





在当今的技术世界中,无论是移动应用程序,企业应用程序还是云应用程序,XML解析功能都是大量应用程序所必需的。 尽管XML膨胀且非常冗长,但它仍然是数据交换领域的王者(JSON是一种不错的选择,请查看我们的教程以了解如何与GWT进行JSON集成)。
XML解析有两种主要方法:SAX和DOM。 SAX规范定义了一种基于事件的方法,其中,已实现的解析器扫描XML数据,并在到达文档的某些部分时使用回调处理程序。 另一方面, DOM规范定义了一种基于树的方法来导航XML文档。
在上一个教程中,我们了解了如何使用SAX解析XML文档。 DOM对象是相对耗费资源的,并且可能不适合在移动环境中使用。 SAX解析器的功能更轻巧,并且占用的内存更少。 SAX是推式解析API,但从某种意义上说,SAXParser使用了带有“回调”的消息处理程序,而不是由解析应用程序调用,因此它在某种程度上“被破坏了”。
一种替代方法是使用一种相对较新的做法,即“拉解析”方法。 简而言之,这种方法的主要区别在于,用户代码处于控制之中,可以在准备处理数据时提取更多数据。 您可以找到一篇出色的文章,介绍如何使用XML Pull Parser和一些XML Pull解析模式来处理XML 。
Android SDK通过XML Pull包支持XML Pull解析(这在Level 1 API中令人惊讶)。 使用的主要类是带有Javadoc页面的XmlPullParser ,其中包括有关如何使用解析器的简单示例。 在本教程中,我将向您展示如何在Android应用程序中添加提取解析功能,以及如何实现比API文档所提供的解析器更复杂的解析器。
如果您是JavaCodeGeeks的普通读者,那么您可能知道我已经开始了一个教程系列,从零开始构建完整的应用程序。 在其第三部分( “ Android Full App,第3部分:解析XML响应” )中,我使用基于XML的外部API来执行电影搜索。 以下是一个示例XML响应: 电影搜索“变形金刚”和(年份)“ 2007”
在该教程中,我介绍了基于SAX的方法,但知道我们将通过使用Android的XML拉式解析器来增强功能。 首先,让我们在Eclipse中创建一个新的Android项目。 我称之为“ AndroidXmlPullParserProject”。 这是使用的配置的屏幕截图:


使用XML Pull API的第一步是获取XmlPullParserFactory类的新实例。 此类用于创建XMPULL V1 API中定义的XML Pull Parser的实现。 我们将禁用工厂的名称空间意识,因为应用程序不需要它。 请注意,这也会提高解析速度。
接下来,我们通过调用newPullParser工厂方法来创建一个新的XmlPullParser 。 必须将输入提供给解析器,并通过setInput方法来完成,该方法需要InputStream和编码作为参数。 我们提供通过URL连接获得的输入流(因为我们的XML文档是Internet资源),但是我们不提供输入编码(null就可以了)。
XML Pull解析是基于事件的,为了解析整个文档,诀窍是创建一个循环,在该循环中,我们依次获取所有解析事件,直到到达END_DOCUMENT事件。 作为一个展示示例,代码将在遇到以下事件时仅打印日志语句:
- START_TAG :已读取XML开始标签。
- TEXT :已读取文本内容。
- END_TAG :已读取XML结束标签。
- START_DOCUMENT :解析器在文档的开头。
- END_DOCUMENT :xml文档的逻辑末尾。
这是我们第一个简单实现的源代码:
package com.javacodegeeks.android.xml.pull;
import java.io.InputStream;
import java.net.URL;
import java.net.URLConnection;
import org.xmlpull.v1.XmlPullParser;
import org.xmlpull.v1.XmlPullParserFactory;
import android.app.Activity;
import android.os.Bundle;
import android.util.Log;
public class XmlPullParserActivity extends Activity {
private static final String xmlUrl =
"http://dl.dropbox.com/u/7215751/JavaCodeGeeks/AndroidFullAppTutorialPart03/Transformers+2007.xml";
private final String TAG = getClass().getSimpleName();
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
try {
parseFromUrl();
}
catch (Exception e) {
Log.e(TAG, "Error while parsing", e);
}
}
private void parseFromUrl() throws Exception {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
factory.setNamespaceAware(false);
XmlPullParser xpp = factory.newPullParser();
URL url = new URL(xmlUrl);
URLConnection ucon = url.openConnection();
InputStream is = ucon.getInputStream();
xpp.setInput(is, null);
int eventType = xpp.getEventType();
while (eventType != XmlPullParser.END_DOCUMENT) {
if (eventType == XmlPullParser.START_DOCUMENT) {
Log.d(TAG, "Start document");
}
else if (eventType == XmlPullParser.END_DOCUMENT) {
Log.d(TAG, "End document");
}
else if (eventType == XmlPullParser.START_TAG) {
Log.d(TAG, "Start tag " + xpp.getName());
}
else if (eventType == XmlPullParser.END_TAG) {
Log.d(TAG, "End tag " + xpp.getName());
}
else if (eventType == XmlPullParser.TEXT) {
Log.d(TAG, "Text " + xpp.getText());
}
eventType = xpp.next();
}
}在您的Android Manifest文件中包含INTERNET权限,然后启动该项目。 转到Eclipse的DDMS视图,并使用类名称“ XmlPullParserActivity”创建一个新过滤器,如下图所示:

