





 本文探讨了在SQL Server中索引外键列的重要性。虽然外键约束不会自动创建索引,但创建索引能提升联接性能,减少维护关系的成本。通过实例展示了创建索引前后的查询性能对比,说明了外键列索引对于提高查询效率的显著效果。
本文探讨了在SQL Server中索引外键列的重要性。虽然外键约束不会自动创建索引,但创建索引能提升联接性能,减少维护关系的成本。通过实例展示了创建索引前后的查询性能对比,说明了外键列索引对于提高查询效率的显著效果。
Before going through the main concern of this article, indexing the foreign key columns, let’s take a small trip back to review the SQL Server Indexes and Foreign Key concepts.
在遍历本文的主要内容(索引外键列)之前,让我们花一点时间回顾一下SQL Server索引和外键概念。
SQL Server索引概述 (SQL Server Indexes Overview)
A SQL Server index is considered as one of the most important performance-tuning factors. They are built on a table or view in the shape of the B-Tree structure to provide a fast access to the requested data, based on the index column’s values, speeding up the query processing. Without having an index in your table, the SQL Server Engine will scan all the table’s data in order to find the row that meets the requested data criteria. You can imagine the table scan as reading all the book pages in order to find a specific word, where the book index will help you in finding the requested information quickly.
SQL Server索引被认为是最重要的性能调整因素之一。 它们以B树结构的形式构建在表或视图上,以基于索引列的值提供对所请求数据的快速访问,从而加快了查询处理。 在表中没有索引的情况下,SQL Server引擎将扫描表的所有数据,以查找符合请求的数据条件的行。 您可以将表扫描想象为阅读所有书籍页面以查找特定单词,其中书籍索引将帮助您快速找到所需信息。
SQL Server offers mainly two types of indexes, a Clustered index that stores the actual data of the table at the leaf level of the index, including all the table columns, and control its sort in the disk. A Non-clustered index contains only the index key columns values in addition to a pointer to the actual data rows stored in the clustered index or the actual table, without specifying the real data order. You can create only one clustered index per each table, with the ability to create up to 999 non-clustered indexes on each table. A table with no clustered index is called a Heap table, with its actual data not sorted in the disk. There are other index types available in SQL Server, such as the Composite index that contains more than one key column, the Unique index that enforces the column values uniqueness and the Covering index that contains all columns needed by the query.
SQL Server主要提供两种类型的索引,即聚集索引 ,它在索引的叶级(包括所有表列)存储表的实际数据,并控制其在磁盘中的排序。 非聚集索引除了指向存储在聚集索引或实际表中的实际数据行的指针外,仅包含索引键列值,而不指定实际数据顺序。 每个表只能创建一个聚簇索引,并且每个表最多可以创建999个非聚簇索引。 没有聚簇索引的表称为堆表 ,其实际数据不在磁盘中排序。 SQL Server中还有其他可用的索引类型,例如包含多个键列的Composite索引 ,强制列值具有唯一性的Unique索引以及包含查询所需的所有列的Covering索引 。
Creating a suitable index is not an easy task, as you need to balance between the need to speed up the data retrieval process and the drawback of the index creation on the data insertion and modification processes. You need also to make sure that the index size is as small as possible, due to the disk space that will be consumed by the index, in addition to the index maintenance overhead. So, it is better always to test index efficiency on a development server before performing that change in the production environment.
创建合适的索引并不是一件容易的事,因为您需要在加快数据检索过程的需要与在数据插入和修改过程中创建索引的缺点之间取得平衡。 您还需要确保索引大小尽可能小,这不仅是因为索引将占用磁盘空间,而且还有索引维护开销。 因此,最好在生产环境中执行更改之前始终在开发服务器上测试索引效率。
外键概述 (Foreign Key Overview)
A Foreign Key is a database key that is used to link two tables together by referencing a field in the first table that contains the foreign key, called the Child table, to the PRIMARY KEY in the second table, called the Parent table. In other words, the foreign key column values in the child table must appear in the referenced PRIMARY KEY column in the parent table before inserting its value to the child table. This reference performed by the foreign key constraint will enforce database referential integrity. You may recall that the PRIMARY KEY is a table constraint that maintains the uniqueness and non-NULL values for the chosen column or columns values, enforcing the entity integrity for that table, with the ability to create only one PRIMARY KEY per each table. You can include the foreign key creation while creating the table using CREATE TABLE T-SQL statement or create it after the table creation using ALTER TABLE T-SQL statement.
