





 本文介绍了Selenium中XPath的用途,基本语法和不同类型的XPath表达式。当其他定位器无法找到网页元素时,XPath成为Selenium的重要定位策略。文章详细讲解了绝对XPath和相对XPath的区别,并提供了生成XPath的方法,包括在Chrome浏览器中的操作。此外,还讨论了XPath函数,如contains(), starts-with()和text(),以及它们在动态页面元素定位中的应用。"
139568659,7337247,AI映射技术在网络安全中的智能应用,"['人工智能', '深度学习', '网络安全', '大数据', '机器学习']
本文介绍了Selenium中XPath的用途,基本语法和不同类型的XPath表达式。当其他定位器无法找到网页元素时,XPath成为Selenium的重要定位策略。文章详细讲解了绝对XPath和相对XPath的区别,并提供了生成XPath的方法,包括在Chrome浏览器中的操作。此外,还讨论了XPath函数,如contains(), starts-with()和text(),以及它们在动态页面元素定位中的应用。"
139568659,7337247,AI映射技术在网络安全中的智能应用,"['人工智能', '深度学习', '网络安全', '大数据', '机器学习']
In Selenium, if elements are not found with locators like name, id, class, linkText, partialLinkText then XPath is used to find an element on the web page.
在Selenium中,如果找不到带有诸如名称,id,类,linkText,partialLinkText之类的定位符的元素,则使用XPath在网页上查找元素。
什么是XPath? (What is XPath?)
XPath also defined as XML path. It is a query language used for navigating through XML documents in order to locate different elements. It is one of the important strategies to locate elements in selenium. XPath is used to locate a web element on a webpage by using the HTML DOM Structure.
XPath也定义为XML路径 。 它是一种查询语言,用于浏览XML文档以查找不同的元素。 在Selenium中定位元素是重要的策略之一。 XPath用于通过使用HTML DOM结构在网页上定位Web元素。
The basic syntax for XPath is explained below with screenshot.
XPath的基本语法将在下面通过屏幕截图进行说明。
Syntax XPath
语法XPath
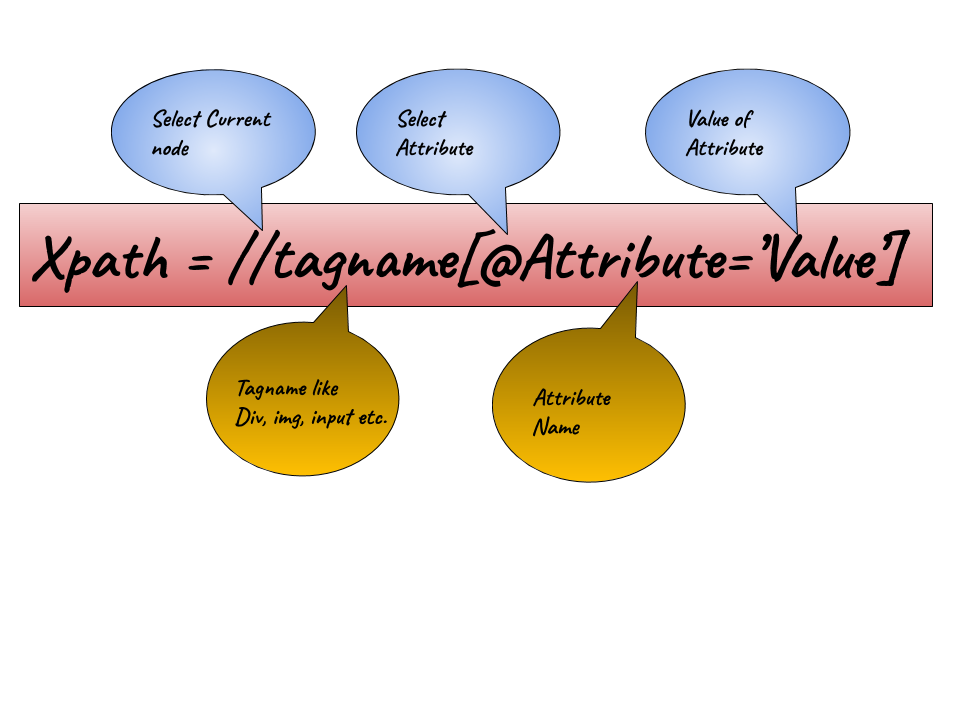
XPath的语法 (Syntax for XPath)
The basic syntax of an XPath is:
XPath的基本语法为:
//tag[@attributeName='attributeValues']- //: It is used to fetch the current node. //:用于获取当前节点。
- tagname: It is the tagname of a particular node. 标记名:这是特定节点的标记名。
- @: It is used to select attribute. @:用于选择属性。
- Attribute: It is the attribute name of the node. 属性:这是节点的属性名称。
- Value: It is the value of the attribute. 值:这是属性的值。
XPath表达式的类型 (Types of XPath Expressions)
There are two types of XPath expressions.