然后,您应该在LogCat视图中找到各种日志消息:
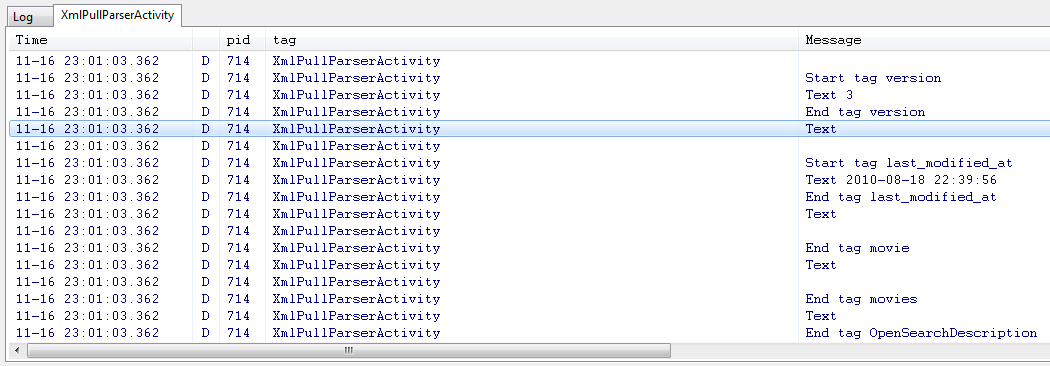

请注意,没有发生任何特殊的解析。 当解析器找到新标签,到达文档末尾等时,我们才得到通知。但是,由于我们确定已经准备好基本的基础架构,因此可以对其进行一些增强。 首先,看一下示例XML (由TMDb API提供):
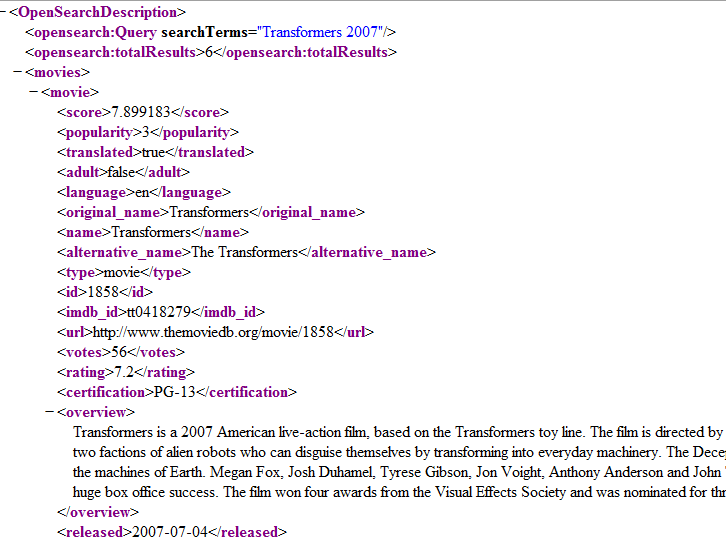