外键是一种数据库键,用于通过将第一个表中包含外键(称为子表)的字段引用到第二个表(称为父表)中的PRIMARY KEY来将两个表链接在一起。 换句话说,在将子表中的外键列值插入到子表中之前,它必须出现在父表中引用的PRIMARY KEY列中。 由外键约束执行的此引用将强制数据库引用完整性。 您可能还记得,PRIMARY KEY是一个表约束,它维护所选列的唯一性和非NULL值,从而增强了该表的实体完整性,并且每个表只能创建一个PRIMARY KEY。 您可以在使用CREATE TABLE T-SQL语句创建表时包括外键创建,也可以在使用ALTER TABLE T-SQL语句创建表后创建外键。
索引外键列的好处 (Benefits of indexing Foreign Key Columns)
When a PRIMARY KEY constraint is defined, a clustered index will be created on the constraint columns by default, if there is no previous clustered index defined on that table. So, we can expect that everything is configured well at the parent table’s side. The case may differ with the foreign key constraint at the child table’s side, where no index will be created on the constraint keys automatically, and it is the database administrator’s or developer’s responsibility to create the index on the child table manually.
定义PRIMARY KEY约束时,如果在该表上未定义以前的聚集索引,则默认情况下将在约束列上创建聚集索引。 因此,我们可以期望所有事情在父表的一侧都配置良好。 情况可能与子表侧的外键约束不同,后者不会在约束键上自动创建索引,数据库管理员或开发人员有责任在子表上手动创建索引。
It is highly recommended to create an index on each foreign key constraint on the child table, as it is very common when calling that key on your queries to join between the child table and the parent table columns, providing better joining performance. Indexing foreign key columns also help in reducing the cost of maintaining the relationship between parent and child tables that is specified by the (CASCADE) or (NO ACTION) option. This option comes into play when an UPDATE or DELETE operation is executed, by speeding up the process of retrieving the common reference values that the action will be performed on.
强烈建议在子表上的每个外键约束上创建索引,因为在查询上调用该键以在子表和父表列之间进行联接时非常常见,从而提供了更好的联接性能。 索引外键列还有助于减少维护(CASCADE)或(NO ACTION)选项指定的父表与子表之间关系的成本。 当执行UPDATE或DELETE操作时,此选项将起作用,它可以加快检索将对其执行操作的公共参考值的过程。
Let us see the benefits of indexing the foreign key columns practically. We will create four tables under the SQLShackDemo testing database, with the relations specified by the database diagram shown below:
让我们看看实际上索引外键列的好处。 我们将在SQLShackDemo测试数据库下创建四个表,其关系如下数据库图所示:
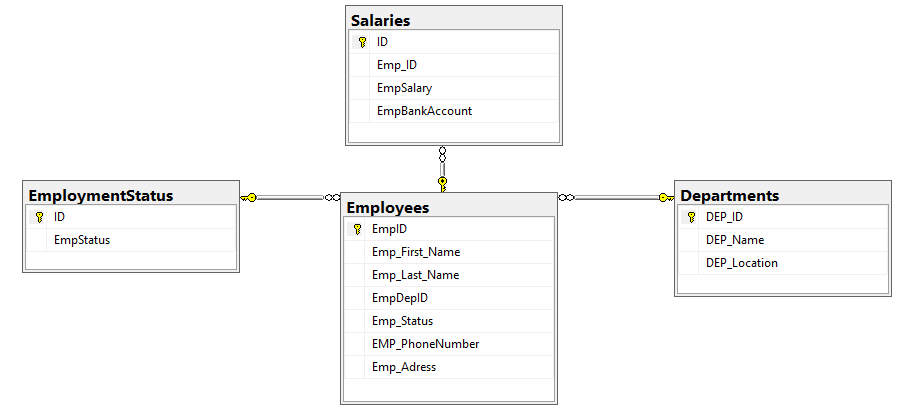
The relations between the tables shown in the previous database diagram can be summarized as:
