






To source data for data science projects, you’ll often rely on SQL and NoSQL databases, APIs, or ready-made CSV data sets.
为了为数据科学项目提供数据,您通常将依赖于SQL和NoSQL数据库, API或现成的CSV数据集。
The problem is that you can’t always find a data set on your topic, databases are not kept current and APIs are either expensive or have usage limits.
问题在于,您无法始终找到有关主题的数据集,数据库无法保持最新状态,API要么昂贵要么受到使用限制。
If the data you’re looking for is on an web page, however, then the solution to all these problems is web scraping.
但是,如果您要查找的数据在网页上,则所有这些问题的解决方案是web scraping 。

In this tutorial we’ll learn to scrape multiple web pages with Python using BeautifulSoup and requests. We’ll then perform some simple analysis using pandas, and matplotlib.
在本教程中,我们将学习使用BeautifulSoup和request使用Python抓取多个网页。 然后,我们将使用pandas和matplotlib进行一些简单的分析。
You should already have some basic understanding of HTML, a good grasp of Python’s basics, and a rough idea about what web scraping is. If you are not comfortable with these, I recommend this beginner web scraping tutorial.
您应该已经对HTML有了一些基本的了解,对Python的基本知识有了很好的了解,并对Web抓取是一个大致的了解。 如果您对这些内容不满意,建议您阅读此初学者网络抓取教程 。
抓取超过2000部电影的数据 (Scraping data for over 2000 movies)
We want to analyze the distributions of IMDB and Metacritic movie ratings to see if we find anything interesting. To do this, we’ll first scrape data for over 2000 movies.
我们想分析IMDB和Metacritic电影收视率的分布,看看是否发现任何有趣的东西。 为此,我们将首先抓取超过2000部电影的数据。
It’s essential to identify the goal of our scraping right from the beginning. Writing a scraping script can take a lot of time, especially if we want to scrape more than one web page. We want to avoid spending hours writing a script which scrapes data we won’t actually need.
从一开始就确定我们的抓取目标至关重要。 编写抓取脚本会花费很多时间,尤其是如果我们要抓取多个网页时,尤其如此。 我们希望避免花费大量时间编写一个脚本,该脚本会收集我们实际上不需要的数据。
找出要抓取的页面 (Working out which pages to scrape)
Once we’ve established our goal, we then need to identify an efficient set of pages to scrape.
一旦确定了目标,我们就需要确定一组有效的页面进行抓取。
We want to find a combination of pages that requires a relatively small number of requests. A request is what happens whenever we access a web page. We ‘request’ the content of a page from the server. The more requests we make, the longer our script will need to run, and the greater the strain on the server.
我们希望找到需要较少数量请求的页面组合。 请求是我们访问网页时发生的事情。 我们从服务器“请求”页面的内容。 我们发出的请求越多,脚本需要运行的时间就越长,并且对服务器的压力也越大。
One way to get all the data we need is to compile a list of movie names, and use it to access the web page of each movie on both IMDB and Metacritic websites.
获取我们所需所有数据的一种方法是编译电影名称列表,并使用它来访问IMDB和Metacritic网站上每部电影的网页。
Since we want to get over 2000 ratings from both IMDB and Metacritic, we’ll have to make at least 4000 requests. If we make one request per second, our script will need a little over an hour to make 4000 requests. Because of this, it’s worth trying to identify more efficient ways of obtaining our data.
