






并行计算
并行数据库流
在上一篇文章中,我写了关于使用并行流和Speedment并行处理数据库内容的信息。 在许多情况下,并行流可能比通常的顺序数据库流快得多。


线程池
Speedment是一个开源的Stream ORM Java工具包和Runtime Java工具,它将现有数据库及其表包装到Java 8流中。 我们可以使用现有的数据库并运行Speedment工具,它将生成与我们使用该工具选择的表相对应的POJO类。 Speedment的一个独特功能是它支持并行数据库流,并且可以使用不同的并行策略来进一步优化性能。默认情况下,并行流是在公共ForkJoinPool上执行的,它们可能会与其他任务竞争。 在本文中,我们将学习如何根据自己的习惯执行并行数据库流。ForkJoinPool,可以更好地控制我们的执行环境。
加速入门
前往GitHub上的开放源Speedment ,学习如何开始Speedment项目。 将工具连接到现有数据库确实非常容易。 阅读我的上一篇文章提供了有关数据库表和PrimeUtil类的外观的更多信息,如以下示例所示。
在默认的ForkJoinPool上执行
这是我在上一篇文章中讨论的应用程序,它将并行扫描数据库表以查找未确定的质数候选者,然后将确定它们是否为质数并相应地更新表。 它是这样的:
Manager<PrimeCandidate> candidatesHigh = app.configure(PrimeCandidateManager.class)
.withParallelStrategy(ParallelStrategy.computeIntensityHigh())
.build();
candidatesHigh.stream()
.parallel() // Use a parallel stream
.filter(PrimeCandidate.PRIME.isNull()) // Only consider nondetermined prime candidates
.map(pc -> pc.setPrime(PrimeUtil.isPrime(pc.getValue()))) // Sets if it is a prime or not
.forEach(candidatesHigh.updater()); // Apply the Manager's updater 首先,我们使用stream().filter(PrimeCandidate.PRIME.isNull())方法在所有候选对象上创建流(使用名为ParallelStrategy.computeIntensityHigh()的并行策略),其中“ prime” stream().filter(PrimeCandidate.PRIME.isNull()) null 。 然后,对每个这样的总理候选人PC,我们无论是“黄金”列设置为true ,如果pc.getValue()是一个主要的或false ,如果pc.getValue()是不是一个素数。 有趣的是, pc.setPrime()方法返回实体pc本身,使我们可以轻松地在多个流操作上进行标记。 在最后一行,我们通过应用candidatesHigh.updater()函数以检查结果更新数据库。
同样,请确保查看我以前的文章,了解并行策略的详细信息和好处。 简而言之,Java的默认并行策略可以很好地满足较低的计算需求,因为它在每个线程上放置了大量初始工作项。 Speedment的并行策略对于中等到较高的计算需求效果更好,因为少量的工作项放在参与的线程上。
该流将确定完全并行的质数,执行线程将使用公用的ForkJoinPool如该图所示(我的笔记本电脑有4个CPU核心和8个CPU线程):
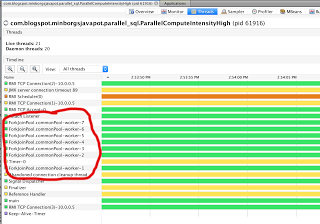
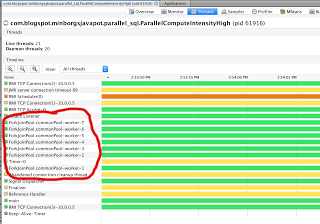
使用自定义执行器服务
正如我们在本文开头所了解的那样,并行流是由Common执行的。默认情况下为ForkJoinPool 。 但是,有时我们想使用我们自己的执行器,也许是因为我们害怕泛滥成灾ForkJoinPool ,以便其他任务无法正常运行。 可以为Speedment(和其他流库)轻松地定义我们自己的执行程序,如下所示:
final ForkJoinPool forkJoinPool = new ForkJoinPool(3);
forkJoinPool.submit(() ->
candidatesHigh.stream()
.parallel()
.filter(PrimeCandidate.PRIME.isNull())
.map(pc -> pc.setPrime(PrimeUtil.isPrime(pc.getValue())))
.forEach(candidatesHigh.updater());
);
try {
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
} catch (InterruptedException ie) {
ie.printStackTrace();
} 该应用程序代码未经修改,但包装到一个我们可以控制自己的自定义ForkJoinPool中。 在上面的示例中,我们设置了一个只有三个工作线程的线程池。 工作线程不与公共ForkJoinPool的线程共享。
使用自定义执行程序服务的线程如下所示:
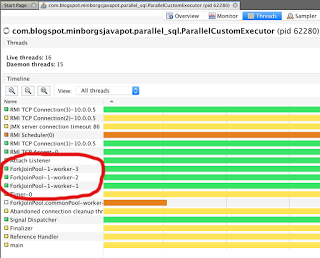
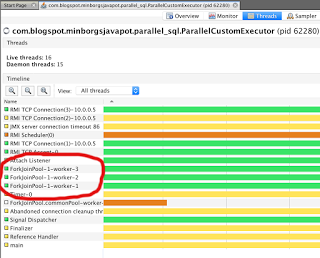
这样,我们既可以控制实际的ThreadPool本身,又可以使用并行策略来精确控制工作项在该池中的布局方式!
保持游泳池中的热量!
翻译自: https://www.javacodegeeks.com/2016/11/work-parallel-database-streams-using-custom-thread-pools.html
并行计算















 5639
5639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