上一个数据库图中显示的表之间的关系可以总结为:
- The EmpDepID column from the Employees table references the Dep_ID column from the Department table. 员工表中的EmpDepID列引用了部门表中的Dep_ID列。
- The EmpStatus column from the Employees table references the ID column from the EmploymentStatus table. 员工表中的EmpStatus列引用了EmploymentStatus表中的ID列。
- The Emp_ID column from the Salaries table references the EmpID column from the Employees table. 薪金表中的Emp_ID列引用了员工表中的EmpID列。
The T-SQL script below is used to create the four new tables with the three foreign key constraints described previously:
下面的T-SQL脚本用于创建具有前面描述的三个外键约束的四个新表:
USE [SQLShackDemo]
GO
CREATE TABLE [dbo].[Departments](
[DEP_ID] [int] NOT NULL PRIMARY KEY ,
[DEP_Name] [nvarchar](50) NULL,
[DEP_Location] [nvarchar](max) NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[EmploymentStatus](
[ID] [int] NOT NULL PRIMARY KEY ,
[EmpStatus] INT NULL,
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Employees](
[EmpID] [int] NOT NULL PRIMARY KEY,
[Emp_First_Name] [nvarchar](50) NULL,
[Emp_Last_Name] [nvarchar](50) NULL,
[EmpDepID] [int] NOT NULL CONSTRAINT [FK_DEP] FOREIGN KEY([EmpDepID])
REFERENCES [dbo].[Departments] ([DEP_ID]) ON DELETE CASCADE,
[Emp_Status] [int] NOT NULL CONSTRAINT [FK_Stat] FOREIGN KEY([Emp_Status])
REFERENCES [dbo].[EmploymentStatus] ([ID]) ON DELETE CASCADE,
[EMP_PhoneNumber] [nvarchar](50) NULL,
[Emp_Adress] [nvarchar](max) NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Salaries](
ID INT IDENTITY (1,1) PRIMARY KEY,
[Emp_ID] [int] NOT NULL CONSTRAINT [FK_Sal] FOREIGN KEY([Emp_ID])
REFERENCES [dbo].[Employees] ([EmpID]) ON DELETE CASCADE,
[EmpSalary] INT NULL,
[EmpBankAccount] VARCHAR(100)
) ON [PRIMARY]
GO
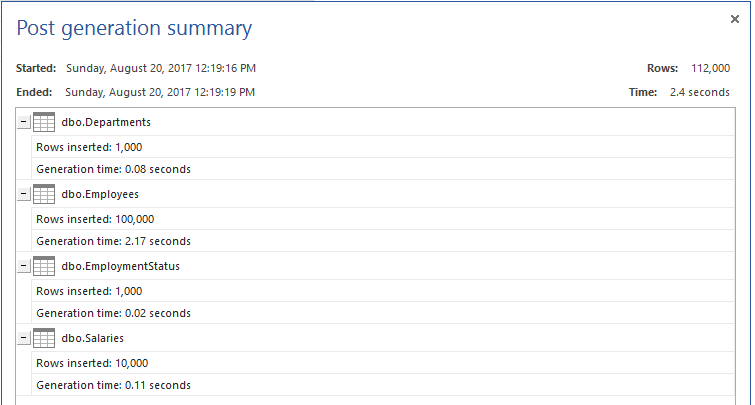
The tables are created successfully now. To have a fair testing scenario, we will fill these tables with testing data using ApexSQL Generate as shown below:
现在已成功创建表。 为了有一个公平的测试方案,我们将使用ApexSQL Generate将这些表填充测试数据,如下所示:
Once the tables are filled with synthetic test data, we will run a SELECT query that joins the four tables together using the foreign keys columns to retrieve data from the Employees table that meets specific criteria. We will start with enabling IO and TIME statistics for performance comparison purposes. We will also free up the procedure cache each time we run the SELECT query to make sure that a new plan will be generated with each run. The T-SQL script to achieve that is as shown below:
一旦表中填充了综合测试数据,我们将运行SELECT查询,该查询使用外键列将四个表连接在一起,以从Employees表中检索满足特定条件的数据。 我们将从启用IO和TIME统计信息开始,以进行性能比较。 每次运行SELECT查询时,我们还将释放过程缓存,以确保每次运行都会生成一个新计划。 实现该目标的T-SQL脚本如下所示:
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
DBCC FREEPROCCACHE;
SELECT EMP.Emp_First_Name , EMP.Emp_Last_Name
FROM [Employees] AS EMP
JOIN [Departments] AS DEP
ON EMP.EmpDepID =DEP.DEP_ID
JOIN [EmploymentStatus] AS Stat
ON EMP.Emp_Status =Stat.ID
JOIN [Salaries] AS Sal
ON EMP.EmpID =Sal.Emp_ID
WHERE EMP.Emp_Status =370 AND EMP.EmpDepID =370 AND Sal.EmpSalary>0 AND EMP.Emp_Adress LIKE '%enim%'
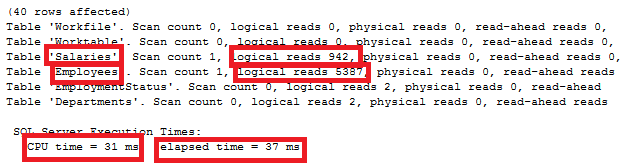
The IO statistics generated by running the previous query shows that 942 logical reads performed on the Salaries table and 5387 logical reads performed on the Employees table to retrieve the requested data. The previous query took 37ms to execute completely, consuming 31ms from the CPU time as shown below:
通过运行上一个查询生成的IO统计信息显示,对Salaries表执行了942次逻辑读取,而对Employees表执行了5387次逻辑读取以检索请求的数据。 上一个查询需要37ms才能完全执行,从CPU时间开始消耗了31ms ,如下所示:
Also, the execution plan generated from the previous query using ApexSQL Plan, shows that a Clustered Index Scan is performed on both Employees and Salaries tables in order to retrieve the requested data, consuming the highest weights from the overall query weight as shown in the execution plan below:
此外,使用ApexSQL Plan从上一个查询生成的执行计划表明,对Employees和Salaries表都执行了聚集索引扫描,以便检索请求的数据,消耗了整个查询权重中最高的权重,如执行所示。计划如下:
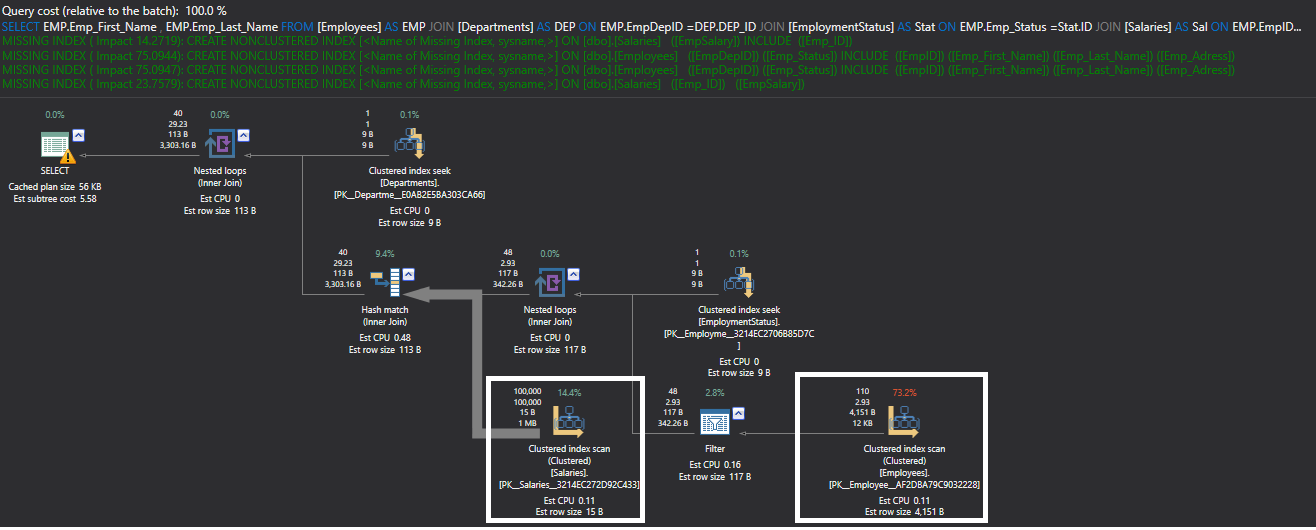
From the previous execution plan, you will find a number of suggested indexes, in green, that SQL Server found that may enhance query performance. You can clearly see that these suggested indexes are on foreign keys columns. It is better always to handle suggested indexes carefully, and make sure that it will speed up the queries without causing any side effects.
