






linux上grep命令

The Linux grep command is a string and pattern matching utility that displays matching lines from multiple files. It also works with piped output from other commands. We show you how.
Linux grep命令是一个字符串和模式匹配实用程序,它显示来自多个文件的匹配行。 它也可以与其他命令的管道输出一起使用。 我们向您展示如何。
grep背后的故事 (The Story Behind grep)
The grep command is famous in Linux and Unix circles for three reasons. Firstly, it is tremendously useful. Secondly, the wealth of options can be overwhelming. Thirdly, it was written overnight to satisfy a particular need. The first two are bang on; the third is slightly off.
由于三个原因, grep命令在Linux和Unix界很出名。 首先,它非常有用。 其次,大量的选择可能是压倒性的。 第三,为了满足特定需要,它一夜之间被编写出来。 前两个爆炸了。 第三是稍微关闭。
Ken Thompson had extracted the regular expression search capabilities from the ed editor (pronounced ee-dee) and created a little program—for his own use—to search through text files. His department head at Bell Labs, Doug Mcilroy, approached Thompson and described the problem one of his colleagues, Lee McMahon, was facing.
Ken Thompson已从ed编辑器(发音为ee-dee )中提取了正则表达式搜索功能,并创建了一个供自己使用的小程序来搜索文本文件。 他在贝尔实验室的部门负责人Doug Mcilroy与Thompson接触,并描述了他的一位同事Lee McMahon所面临的问题。
McMahon was trying to identify the authors of the Federalist papers through textual analysis. He needed a tool that could search for phrases and strings within text files. Thompson spent about an hour that evening making his tool a general utility that could be used by others and renamed it as grep. He took the name from the ed command string g/re/p , which translates as “global regular expression search.”
麦克马洪试图通过文本分析来确定联邦主义者论文的作者。 他需要一个可以在文本文件中搜索短语和字符串的工具。 汤普森那天晚上花了一个小时左右的时间,使他的工具成为可以被其他人使用的通用工具,并将其重命名为grep 。 他从ed命令字符串g/re/p取了名字,该字符串翻译为“全局正则表达式搜索”。
You can watch Thompson talking to Brian Kernighan about the birth of grep.
您可以观看汤普森与Brian Kernighan谈论grep的诞生。
使用grep进行简单搜索 (Simple Searches With grep)
To search for a string within a file, pass the search term and the file name on the command line:
要在文件中搜索字符串,请在命令行中传递搜索词和文件名:

Matching lines are displayed. In this case, it is a single line. The matching text is highlighted. This is because on most distributions grep is aliased to:
显示匹配行。 在这种情况下,它是一行。 匹配的文本突出显示。 这是因为在大多数发行版中, grep的别名为:
alias grep='grep --colour=auto'
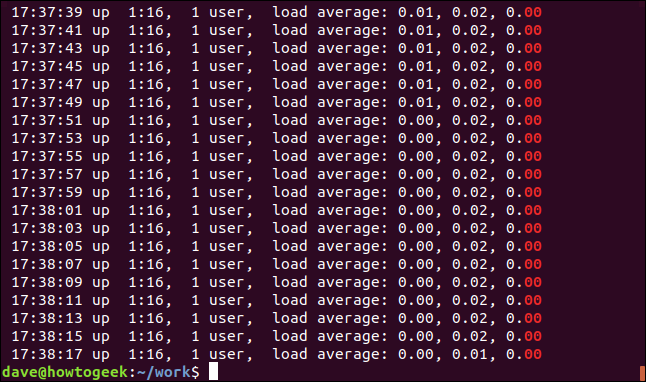
Let’s look at results where there are multiple lines that match. We’ll look for the word “Average” in an application log file. Because we can’t recall if the word is in lowercase in the log file, we’ll use the -i (ignore case) option:
让我们看一下有多行匹配的结果。 我们将在应用程序日志文件中查找“ Average”一词。 因为我们无法记住日志文件中的单词是否为小写字母,所以我们将使用-i (忽略大小写)选项:
grep -i Average geek-1.log