XPath表达式有两种类型。
- Absolute XPath 绝对XPath
- Relative XPath 相对XPath
绝对XPath (Absolute XPath)
It is the direct way to find the element on the web page. The main disadvantage of absolute XPath is that if there are any changes made by developers in the path of the element then our written XPath will no longer work. The advantage of using absolute XPath is that it identifies the element very fast.
这是在网页上查找元素的直接方法。 绝对XPath的主要缺点是,如果开发人员对元素的路径进行了任何更改,则我们编写的XPath将不再起作用。 使用绝对XPath的优点是它可以非常快速地识别元素。
The main characteristic of XPath is that the XPath expressions created using absolute XPath begin with the single forward slash(/), which means begins the selection from the root node.
XPath的主要特征是使用绝对XPath创建的XPath表达式以单个正斜杠(/)开头,这意味着从根节点开始选择。
Example:
例:
/html/head/body/table/tbody/tr/thIf there is a tag added between body and table as below.
如下所示,是否在主体和表格之间添加了标签。
html/head/body/form/table/tbody/tr/thThe first path will not work as “form” tag is added in between.
第一个路径将不起作用,因为在两者之间添加了“ form”标签。
相对XPath (Relative XPath)
A relative XPath is one where the path starts from the middle of the HTML DOM structure of your choice. It doesn’t need to start from the root node, which means it can search for the element anywhere at the webpage.
相对的XPath是从您选择HTML DOM结构的中间开始的路径。 它不需要从根节点开始,这意味着它可以在网页上的任何位置搜索元素。
Example
例
//input[@id='ap_email']Now, let’s understand with an example.
现在,让我们看一个例子。
Here we will launch Google Chrome and navigate to google.com.
在这里,我们将启动Google Chrome浏览器并导航到google.com。
Here, we will try to locate the search bar by using XPath.
在这里,我们将尝试使用XPath定位搜索栏。
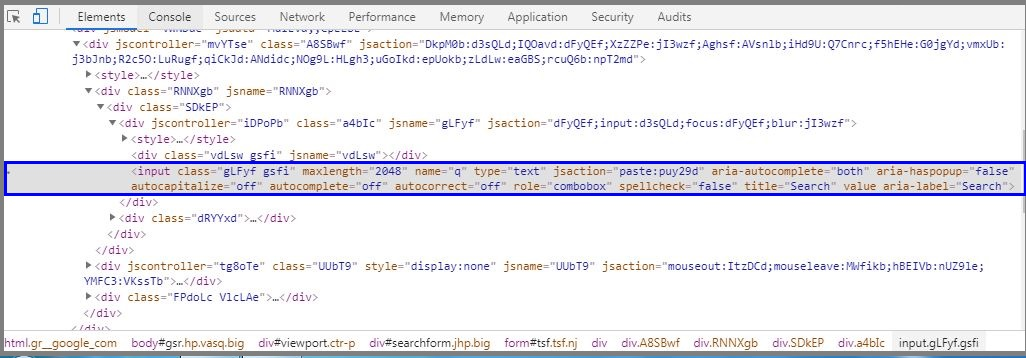
On inspecting the web element (search bar) you can see it has an input tag and attributes like id and class.
