







Hadoop的mapreduce搭建
MapReduce
首先是spliting吧一个块切割成各种小的
MapReduce的split大小
Max.split(100M)
Min.split(10M)
Block(64M)
Max(min.split, min(max.split,block))
MapReduce的架构
主多从结构
主JobTracker:
负责调度分配每个子任务taskTracker上,如果发现有失败的task就重新分配其任务到其他节点,每个hadoop集群中只一个JobTracker一般它运行在Master节点上(也就是secondaryNode)
从TaskTracker
Tasktracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务,为了减少网络带宽TaskTracker最好运行在HDFS的datanode上
开始搭建
我们随意指定一台机器为主JobTracker
我们用node2作为JobTracker
修改配置文件

官网

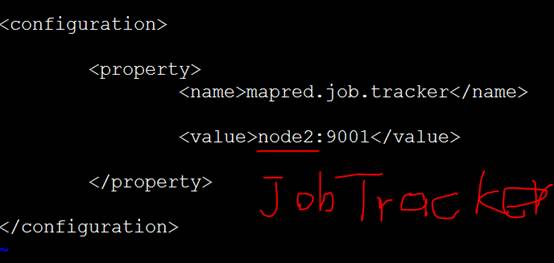
后面的TaskTracker不用直接配,默认就是其他datanode
吧这个文件发到其他主机上


传好之后
启动

然后我们的第一个节点
也就是我们的JobTracker是
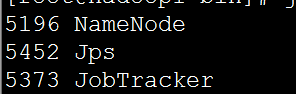
我们其他的datanode是
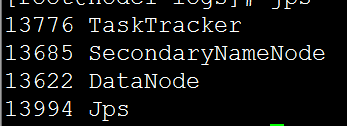
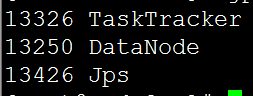
结果:
















 1030
1030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