Every matching line is displayed, with the matching text highlighted in each one.
显示每条匹配的行,并在每行中突出显示匹配的文本。
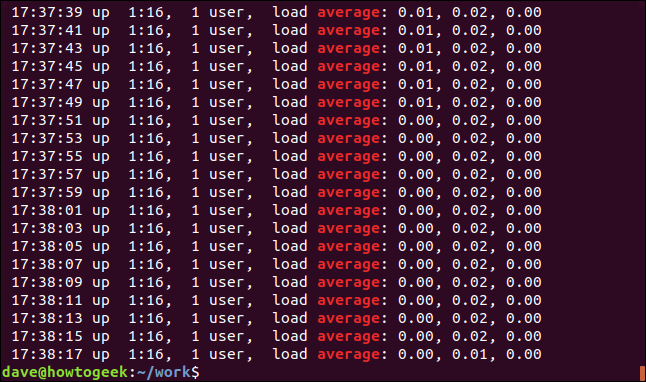
We can display the non-matching lines by using the -v (invert match) option.
我们可以使用-v(反转匹配)选项显示不匹配的行。
grep -v Mem geek-1.log

There is no highlighting because these are the non-matching lines.
没有突出显示,因为这些是不匹配的行。
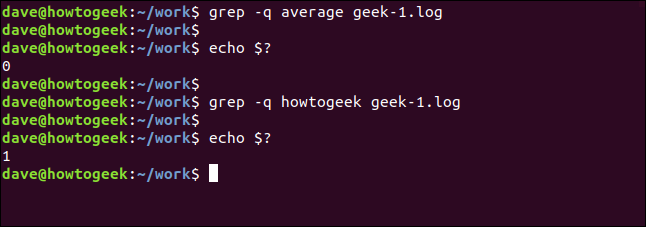
We can cause grep to be completely silent. The result is passed to the shell as a return value from grep. A result of zero means the string was found, and a result of one means it was not found. We can check the return code using the $? special parameters:
我们可以使grep完全保持沉默。 结果作为grep的返回值传递到外壳。 的零种手段串A结果发现,和中的一个装置的结果它没有被发现。 我们可以使用$?检查返回代码$? 特殊参数:
grep -q average geek-1.log
echo $?
grep -q howtogeek geek-1.log
echo $?
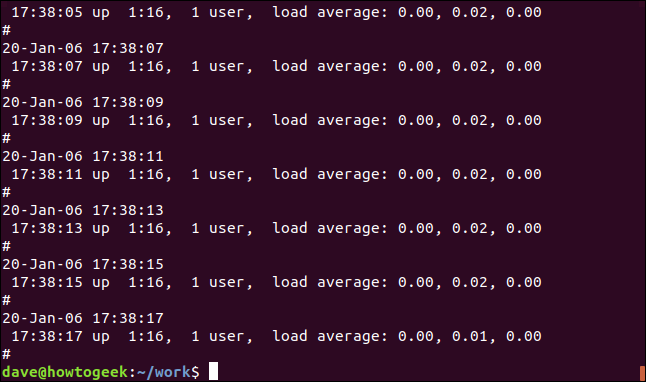
使用grep进行递归搜索 (Recursive Searches With grep)
To search through nested directories and subdirectories, use the -r (recursive) option. Note that you don’t provide a file name on the command line, you must provide a path. Here we’re searching in the current directory “.” and any subdirectories:
要搜索嵌套目录和子目录,请使用-r(递归)选项。 请注意,您没有在命令行上提供文件名,而必须提供路径。 在这里,我们正在当前目录中搜索“。” 以及任何子目录:
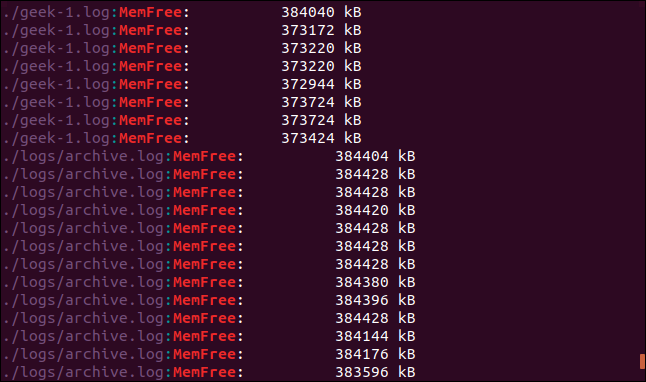
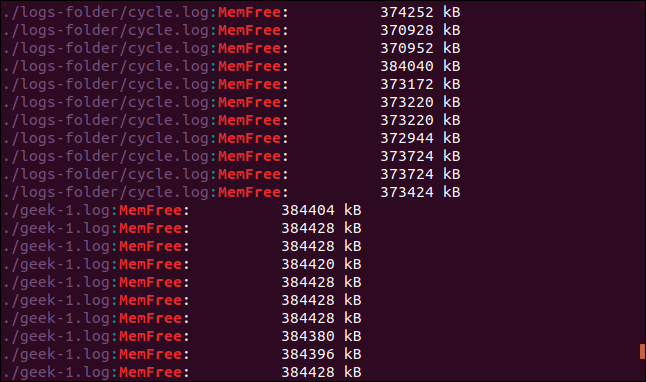
grep -r -i memfree .

