







概要
今天(2023/3/3)将教大家怎么对古诗文网的推荐名句进行爬取,难度为入门(星期一想偷懒一下),内容包括:名句内容及其名句出处。
一、使用模块
import csv
import requests
from pyquery import PyQuery as pq二、反爬技术
无
三、分析过程
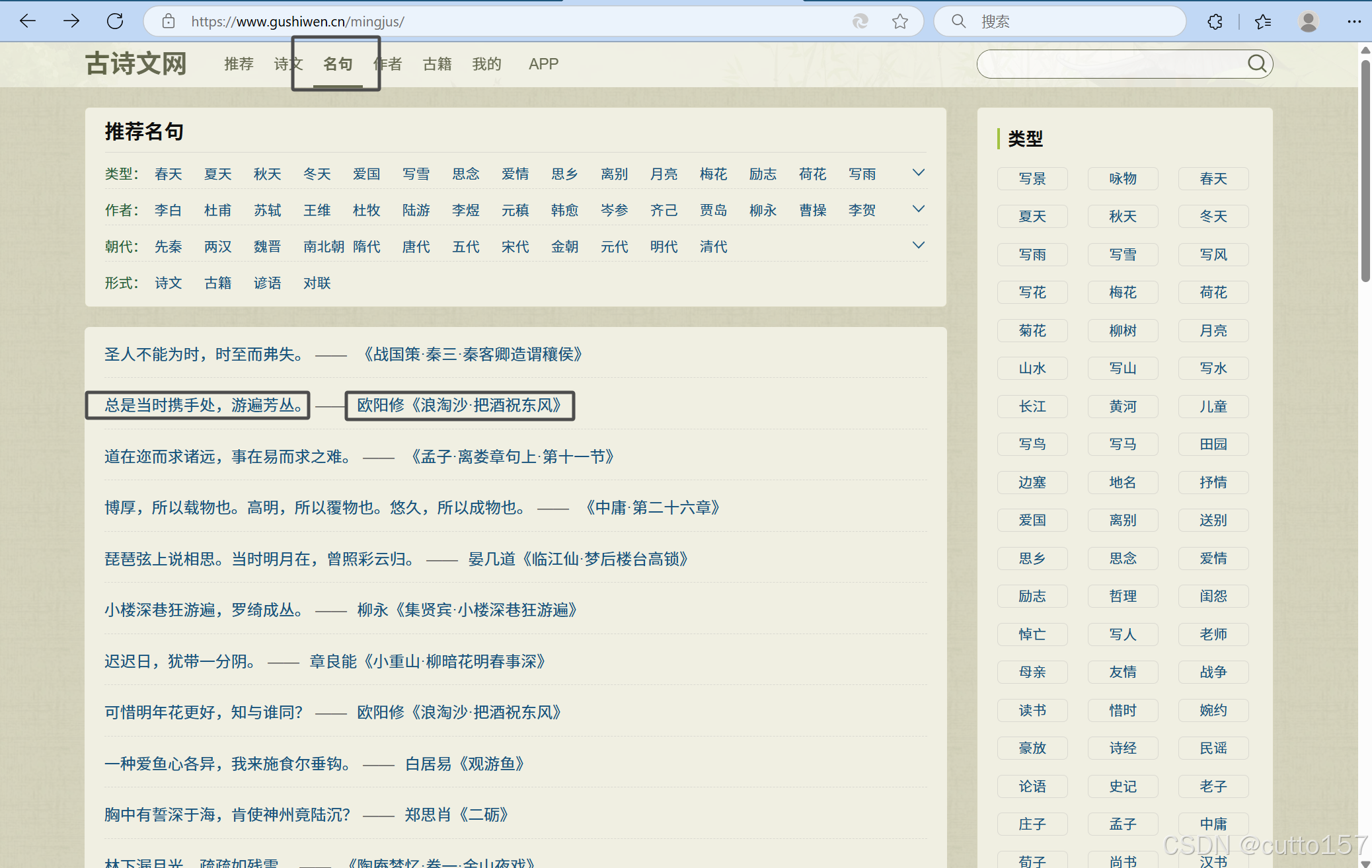
1.查看下一页如何实现,发现采用分页的形式,但是只有上一页和下一页选项,猜测为静态网页,并且上一页为灰色,表示不可点击,猜测有最大页码。

