







一、什么是Kafka
Kafka是一个开源的分布式流处理平台,由Apache软件基金会开发并维护。它最初是由LinkedIn开发的,用于解决大规模的实时数据传输和处理问题。
Kafka的设计目标是提供高吞吐量、低延迟的数据传输,同时保证数据的持久性和可靠性。它提供了一种分布式、可扩展的发布-订阅模型,允许多个生产者将数据发布到一个或多个主题(topic),同时多个消费者可以从一个或多个主题订阅数据进行处理。
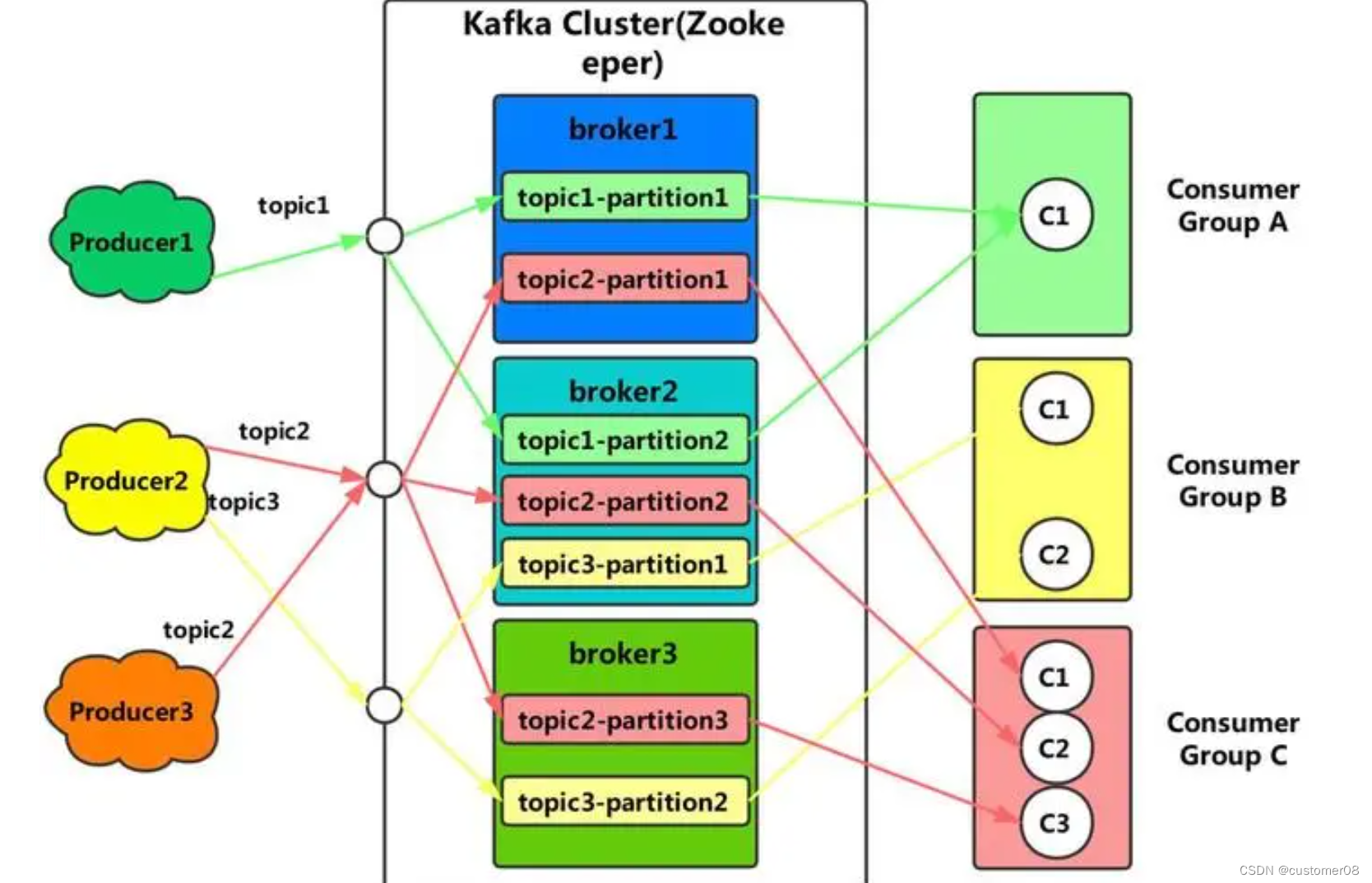
Kafka的基本组件包括以下几个部分:
- Broker:Kafka的服务器节点,存储和处理数据。多个Broker组成一个Kafka集群。
- Topic:数据发布的逻辑概念,数据被分成一个或多个主题,每个主题可以有多个分区(partition)。
- Partition:每个主题可以分为多个分区,每个分区在不同的Broker上进行存储和处理。分区是Kafka实现高吞吐量和可扩展性的关键。
- Producer:数据的生产者,负责将数据发布到指定的主题。
- Consumer:数据的消费者,订阅一个或多个主题的数据,并进行处理。
- Consumer Group:一个或多个消费者组成一个消费者组,每个消费者组可以订阅一个或多个主题。
Kafka具有高吞吐量、可扩展性和持久性的特点,适用于大规模的实时数据处理场景,如日志收集、事件驱动架构、消息队列等。它已广泛应用于各行各业,成为流处理和消息传递的重要工具之一。
二、Kafka的应用场景
Kafka的应用场景非常广泛,以下是一些常见的应用场景:
- 日志收集和处理:Kafka可以作为集中式的日志收集系统,收集分散在多个服务器上的日志数据,并将其发送到相应的消费者进行处理和存储,如ELK(Elasticsearch, Logstash, Kibana)堆栈。
- 消息队列:Kafka的高吞吐量和低延迟特性使其成为消息队列的优选工具。它可以作为异步通信的中间件,可用于解耦多个系统之间的通信,如微服务架构中的消息传递。
- 流式处理:Kafka的流处理功能使其成为实时数据处理和分析的关键组件。通过将数据发布到Kafka主题,多个消费者可以并行处理和分析数据,如实时数据分析、实时推荐等。
- 数据管道和ETL:Kafka可以作为数据管道的基础,将数据从不同的数据源、数据仓库、应用程序之间进行可靠的传递和转换,如数据湖架构和数据集成。
- 事件驱动架构:Kafka的发布-订阅模型和持久性特性使其成为事件驱动架构的理想选择。多个服务可以通过Kafka传递事件消息,以实现解耦、伸缩性和可靠性。
- 实时流分析:Kafka可以与实时流处理框架(如Apache Storm、Apache Flink和Spark Streaming)结合使用,以实现实时数据流的处理和分析,如实时计算、异常检测等。
- 网络监控和传感器数据:Kafka可以用于收集和处理大规模的网络监控数据和传感器数据,如物联网(IoT)应用、智能城市、工厂自动化等。
总而言之,Kafka的高性能、可扩展性和可靠性使其在各种大规模实时数据处理场景下表现出色。无论是日志收集、消息传递、流处理还是事件驱动架构,Kafka都能提供高效的解决方案。
三、springboot如何整合Kafka
在Spring Boot中整合Kafka非常简单。下面是整合Kafka的基本步骤:
添加Kafka依赖:在pom.xml文件中添加Kafka相关的依赖,如下所示:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
