






web服务器和数据服务器
2010 update: Lo, the Web Performance Advent Calendar hath moved
2010年更新: Lo, Web Performance Advent Calendar已移动
Dec 8 This article is part of the 2009 performance advent calendar experiment. This is also the first ever guest post to this blog. Please welcome the world-famous Christian Heilmann! And stay tuned for the next articles.
12月8日本文是2009年性能出现日历实验的一部分。 这也是该博客的第一篇客座帖子。 请欢迎举世闻名的克里斯蒂安·海尔曼(Christian Heilmann) ! 并继续关注下一篇文章。
 Chris Heilmann is a self confessed data junkie and worked for over 12 years as a professional web developer. Having published several books on JavaScript, Accessibility and web development using web services he right now works as a developer evangelist for the Yahoo Developer Network. He blogs at 克里斯·海尔曼(Chris Heilmann)是一个自认是数据迷的人,作为专业的Web开发人员已经工作了12年以上。 在出版了几本有关使用Web服务JavaScript,可访问性和Web开发的书籍之后,他现在担任Yahoo Developer Network的开发人员。 他的博客位于
Chris Heilmann is a self confessed data junkie and worked for over 12 years as a professional web developer. Having published several books on JavaScript, Accessibility and web development using web services he right now works as a developer evangelist for the Yahoo Developer Network. He blogs at 克里斯·海尔曼(Chris Heilmann)是一个自认是数据迷的人,作为专业的Web开发人员已经工作了12年以上。 在出版了几本有关使用Web服务JavaScript,可访问性和Web开发的书籍之后,他现在担任Yahoo Developer Network的开发人员。 他的博客位于
RSS is a wonderful format to get information from all kind of different sources. It is dead easy to provide, has a predictable (albeit limited) format and is very easy to use. The problem of course is that with the amount of different feeds used in one page its performance goes down.
RSS是一种出色的格式,可以从各种不同的来源获取信息。 它非常容易提供,具有可预测的格式(尽管有限),并且非常易于使用。 当然,问题在于一页中使用的不同Feed的数量会降低其性能。
The reason is the classic HTTP request issue - the more you negotiate, find and pull the slower your page renders. Therefore you need to try to shorten the time the calls happen.
原因是经典的HTTP请求问题-您协商,查找和拉出的内容越多,页面呈现的速度就越慢。 因此,您需要尝试缩短呼叫发生的时间。
Say you want to pull the following five RSS feeds and display them:
假设您要拉出以下五个RSS提要并显示它们:
- http://code.flickr.com/blog/feed/rss/ http://code.flickr.com/blog/feed/rss/
- http://feeds.delicious.com/v2/rss/codepo8?count=15 http://feeds.delicious.com/v2/rss/codepo8?count=15
- http://www.stevesouders.com/blog/feed/rss http://www.stevesouders.com/blog/feed/rss
- http://www.yqlblog.net/blog/feed/ http://www.yqlblog.net/blog/feed/
- http://www.quirksmode.org/blog/index.xml http://www.quirksmode.org/blog/index.xml
The least effective way of doing that is pulling and displaying them one after the other:
这样做的最无效方法是将它们一个接一个地拉出并显示:
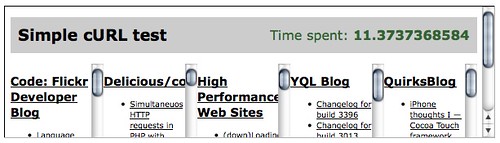
$oldtime = microtime(true);
$url = 'http://code.flickr.com/blog/feed/rss/';
$content[] = get($url);
$url = 'http://feeds.delicious.com/v2/rss/codepo8?count=15';
$content[] = get($url);
$url = 'http://www.stevesouders.com/blog/feed/rss';
$content[] = get($url);
$url = 'http://www.yqlblog.net/blog/feed/';
$content[] = get($url);
$url = 'http://www.quirksmode.org/blog/index.xml';
$content[] = get($url);
display($content);
echo '<p>Time spent: <strong>' . (microtime(true)-$oldtime) .'</strong></p>';
function get($url){
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($ch);
curl_close($ch);
return $output;
}
function display($data){
foreach($data as $d){
$obj = simplexml_load_string($d);
echo '<div><h2><a href="'.$obj->channel->link.'">'.
$obj->channel->title.'</a></h2>';
echo '<ul>';
foreach($obj->channel->item as $i){
echo '<li><a href="'.$i->link.'">'.$i->title.'</a></li>';
}
echo '</ul></div>';
}
}
Using Stoyan's Multi Curl function you already realise quite an increase in speed.
