






Python深度学习-快速指南 (Python Deep Learning - Quick Guide)
Python深度学习-简介 (Python Deep Learning - Introduction)
Deep structured learning or hierarchical learning or deep learning in short is part of the family of machine learning methods which are themselves a subset of the broader field of Artificial Intelligence.
深度结构化学习或分层学习或简称为深度学习是机器学习方法家族的一部分,而机器学习方法本身就是更广泛的人工智能领域的子集。
Deep learning is a class of machine learning algorithms that use several layers of nonlinear processing units for feature extraction and transformation. Each successive layer uses the output from the previous layer as input.
深度学习是一类机器学习算法,它使用几层非线性处理单元进行特征提取和转换。 每个后续层都使用前一层的输出作为输入。
Deep neural networks, deep belief networks and recurrent neural networks have been applied to fields such as computer vision, speech recognition, natural language processing, audio recognition, social network filtering, machine translation, and bioinformatics where they produced results comparable to and in some cases better than human experts have.
深度神经网络,深度信念网络和递归神经网络已应用于计算机视觉,语音识别,自然语言处理,音频识别,社交网络过滤,机器翻译和生物信息学等领域,在这些领域所产生的结果可与之媲美,在某些情况下比人类专家要好。
Deep Learning Algorithms and Networks −
深度学习算法和网络-
are based on the unsupervised learning of multiple levels of features or representations of the data. Higher-level features are derived from lower level features to form a hierarchical representation.
基于无监督学习数据的多个级别的特征或表示形式。 较高级别的功能从较低级别的功能派生而来,形成了层次表示。
use some form of gradient descent for training.
使用某种形式的梯度下降进行训练。
Python深度学习-环境 (Python Deep Learning - Environment)
In this chapter, we will learn about the environment set up for Python Deep Learning. We have to install the following software for making deep learning algorithms.
在本章中,我们将学习为Python深度学习设置的环境。 我们必须安装以下软件来进行深度学习算法。
- Python 2.7+ Python 2.7以上
- Scipy with Numpy 脾气暴躁的西皮
- Matplotlib Matplotlib
- Theano 茶野
- Keras 凯拉斯
- TensorFlow TensorFlow
It is strongly recommend that Python, NumPy, SciPy, and Matplotlib are installed through the Anaconda distribution. It comes with all of those packages.
强烈建议通过Anaconda发行版安装Python,NumPy,SciPy和Matplotlib。 它包含所有这些软件包。
We need to ensure that the different types of software are installed properly.
我们需要确保正确安装了不同类型的软件。
Let us go to our command line program and type in the following command −
让我们进入命令行程序并输入以下命令-
$ python
Python 3.6.3 |Anaconda custom (32-bit)| (default, Oct 13 2017, 14:21:34)
[GCC 7.2.0] on linux
Next, we can import the required libraries and print their versions −
接下来,我们可以导入所需的库并打印其版本-
import numpy
print numpy.__version__
输出量 (Output)
1.14.2
安装Theano,TensorFlow和Keras (Installation of Theano, TensorFlow and Keras)
Before we begin with the installation of the packages − Theano, TensorFlow and Keras, we need to confirm if the pip is installed. The package management system in Anaconda is called the pip.
在开始安装软件包-Theano,TensorFlow和Keras之前,我们需要确认是否已安装pip 。 Anaconda中的包裹管理系统称为pip。
To confirm the installation of pip, type the following in the command line −
要确认pip的安装,请在命令行中键入以下内容-
$ pip
Once the installation of pip is confirmed, we can install TensorFlow and Keras by executing the following command −
确认安装了pip后,我们可以通过执行以下命令来安装TensorFlow和Keras-
$pip install theano
$pip install tensorflow
$pip install keras
Confirm the installation of Theano by executing the following line of code −
通过执行以下代码行来确认Theano的安装-
$python –c “import theano: print (theano.__version__)”
输出量 (Output)
1.0.1
Confirm the installation of Tensorflow by executing the following line of code −
通过执行以下代码行来确认Tensorflow的安装-
$python –c “import tensorflow: print tensorflow.__version__”
输出量 (Output)
1.7.0
Confirm the installation of Keras by executing the following line of code −
通过执行以下代码行来确认Keras的安装-
$python –c “import keras: print keras.__version__”
Using TensorFlow backend
输出量 (Output)
2.1.5
Python深度基础机器学习 (Python Deep Basic Machine Learning)
Artificial Intelligence (AI) is any code, algorithm or technique that enables a computer to mimic human cognitive behaviour or intelligence. Machine Learning (ML) is a subset of AI that uses statistical methods to enable machines to learn and improve with experience. Deep Learning is a subset of Machine Learning, which makes the computation of multi-layer neural networks feasible. Machine Learning is seen as shallow learning while Deep Learning is seen as hierarchical learning with abstraction.