配置Kafka连接:在application.properties或application.yml文件中配置Kafka的连接信息,如下所示:
spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.consumer.group-id=group1
创建生产者:创建一个Kafka生产者类,用于发送消息到Kafka主题。可以使用KafkaTemplate类来简化生产者的操作,如下所示:
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
@Component
public class KafkaProducer {
private final KafkaTemplate<String, String> kafkaTemplate;
public KafkaProducer(KafkaTemplate<String, String> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void sendMessage(String topic, String message) {
kafkaTemplate.send(topic, message);
}
}
创建消费者:创建一个Kafka消费者类,用于从Kafka主题接收消息并进行处理。可以通过在方法上添加@KafkaListener注解来指定要监听的主题,如下所示:
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class KafkaConsumer {
@KafkaListener(topics = "my-topic", groupId = "group1")
public void receiveMessage(String message) {
// 处理接收到的消息
System.out.println("Received message: " + message);
}
}
使用Kafka:在其他业务逻辑中可以通过注入KafkaProducer类来发送消息,如下所示:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class MyController {
private final KafkaProducer kafkaProducer;
@Autowired
public MyController(KafkaProducer kafkaProducer) {
this.kafkaProducer = kafkaProducer;
}
@PostMapping("/send")
public void sendMessage(@RequestBody String message) {
kafkaProducer.sendMessage("my-topic", message);
}
}
通过以上步骤,你就可以在Spring Boot应用中成功整合Kafka,并使用生产者发送消息,以及消费者接收和处理消息了。记得在启动类上加上@EnableKafka注解来启用Kafka支持。
四、什么是Kafka重平衡运维
Kafka重平衡(Rebalancing)是指在Kafka集群中,当消费者加入或退出消费者组时,Kafka会自动重新分配分区给消费者,以保证每个消费者处理相对均衡的负载。重平衡是Kafka集群的核心机制之一,它确保了高可用性和伸缩性。
Kafka重平衡运维是指在Kafka集群运行过程中,对重平衡操作进行管理和监控。以下是一些重平衡运维的关键点:
- 监控消费者组健康状态:及时监控消费者组的健康状态,确保每个消费者都正常运行。可以通过Kafka提供的命令行工具或监控工具来实现。