使用Stoyan的Multi Curl功能,您已经实现了速度的极大提高。
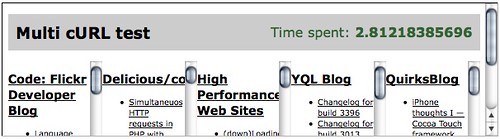
$data = array(
'http://code.flickr.com/blog/feed/rss/',
'http://feeds.delicious.com/v2/rss/codepo8?count=15',
'http://www.stevesouders.com/blog/feed/rss',
'http://www.yqlblog.net/blog/feed/',
'http://www.quirksmode.org/blog/index.xml'
);
$r = multiRequest($data);
display($r);
function multiRequest($data, $options = array()) {
// array of curl handles
$curly = array();
// data to be returned
$result = array();
// multi handle
$mh = curl_multi_init();
// loop through $data and create curl handles
// then add them to the multi-handle
foreach ($data as $id => $d) {
$curly[$id] = curl_init();
$url = (is_array($d) && !empty($d['url'])) ? $d['url'] : $d;
curl_setopt($curly[$id], CURLOPT_URL, $url);
curl_setopt($curly[$id], CURLOPT_HEADER, 0);
curl_setopt($curly[$id], CURLOPT_RETURNTRANSFER, 1);
// post?
if (is_array($d)) {
if (!empty($d['post'])) {
curl_setopt($curly[$id], CURLOPT_POST, 1);
curl_setopt($curly[$id], CURLOPT_POSTFIELDS, $d['post']);
}
}
// extra options?
if (!empty($options)) {
curl_setopt_array($curly[$id], $options);
}
curl_multi_add_handle($mh, $curly[$id]);
}
// execute the handles
$running = null;
do {
curl_multi_exec($mh, $running);
} while($running > 0);
// get content and remove handles
foreach($curly as $id => $c) {
$result[$id] = curl_multi_getcontent($c);
curl_multi_remove_handle($mh, $c);
}
// all done
curl_multi_close($mh);
return $result;
}
function display($data){
foreach($data as $d){
$obj = simplexml_load_string($d);
echo '<div><h2><a href="'.$obj->channel->link.'">'.
$obj->channel->title.'</a></h2>';
echo '<ul>';
foreach($obj->channel->item as $i){
echo '<li><a href="'.$i->link.'">'.$i->title.'</a></li>';
}
echo '</ul></div>';
}
}
However, there are still two things that are annoying:
但是,仍然有两件事很烦人:
- You pull far more data than you really need 您提取的数据远远超出您的实际需要
- You do all the request from your server您从服务器执行所有请求
Yahoo Pipes has been used for that kind of task for quite a while, but the issue was that it is a visual interface and therefore hard to maintain. The server was also not the best performing out there.
Yahoo Pipes已经用于此类任务已有很长时间了,但是问题在于它是可视界面,因此难以维护。 服务器也不是最好的。
The good news is that there is a new(er) kid on the block in Yahoo Land called YQL running on a massively fast server farm and with one purpose: making it easier to use web services, mix them and get only the data back that you want.
好消息是,Yahoo Land的一个街区有一个名为YQL的新孩子正在一个大型的快速服务器场上运行,其目的是:简化Web服务的使用,混合以及仅获取返回的数据。你要。
YQL in itself is a web service and you post queries to it that access other web services in a SQL style syntax. Normally you'd get RSS feeds using the RSS table, like so:
YQL本身就是Web服务,您可以向其发布查询,这些查询以SQL样式语法访问其他Web服务。 通常,您将使用RSS表获得RSS feed,如下所示:
select * from rss where url="http://feeds.delicious.com/v2/rss/codepo8?count=15"
See the single RSS in the YQL console (you need a Yahoo account to log in). You can also see the single RSS retrieval output.
在YQL控制台中查看单个RSS (您需要Yahoo帐户登录)。 您还可以看到单个RSS检索输出。
The issue with this is that it only retrieves the items of the RSS feed and not the title, which we need for the headings. Therefore we need to use the XML table:
这样做的问题是,它仅检索RSS feed的项目,而不检索标题所需的标题。 因此,我们需要使用XML表:
select * from xml where url="http://feeds.delicious.com/v2/rss/codepo8?count=15"
See the single XML in the YQL console (you need a Yahoo account to log in). You can also see the single XML retrieval output.