由于我们希望同时获得IMDB和Metacritic的2000多个评分,因此我们必须至少提出4000个请求。 如果我们每秒发出一个请求,那么脚本将需要一个多小时来发出4000个请求。 因此,值得尝试找出更有效的方式来获取我们的数据。
If we explore the IMDB website, we can discover a way to halve the number of requests. Metacritic scores are shown on the IMDB movie page, so we can scrape both ratings with a single request:
如果我们浏览IMDB网站,我们可以找到一种将请求数量减半的方法。 Metacritic得分显示在IMDB电影页面上,因此我们可以在一个请求中同时抓取两个等级:
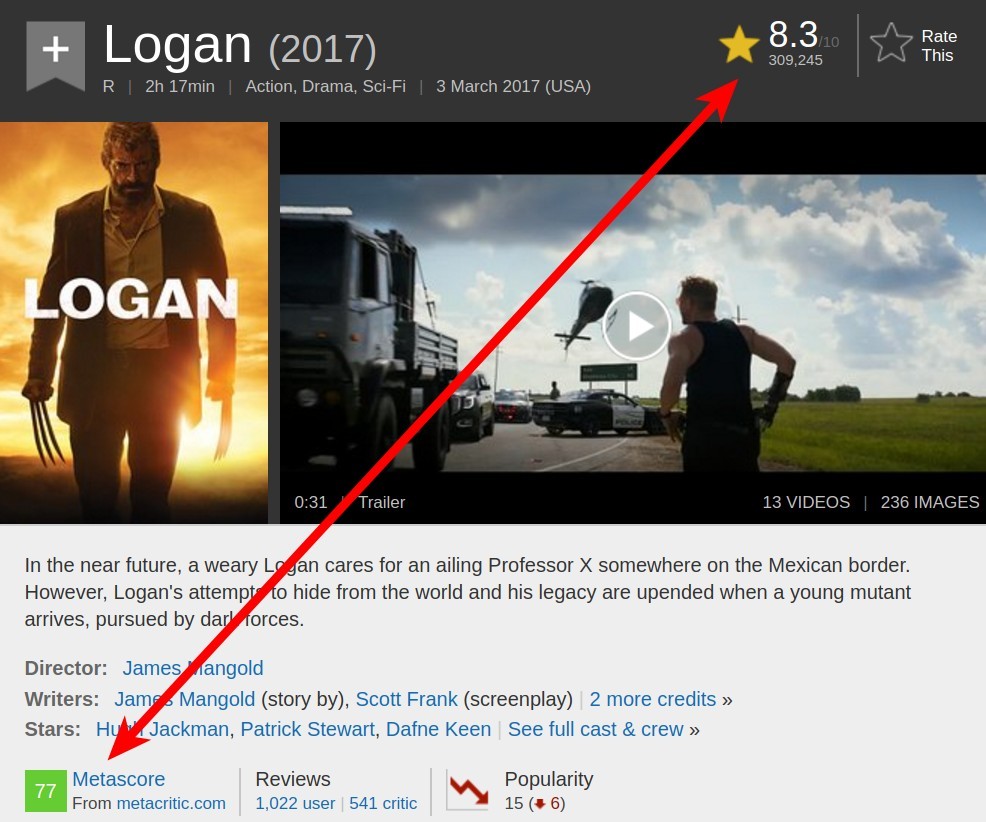
If we investigate the IMDB site further, we can discover the page shown below. It contains all the data we need for 50 movies. Given our aim, this means we’ll only have to do about 40 requests, which is 100 times less than our first option. Let’s explore this last option further.
如果我们进一步调查IMDB网站,则会发现下面显示的页面。 它包含了50部电影所需的所有数据。 按照我们的目标,这意味着我们只需要处理大约40个请求,这比我们的第一种选择少100倍。 让我们进一步探讨最后一个选项。

识别URL结构 (Identifying the URL structure)
Our challenge now is to make sure we understand the logic of the URL as the pages we want to scrape change. If we can’t understand this logic enough so we can implement it into code, then we’ll reach a dead end.
现在,我们面临的挑战是确保我们了解要抓取更改的页面时URL的逻辑。 如果我们对这种逻辑不够了解,无法将其实现为代码,那么我们将陷入僵局。
If you go on IMDB’s advanced search page, you can browse movies by year:
Let’s browse by year 2017, sort the movies on the first page by number of votes, then switch to the next page. We’ll arrive at this web page, which has this URL:
让我们按2017年浏览,按票数对第一页上的电影进行排序,然后切换到下一页。 我们将到达此网页 ,该网页具有以下URL:

In the image above, you can see that the URL has several parameters after the question mark:
在上图中,您可以看到URL在问号后面有几个参数:
release_date– Shows only the movies released in a specific year.sort– Sorts the movies on the page.sort=num_votes,desctranslates to sort by number of votes in a descending order.page– Specifies the page number.ref_– Takes us to the the next or the previous page. The reference is the page we are currently on.adv_nxtandadv_prvare two possible values. They translate to advance to the next page, and advance to the previous page, respectively.
-
release_date–仅显示特定年份发行的电影。 -
sort–对页面上的影片进行排序。sort=num_votes,desc转换为按票数降序排列。 -
page–指定页码。 -
ref_–将我们带到下一页或上一页。 参考是我们当前所在的页面。adv_nxt和adv_prv是两个可能的值。 它们分别翻译以前进到下一页和前进到前一页。
If you navigate through those pages and observe the URL, you will notice that only the values of the parameters change. This means we can write a script to match the logic of the changes and make far fewer requests to scrape our data.