在上一个执行计划中,您会发现许多建议的索引(绿色),这些索引是SQL Server发现的,可以增强查询性能。 您可以清楚地看到这些建议的索引在外键列上。 最好始终仔细处理建议的索引,并确保它可以加快查询速度而又不会引起任何副作用。
In addition to the suggested indexes warning provided within the execution plan, we can search for all the foreign keys columns in all the database tables that are not indexed yet. In order to create indexes on these columns. What we will do is:
除了执行计划中提供的建议索引警告之外,我们还可以在所有尚未建立索引的数据库表中搜索所有外键列。 为了在这些列上创建索引。 我们将要做的是:
- sys.foreign_keys system object and fill its information in the #TempForeignKeys temp table. sys.foreign_keys系统对象从所有数据库表中检索所有外键,并将其信息填充在#TempForeignKeys临时表中。
- sys.foreign_keys_columns system object joined with the #TempForeignKeys temp table and sys.index_columns系统对象加入了sys.index_columns system object and fill the object IDs information in the #TempIndexedFK temp table. sys.foreign_keys_columns系统对象检索所有数据库表的所有索引的外键列,并填写在#TempIndexedFK临时表的对象ID信息。
- Retrieve the foreign keys from all database tables that columns are not indexed yet by excluding the result filled in the # TempIndexedFK temp table from the result filled in the #TempForeignKeys temp table. 通过从#TempForeignKeys临时表中填充的结果中排除#TempIndexedFK临时表中填充的结果,从所有尚未索引列的数据库表中检索外键。
Gathering all together, the below T-SQL script can be used to retrieve all foreign keys that columns are not indexed yet:
将所有这些聚集在一起,下面的T-SQL脚本可用于检索尚未为列建立索引的所有外键:
CREATE TABLE #TempForeignKeys (TableName varchar(100), ForeignKeyName varchar(100) , ObjectID int)
INSERT INTO #TempForeignKeys
SELECT OBJ.NAME, ForKey.NAME, ForKey .[object_id]
FROM sys.foreign_keys ForKey
INNER JOIN sys.objects OBJ
ON OBJ.[object_id] = ForKey.[parent_object_id]
WHERE OBJ.is_ms_shipped = 0
CREATE TABLE #TempIndexedFK (ObjectID int)
INSERT INTO #TempIndexedFK
SELECT ObjectID
FROM sys.foreign_key_columns ForKeyCol
JOIN sys.index_columns IDXCol
ON ForKeyCol.parent_object_id = IDXCol.[object_id]
JOIN #TempForeignKeys FK
ON ForKeyCol.constraint_object_id = FK.ObjectID
WHERE ForKeyCol.parent_column_id = IDXCol.column_id
SELECT * FROM #TempForeignKeys WHERE ObjectID NOT IN (SELECT ObjectID FROM #TempIndexedFK)
DROP TABLE #TempForeignKeys
DROP TABLE #TempIndexedFK
The result will show that no index found on the three foreign keys created previously:
结果将显示在先前创建的三个外键上找不到索引:
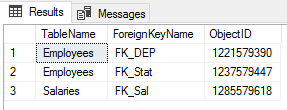
Let us create the below two indexes that include the foreign key columns on both the Employees and Salaries tables using the T-SQL script below:
让我们使用下面的T-SQL脚本创建以下两个索引,其中包括Employees和Salaries表上的外键列:
USE [SQLShackDemo]
GO
CREATE NONCLUSTERED INDEX [IX_Employees_Emp_Status_EmpDepID]
ON [dbo].[Employees] ([Emp_Status],[EmpDepID])
INCLUDE ([EmpID],[Emp_First_Name],[Emp_Last_Name],[Emp_Adress])
GO
CREATE NONCLUSTERED INDEX [IX_Salaries_Emp_ID] ON [dbo].[Salaries]
(
[Emp_ID] ASC
)
INCLUDE ([EmpSalary])
GO
Then try to run the previous SELECT statement again, to check if these two new indexes will enhance the query performance.
