






kafka教程
让我们玩得开心。
这是新的一年的开始-我们正处于新事物的门槛上-因此让我们期待您在2016年可能会做的事情。现在我知道做出预测的风险,尤其是有记录的预测,但是我很高兴您能在一年后回访,看看我对2016年的预测是如何完成的。
您在2016年会做什么?
在我做出2016年预测之前,首先要更普遍(有趣地)思考推测未来的挑战。 我们是否根据数据和模型进行工作? 从观察和预感? 请记住,描述未来的准确性部分取决于目标的未来时间。
传统上会遥远地预测人们的生活前景。 有时它们是准确的,更经常是滑稽的错误。 回顾未来应该是一种娱乐,我称之为“记住未来”。
例如,2000年引起了人们多年的想像力。 我遇到了一篇发表于1900年的女士家庭杂志上的文章,其中对我们2000年的生活做出了预测。在大致正确的预测中,有汽车将大量涌现的情况,照片可以从遥远的国家电报,这样,它们可以在一小时内在报纸上印制出来,包括领土在内的美国人口将超过3.5亿(2000年人口普查使美国人口为2.82亿,有点短)。 预测不会有更多的苍蝇或蚊子,城市中的交通将在地下或高架上发生,因此城市将“没有噪音”,而我们将不再使用字母C,X或Q 。
未来并没有如前所述,部分原因是我们经常以与预期不同的方式解决相同的问题:今天,高速公路上的城市交通被分流了,但是-不能消除噪音。 而且,我们不是通过“发射”某些辅音来规范拼写,而是依靠自动拼写纠正系统(有时会产生可笑的结果)。
返回大数据
Ted Dunning在那个城市的Strata Hadoop World会议的一周期间,在新加坡大数据聚会上对当前和未来的大数据趋势进行了生动的演讲,提出了“记住未来”的主题。 另一位演讲者,Hadoop创始人道格·切特(Doug Cutting)也提出了关于大数据系统在不久的将来走向何处的想法。


Doug谈到了Hadoop生态系统的发展,特别是在分析方面。 在许多情况下,基于批处理的计算已被内存中的微批处理计算能力所取代,因此,人们对Apache Spark的兴趣日益浓厚。
泰德(Ted)首先以一种文化趋势来招待人们,但这种文化趋势并没有像他预料的那样,然后他描述了一个成功的,具有前瞻性的大数据项目-这是一个19世纪的开源项目,该项目很好地利用了海洋和风能数据来绘制航行航海图。 跳到了今天,Ted解释了当前大数据趋向于简化机器学习项目,以使其具有实用价值的趋势。 Ted还谈到了需要更简化的方式来处理复杂数据以避免必须建立数百个表的情况(传统关系系统就是如此),他展示了在这种情况下利用SQL引擎Apache Drill的灵活性的优势。
2016年的六大预测
受描述大数据趋势的其他人的启发,现在我伸出我的脖子,对自己在2016年的工作做出自己的预测(纯观点)。毕竟,这只是未来的一年……
流数据
我有信心在整个2016年对流数据和流分析产生爆炸性的兴趣。 流数据将以比以前更多的方式和新的方式被更多的组织使用。 物联网传感器数据量的增加只是流数据的来源之一。 一系列事件(例如来自网络流量的点击流数据或机器日志文件)将越来越多地通过使用Apache Spark进行近实时处理或使用更新的工具Apache Flink进行实时分析来作为流进行分析。
重大变化之一将是以不同的方式来考虑最能支持这些应用程序的体系结构:消息队列将成为设计这些系统的中心焦点。 在流分析程序的工作流中,消息传递层将不仅仅是一个安全缓冲区。 正确完成后,消息队列将成为可重播,不变的持久日志,为多个主服务器(例如实时分析应用程序,数据库或搜索文档)提供服务。 由于这些原因,我预计将大大增加使用已经流行的消息传递工具Apache Kafka,并对新的MapR Streams (支持Kafka API的集成消息传递技术)产生浓厚的兴趣。
缩短实现价值的时间
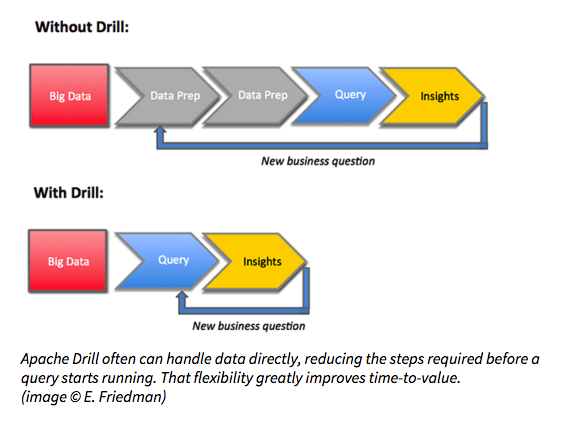
企业需要实用的方法来更快地实现价值,因此,如果您的企业需要使用SQL ,我相信您可能会在2016年尝试Apache Drill 。 随着发布次数的增加,Drill的功能不断扩展,但它已经是使用标准SQL的高性能,高可伸缩性和极其灵活的查询引擎。 这对于来自传统背景的大数据用户以及Hadoop和NoSQL世界的资深人士来说同样具有吸引力,他们希望查询引擎能够轻松处理各种非结构化和嵌套的数据类型,例如JSON和Parquet。
Drill的特性也许最有可能让您尝试使用它,而它几乎不需要准备就可以查询数据,这可以减少从数据获取见解所需的时间或数天。 在开始查询之前,只需花费较少的时间,借助Drill,您就可以根据从第一个查询中学到的知识快速构建第二个查询。 更快的开发,更快的见解,更短的价值实现时间。

