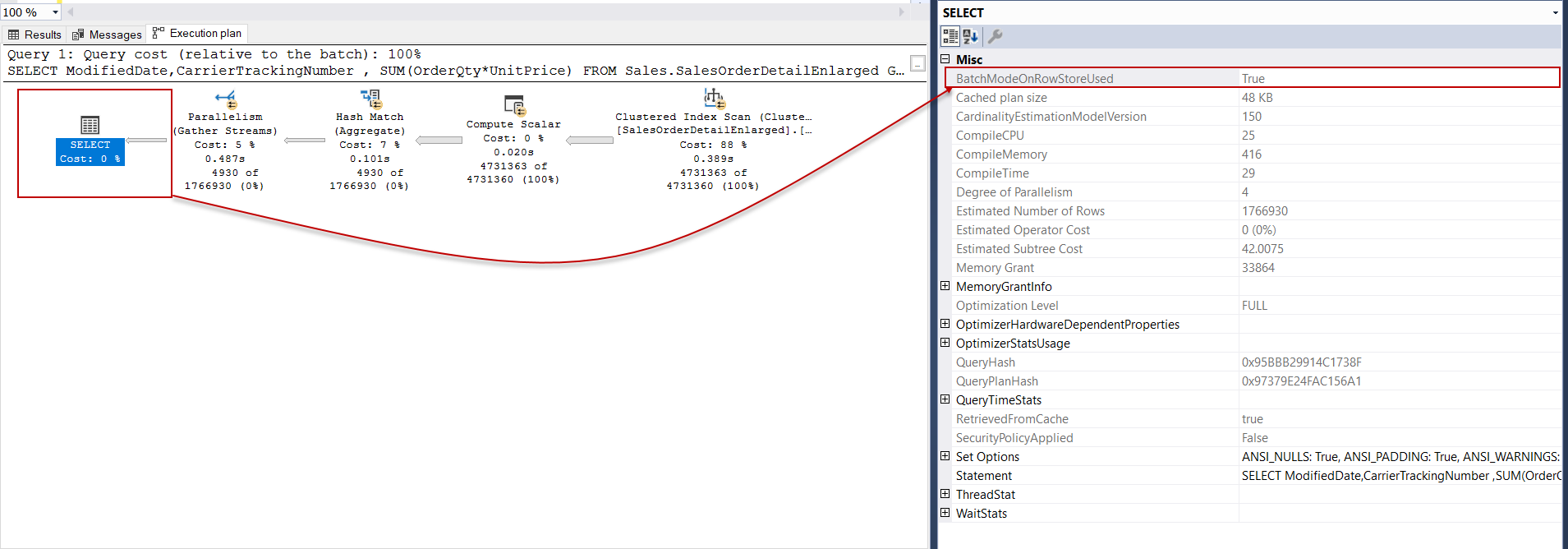
The BatchModeOnRowStoreUsed property can be seen as true on the Select operator properties. This property specifies at least one of the execution plan element have performed batch mode query processing for the rowstore data:
在Select运算符属性上,可以将BatchModeOnRowStoreUsed属性视为true。 此属性指定至少一个执行计划元素已对行存储数据执行批处理模式查询处理:
When we look at the property of the clustered index scan operator, we will see that the execution mode property is Batch, so it indicates this operator process data using the batch mode:
当我们查看聚集索引扫描运算符的属性时,我们将看到执行模式属性为Batch ,因此它指示此运算符使用批处理模式处理数据:
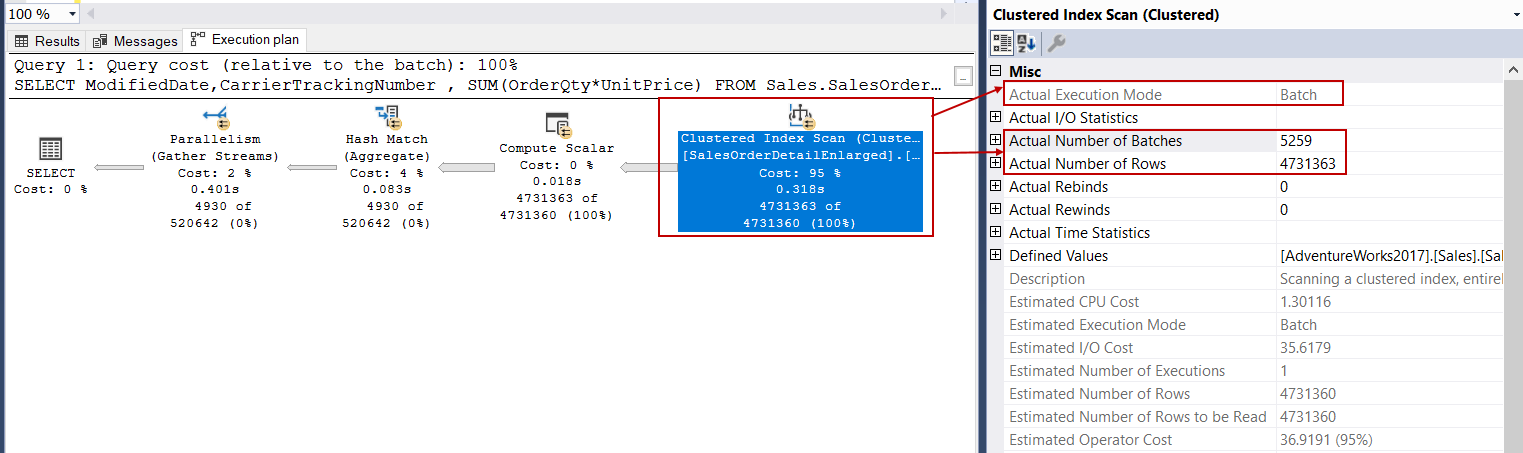
At this point, we should draw attention to the batch number in the execution plan. 5.259 batches have been executed by the clustered index scan operator, and it has handled 4.731.363 rows. Therefore, processing about 900 rows per batch will be more effective than handling row by row.
此时,我们应该提请注意执行计划中的批号。 聚集索引扫描运算符已执行5.259批处理,并且已处理了4.731.363行。 因此,每批处理约900行将比逐行处理更为有效。
At the same time, these batch executions have been acted by the separated threads. If we expand the Actual Number of Batches option we can find out how many batches have been executed by the individual threads:
