





Python熊猫– GroupBy (Python Pandas – GroupBy)
GroupBy method can be used to work on group rows of data together and call aggregate functions. It allows to group together rows based off of a column and perform an aggregate function on them.
GroupBy方法可用于一起处理分组数据行并调用聚合函数。 它允许基于列将行分组在一起,并对它们执行聚合功能。
Consider the below example, there are three partitions of IDS (1, 2, and 3) and several values for them. We can now group by the ID column and aggregate them using some sort of aggregate function. Here we are sum-ing the values and putting the values.
考虑下面的示例,有三个IDS分区(1、2和3),以及它们的几个值。 现在,我们可以按ID列进行分组,并使用某种聚合函数对其进行聚合。 在这里,我们将这些值相加并放入这些值。
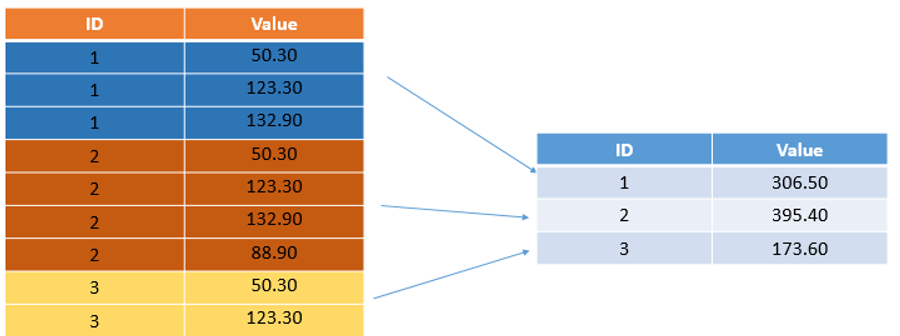
与熊猫团购 (Groupby with Pandas)
Create a dataframe from a dictionary
从字典创建数据框
import numpy as np
import pandas as pd
data = {'company':['Google','Microsoft','FB','Google','FB'], 'person':['Molly','Nathaniel', 'Sriansh', 'Carl','Sarah'], 'Sales':[200,123,130,144,122]}
df = pd.DataFrame(data)
print(df)
Output
输出量
company person Sales
0 Google Molly 200
1 Microsoft Nathaniel 123
2 FB Sriansh 130
3 Google Carl 144
4 FB Sarah 122
Following examples illustrate the 'GroupBy' function,
以下示例说明了“ GroupBy”功能 ,
Example 1: GroupBy by 'company'
示例1:按“公司”分组
# returns the groubBy object
print(df.groupby('company'))
'''
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x7f1721585350>
'''
by_company = df.groupby('company')
#invoke aggregate function
print(by_company.mean())
'''
Sales
company
FB 126
Google 172
Microsoft 123
'''
In the above example, we don't see the person column, because the data type is String and by no means, we can get mean of String variables, and hence Pandas automatically ignores any non-numeric values.
在上面的示例中,我们没有看到person列,因为数据类型是String ,但绝不能获得String变量的均值 ,因此Pandas自动忽略任何非数字值。
Below are some more examples of aggregate functions,
以下是聚合函数的更多示例,
print(by_company.sum())
'''
Output:
Sales
company
FB 252
Google 344
Microsoft 123
'''
print(by_company.std())
'''
Output:
Sales
company
FB 5.656854
Google 39.597980
Microsoft NaN
'''
Note the return type of the values are by default a DataFrame, as illustrated below,
请注意,默认情况下,值的返回类型为DataFrame,如下所示,
std = by_company.std()
print(type(std))
'''
Output:
<class 'pandas.core.frame.DataFrame'>
'''
And, hence we can perform all the dataFrame functions such as,
并且,因此我们可以执行所有dataFrame函数,例如,
print(by_company.std().loc['FB'])
'''
Output:
Sales 5.656854
Name: FB, dtype: float64
'''
The above mentioned steps, all can be performed in a single step as follows,
上述步骤全部可以在一个步骤中执行,如下所示:
print(df.groupby('company').sum().loc['FB'])
'''
Output:
Sales 252
Name: FB, dtype: int64
'''
Some more aggregate functions are,
还有一些聚合函数,
print(df.groupby('company').count())
'''
Output:
person Sales
company
FB 2 2
Google 2 2
Microsoft 1 1
'''
print(df.groupby('company').max())
'''
Output:
person Sales
company
FB Sriansh 130
Google Molly 200
Microsoft Nathaniel 123
'''
print(df.groupby('company').min())
'''
Output:
person Sales
company
FB Sarah 122
Google Carl 144
Microsoft Nathaniel 123
'''
使用具有描述方法的GroupBy (Using GroupBy with describe method)
The describe() method returns a bunch of useful information all at once.
describe()方法一次返回一堆有用的信息。
print(df.groupby('company').describe())
'''
Output:
Sales ...
count mean std ... 50% 75% max
company ...
FB 2.0 126.0 5.656854 ... 126.0 128.0 130.0
Google 2.0 172.0 39.597980 ... 172.0 186.0 200.0
Microsoft 1.0 123.0 NaN ... 123.0 123.0 123.0
[3 rows x 8 columns]
'''
The format of the description can be changed using transpose() method,
可以使用transpose()方法更改描述的格式,
print(df.groupby('company').describe().transpose())
'''
Output:
company FB Google Microsoft
Sales count 2.000000 2.00000 1.0
mean 126.000000 172.00000 123.0
std 5.656854 39.59798 NaN
min 122.000000 144.00000 123.0
25% 124.000000 158.00000 123.0
50% 126.000000 172.00000 123.0
75% 128.000000 186.00000 123.0
max 130.000000 200.00000 123.0
'''
翻译自: https://www.includehelp.com/python/python-pandas-groupby.aspx















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