人工智能(AI)是使计算机能够模仿人类认知行为或智力的任何代码,算法或技术。 机器学习(ML)是AI的子集,它使用统计方法来使机器学习并根据经验进行改进。 深度学习是机器学习的一个子集,它使多层神经网络的计算变得可行。 机器学习被视为浅层学习,而深度学习被视为具有抽象的分层学习。
Machine learning deals with a wide range of concepts. The concepts are listed below −
机器学习涉及各种各样的概念。 概念在下面列出-
- supervised 监督的
- unsupervised 无监督
- reinforcement learning 强化学习
- linear regression 线性回归
- cost functions 成本函数
- overfitting 过度拟合
- under-fitting 不合身
- hyper-parameter, etc. 超参数等
In supervised learning, we learn to predict values from labelled data. One ML technique that helps here is classification, where target values are discrete values; for example,cats and dogs. Another technique in machine learning that could come of help is regression. Regression works onthe target values. The target values are continuous values; for example, the stock market data can be analysed using Regression.
在监督学习中,我们学习根据标记数据预测值。 分类法,其中目标值是离散值,这是帮助ML的一种技术。 例如猫和狗。 机器学习中的另一种可能会带来帮助的技术是回归。 回归适用于目标值。 目标值是连续值。 例如,可以使用回归分析股市数据。
In unsupervised learning, we make inferences from the input data that is not labelled or structured. If we have a million medical records and we have to make sense of it, find the underlying structure, outliers or detect anomalies, we use clustering technique to divide data into broad clusters.
在无监督学习中,我们从未标记或未结构化的输入数据中进行推断。 如果我们有一百万条医疗记录,并且我们必须弄清楚它,发现底层结构,离群值或检测异常,则可以使用聚类技术将数据划分为广泛的聚类。
Data sets are divided into training sets, testing sets, validation sets and so on.
数据集分为训练集,测试集,验证集等。
A breakthrough in 2012 brought the concept of Deep Learning into prominence. An algorithm classified 1 million images into 1000 categories successfully using 2 GPUs and latest technologies like Big Data.
2012年的一项突破使深度学习的概念倍受关注。 该算法使用2个GPU和最新技术(例如大数据)成功地将100万张图像分类为1000个类别。
深度学习与传统机器学习的关系 (Relating Deep Learning and Traditional Machine Learning)
One of the major challenges encountered in traditional machine learning models is a process called feature extraction. The programmer needs to be specific and tell the computer the features to be looked out for. These features will help in making decisions.
传统机器学习模型中遇到的主要挑战之一是称为特征提取的过程。 程序员需要具体说明并告诉计算机要注意的功能。 这些功能将有助于做出决策。
Entering raw data into the algorithm rarely works, so feature extraction is a critical part of the traditional machine learning workflow.
将原始数据输入算法很少,因此特征提取是传统机器学习工作流程的关键部分。
This places a huge responsibility on the programmer, and the algorithm's efficiency relies heavily on how inventive the programmer is. For complex problems such as object recognition or handwriting recognition, this is a huge issue.
这给程序员带来了巨大的责任,算法的效率在很大程度上取决于程序员的创造力。 对于诸如对象识别或手写识别之类的复杂问题,这是一个巨大的问题。
Deep learning, with the ability to learn multiple layers of representation, is one of the few methods that has help us with automatic feature extraction. The lower layers can be assumed to be performing automatic feature extraction, requiring little or no guidance from the programmer.