同时,这些批处理执行是由单独的线程执行的。 如果我们扩展“ 实际批次数”选项,我们可以找出各个线程执行了多少个批次:

We can disable batch mode on rowstore option to using DISALLOW_BATCH_MODE hint. When we execute the following query, the query optimizer does not decide to use the batch mode on rowstore option:
我们可以禁用行存储选项上的批处理模式,以使用DISALLOW_BATCH_MODE提示。 当我们执行以下查询时,查询优化器不会决定在rowstore选项上使用批处理模式:
SELECT ModifiedDate,CarrierTrackingNumber ,
SUM(OrderQty*UnitPrice) FROM Sales.SalesOrderDetailEnlarged
GROUP BY ModifiedDate,CarrierTrackingNumber
OPTION(USE HINT('DISALLOW_BATCH_MODE'))
At the same time, we can disable the batch mode feature at the database level. The BATCH_MODE_ON_ROWSTORE option can be applied at the database level and disable the batch mode on rowstore feature:
同时,我们可以在数据库级别禁用批处理模式功能。 可以在数据库级别应用BATCH_MODE_ON_ROWSTORE选项,并在行存储功能上禁用批处理模式:
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ON_ROWSTORE = OFF
The following query re-enables the batch mode on rowstore:
以下查询在行存储上重新启用批处理模式:
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ON_ROWSTORE = ON
We should consider that this feature is still only enabled for the SQL Server 2019 Enterprise edition.