在检查Web元素(搜索栏)时,您可以看到它具有输入标签以及诸如id和class之类的属性。
Now, we use the tag name and attributes to generate XPath which in turn will locate the search bar.
现在,我们使用标签名称和属性来生成XPath,XPath随后将找到搜索栏。
Inspect Google Search Xpath
检查Google搜索Xpath
Here, just click Elements tab and press Ctrl + F to open a search box in chromes developers tool.
在这里,只需点击“元素”标签,然后按Ctrl + F即可在Chrome开发者工具中打开搜索框。
Next, you can write XPath, string selector and it will try to search the element based on that criteria.
接下来,您可以编写XPath,字符串选择器,它将尝试根据该条件搜索元素。
As you can see in the above image, it has an input tag.
如上图所示,它具有一个输入标签。
Now I will start with // input. Here //input implies tag name.
现在,我将从//输入开始。 //输入暗示标签名称。
Now, I will use the name attribute and pass ‘q’ in single quotes as its value. This gives XPath expression as below:
现在,我将使用name属性,并在单引号中传递“ q”作为其值。 这给出了XPath表达式,如下所示:
//input[@name='q']
Searchbox XPath Name
Searchbox XPath名称
As you can see from the above image, it has highlighted the element on writing the XPath which implies that particular element was located using XPath.
从上图可以看到,它突出显示了编写XPath时的元素,这意味着该特定元素是使用XPath定位的。
如何生成XPath (How to generate XPath)
Usually, we generate the XPath in two ways – manually and by using Inbuilt utilities. But in manual case, sometimes the HTML file is quite big or complex and writing the XPath of each and every element manually would be a quite difficult task. In this case, there are certain utilities which can help us.
通常,我们以两种方式生成XPath-手动或使用内置实用程序。 但是在手动情况下,有时HTML文件很大或很复杂,而手动编写每个元素的XPath将会是一项艰巨的任务。 在这种情况下,某些实用程序可以为我们提供帮助。
- Chrome Browser: It has Inbuilt utility to inspect and generate the XPath. Chrome浏览器 :它具有内置实用程序,可以检查和生成XPath。
Example:
例:
In the below example, we open Chrome browser and login to Facebook application by entering Email, Password and by clicking Log In button.
在下面的示例中,我们打开Chrome浏览器,并通过输入电子邮件,密码并单击登录按钮来登录Facebook应用程序。
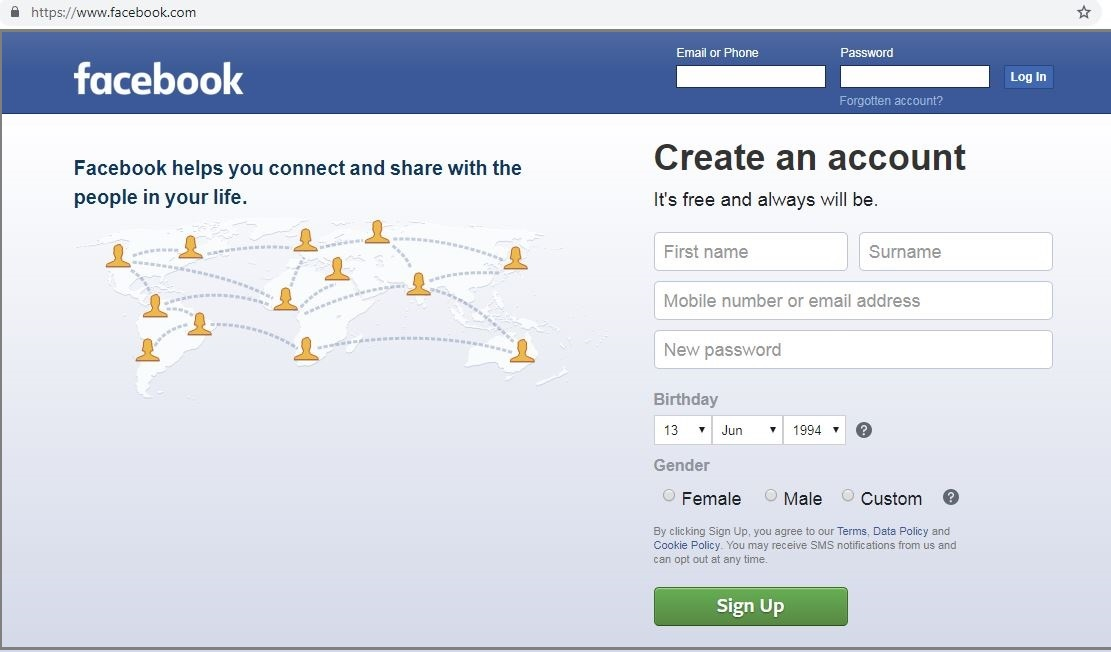
Facebook Login Page
Facebook登录页面
To inspect Email or phone web element, Right-click on Email or phone input box and select Inspect.
