






c# 建立一个项目
建立一个项目 (Setting Up a Project)
In this chapter, we will understand the process involved in setting up a project to perform logistic regression in Python, in detail.
在本章中,我们将详细了解设置项目以在Python中执行逻辑回归的过程。
安装Jupyter (Installing Jupyter)
We will be using Jupyter - one of the most widely used platforms for machine learning. If you do not have Jupyter installed on your machine, download it from here. For installation, you can follow the instructions on their site to install the platform. As the site suggests, you may prefer to use Anaconda Distribution which comes along with Python and many commonly used Python packages for scientific computing and data science. This will alleviate the need for installing these packages individually.
我们将使用Jupyter-机器学习最广泛使用的平台之一。 如果您的计算机上未安装Jupyter,请从此处下载。 对于安装,您可以按照其网站上的说明安装平台。 正如该站点所建议的那样,您可能更喜欢使用Python附带的Anaconda Distribution和用于科学计算和数据科学的许多常用Python软件包。 这将减少单独安装这些软件包的需要。
After the successful installation of Jupyter, start a new project, your screen at this stage would look like the following ready to accept your code.
成功安装Jupyter后,开始一个新项目,此阶段的屏幕如下所示,可以接受您的代码。
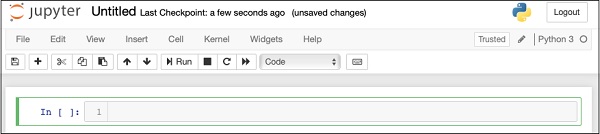
Now, change the name of the project from Untitled1 to “Logistic Regression” by clicking the title name and editing it.
现在,通过单击标题名称并对其进行编辑,将项目名称从Untitled1更改为“ Logistic Regression” 。
First, we will be importing several Python packages that we will need in our code.
首先,我们将导入代码中需要的几个Python软件包。
导入Python包 (Importing Python Packages)
For this purpose, type or cut-and-paste the following code in the code editor −
为此,请在代码编辑器中键入或剪切以下代码-
In [1]: # import statements
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
Your Notebook should look like the following at this stage −
您的笔记本在此阶段应如下所示:

Run the code by clicking on the Run button. If no errors are generated, you have successfully installed Jupyter and are now ready for the rest of the development.
通过单击“ 运行”按钮运行代码。 如果未生成任何错误,则说明您已经成功安装了Jupyter,现在可以进行其余的开发了。
The first three import statements import pandas, numpy and matplotlib.pyplot packages in our project. The next three statements import the specified modules from sklearn.
前三个import语句在我们的项目中导入pandas,numpy和matplotlib.pyplot程序包。 接下来的三个语句从sklearn导入指定的模块。
Our next task is to download the data required for our project. We will learn this in the next chapter.
我们的下一个任务是下载项目所需的数据。 我们将在下一章中学习。
c# 建立一个项目















 6259
6259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