如果您浏览这些页面并观察URL,您会注意到只有参数值会更改。 这意味着我们可以编写一个脚本来匹配更改的逻辑,并且发出更少的请求来抓取我们的数据。
Let’s start writing the script by requesting the content of this single web page: http://www.imdb.com/search/title?release_date=2017&sort=num_votes,desc&page=1. In the following code cell we will:
让我们通过请求以下单个网页的内容开始编写脚本: http://www.imdb.com/search/title?release_date=2017&sort=num_votes,desc&page=1 : http://www.imdb.com/search/title?release_date=2017&sort=num_votes,desc&page=1 ?release_date=2017&sort=num_votes,desc&page http://www.imdb.com/search/title?release_date=2017&sort=num_votes,desc&page=1 。 在以下代码单元中,我们将:
- Import the
get()function from therequestsmodule. - Assign the address of the web page to a variable named
url. - Request the server the content of the web page by using
get(), and store the server’s response in the variableresponse. - Print a small part of
response’s content by accessing its.textattribute (responseis now aResponseobject).
- 从
requests模块导入get()函数。 - 将网页地址分配给名为
url的变量。 - 使用
get()向服务器请求网页的内容,并将服务器的响应存储在变量response。 - 通过访问
response文本的.text属性(response现在是Response对象),打印response内容的一小部分。
from from requests requests import import get
get
url url = = 'http://www.imdb.com/search/title?release_date=2017&sort=num_votes,desc&page=1'
'http://www.imdb.com/search/title?release_date=2017&sort=num_votes,desc&page=1'
response response = = getget (( urlurl )
)
printprint (( responseresponse .. texttext [:[: 500500 ])
])
<!DOCTYPE html>
<html
xmlns:og="http://ogp.me/ns#"
xmlns:fb="http://www.facebook.com/2008/fbml">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="apple-itunes-app" content="app-id=342792525, app-argument=imdb:///?src=mdot">
<script type="text/javascript">var ue_t0=window.ue_t0||+new Date();</script>
<script type="text/javascript">
var ue_mid = "A1EVAM02EL8SFB";
了解单个页面HTML结构 (Understanding the HTML structure of a single page)