要检查电子邮件或电话 Web元素,请右键单击“ 电子邮件或电话”输入框,然后选择“检查”。
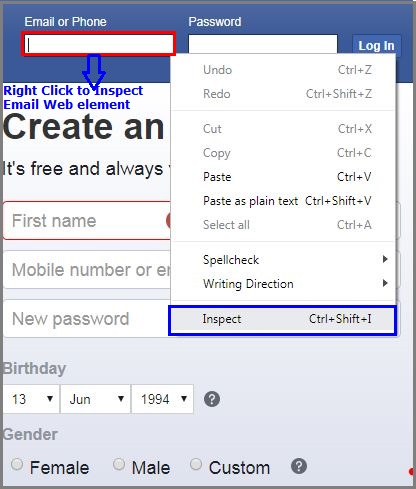
Inspect Email
检查电子邮件
Once inspecting the Email or phone web element, it will open HTML DOM structure like below.
一旦检查了电子邮件或电话网络元素,它将打开如下所示HTML DOM结构。
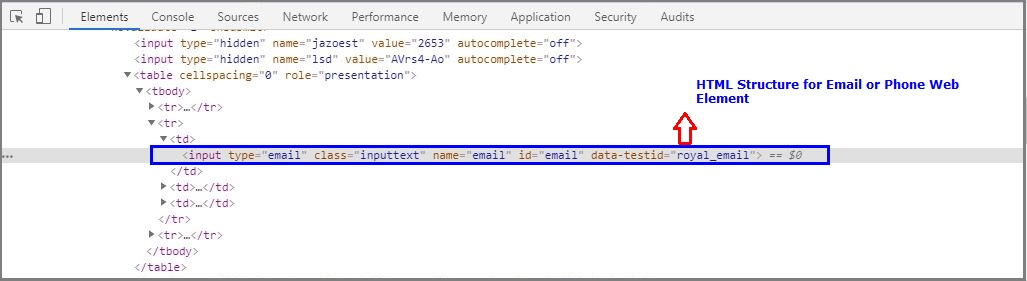
Email HTML Structure
电子邮件HTML结构
To get the Xpath of Email or phone web element, Right-click on HTML Structure, select Copy and Click on Copy XPath.
要获取电子邮件或电话 Web元素的Xpath,请右键单击HTML Structure,选择“复制”,然后单击“复制XPath”。

Email Xpath
电子邮件Xpath
In this case, the XPath is:
在这种情况下,XPath为:
//*[@id="email"]To inspect Password web element, Right-click on Password input box and select Inspect.