The output includes the directory and filename of each matching line.
输出包括每个匹配行的目录和文件名。
We can make grep follow symbolic links by using the -R (recursive dereference) option. We’ve got a symbolic link in this directory, called logs-folder. It points to /home/dave/logs.
我们可以使用-R (递归取消引用)选项使grep跟随符号链接。 在此目录中,我们有一个符号链接,称为logs-folder 。 它指向/home/dave/logs 。
ls -l logs-folder

Let’s repeat our last search with the -R (recursive dereference) option:
让我们使用-R (递归取消引用)选项重复上一次搜索:
grep -R -i memfree .

The symbolic link is followed and the directory it points to is searched by grep too.
跟随符号链接, grep也搜索它指向的目录。
搜索整个词 (Searching for Whole Words)
By default, grep will match a line if the search target appears anywhere in that line, including inside another string. Look at this example. We’re going to search for the word “free.”
默认情况下,如果搜索目标出现在该行的任何位置(包括另一个字符串内),则grep将匹配该行。 看这个例子。 我们将搜索“免费”一词。
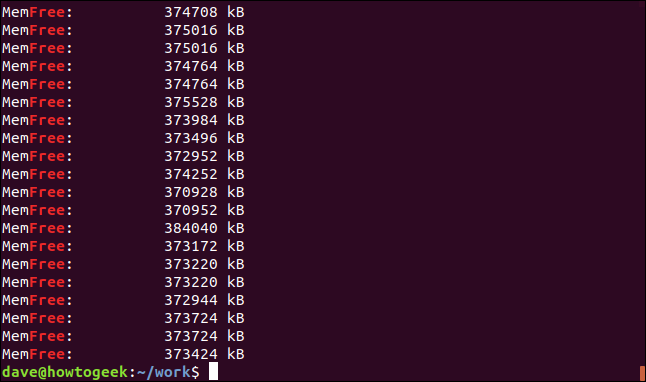
grep -i free geek-1.log

The results are lines that have the string “free” in them, but they’re not separate words. They’re part of the string “MemFree.”
结果是其中包含字符串“ free”的行,但它们不是单独的单词。 它们是字符串“ MemFree”的一部分。
To force grep to match separate “words” only, use the -w (word regexp) option.
要强制grep仅匹配单独的“单词”,请使用-w (单词regexp)选项。
grep -w -i free geek-1.log
echo $?

This time there are no results because the search term “free” does not appear in the file as a separate word.
这次没有结果,因为搜索词“ free”没有在文件中单独出现。
使用多个搜索词 (Using Multiple Search Terms)
The -E (extended regexp) option allows you to search for multiple words. (The -E option replaces the deprecated egrep version of grep.)
-E (扩展的regexp)选项使您可以搜索多个单词。 ( -E选项替换了不建议使用的grep egrep版本。)
This command searches for two search terms, “average” and “memfree.”
该命令搜索两个搜索词“ average”和“ memfree”。
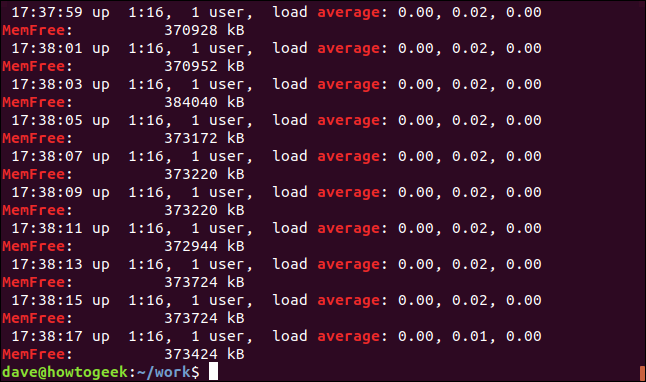
grep -E -w -i "average|memfree" geek-1.log