- 避免频繁的加入和退出消费者:频繁的消费者加入和退出会触发频繁的重平衡操作,影响Kafka集群的稳定性和性能。因此,应该尽量避免频繁的消费者变动。
- 控制消费者组的分区分配策略:可以通过配置消费者组的分区分配策略来控制重平衡的行为。Kafka提供了两种默认的策略:Range和RoundRobin,也可以自定义策略。
- 配置适当的消费者组和分区数量:合理配置消费者组和分区的数量,以确保负载均衡和高可用性。如果消费者组过大或分区数量过少,可能会导致性能下降或负载不均衡。
- 处理重平衡失败的情况:在某些情况下,重平衡可能会失败,如网络故障、节点宕机等。在这种情况下,需要及时发现和处理异常,确保集群恢复正常运行。
- 监控重平衡操作的性能:重平衡操作可能会导致一些性能开销,包括网络传输、分区重新分配等。因此,需要监控重平衡操作的性能指标,如延迟、吞吐量等。
总之,Kafka重平衡运维是确保Kafka集群稳定和高效运行的重要任务。通过监控健康状态、合理配置和管理消费者组、处理异常情况等措施,可以保证重平衡操作的顺利进行,并提供良好的性能和可用性。
五、什么是Kafka参数调优
Kafka参数调优是指根据特定的使用场景和需求来调整Kafka的配置参数,以提高Kafka集群的性能、稳定性和可靠性。下面是一些常见的Kafka参数调优的注意事项:
- Broker 参数调优:
num.network.threads和num.io.threads:调整网络和I/O线程的数量,以适应集群的负载。socket.send.buffer.bytes和socket.receive.buffer.bytes:调整TCP Socket的发送和接收缓冲区大小,以提高网络吞吐量。log.segment.bytes:设置每个日志段的大小,以平衡磁盘空间和读写性能。log.roll.hours和log.retention.hours:控制日志段的滚动和保留策略,以适应数据的存储和保留需求。
- Consumer 参数调优:
max.poll.records和fetch.max.bytes:调整消费者每次拉取的消息数量和总字节数,以提高拉取性能。fetch.min.bytes和fetch.max.wait.ms:控制消费者的拉取策略,以平衡吞吐量和延迟。enable.auto.commit和auto.commit.interval.ms:配置消费者的自动提交偏移量的策略,以确保消费的消息不会重复或丢失。
- Producer 参数调优:
acks:设置生产者的消息确认机制(0、1或all),以平衡消息的可靠性和性能。batch.size和linger.ms:控制生产者的消息批量发送行为,以提高发送的吞吐量。compression.type:设置消息的压缩算法,以减小网络传输和磁盘存储的开销。
- JVM 参数调优:
Xmx和Xms:调整Kafka Broker、Consumer和Producer的Java堆内存大小,以适应不同的负载和数据量。XX:+UseG1GC:选择适合的垃圾回收器,以提高JVM性能和内存管理效率。
- 网络和硬件调优:
- 网络带宽和延迟:确保Kafka集群的网络带宽和延迟满足实际需求。
- 磁盘和存储:选择高速和可靠的磁盘存储,以确保数据的持久性和读写性能。
在调优 Kafka 参数时,需要根据实际情况进行测试和性能分析,以找到最优的参数配置。此外,还可以使用Kafka提供的监控工具和指标来实时监测集群的性能和健康状态,进一步进行调优和优化。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