我们应该考虑仍然仅针对SQL Server 2019企业版启用此功能。
性能测试:批处理模式执行与行模式执行 (Performance test: Batch mode execution vs Row mode execution)
In this test, we will compare the CPU utilization of the batch mode query processing against row mode for the same query.
在此测试中,我们将针对同一查询将批处理模式查询处理的CPU使用率与行模式进行比较。
The convenient and simple way to measure the CPU utilization of a query is to enable the SET STATISTICS TIME option. To test queries on a cold buffer cache environment, we will use the DROPCLEANBUFFERS statement.
衡量查询的CPU使用率的简便方法是启用SET STATISTICS TIME选项。 为了在冷缓冲区缓存环境中测试查询,我们将使用DROPCLEANBUFFERS语句。
Thus, we will create equal conditions for these two queries.
因此,我们将为这两个查询创建相等的条件。
Note: DROPCLEANBUFFERS option should not be executed on the production servers if you don’t have enough knowledge background of this statement.
注意 :如果您对该语句的知识背景不足,则不应在生产服务器上执行DROPCLEANBUFFERS选项。
At first, we are going to execute the following query which process rows on the batch mode:
首先,我们将执行以下查询,以批处理方式处理行:
SET STATISTICS TIME ON
GO
DBCC DROPCLEANBUFFERS
GO
SELECT ModifiedDate,CarrierTrackingNumber ,
SUM(OrderQty*UnitPrice) FROM Sales.SalesOrderDetailEnlarged
GROUP BY ModifiedDate,CarrierTrackingNumber
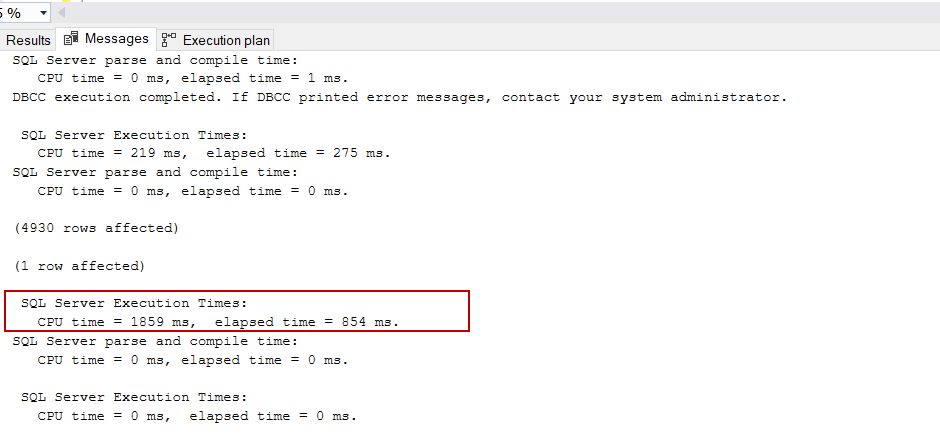
We will parse this output with Statistics Parser to convert to more meaningful reports:
我们将使用Statistics Parser解析此输出,以转换为更有意义的报告:
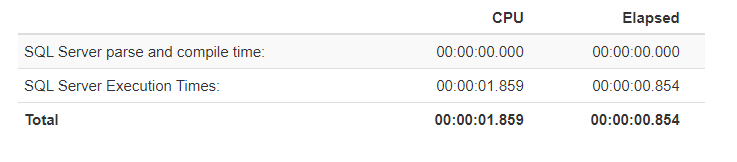
For the following query, we will disable batch mode on the rowstore feature and execute the query:
对于以下查询,我们将在行存储功能上禁用批处理模式并执行查询:
SET STATISTICS TIME ON
GO
DBCC DROPCLEANBUFFERS
GO
SELECT ModifiedDate,CarrierTrackingNumber ,
SUM(OrderQty*UnitPrice) FROM Sales.SalesOrderDetailEnlarged