All of the matching lines are displayed for each of the search terms.
将为每个搜索词显示所有匹配行。
You can also search for multiple terms that are not necessarily whole words, but they can be whole words too.
您还可以搜索不一定是整个单词的多个术语,但也可以是整个单词。
The -e (patterns) option allows you to use multiple search terms on the command line. We’re making use of the regular expression bracket feature to create a search pattern. It tells grep to match any one of the characters contained within the brackets “[].” This means grep will match either “kB” or “KB” as it searches.
-e (模式)选项允许您在命令行上使用多个搜索词。 我们正在使用正则表达式括号功能来创建搜索模式。 它告诉grep匹配括号“ []”中包含的任何字符。 这意味着grep将匹配“ kB”或“ KB”。
![grep -e MemFree -e [kK]B geek-1.log in a terminal window](https://i-blog.csdnimg.cn/blog_migrate/faaf88a2e11f6a2ff86c2a26d9985a34.png)
Both strings are matched, and, in fact, some lines contain both strings.
两个字符串都匹配,实际上,某些行包含两个字符串。
![Output from grep -e MemFree -e [kK]B geek-1.log in a terminal window](https://i-blog.csdnimg.cn/blog_migrate/30fae889d8788158c5ef9f51c5f2434a.png)
精确匹配线 (Matching Lines Exactly)
The -x (line regexp) will only match lines where the entire line matches the search term. Let’s search for a date and time stamp that we know appears only once in the log file:
-x (行正则表达式)仅匹配整行与搜索词匹配的行。 让我们搜索一个我们知道在日志文件中仅出现一次的日期和时间戳:
grep -x "20-Jan--06 15:24:35" geek-1.log

The single line that matches is found and displayed.
找到并显示匹配的单行。
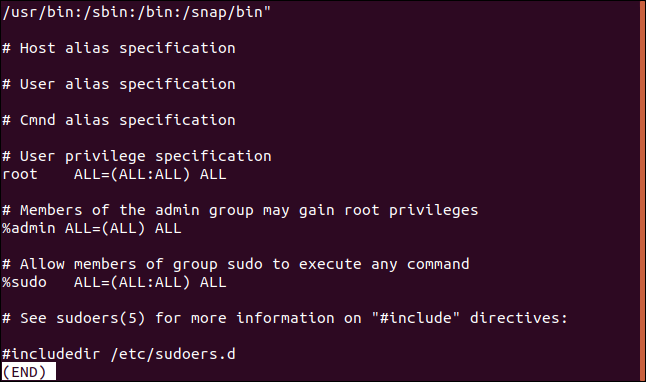
The opposite of that is only showing the lines that don’t match. This can be useful when you’re looking at configuration files. Comments are great, but sometimes it’s hard to spot the actual settings in amongst them all. Here’s the /etc/sudoers file:
相反的是仅显示不匹配的行。 当您查看配置文件时,这可能很有用。 注释很棒,但有时很难在其中找到实际设置。 这是/etc/sudoers文件:
We can effectively filter out the comment lines like this:
我们可以像这样有效地过滤掉注释行:
sudo grep -v "#" /etc/sudoers
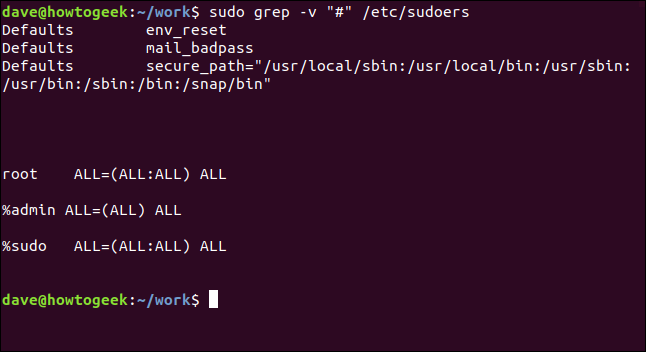
That’s much easier to parse.
这更容易解析。
仅显示匹配文本 (Only Displaying Matching Text)
There may be an occasion when you don’t want to see the entire matching line, just the matching text. The -o (only matching) option does just that.
在某些情况下,您可能不想仅看到匹配的文本,而不会看到整个匹配的行。 -o (仅匹配)选项可以做到这一点。
grep -o MemFree geek-1.log