它是带有嵌套元素等的典型XML文档。对我们而言,有趣的数据是“ movies”元素中的数据。 我们将创建一个Movie类,并将每个子元素映射到相应的class字段。 此外,我们还将使用相同的方法创建一个Image类。 请注意,电影可以包含零个或多个图像。 因此,两个域模型类是:
package com.javacodegeeks.android.xml.pull.model;
import java.util.ArrayList;
public class Movie {
public String score;
public String popularity;
public boolean translated;
public boolean adult;
public String language;
public String originalName;
public String name;
public String type;
public String id;
public String imdbId;
public String url;
public String votes;
public String rating;
public String certification;
public String overview;
public String released;
public String version;
public String lastModifiedAt;
public ArrayList<Image> imagesList;
}package com.javacodegeeks.android.xml.pull.model;
public class Image {
public String type;
public String url;
public String size;
public int width;
public int height;
}现在我们准备开始解析。 我们首先以与以前相同的方式创建工厂和提取解析器。 请注意,文档并非直接以“电影”元素开头,但是我们希望跳过一些元素。 这可以通过使用nextTag (用于START_TAG和END_TAG事件)和nextText (用于TEXT事件)方法来实现。
现在我们准备进行有趣的解析。 我们将使用“类似递归”的方法。 “电影”元素包含多个“电影”元素,其中“电影”元素包含多个“图像”元素。 因此,我们使用专用方法解析每个元素,从父元素“钻取”到子元素。 从一种方法到另一种方法,我们将XmlPullParser实例作为参数传递,因为有一个唯一的解析器来实现解析。 每个方法的结果都是模型类的实例,最后是电影列表。 为了检查当前元素的名称,我们使用getName方法,并且为了检索包含的文本,我们使用nextText方法。 对于属性,我们使用getAttributeValue方法,其中第一个参数是名称空间(本例中为null),第二个参数是属性名称。
足够多的讨论,让我们看看所有这些如何转换为代码:
package com.javacodegeeks.android.xml.pull;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import org.xmlpull.v1.XmlPullParser;
import org.xmlpull.v1.XmlPullParserException;
import org.xmlpull.v1.XmlPullParserFactory;
import android.app.Activity;
import android.os.Bundle;
import android.util.Log;
import com.javacodegeeks.android.xml.pull.model.Image;
import com.javacodegeeks.android.xml.pull.model.Movie;
public class XmlPullParserActivity extends Activity {
private static final String xmlUrl =
"http://dl.dropbox.com/u/7215751/JavaCodeGeeks/AndroidFullAppTutorialPart03/Transformers+2007.xml";
private final String TAG = getClass().getSimpleName();
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
try {
List<Movie> movies = parseFromUrl();
for (Movie movie : movies) {
Log.d(TAG, "Movie:"+movie);
}
}
catch (Exception e) {
Log.e(TAG, "Error while parsing", e);
}
}
private List<Movie> parseFromUrl() throws XmlPullParserException, IOException {
List<Movie> moviesList = null;
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
factory.setNamespaceAware(false);
XmlPullParser parser = factory.newPullParser();
URL url = new URL(xmlUrl);
URLConnection ucon = url.openConnection();