集权
人们越来越多地将大数据平台视为其整个组织的中心部分,而不是一个特殊目的的项目。 大数据平台(例如基于Hadoop和NoSQL的系统)将需要轻松地连接到传统技术,例如企业数据仓库,关系数据库或BI工具。
对于全球组织而言,集中化的一个自相矛盾的方面是需要在全球范围内分发数据。 您组织的不同部门需要访问统一的数据集。 在分解地理位置不同的中心内或中心之间不必要的孤岛时,您将要避免传播延迟。 可能存在法律问题,需要对数据进行本地化。 由于这些原因,我预测许多组织将希望使用一种具有安全可靠方法的系统来维护可以快速同步的多个数据中心。
专题:医疗保健
我认为医疗保健行业中的大数据使用有望在2016年Swift扩展。人们已经意识到使用数据来减少欺诈并通过使用电子病历,机器的长期维护记录来改善医疗保健的力量,以及传感器信息流。 对于这些用例而言,出色的数据安全性和治理当然很重要。
专题:电信
电信将在2016年在大数据领域中脱颖而出的另一个领域。 电信公司已经有很好的大数据用例:将ETL的压力转移到Hadoop,同时维持企业仓库的复杂账单; 对进出蜂窝塔的数据进行异常检测以发现并快速响应突然的使用变化,并在通话中断后采用实时分析快速响应用户,以改善体验并减少用户流失。
流数据架构和技术(如上所述)的扩展将使电信受益。 但是,即使您自己不使用电信,这种特殊情况也可能会影响您。 越来越多的非电话应用正在利用电信网络。 例如,汽车中的传感器经常通过电信网络发送数据。 综上所述,我预计您可能会在2016年将高级电信与大数据相结合。
最好的预测:你会让我惊讶
我对2016年的最佳预测是,您将想出一些创新的方法来使用尚未出现的大数据。 也许它将以新颖的方式解决我已经知道的问题。 也许这将是全新的东西。 无论哪种方式,到2017年1月,我都会“记住未来”,即使我的其他五个预测都是准确的,我也会为新事物感到惊讶。
其他资源
对于作者的相关内容,请参见以下免费资源:
翻译自: https://www.javacodegeeks.com/2016/01/will-2016-apache-spark-kafka-drill.html
kafka教程















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