能够学习多层表示的深度学习是帮助我们进行自动特征提取的少数几种方法之一。 可以假设较低的层正在执行自动特征提取,几乎不需要程序员的指导。
人工神经网络 (Artificial Neural Networks)
The Artificial Neural Network, or just neural network for short, is not a new idea. It has been around for about 80 years.
人工神经网络,或者简称为神经网络,并不是一个新想法。 它已经存在了大约80年。
It was not until 2011, when Deep Neural Networks became popular with the use of new techniques, huge dataset availability, and powerful computers.
直到2011年,深度神经网络因使用新技术,巨大的数据集可用性和强大的计算机而变得流行。
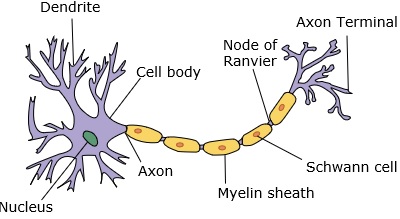
A neural network mimics a neuron, which has dendrites, a nucleus, axon, and terminal axon.
神经网络模仿具有树突,核,轴突和末端轴突的神经元。
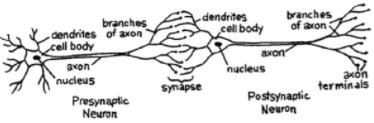
For a network, we need two neurons. These neurons transfer information via synapse between the dendrites of one and the terminal axon of another.
对于一个网络,我们需要两个神经元。 这些神经元通过突触在一个的树突和另一个的终轴突之间传递信息。
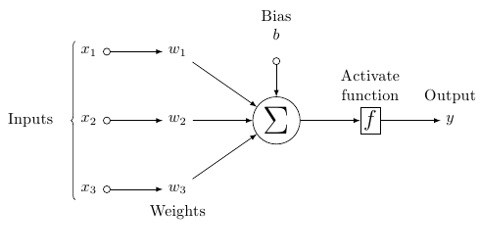
A probable model of an artificial neuron looks like this −
人工神经元的可能模型看起来像这样-
A neural network will look like as shown below −
神经网络如下图所示-
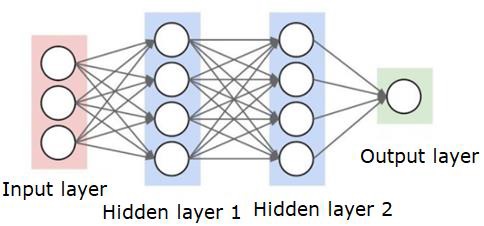
The circles are neurons or nodes, with their functions on the data and the lines/edges connecting them are the weights/information being passed along.
圆圈是神经元或节点,它们在数据上具有功能,连接它们的线/边是传递的权重/信息。
Each column is a layer. The first layer of your data is the input layer. Then, all the layers between the input layer and the output layer are the hidden layers.
每列是一个层。 数据的第一层是输入层。 然后,输入层和输出层之间的所有层都是隐藏层。
If you have one or a few hidden layers, then you have a shallow neural network. If you have many hidden layers, then you have a deep neural network.
如果您有一个或几个隐藏层,那么您就拥有一个浅层的神经网络。 如果您有许多隐藏层,那么您将拥有一个深层的神经网络。
In this model, you have input data, you weight it, and pass it through the function in the neuron that is called threshold function or activation function.
在此模型中,您具有输入数据,对其进行加权,然后将其通过神经元中的函数(称为阈值函数或激活函数)传递。
Basically, it is the sum of all of the values after comparing it with a certain value. If you fire a signal, then the result is (1) out, or nothing is fired out, then (0). That is then weighted and passed along to the next neuron, and the same sort of function is run.
基本上,它是将它与某个特定值进行比较之后所有值的总和。 如果您发射信号,则结果为(1),否则没有结果,则为(0)。 然后将其加权并传递到下一个神经元,并运行相同类型的功能。
We can have a sigmoid (s-shape) function as the activation function.
我们可以将S型(s形)函数作为激活函数。
As for the weights, they are just random to start, and they are unique per input into the node/neuron.
至于权重,它们只是随机开始的,并且对于节点/神经元的每个输入都是唯一的。
In a typical "feed forward", the most basic type of neural network, you have your information pass straight through the network you created, and you compare the output to what you hoped the output would have been using your sample data.