要检查“ 密码” Web元素,请右键单击“ 密码”输入框,然后选择“检查”。
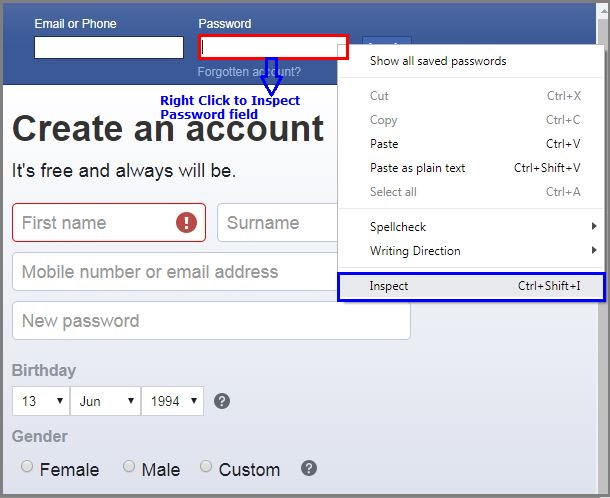
Inspect Password
检查密码
Once inspecting the Password web element, it will open HTML DOM structure like below.
一旦检查了密码 Web元素,它将打开如下HTML DOM结构。
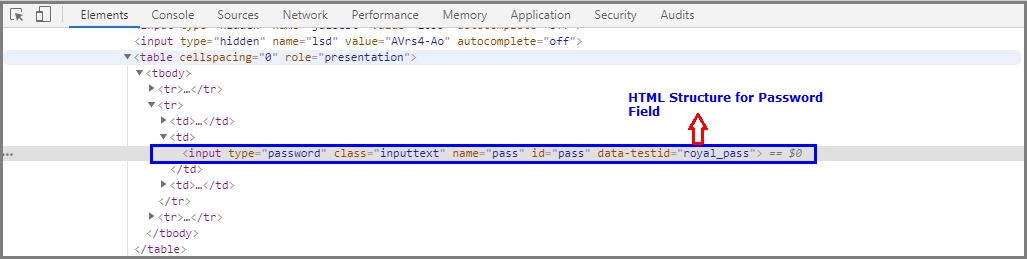
Password HTML Structure
密码HTML结构
To get the Xpath of Password web element, Right-click on HTML Structure, select Copy and Click on Copy XPath.
要获取密码 Xpath Web元素,请右键单击HTML Structure,选择“复制”,然后单击“复制XPath”。

Password XPath
密码XPath
In this case, the XPath is:
在这种情况下,XPath为:
//*[@id="pass"]To inspect Log In button, Right-click on Log In button and select Inspect.
要检查“ 登录”按钮,请右键单击“ 登录”按钮,然后选择“检查”。
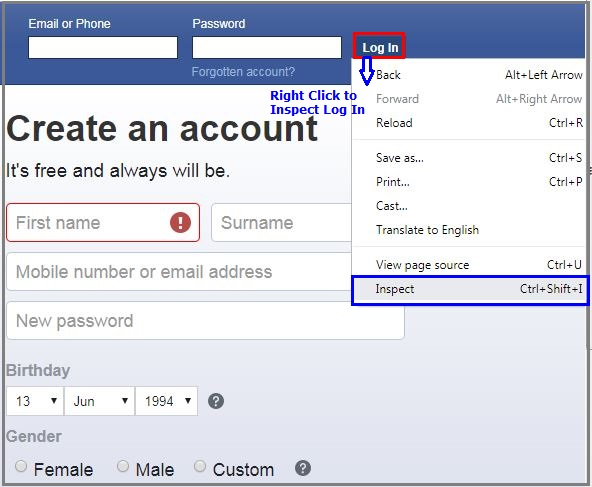
Inspect LogIn
检查登录
Once inspecting the LogIn button, it will open HTML DOM structure like below.
