






冷备份 日志文件 归档文件
Update: Second part
更新:第二部分
One way to do web performance research is to dig into what's out there. It's a tradition dating back from Steve Souders and his HPWS where he was looking at the top 10 Alexa sites for proof that best practices are or aren't followed. This involves loading each pages and inspecting the body or the response headers. Pros: real sites. Cons: manual labor, small sample.
进行网络性能研究的一种方法是挖掘其中的内容。 这是一项传统,可追溯到史蒂夫·索德斯( Steve Souders)和他的HPWS ,他一直在Alexa排名前10的站点中寻找证据,以证明是否遵循或不遵循最佳实践。 这涉及加载每个页面并检查正文或响应标题。 优点:真正的网站。 缺点:体力劳动,样品少。
I've done some image and CSS optimization research grabbing data in any way that looks easy: using the Yahoo image search API to get URLs or using Fiddler to monitor and export the traffic and loading a bazillion sites in IE with a script. Or using HTTPWatch. Pros: big sample. Cons: reinvent the wheel and use a different sampling criteria every time.
我已经完成了一些图像和CSS优化研究,以看起来很容易的任何方式获取数据:使用Yahoo图像搜索API获取URL或使用Fiddler监视和导出流量,并使用脚本在IE中加载庞大的网站。 或使用HTTPWatch 。 优点:大样本。 缺点:重新发明轮子,每次使用不同的采样标准。
Today we have httparchive.org which makes performance research so much easier. It already has a bunch of data you can export and dive into immediately. It's also a common starting point so two people can examine the same data independently and compare or reproduce each other's results.
今天,我们有了httparchive.org ,它使性能研究非常容易。 它已经具有大量数据,您可以将其导出并立即进入。 这也是一个共同的出发点,因此两个人可以独立检查相同的数据并比较或复制彼此的结果。
Let's see how to get started with the HTTP archive's data.
让我们看看如何开始使用HTTP存档的数据。