然后尝试再次运行前面的SELECT语句,以检查这两个新索引是否可以提高查询性能。
The IO statistics gathered from the new run of the query shows that the number of logical reads on the Salaries table decreased to 96, compared with the 942 logical reads performed before adding the index, with about 90% enhancement to the logical reads on the Salaries table. For the Employees table, the number of logical reads on the table after creating the index is decreased to 9, compared with the 5,387 logical reads performed before adding the index, with about 99% enhancement to the logical reads on the Employees table. The enhancement is clear also from the TIME statistics gathered from the query, where the query took only 1ms to execute completely, compared with the 37ms required to execute the query before adding the indexes, with about 97% enhancement to the total query execution time. No CPU time was consumed to run the query now, compared with 31ms of CPU time consumed before creating the indexes, with 100% enhancement as shown below:
从查询的新运行中收集的IO统计数据表明,与添加索引之前执行的942次逻辑读取相比,在Salaries表上的逻辑读取数减少到96次 ,与Salaries中的逻辑读取相比,增强了大约90%表。 对于Employees表,创建索引后在表上的逻辑读取数减少到9 ,而添加索引之前执行的5,387逻辑读取相比,Employees表上的逻辑读取增加了约99% 。 从查询中收集的TIME统计信息中也可以明显看出这种增强,其中查询完全执行只花了1ms ,而添加索引之前执行查询所需的时间是37ms,与总查询执行时间相比,提高了约97% 。 与创建索引之前消耗31ms的CPU时间相比,现在运行查询不需要消耗任何CPU时间,并且增强了100% ,如下所示:

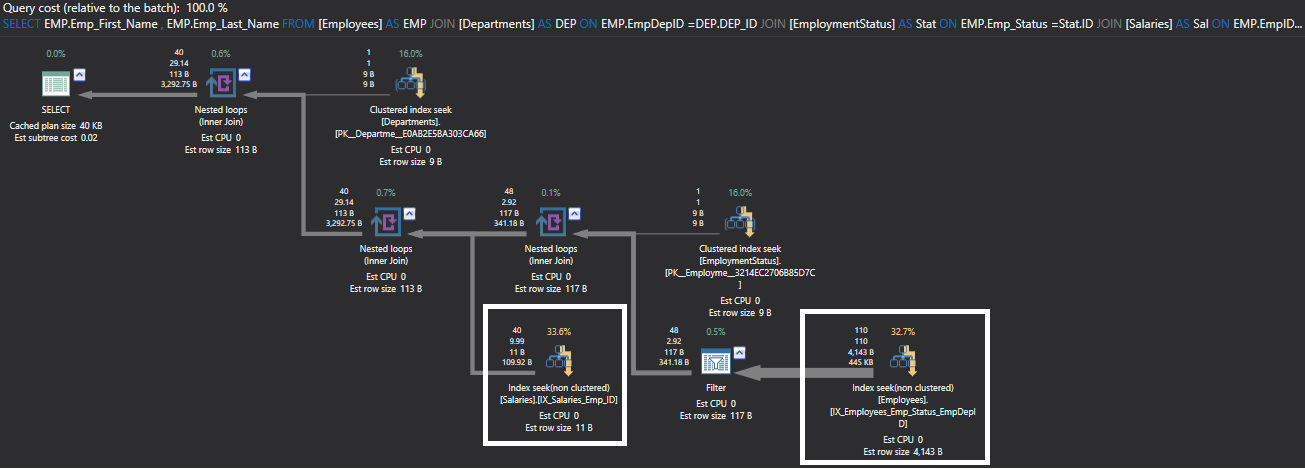
Checking the execution plan that is generated from the previous query after creating the indexes, using ApexSQL Plan. You can clearly see that a much faster index seek process is performed on both the Employees and Salaries tables in order to retrieve the requested data instead of the Clustered Index Scan performed previously, as shown in the execution plan below:
使用ApexSQL Plan检查在创建索引后从上一个查询生成的执行计划。 您可以清楚地看到,Employees和Salaries表上都执行了更快的索引查找过程,以便检索请求的数据,而不是以前执行的“聚集索引扫描”,如下面的执行计划所示:
结论 (Conclusion)
When you define a foreign key constraint in your database table, an index will not be created automatically on the foreign key columns, as in the PRIMARY KEY constraint situation in which a clustered index will be created automatically when defining it. It is highly recommended to create an index on the foreign key columns, to enhance the performance of the joins between the primary and foreign keys, and also reduce the cost of maintaining the relationship between the child and parent tables. Before adding any new indexes, it is better to test on a development environment and monitor the overall performance after the implementation, to make sure that the added indexes improve performance and do not negatively impact the system performance.
当您在数据库表中定义外键约束时,不会在外键列上自动创建索引,就像在PRIMARY KEY约束情况下那样,在定义索引时会自动创建聚簇索引。 强烈建议在外键列上创建索引,以增强主键和外键之间的联接性能,并降低维护子表和父表之间关系的成本。 在添加任何新索引之前,最好在开发环境上进行测试并监视实施后的总体性能,以确保所添加的索引可以提高性能并且不会对系统性能产生负面影响。
翻译自: https://www.sqlshack.com/index-foreign-key-columns-sql-server/















 1310
1310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