The display is reduced to showing only the text that matches the search term, instead of the entire matching line.
显示减少为仅显示与搜索词匹配的文本,而不是整个匹配行。

用grep计数 (Counting With grep)
grep isn’t just about text, it can provide numerical information too. We can make grep count for us in different ways. If we want to know how many times a search term appears in a file, we can use the -c (count) option.
grep不仅与文本有关,还可以提供数字信息。 我们可以通过不同的方式使grep计数。 如果我们想知道搜索词在文件中出现多少次,可以使用-c (计数)选项。
grep -c average geek-1.log

grep reports that the search term appears 240 times in this file.
grep报告搜索词在此文件中出现240次。
You can make grep display the line number for each matching line by using the -n (line number) option.
您可以使用-n (行号)选项使grep显示每个匹配行的行号。
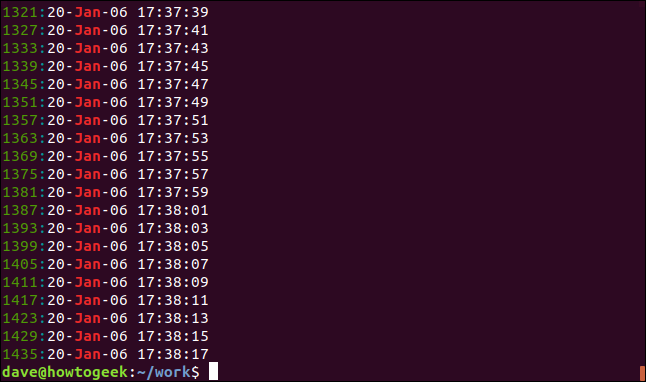
grep -n Jan geek-1.log

The line number for each matching line is displayed at the start of the line.
每条匹配行的行号显示在该行的开头。
To reduce the number of results that are displayed, use the -m (max count) option. We’re going to limit the output to five matching lines:
要减少显示的结果数,请使用-m (最大计数)选项。 我们将输出限制为五行:
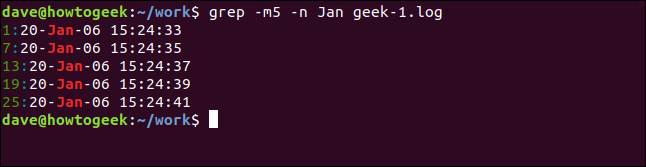
grep -m5 -n Jan geek-1.log
添加上下文 (Adding Context)
Being able to see some additional lines—possibly non-matching lines—for each matching line is often useful. it can help distinguish which of the matched lines are the ones you are interested in.
能够看到每个匹配行的其他一些行(可能是不匹配的行)通常很有用。 它可以帮助您区分哪些匹配的行是您感兴趣的行。
To show some lines after the matching line, use the -A (after context) option. We’re asking for three lines in this example:
要在匹配的行之后显示一些行,请使用-A(在上下文之后)选项。 在此示例中,我们要求输入三行:
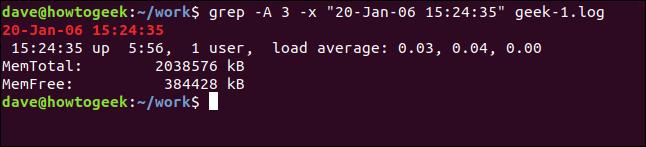
grep -A 3 -x "20-Jan-06 15:24:35" geek-1.log
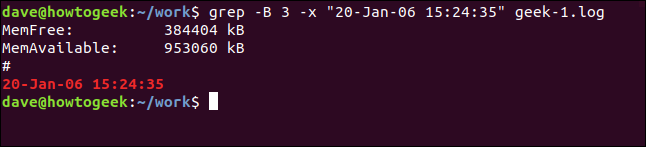
To see some lines from before the matching line, use the -B (context before) option.
要查看匹配行之前的一些行,请使用-B (在上下文之前)选项。
grep -B 3 -x "20-Jan-06 15:24:35" geek-1.log
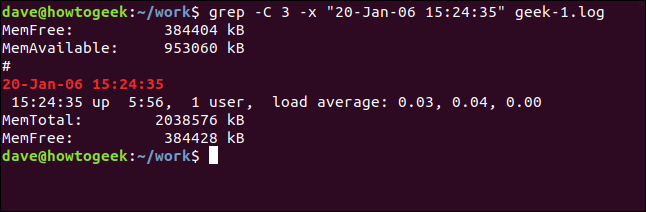
And to include lines from before and after the matching line use the -C (context) option.
要包含匹配行之前和之后的行,请使用-C (上下文)选项。
grep -C 3 -x "20-Jan-06 15:24:35" geek-1.log
显示匹配文件 (Showing Matching Files)
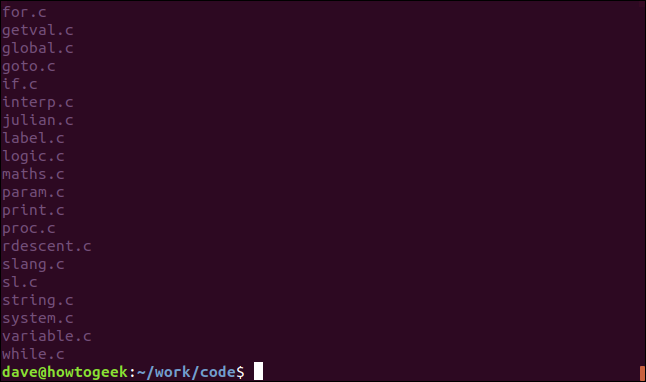
To see the names of the files that contain the search term, use the -l (files with match) option. To find out which C source code files contain references to the sl.h header file, use this command:
要查看包含搜索词的文件的名称,请使用-l (具有匹配项的文件)选项。 要找出哪些C源代码文件包含对sl.h头文件的引用,请使用以下命令:
grep -l "sl.h" *.c