As you can see from the first line of response.text, the server sent us an HTML document. This document describes the overall structure of that web page, along with its specific content (which is what makes that particular page unique).
从response.text的第一行可以看到,服务器向我们发送了一个HTML文档。 本文档描述了该网页的整体结构及其特定内容(这是使该特定页面唯一的原因)。
All the pages we want to scrape have the same overall structure. This implies that they also have the same overall HTML structure. So, to write our script, it will suffice to understand the HTML structure of only one page. To do that, we’ll use the browser’s Developer Tools.
我们要抓取的所有页面都具有相同的整体结构。 这意味着它们也具有相同的整体HTML结构。 因此,编写我们的脚本,仅了解一页HTML结构就足够了。 为此,我们将使用浏览器的开发人员工具 。
If you use Chrome, right-click on a web page element that interests you, and then click Inspect. This will take you right to the HTML line that corresponds to that element:
如果您使用的是Chrome浏览器 ,请右键单击您感兴趣的网页元素,然后单击“检查”。 这将使您直接转到与该元素对应HTML行:
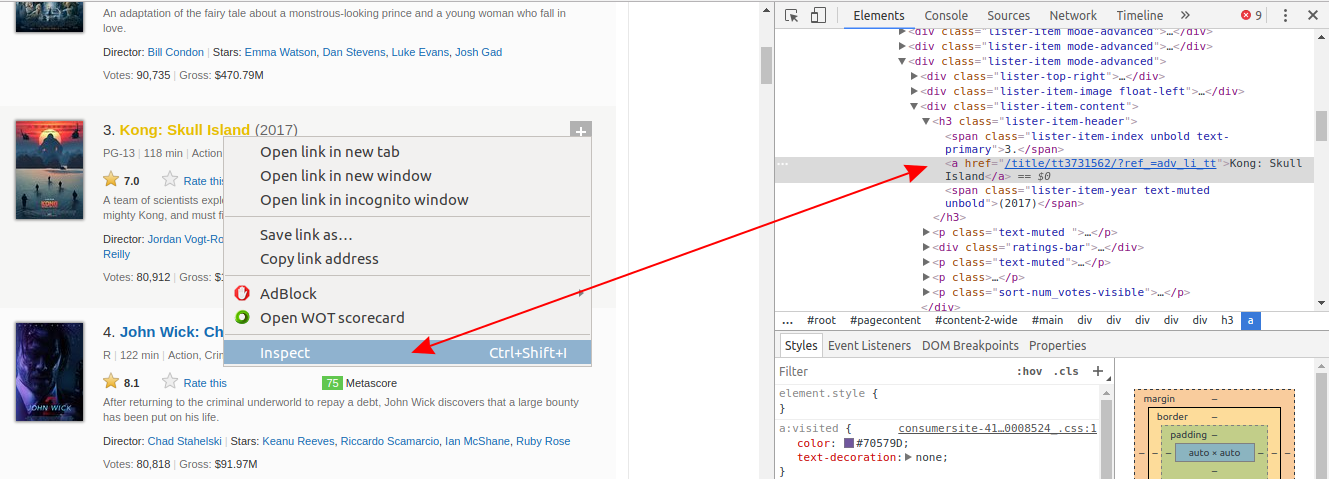
Right-click on the movie’s name, and then left-click Inspect. The HTML line highlighted in gray corresponds to what the user sees on the web page as the movie’s name.
右键单击电影的名称,然后左键单击“检查”。 用灰色突出显示HTML行与用户在网页上看到的电影名称相对应。
You can also do this using both Firefox and Safari DevTools.
您也可以同时使用Firefox和Safari DevTools进行此操作。
Notice that all of the information for each movie, including the poster, is contained in a div tag.
请注意,每个电影(包括海报)的所有信息都包含在div标签中。

There are a lot of HTML lines nested within each div tag. You can explore them by clicking those little gray arrows on the left of the HTML lines corresponding to each div. Within these nested tags we’ll find the information we need, like a movie’s rating.
每个div标签中嵌套了许多HTML行。 您可以通过单击与每个div对应HTML行左侧的灰色小箭头来浏览它们。 在这些嵌套标签中,我们将找到所需的信息,例如电影的分级。
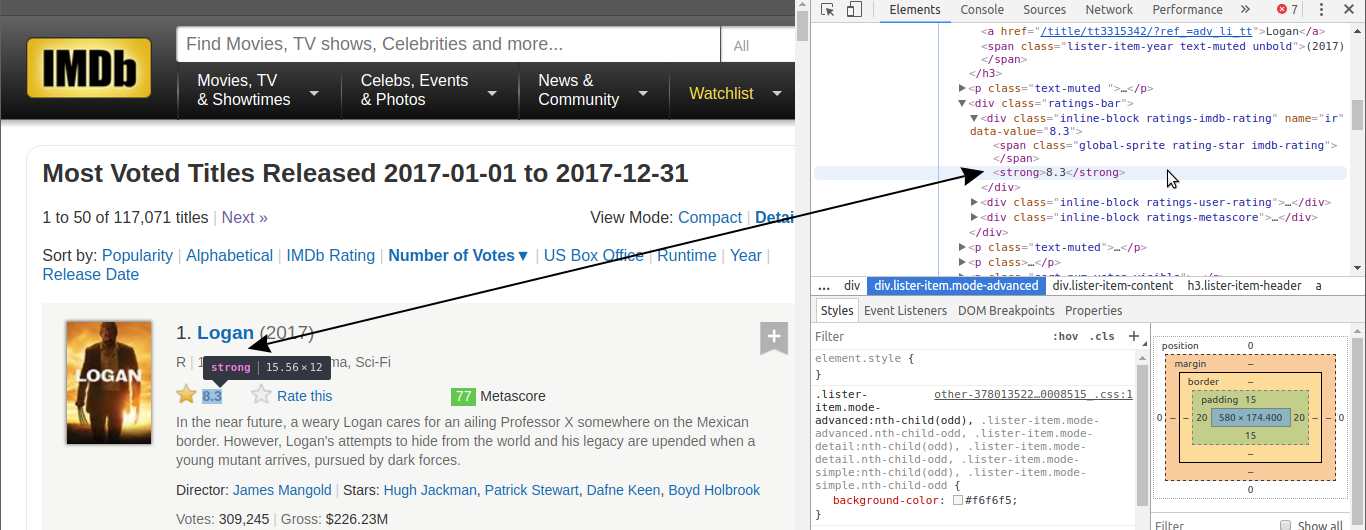
There are 50 movies shown per page, so there should be a div container for each. Let’s extract all these 50 containers by parsing the HTML document from our earlier request.