InputStream is = ucon.getInputStream();
parser.setInput(is, null);
parser.nextTag();
parser.nextTag();
parser.nextTag();
parser.nextTag();
parser.nextText();
parser.nextTag();
moviesList = parseMovies(parser);
return moviesList;
}
private List<Movie> parseMovies(XmlPullParser parser) throws XmlPullParserException, IOException {
List<Movie> moviesList = new LinkedList<Movie>();
Log.d(TAG, "parseMovies tag " + parser.getName());
while (parser.nextTag() == XmlPullParser.START_TAG) {
Log.d(TAG, "parsing movie");
Movie movie = parseMovie(parser);
moviesList.add(movie);
}
return moviesList;
}
private Movie parseMovie(XmlPullParser parser) throws XmlPullParserException, IOException {
Movie movie = new Movie();
Log.d(TAG, "parseMovie tag " + parser.getName());
while (parser.nextTag() == XmlPullParser.START_TAG) {
if (parser.getName().equals("name")) {
movie.name = parser.nextText();
}
else if (parser.getName().equals("score")) {
movie.score = parser.nextText();
}
else if (parser.getName().equals("images")) {
Image image = parseImage(parser);
movie.imagesList = new ArrayList<Image>();
movie.imagesList.add(image);
}
else if (parser.getName().equals("version")) {
movie.version = parser.nextText();
}
else {
parser.nextText();
}
}
return movie;
}
private Image parseImage(XmlPullParser parser) throws XmlPullParserException, IOException {
Image image = new Image();
Log.d(TAG, "parseImage tag " + parser.getName());
while (parser.nextTag() == XmlPullParser.START_TAG) {
if (parser.getName().equals("image")) {
image.type = parser.getAttributeValue(null, "type");
image.url = parser.getAttributeValue(null, "url");
image.size = parser.getAttributeValue(null, "size");
image.width = Integer.parseInt(parser.getAttributeValue(null, "width"));
image.height = Integer.parseInt(parser.getAttributeValue(null, "height"));
}
parser.next();
}
return image;
}
}该代码非常简单,只需记住我们正在使用“向下钻取”方法来解析更深层的元素(电影,电影,图像)。 请注意,在影片分析方法中,为简洁起见,我们仅包含了一些字段。 另外,不要忘记调用parser.nextText()方法以允许解析器移动并获取下一个标记(否则,您将得到一些讨厌的异常,因为当前事件的类型将不是START_TAG )。
再次运行项目的配置,并检查LogCat是否包含正确的调试语句:
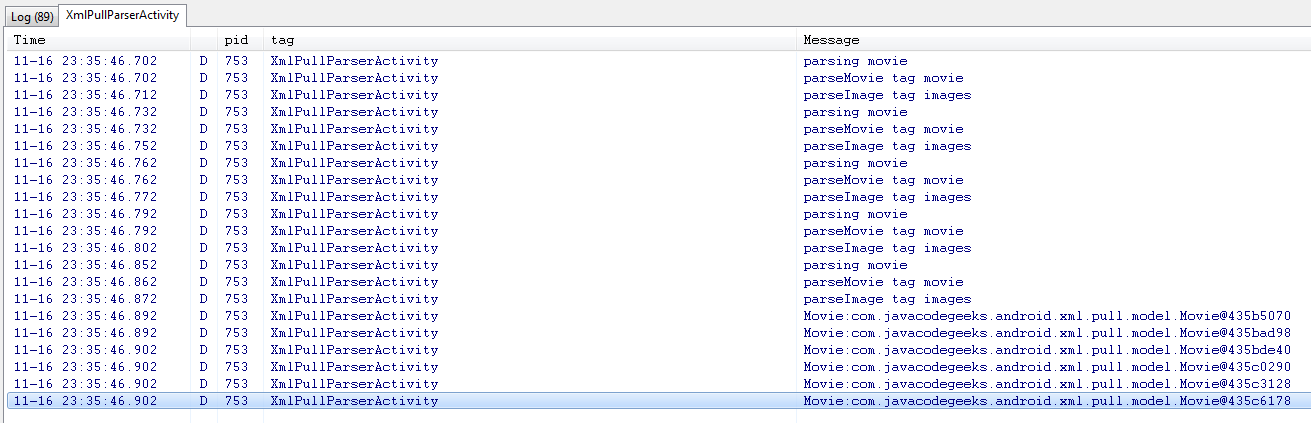

而已! XML Pull解析功能直接应用于您的Android应用程序。 您可以在此处下载为此文章创建的Eclipse项目。
- “ Android完整应用程序教程”系列
- Android文字转语音应用
- 带有Yahoo API的Android反向地理编码– PlaceFinder
- Android基于位置的服务应用程序– GPS位置
- 使用VirtualBox在PC上安装Android OS
- 拥抱Android的强大功能:快速概览
翻译自: https://www.javacodegeeks.com/2010/11/boost-android-xml-parsing-xml-pull.html















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