The file names are listed, not the matching lines.
列出了文件名,而不是匹配的行。
And of course, we can look for files that don’t contain the search term. The -L (files without match) option does just that.
当然,我们可以查找不包含搜索词的文件。 -L (不匹配的文件)选项就是这样做的。
grep -L "sl.h" *.c

行的开始和结束 (Start and End of Lines)
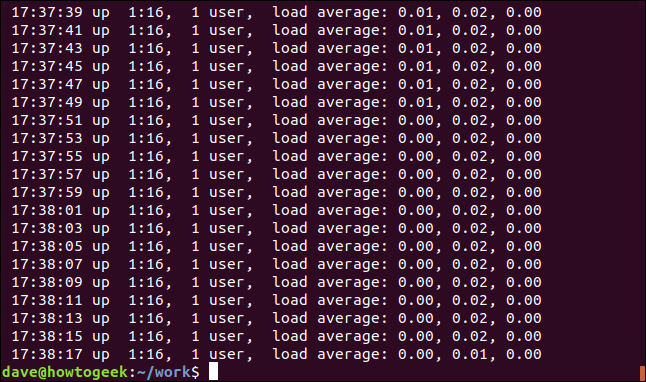
We can force grep to only display matches that are either at the start or the end of a line. The “^” regular expression operator matches the start of a line. Practically all of the lines within the log file will contain spaces, but we’re going to search for lines that have a space as their first character:
我们可以强制grep只显示在行的开头或结尾的匹配项。 正则表达式运算符“ ^”匹配行的开头。 实际上,日志文件中的所有行都将包含空格,但是我们将搜索以空格作为第一个字符的行:
grep "^ " geek-1.log

The lines that have a space as the first character—at the start of the line—are displayed.
显示以空格作为第一个字符的行(在该行的开头)。
To match the end of the line, use the “$” regular expression operator. We’re going to search for lines that end with “00.”
要匹配行尾,请使用“ $”正则表达式运算符。 我们将搜索以“ 00”结尾的行。
grep "00$" geek-1.log