在典型的“前馈”(神经网络的最基本类型)中,您的信息将直接通过创建的网络传递,然后将输出与希望使用示例数据获得的输出进行比较。
From here, you need to adjust the weights to help you get your output to match your desired output.
在这里,您需要调整权重以帮助您获得与所需输出匹配的输出。
The act of sending data straight through a neural network is called a feed forward neural network.
直接通过神经网络发送数据的行为称为前馈神经网络。
Our data goes from input, to the layers, in order, then to the output.
我们的数据从输入开始依次到各层,再到输出。
When we go backwards and begin adjusting weights to minimize loss/cost, this is called back propagation.
当我们倒退并开始调整权重以最小化损失/成本时,这称为反向传播。
This is an optimization problem. With the neural network, in real practice, we have to deal with hundreds of thousands of variables, or millions, or more.
这是一个优化问题。 使用神经网络,在实际中,我们必须处理成千上万个变量,甚至数百万个甚至更多。
The first solution was to use stochastic gradient descent as optimization method. Now, there are options like AdaGrad, Adam Optimizer and so on. Either way, this is a massive computational operation. That is why Neural Networks were mostly left on the shelf for over half a century. It was only very recently that we even had the power and architecture in our machines to even consider doing these operations, and the properly sized datasets to match.
第一个解决方案是使用随机梯度下降作为优化方法。 现在,有一些选项,例如AdaGrad,Adam Optimizer等。 无论哪种方式,这都是一个庞大的计算操作。 这就是为什么神经网络大部分被搁置了半个多世纪。 直到最近,我们甚至在机器中都拥有强大的功能和体系结构,甚至可以考虑执行这些操作,并选择合适大小的数据集进行匹配。
For simple classification tasks, the neural network is relatively close in performance to other simple algorithms like K Nearest Neighbors. The real utility of neural networks is realized when we have much larger data, and much more complex questions, both of which outperform other machine learning models.
对于简单的分类任务,神经网络在性能上与其他简单算法(例如K最近邻居)相对接近。 当我们拥有更大的数据和更复杂的问题时,神经网络才真正发挥作用,这两者都胜过其他机器学习模型。
深度神经网络 (Deep Neural Networks)
A deep neural network (DNN) is an ANN with multiple hidden layers between the input and output layers. Similar to shallow ANNs, DNNs can model complex non-linear relationships.
深度神经网络(DNN)是在输入和输出层之间具有多个隐藏层的ANN。 与浅层ANN相似,DNN可以对复杂的非线性关系建模。
The main purpose of a neural network is to receive a set of inputs, perform progressively complex calculations on them, and give output to solve real world problems like classification. We restrict ourselves to feed forward neural networks.
神经网络的主要目的是接收一组输入,对其进行渐进的复杂计算,并提供输出以解决诸如分类之类的现实问题。 我们限制自己前馈神经网络。
We have an input, an output, and a flow of sequential data in a deep network.
在深度网络中,我们具有输入,输出和顺序数据流。
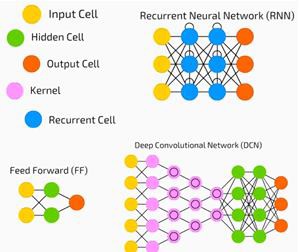
Neural networks are widely used in supervised learning and reinforcement learning problems. These networks are based on a set of layers connected to each other.
神经网络广泛用于监督学习和强化学习问题。 这些网络基于彼此连接的一组层。
In deep learning, the number of hidden layers, mostly non-linear, can be large; say about 1000 layers.
在深度学习中,隐藏层的数量(大多数是非线性的)可能很大; 说大约1000层。
DL models produce much better results than normal ML networks.
DL模型比普通的ML网络产生更好的结果。
We mostly use the gradient descent method for optimizing the network and minimising the loss function.
我们主要使用梯度下降法来优化网络并最小化损失函数。
We can use the Imagenet, a repository of millions of digital images to classify a dataset into categories like cats and dogs. DL nets are increasingly used for dynamic images apart from static ones and for time series and text analysis.
