







 本文介绍了神经网络的基础,特别是反向传播算法。神经网络由多层感知器组成,单层感知器类似线性分类器。多层感知器通过反向传播算法更新权重,但该算法易陷入局部最小,可能导致过拟合。深度学习采用预训练和权重微调等技巧解决了这些问题。文章通过一个简单的网络模型解释了前向传播和反向传播的过程,并提供了相关代码实现。
本文介绍了神经网络的基础,特别是反向传播算法。神经网络由多层感知器组成,单层感知器类似线性分类器。多层感知器通过反向传播算法更新权重,但该算法易陷入局部最小,可能导致过拟合。深度学习采用预训练和权重微调等技巧解决了这些问题。文章通过一个简单的网络模型解释了前向传播和反向传播的过程,并提供了相关代码实现。
神经网络又火了,因为深度学习火了,所以必须增加个传统神经网络的介绍,尤其是back propagation算法。很简单,俺也就不舞文弄墨的说复杂咯,神经网络模型如(图一)所示:
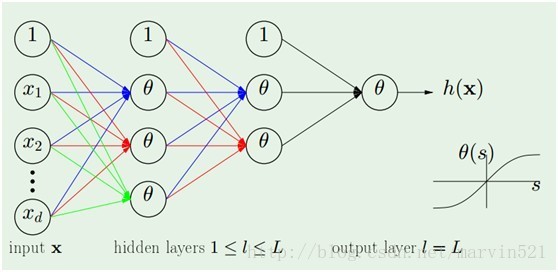
(图一)
(图一)中的神经网络模型是由多个感知器(perceptron)分几层组合而成,所谓感知器就是单层的神经网络(准确的说应该不叫神经网络咯),它只有一个输出节点,如(图二)所示:
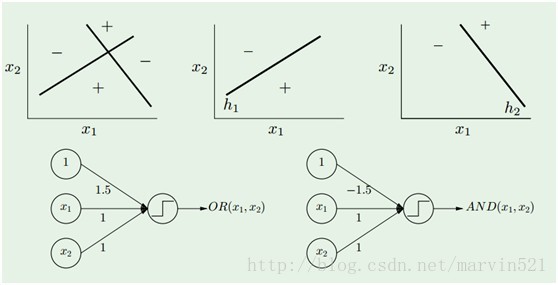
(图二) 感知器
一个感知器就相当于一个线性分类器,而一层神经网络有多个隐藏节点的,就是多个感知器的组合,那么它其实就是多个线性分类器组合形成非线性分类器咯,如(图三)所示:
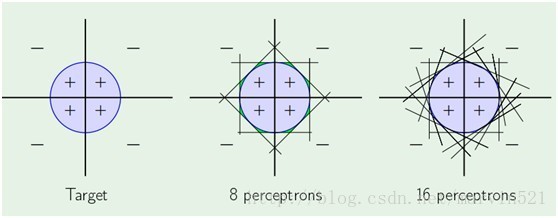
(图三)
一层感知器拟合能力就颇为强大,而多层的感知器组合起来,那拟合能力更没得说,可惜的是拟合能力虽然强大,但是求出准确拟合参数的算法不是太好,容易陷入局部最小,而且BP算法很“擅长”陷入局部最小,所谓局部最小,如(图四)所示,网络的权重被随机初始化后,然后求得梯度,然后用梯度更新参数,如果初始化的参数的点选择的不恰当,当梯度为0的点可能是一个使得代价J局部最小的点,而不是全局最小的,自然得到的网络权重也不是最好的。BP算法一直都有这样的问题,而且也容易因为网络规模大导致过拟合,好在最近深度学习提了一系列的trick改善了这些问题。比如用贪心预训练来改进初始化参数,相当于找到了一个好的初始点,严格的说是在正负阶段里主动修改了J的“地形”,这是个人的一些理解,最后再结合标签用传统的BP算法继续进行寻找全局最小,这个BP算法的作用在深度学习里也叫权重微调,当然BP不是唯一的权重微调算法,各种微调的宗旨只有一个ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