检查“ 登录”按钮后,它将打开如下所示HTML DOM结构。
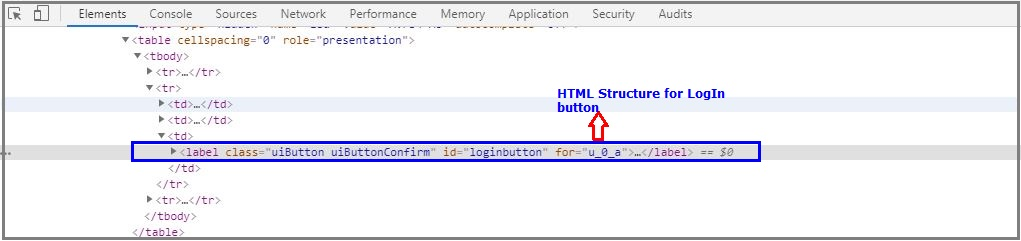
LogIn HTML Structure
登录HTML结构
To get the Xpath of Log In button, Right-click on HTML Structure, select Copy and Click on Copy XPath.
要获得“ 登录 Xpath”按钮,请右键单击“ HTML结构”,选择“复制”,然后单击“复制XPath”。
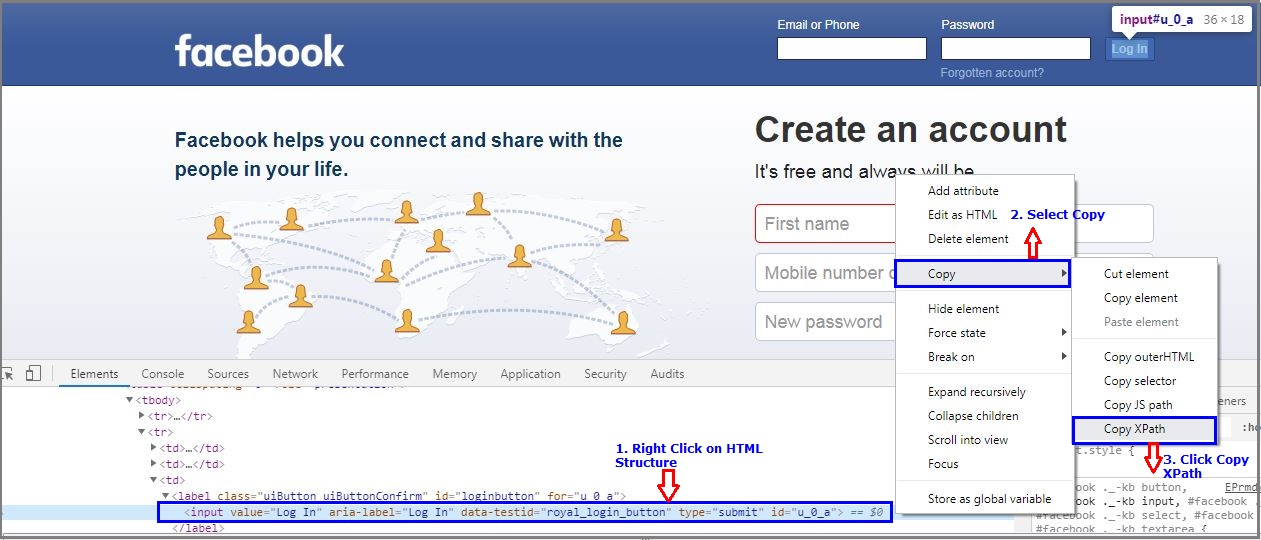
Login XPath
登录XPath
In this case, the XPath is:
在这种情况下,XPath为:
//*[@id="u_0_a"]Java Selenium XPath示例 (Java Selenium XPath Example)
Here is the java class for logging into Facebook using Selenium. We will use the earlier identified XPath expressions to send the values for login.
这是使用Selenium登录Facebook的Java类。 我们将使用较早识别的XPath表达式发送登录值。
package com.journaldev.selenium.xpath;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
public class RelativeXPath {
public static void main(String[] args) {
System.setProperty("webdriver.chrome.driver","D:\\Drivers\\chromedriver.exe");
WebDriver driver= new ChromeDriver();
driver.get("https://www.facebook.com/");
driver.manage().window().maximize();
//XPath for Email Field
driver.findElement(By.xpath("//*[@id='email']")).sendKeys("xxx@gmail.com");
//XPath for Password Field
driver.findElement(By.xpath("//*[@id='pass']")).sendKeys("xxxxxxx");
driver.findElement(By.xpath("//*[@id=\"u_0_a\"]")).click();
}
}XPath函数 (XPath Functions)
Automation using Selenium is a great technology that provides many ways to identify an element on the web page. But sometimes we face problems in identifying the element on a page which have the same attributes.