(Assuming MacOS, but the differences with other OS are negligible)
(假设为MacOS,但与其他操作系统的差异可以忽略不计)
1. Install MySQL 2. Your mysql binary will be in /usr/local/mysql/bin/mysql. Feel free to create an alias. Your username is root and no password. This is of course terribly insecure but for a local machine with no important data, it's probably tolerable. Connect:
1.安装MySQL 2.您的mysql二进制文件位于/usr/local/mysql/bin/mysql 。 随意创建别名。 您的用户名是root ,没有密码。 这当然是非常不安全的,但是对于没有重要数据的本地计算机来说,这是可以容忍的。 连接:
$ /usr/local/mysql/bin/mysql -u root
You'll see some text and a friendly cursor:
您会看到一些文本和一个友好的光标:
...
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
3. Create your new shiny database:
3.创建新的闪亮数据库:
mysql> create database httparchive;
Query OK, 1 row affected (0.00 sec)
Look into the new DB, it's empty, no tables or data, as expected:
查看新的数据库,它是空的,没有表或数据,如预期的那样:
mysql> \u httparchive
Database changed
mysql> show tables;
Empty set (0.00 sec)
4. Quit mysql for now:
4.现在退出mysql:
mysql> quit;
Bye
5. Go the archive and fetch the database schema.
$ curl http://httparchive.org/downloads/httparchive_schema.sql > ~/Downloads/schema.sql
While you're there get the latest DB dump. That would be the link that says IE. Today it says Dec 15 and is 2.5GB. So be prepared. Save it and unzip it as, say, ~/Downloads/dump.sql
当您在那里时,可获得最新的数据库转储。 那就是说IE的链接。 今天它说12月15日,是2.5GB。 所以要做好准备。 保存并解压缩为~/Downloads/dump.sql
6. Recreate the DB tables:
6.重新创建数据库表:
$ /usr/local/mysql/bin/mysql -u root httparchive < ~/Downloads/schema.sql
7. Import the data (takes a while):
7.导入数据(需要一段时间):
$ /usr/local/mysql/bin/mysql -u root httparchive < ~/Downloads/dump.sql
8. Log back into mysql and look around:
8.重新登录mysql并环顾四周:
$ /usr/local/mysql/bin/mysql -u root httparchive;
[yadda, yadda...]
mysql> show tables;
+-----------------------+
| Tables_in_httparchive |
+-----------------------+
| pages |
| pagesmobile |
| requests |
| requestsmobile |
| stats |
+-----------------------+
5 rows in set (0.00 sec)
Dataaaa!
达塔!
What's in the requests table I couldn't help but wonder (damn you, SATC)
我不禁想知道requests表中的内容(该死,SATC)
mysql> describe requests;
+------------------------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------------------+------------------+------+-----+---------+----------------+
| requestid | int(10) unsigned | NO | PRI | NULL | auto_increment |
| pageid | int(10) unsigned | NO | MUL | NULL | |
| startedDateTime | int(10) unsigned | YES | MUL | NULL | |
| time | int(10) unsigned | YES | | NULL | |
| method | varchar(32) | YES | | NULL | |
| url | text | YES | | NULL | |
| urlShort | varchar(255) | YES | | NULL | |
| redirectUrl | text | YES | | NULL | |
| firstReq | tinyint(1) | NO | | NULL | |
| firstHtml | tinyint(1) | NO | | NULL | |
| reqHttpVersion | varchar(32) | YES | | NULL | |
| reqHeadersSize | int(10) unsigned | YES | | NULL | |
| reqBodySize | int(10) unsigned | YES | | NULL | |
| reqCookieLen | int(10) unsigned | NO | | NULL | |
| reqOtherHeaders | text | YES | | NULL | |
| status | int(10) unsigned | YES | | NULL | |
| respHttpVersion | varchar(32) | YES | | NULL | |
| respHeadersSize | int(10) unsigned | YES | | NULL | |
| respBodySize | int(10) unsigned | YES | | NULL | |
| respSize | int(10) unsigned | YES | | NULL | |
| respCookieLen | int(10) unsigned | NO | | NULL | |
| mimeType | varchar(255) | YES | | NULL | |
.....
Hm, I wonder what are common mime types these days. Limiting to 10000 or more occurrences of the same mime type, because there's a lot of garbage out there. If you've never looked into real web data, you'd surprised how much misconfiguration is going on. It's a small miracle the web even works.
嗯,我想知道这些天常见的哑剧类型是什么。 由于存在大量垃圾,因此最多可以限制10000个或更多相同MIME类型的事件。 如果您从未研究过真实的Web数据,那么您会惊讶于正在发生的配置错误。 网络甚至可以工作,这是一个小奇迹。
9. Most common mime types:
9.最常见的哑剧类型:
select count(requestid) as ct, mimeType
from requests
group by mimeType
having ct > 10000
order by ct desc;
+---------+-------------------------------+
| ct | mimeType |
+---------+-------------------------------+
| 7448471 | image/jpeg |
| 4640536 | image/gif |
| 4293966 | image/png |
| 2843749 | text/html |
| 1837887 | application/x-javascript |
| 1713899 | text/javascript |
| 1455097 | text/css |
| 1093004 | application/javascript |
| 619605 | |
| 343018 | application/x-shockwave-flash |
| 188799 | image/x-icon |
| 169928 | text/plain |
| 70226 | text/xml |
| 50439 | font/eot |
| 45416 | application/xml |
| 41052 | application/octet-stream |
| 38618 | application/json |
| 30201 | text/x-cross-domain-policy |
| 25248 | image/vnd.microsoft.icon |
| 20513 | image/jpg |
| 12854 | application/vnd.ms-fontobject |
| 11788 | image/pjpeg |
+---------+-------------------------------+
22 rows in set (2 min 25.18 sec)
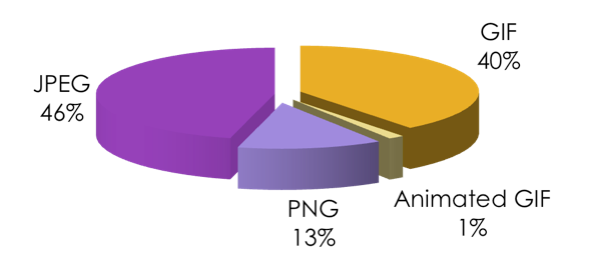
So the web is mostly made of JPEGs. GIFs are still more than PNGs despite all best efforts. Although OTOH (assuming these are comparable datasets), PNG is definitely gaining compared to this picture from two and a half years ago. Anyway.
因此,网络主要由JPEG组成。 尽管已尽了最大努力,但GIF仍然超过PNG。 尽管OTOH(假设这些是可比较的数据集),但与两年半前的这张图片相比,PNG肯定在增长。 无论如何。
是你的时间! (It's you time!)
So this is how easy it is to get started with the HTTPArchive. What experiment would you run with this data?
因此,开始使用HTTPArchive很容易。 您将使用此数据进行什么实验?
Tell your friends about this post on Facebook and Twitter
在Facebook和Twitter上告诉您的朋友有关此帖子的信息
冷备份 日志文件 归档文件















 301
301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}