我们可以使用Imagenet (数百万个数字图像的存储库)将数据集分类为猫和狗等类别。 DL网络越来越多地用于除静态图像之外的动态图像以及时间序列和文本分析。
Training the data sets forms an important part of Deep Learning models. In addition, Backpropagation is the main algorithm in training DL models.
训练数据集是深度学习模型的重要组成部分。 另外,反向传播是训练DL模型的主要算法。
DL deals with training large neural networks with complex input output transformations.
DL处理具有复杂输入输出转换的大型神经网络的训练。
One example of DL is the mapping of a photo to the name of the person(s) in photo as they do on social networks and describing a picture with a phrase is another recent application of DL.
DL的一个示例是将照片映射到照片中的人的名字,就像他们在社交网络上所做的那样,并用短语描述图片是DL的另一项最新应用。
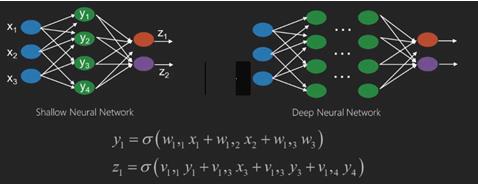
Neural networks are functions that have inputs like x1,x2,x3…that are transformed to outputs like z1,z2,z3 and so on in two (shallow networks) or several intermediate operations also called layers (deep networks).
神经网络是具有x1,x2,x3等输入的函数,这些函数在两个(浅网络)或几个中间操作(也称为层)(深层网络)中转换为z1,z2,z3等输出。
The weights and biases change from layer to layer. ‘w’ and ‘v’ are the weights or synapses of layers of the neural networks.
权重和偏差会随层的不同而变化。 “ w”和“ v”是神经网络各层的权重或突触。
The best use case of deep learning is the supervised learning problem.Here,we have large set of data inputs with a desired set of outputs.
深度学习的最佳用例是有监督的学习问题。在这里,我们有大量的数据输入和所需的一组输出。
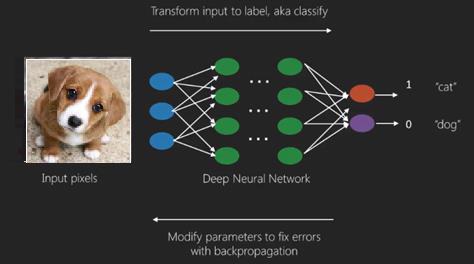
Here we apply back propagation algorithm to get correct output prediction.
在这里,我们应用反向传播算法来获得正确的输出预测。
The most basic data set of deep learning is the MNIST, a dataset of handwritten digits.
深度学习的最基本数据集是MNIST,这是手写数字的数据集。
We can train deep a Convolutional Neural Network with Keras to classify images of handwritten digits from this dataset.
我们可以使用Keras深度训练卷积神经网络,以对该数据集中的手写数字图像进行分类。
The firing or activation of a neural net classifier produces a score. For example,to classify patients as sick and healthy,we consider parameters such as height, weight and body temperature, blood pressure etc.
触发或激活神经网络分类器会产生一个分数。 例如,为了将患者分类为健康患者,我们考虑身高,体重和体温,血压等参数。
A high score means patient is sick and a low score means he is healthy.
高分表示患者生病,低分表示患者健康。
Each node in output and hidden layers has its own classifiers. The input layer takes inputs and passes on its scores to the next hidden layer for further activation and this goes on till the output is reached.
输出层和隐藏层中的每个节点都有自己的分类器。 输入层接受输入并将其分数传递到下一个隐藏层以进行进一步激活,并一直进行到达到输出为止。
This progress from input to output from left to right in the forward direction is called forward propagation.
从输入到输出从左到右在向前方向上的这种进展称为前向传播。
Credit assignment path (CAP) in a neural network is the series of transformations starting from the input to the output. CAPs elaborate probable causal connections between the input and the output.
神经网络中的信用分配路径(CAP)是从输入到输出的一系列转换。 CAP详细说明了输入和输出之间可能的因果关系。
CAP depth for a given feed forward neural network or the CAP depth is the number of hidden layers plus one as the output layer is included. For recurrent neural networks, where a signal may propagate through a layer sev
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 507
507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