在YQL控制台中查看单个XML (您需要Yahoo帐户登录)。 您还可以看到单个XML检索输出。
This gives us the same data the normal cURL calls give us. The cool thing about YQL is though that you can filter the data you get back to the bare minimum. In our case, this means replacing the * with the title and the link of the feed and of the items:
这给了我们正常的cURL调用给我们的相同数据。 关于YQL的最酷的事情是,您可以过滤返回到最低限度的数据。 在我们的例子中,这意味着用标题和提要和项目链接的*代替*:
select channel.title,channel.link,channel.item.title,channel.item.link
from xml
where url="http://feeds.delicious.com/v2/rss/codepo8?count=15"
See the filtered RSS in the YQL console (you need a Yahoo account to log in). You can also see the filtered RSS retrieval output.
在YQL控制台中查看过滤的RSS (您需要Yahoo帐户登录)。 您还可以看到过滤后的RSS检索输出。
In order to use this with all of our RSS feeds, we can use the in() command:
为了在我们所有的RSS feed中使用它,我们可以使用in()命令:
select channel.title,channel.link,channel.item.title,channel.item.link
from xml where url in(
'http://code.flickr.com/blog/feed/rss/',
'http://feeds.delicious.com/v2/rss/codepo8?count=15',
'http://www.stevesouders.com/blog/feed/rss',
'http://www.yqlblog.net/blog/feed/',
'http://www.quirksmode.org/blog/index.xml'
)
Check the aggregation in the console or the aggregation output.
This leaves all the hard work to the Yahoo Server farm. YQL pulls all the RSS feeds, adds one after the other and then gives it back to us as XML. We could simply use the generated URL from the console, but it is much more versatile to assemble the query in PHP:
这将所有艰苦的工作留给了Yahoo Server服务器场。 YQL提取所有RSS提要,一个接一个地添加,然后将其作为XML返回给我们。 我们可以简单地使用从控制台生成的URL,但是在PHP中组合查询的用途更加广泛:
$data = array(
'http://code.flickr.com/blog/feed/rss/',
'http://feeds.delicious.com/v2/rss/codepo8?count=15',
'http://www.stevesouders.com/blog/feed/rss',
'http://www.yqlblog.net/blog/feed/',
'http://www.quirksmode.org/blog/index.xml'
);
$url ='http://query.yahooapis.com/v1/public/yql?q=';
$query = "select channel.title,channel.link,channel.item.title,channel.item.link from xml where url in('".implode("','",$data)."')";
$url.=urlencode($query).'&format=xml';
$content = get($url);
display($content);
function get($url){
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($ch);
curl_close($ch);
return $output;
}
function display($data){
$data = simplexml_load_string($data);
$sets = $data->results->rss;
$all = sizeof($sets);
for($i=0;$i<$all;$i++){
$r = $sets[$i];
$title = $r->channel->title.'';
if($title != $oldtitle){
echo '<div><h2><a href="'.($r->channel->link.'').'">'.
($r->channel->title.'').'</a></h2><ul>';
}
echo '<li><a href="'.($r->channel->item->link.'').'">'.
($r->channel->item->title.'').'</a></li>';
if($title != $sets[$i+1]->channel->title.''){
echo '</ul></div>';
}
$oldtitle = $r->channel->title.'';
};
}
As you can see the loop to display the different RSS feeds a bit clunky and we could use an open YQL table to move the whole conversion to a server-side JavaScript. However, as it is the performance of this way of retrieving the RSS feeds beats all the others hands-down already:
如您所见,显示不同RSS提要的循环有点笨拙,我们可以使用一个打开的YQL表将整个转换移至服务器端JavaScript 。 但是,由于这种检索RSS feed的方式的性能已经击败了其他所有方法:
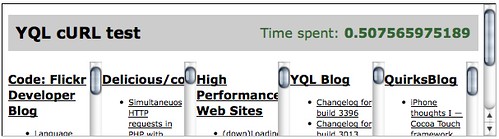
You can try it yourself, get the demo code from GitHub and run it on your own server to see the magic of YQL.
您可以自己尝试,从GitHub获取演示代码,然后在自己的服务器上运行它,以查看YQL的魔力。
Tell your friends about this post on Facebook and Twitter
在Facebook和Twitter上告诉您的朋友有关此帖子的信息
翻译自: https://www.phpied.com/collecting-web-data-with-a-faster-free-server/
web服务器和数据服务器















 5164
5164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