每页显示50个电影,因此每个电影应有一个div容器。 让我们通过解析先前请求中HTML文档来提取所有这50个容器。
使用BeautifulSoup解析HTML内容 (Using BeautifulSoup to parse the HTML content)
To parse our HTML document and extract the 50 div containers, we’ll use a Python module called BeautifulSoup, the most common web scraping module for Python.
为了解析HTML文档并提取50个div容器,我们将使用一个名为BeautifulSoup的Python模块,这是Python最常见的Web抓取模块。
In the following code cell we will:
在以下代码单元中,我们将:
- Import the
BeautifulSoupclass creator from the packagebs4. - Parse
response.textby creating aBeautifulSoupobject, and assign this object tohtml_soup. The'html.parser'argument indicates that we want to do the parsing using Python’s built-in HTML parser.
- 从包
bs4导入BeautifulSoup类创建者。 - 通过创建
BeautifulSoup对象来解析response.text,并将该对象分配给html_soup。'html.parser'参数指示我们要使用Python的内置HTML解析器进行解析 。
bs4.BeautifulSoup
Before extracting the 50 div containers, we need to figure out what distinguishes them from other div elements on that page. Often, the distinctive mark resides in the class attribute. If you inspect the HTML lines of the containers of interest, you’ll notice that the class attribute has two values: lister-item and mode-advanced. This combination is unique to these div containers. We can see that’s true by doing a quick search (Ctrl + F). We have 50 such containers, so we expect to see only 50 matches:
在提取50个div容器之前,我们需要弄清它们与该页面上其他div元素的区别。 通常,独特标记位于class 属性中 。 如果检查感兴趣的容器HTML行,则会注意到class属性具有两个值: lister-item和mode-advanced 。 这些组合对于这些div容器是唯一的。 通过执行快速搜索( Ctrl + F ),我们可以看到这是正确的。 我们有50个这样的容器,因此我们预计只会看到50个匹配项:

Now let’s use the find_all() method to extract all the div containers that have a class attribute of lister-item mode-advanced:
现在,让我们使用find_all() 方法提取所有具有lister-item mode-advanced class属性的div容器:
movie_containers movie_containers = = html_souphtml_soup .. find_allfind_all (( 'div''div' , , class_ class_ = = 'lister-item mode-advanced''lister-item mode-advanced' )
)
printprint (( typetype (( movie_containersmovie_containers ))
))
printprint (( lenlen (( movie_containersmovie_containers ))
))
<class 'bs4.element.ResultSet'>
50
find_all() returned a ResultSet object which is a list containing all the 50 divs we are interested in.
find_all()返回一个ResultSet对象,该对象是一个列表,其中包含我们感兴趣的所有50个divs 。
Now we’ll select only the first container, and extract, by turn, each item of interest:
现在,我们将只选择第一个容器,然后依次提取每个感兴趣的项目:
- The name of the movie.
- The year of release.
- The IMDB rating.
- The Metascore.
- The number of votes.
- 电影的名称。
- 发布年份。
- IMDB评级。
- Metascore。
- 票数。
We can access the first container, which contains information about a single movie, by using list notation on movie_containers.
通过使用movie_containers上的列表符号,我们可以访问第一个容器,其中包含有关单个电影的信息。
<div class="lister-item mode-advanced">
<div class="lister-top-right">
<div class="ribbonize" data-caller="filmosearch" data-tconst="tt3315342"></div>
</div>
<div class="lister-item-image float-left">
<a href="/title/tt3315342/?ref_=adv_li_i"> <img alt="Logan" class="loadlate" data-tconst="tt3315342" height="98" loadlate="https://images-na.ssl-images-amazon.com/images/M/MV5BMjQwODQwNTg4OV5BMl5BanBnXkFtZTgwMTk4MTAzMjI@._V1_UX67_CR0,0,67,98_AL_.jpg" src="http://ia.media-imdb.com/images/G/01/imdb/images/nopicture/large/film-184890147._CB522736516_.png" width="67 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