使用Selenium进行自动化是一项伟大的技术,它提供了多种方法来识别网页上的元素。 但是有时我们在识别页面上具有相同属性的元素时会遇到问题。
Some of the cases can be: elements having the same attributes and names or having more than one button with same ids and name.
某些情况可能是:具有相同属性和名称的元素或具有多个具有相同ID和名称的按钮。
In those cases, it’s challenging for selenium to identify a particular object on a web page and this is where XPath functions come in to picture.
在这些情况下,Selenium很难识别网页上的特定对象,而这正是XPath函数发挥作用的地方。
XPath函数的类型 (Types of XPath Functions)
Selenium is comprised of various XPath functions. Below are the three functions which are widely used.
Selenium由各种XPath函数组成。 以下是广泛使用的三个功能。
- contains() contains()
- text() 文本()
- starts-with() 以。。开始()
1. contains() (1. contains())
contains() is one of the functions used in XPath expression. This method is used when the value of any attribute changes dynamically. For example, login information.
contains()是XPath表达式中使用的功能之一。 当任何属性的值动态更改时,将使用此方法。 例如,登录信息。
This method can locate a web element with the available partial text.
此方法可以使用可用的部分文本来定位Web元素。
Following are the examples of contains() method.
以下是contains()方法的示例。
- Xpath=.//* [contains (@name, ‘button’)] Xpath =。// * [包含(@name,'button')]
- Xpath=//*[contains(@id, ‘login’)] Xpath = // * [包含(@id,'登录')]
- Xpath=//*[contains(text (),’testing’)] Xpath = // * [包含(text(),'testing')]
- Xpath=//*[contains (@href,’https://www.journaldev.com’)] Xpath = // * [包含(@ href,'https://www.journaldev.com')]
- Xpath=//*[contains (@type, ‘sub-type’)] Xpath = // * [包含(@type,'sub-type')]
2. starts-with() (2. starts-with())
starts-with() is the function used to find a web element whose value of an attribute changes on the refresh or on any other dynamic operation on the web page.
starts-with()是用于查找Web元素的函数,该Web元素的属性值在刷新或Web页上的任何其他动态操作时发生变化。
In this function, we match the starting text of the attribute which is used to locate an element whose attribute changes dynamically.
在此函数中,我们匹配属性的起始文本,该文本用于查找其属性动态变化的元素。
For example, if id of a particular element changes dynamically on the web page such as ‘id1’, ‘id2’, ‘id3’ and so on..but the text remains the same.
例如,如果某个特定元素的id在网页上动态更改,例如“ id1”,“ id2”,“ id3”等,但是文本保持不变。
Following are the examples of starts-with() expression.
以下是starts-with()表达式的示例。
- Xpath=//label[starts-with(@id, ‘message’)] Xpath = // label [starts-with(@id,'message')]
3. text() (3. text())
The text() function is used to locate an element with the exact text.
text()函数用于查找具有确切文本的元素。
Below are the examples of text function.
以下是文本功能的示例。
- Xpath=//td Xpath = // td
结论 (Conclusion)
XPath is required to find an element on the web page as to do an operation on a particular element. XPath expression select nodes or list of nodes on the basis of attributes like ID, Classname, Name, etc. from an XML document.
需要XPath才能在网页上查找元素,以便对特定元素进行操作。 XPath表达式根据XML文档中的ID,Classname,Name等属性选择节点或节点列表。
翻译自: https://www.journaldev.com/29661/selenium-xpath-examples















 1499
1499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