The display shows the lines that have “00” as their final characters.
显示屏显示以“ 00”作为最后字符的行。
在grep中使用管道 (Using Pipes with grep)
Of course, you can pipe input to grep , pipe the output from grep into another program, and have grep nestled in the middle of a pipe chain.
当然,你也可以管道输入到grep ,管从输出grep到另一个程序,并有grep坐落在一个管道链的中间。
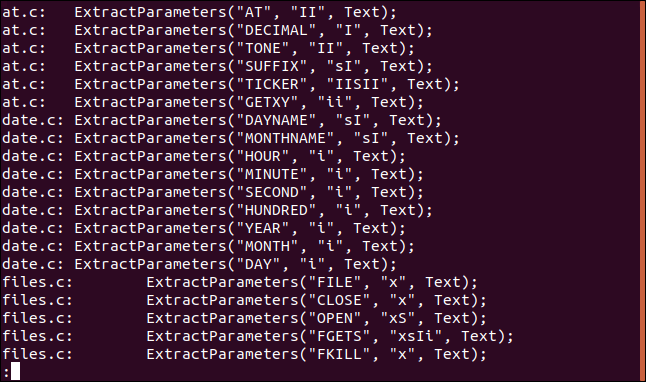
Let’s say we want to see all occurrences of the string “ExtractParameters” in our C source code files. We know there’s going to be quite a few, so we pipe the output into less:
假设我们要查看C源代码文件中所有出现的字符串“ ExtractParameters”。 我们知道将会有很多,所以我们将输出传递给less :
grep "ExtractParameters" *.c | less

The output is presented in less.
输出以less 。
This lets you page through the file listing and to use less's search facility.
这使您可以浏览文件列表并使用less's搜索功能。
If we pipe the output from grep into wc and use the -l (lines) option, we can count the number of lines in the source code files that contain “ExtractParameters”. (We could achieve this using the grep -c (count) option, but this is a neat way to demonstrate piping out of grep.)
如果我们将grep的输出通过管道传输到wc并使用-l (lines)选项,则可以计算源代码文件中包含“ ExtractParameters”的行数。 (我们可以使用grep -c (count)选项实现此目的,但这是演示从grep进行管道化的一种巧妙方法。)
grep "ExtractParameters" *.c | wc -l

With the next command, we’re piping the output from ls into grep and piping the output from grep into sort . We’re listing the files in the current directory, selecting those with the string “Aug” in them, and sorting them by file size:
使用下一条命令,我们将ls的输出ls给grep并将grep的输出grep给sort 。 我们将列出当前目录中的文件,选择其中包含字符串“ Aug”的文件,然后按文件大小对其进行排序:
ls -l | grep "Aug" | sort +4n
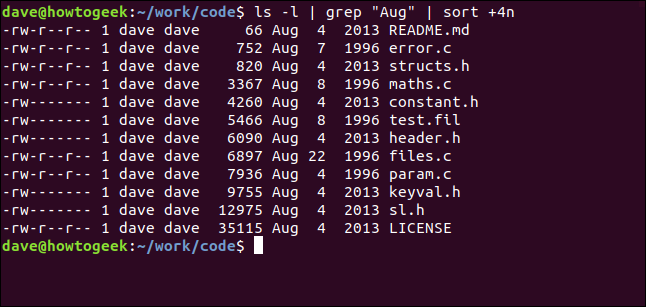
Let’s break that down:
让我们分解一下:
ls -l: Perform a long format listing of the files using
ls.ls -l :使用
ls执行文件的长格式列表。grep “Aug”: Select the lines from the
lslisting that have “Aug” in them. Note that this would also find files that have “Aug” in their names.grep“ Aug” :从
ls列表中选择带有“ Aug”的行。 请注意,这还将查找名称中带有“ Aug”的文件。sort +4n: Sort the output from grep on the fourth column (filesize).
sort + 4n :对第四列的grep输出(文件大小)进行排序。
We get a sorted listing of all the files modified in August (regardless of year), in ascending order of file size.
我们获得了按文件大小的升序排列的所有文件的排序列表,这些文件在八月(不考虑年份)中进行了修改。
grep:更少的命令,更多的盟友 (grep: Less a Command, More of an Ally)
grep is a terrific tool to have at your disposal. It dates from 1974 and is still going strong because we need what it does, and nothing does it better.
grep是一个很棒的工具供您使用。 它的历史可以追溯到1974年,但由于我们需要它所做的一切,而它却没有更好的表现,因此它仍然很强大。
Coupling grep with some regular expressions-fu really takes it to the next level.
将grep与一些正则表达式结合起来,确实可以将grep提升到一个新的水平。
翻译自: https://www.howtogeek.com/496056/how-to-use-the-grep-command-on-linux/
linux上grep命令


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