GROUP BY ModifiedDate,CarrierTrackingNumber
OPTION(USE HINT('DISALLOW_BATCH_MODE'))
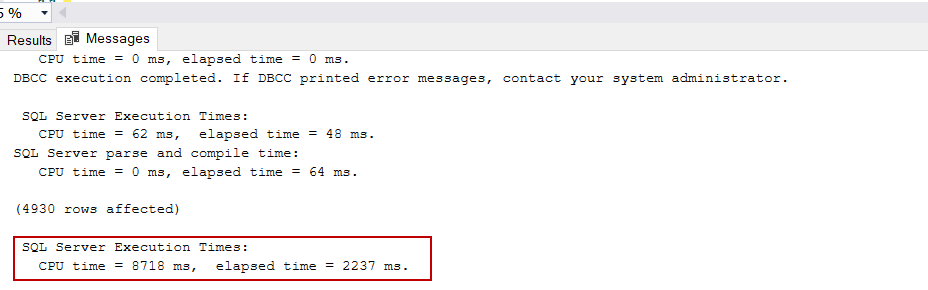
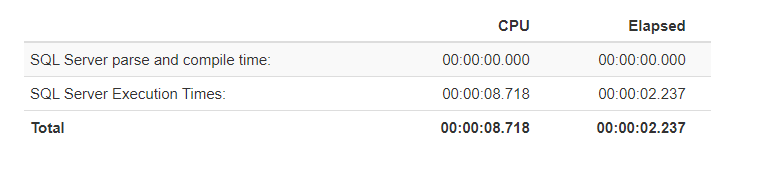
The following chart represents the graphical illustration of the performance results on the SQL Server 2019 environment:
下图显示了SQL Server 2019环境下的性能结果的图形说明:
It seems that, obviously, batch mode query processing has outstanding performance against row mode query processing. The batch mode CPU utilization is nearly 4 times lower than the row mode. Batch mode elapsed time is also 2.5 times lower than the row mode.
显然,批处理模式查询处理相对于行模式查询处理具有出色的性能。 批处理模式下的CPU利用率比行模式低了近4倍。 批处理模式的经过时间也比行模式少2.5倍。
Normally the elapsed time should be greater than the CPU time, but for these queries, it is just the opposite. The reason for this absurd case is very simple; the query optimizer decided to use parallel execution plans for these queries. In the parallel execution plans, the CPU time indicates the cumulative total value of the separated threads CPU time values:
通常,经过的时间应大于CPU时间,但是对于这些查询,情况恰恰相反。 发生这种荒唐事件的原因很简单; 查询优化器决定对这些查询使用并行执行计划。 在并行执行计划中,CPU时间表示各个线程的累计CPU时间值:
提示:自适应联接 (Tip: Adaptive Joins)
In the execution plans, the query optimizer chooses different joining algorithms to connect the rows of the different tables. However, if the query optimizer uses the batch execution mode, it also considers using adaptive join type. The main benefit of this join operator is that it decides to a join method dynamically on the runtime according to the row count threshold. These join methods can be hash or nested join algorithms. Now we will execute the following query and look at the execution plan:
在执行计划中,查询优化器选择不同的联接算法来连接不同表的行。 但是,如果查询优化器使用批处理执行模式,则它还会考虑使用自适应联接类型。 此连接运算符的主要好处是,它可以根据行数阈值在运行时动态决定连接方法。 这些联接方法可以是哈希联接或嵌套联接算法。 现在,我们将执行以下查询,并查看执行计划:
SELECT ProductID,SUM(LineTotal) ,
SUM(UnitPrice) , SUM(UnitPriceDiscount) FROM
Sales.SalesOrderDetailEnlarged SOrderDet
INNER JOIN Sales.SalesOrderHeaderEnlarged SalesOr
ON SOrderDet.SalesOrderID = SalesOr.SalesOrderID
GROUP BY ProductID
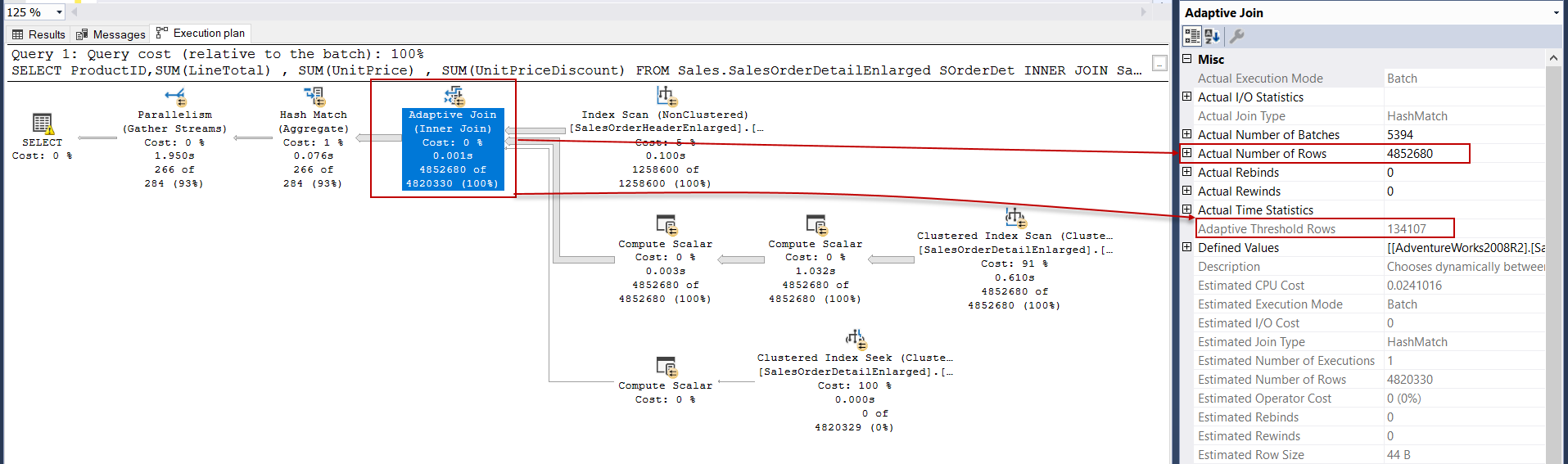
For this execution plan, the row number crosses Adaptive Threshold Rows value, so it has performed the hash join method.
对于此执行计划,行号越过“ 自适应阈值行”值,因此它执行了哈希联接方法。
“You can see the article SQL Server 2017: Adaptive Join Internals for more details about the adaptive joins”
“您可以查看文章SQL Server 2017:自适应联接内部以获取有关自适应联接的更多详细信息”
结论 (Conclusion)
In this article, we learned batch mode on rowstore feature, which was introduced with the SQL Server 2019. This feature provides performance improvements for the analytical queries and reduces CPU utilization. However, the main advantage of this feature is not required for any code replacing for the queries or the application sides. As the last sentence, if we want to take advantage of the batch mode query processing for the lower versions of the SQL Server, this Batch Mode Hacks for Rowstore Queries in SQL Server article might be helpful to overcome this issue.
在本文中,我们学习了SQL Server 2019中引入的基于行存储的批处理模式功能。此功能可提高分析查询的性能并降低CPU利用率。 但是,此功能的主要优点对于替换查询或应用程序端的任何代码均不需要。 作为最后一句话,如果我们想利用较低版本SQL Server的批处理模式查询处理功能,这篇SQL Server 中的行存储查询批处理模式黑客文章可能有助于克服此问题。
翻译自: https://www.sqlshack.com/sql-server-2019-new-features-batch-mode-on-rowstore/

















 6697
6697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









