







NumPy是python的专用数组,底层是C语言实现的,节省内存,开发效率高。而Pandas则是一款功能强大的数据分析工具,是为处理表格数据而生的。
一:numpy文件的存取
NumPy提供了多种存取数组内容的文件操作函数。保存数组数据的文件可以是二进制格式或者文本格式。二进制格式的文件又分为NumPy专用的格式化二进制类型和无格式类型。
一,tofile()和fromfile()
-
- tofile()将数组中的数据以二进制格式写进文件
- tofile()输出的数据不保存数组形状和元素类型等信息
- fromfile()函数读回数据时需要用户指定元素类型,并对数组的形状进行适当的修改
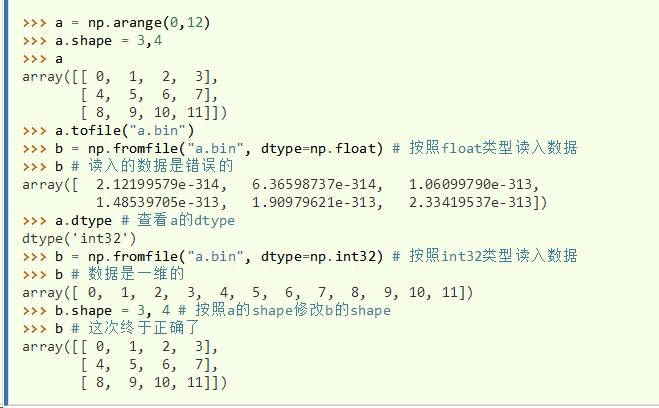
从上面的例子可以看出,在读入数据时:需要正确设置dtype参数,并修改数组的shape属性才能得到和原始数据一致的结果。无论数据的排列顺序是C语言格式还是Fortran语言格式,tofile()都统一使用C语言格式输出。此外如果指定了sep参数,则fromfile()和tofile()将以文本格式对数组进行输入输出。sep参数指定的是文本数据中数值的分隔符。
二.save()和load()
- NumPy专用的二进制格式保存数据,它们会自动处理元素类型和形状等信息
- 如果想将多个数组保存到一个文件中,可以使用savez()
- savez()的第一个参数是文件名,其后的参数都是需要保存的数组,也可以使用关键字参数为数组起名
- 非关键字参数传递的数组会自动起名为arr_0、arr_1、...。
- savez()输出的是一个扩展名为npz的压缩文件,其中每个文件都是一个save()保存的npy文件,文件名和数组名相同
- load()自动识别npz文件,并且返回一个类似于字典的对象,可以通过数组名作为键获取数组的内容


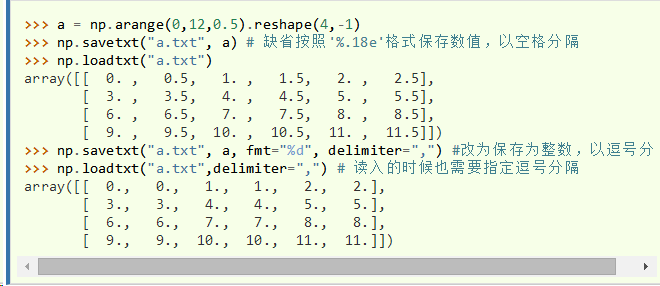
三.savetxt()和loadtxt()
- 读写1维和2维数组的文本文件
- 可以用它们读写CSV格式的文本文件


四.文件对象file

二:pandas文件存取
数据结构:pandas给人的感觉就是自带索引,所以查找的效率是比较高的呃。在使用pandas的时候要时刻记着它是一张表,就可以创建,增删改查等操作。也可以结合数据库中的表项来理解。
- from pandas import *
- from random import *
- df = DataFrame(columns=('lib', 'qty1', 'qty2'))#生成空的pandas表
Series:一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近,其区别是:List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。
Time- Series:以时间为索引的Series。
DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。
Panel :三维的数组,可以理解为DataFrame的容器。
Pandas 有两种自己独有的基本数据结构。读者应该注意的是,它固然有着两种数据结构,因为它依然是 Python 的一个库,所以,Python 中有的数据类型在这里依然适用,也同样还可以使用类自己定义数据类型。只不过,Pandas 里面又定义了两种数据类型:Series 和 DataFrame,它们让数据操作更简单了。
一、读取文本格式数据


注:索引:将一个或者多个列返回dataframe来处理,获取列名;类型推断和数据转换:用户定义值得转换,缺失值的标记等;日期解析:包括组合功能,比如将分散在多个列中的日期数据组合成单个列;迭代:支持大文件逐块迭代,而不是一次性读取;不规整数据问题:可以跳过,清洗。
二、示例操作



























 463
463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