2.空白处右键,打开检查面板,选择网络选项卡,点击下一页,任意选择名句作为关键词进行搜索,发现确实为静态网页,数据嵌入在html中
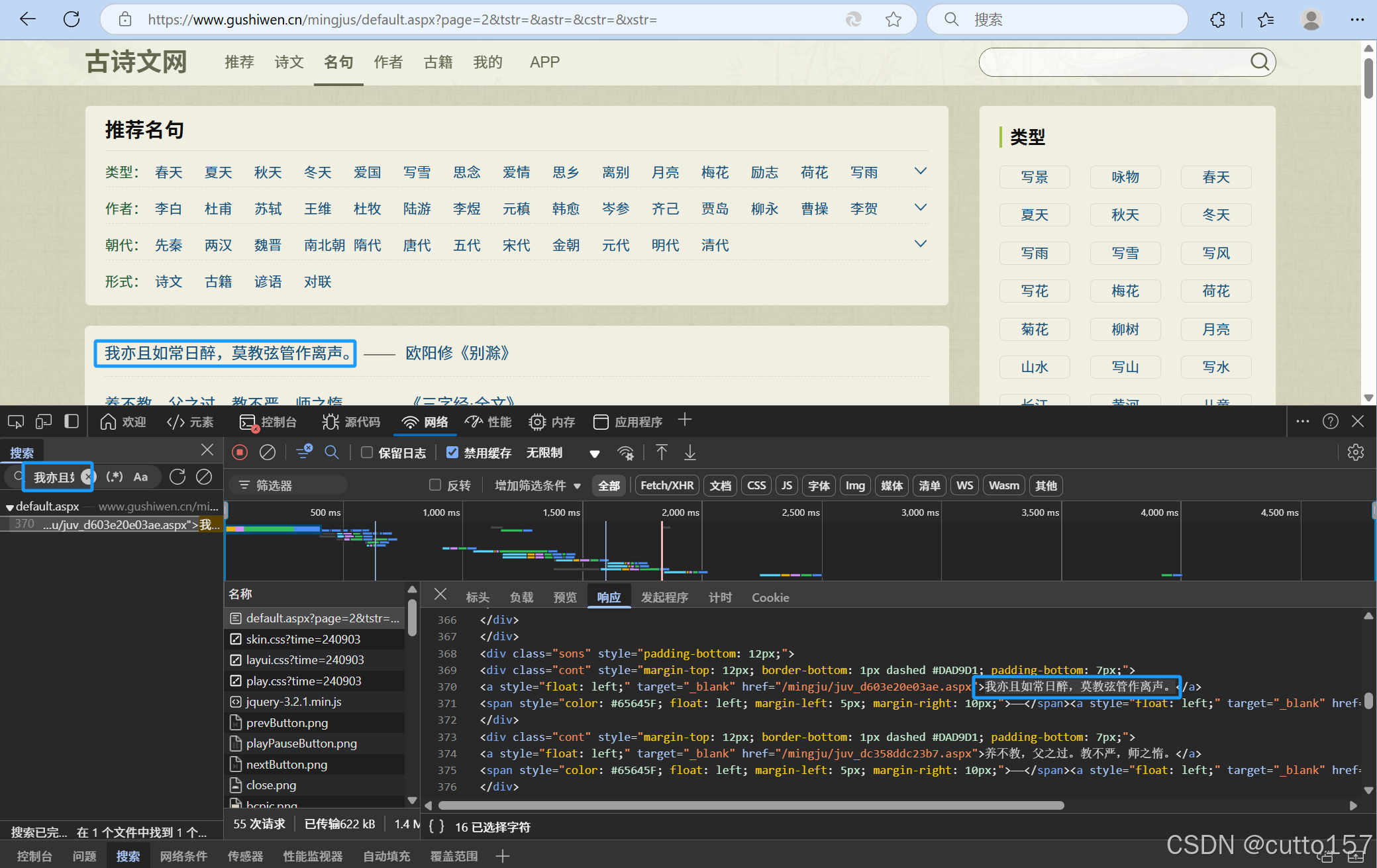
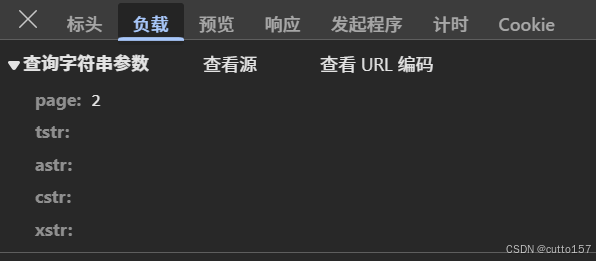
3.接下来,破解请求。发起的是get方式,请求的URL是https://www.gushiwen.cn/mingjus/default.aspx?page=2&tstr=&astr=&cstr=&xstr=,请求的参数有5个,只有page有值,表示为请求第n页。

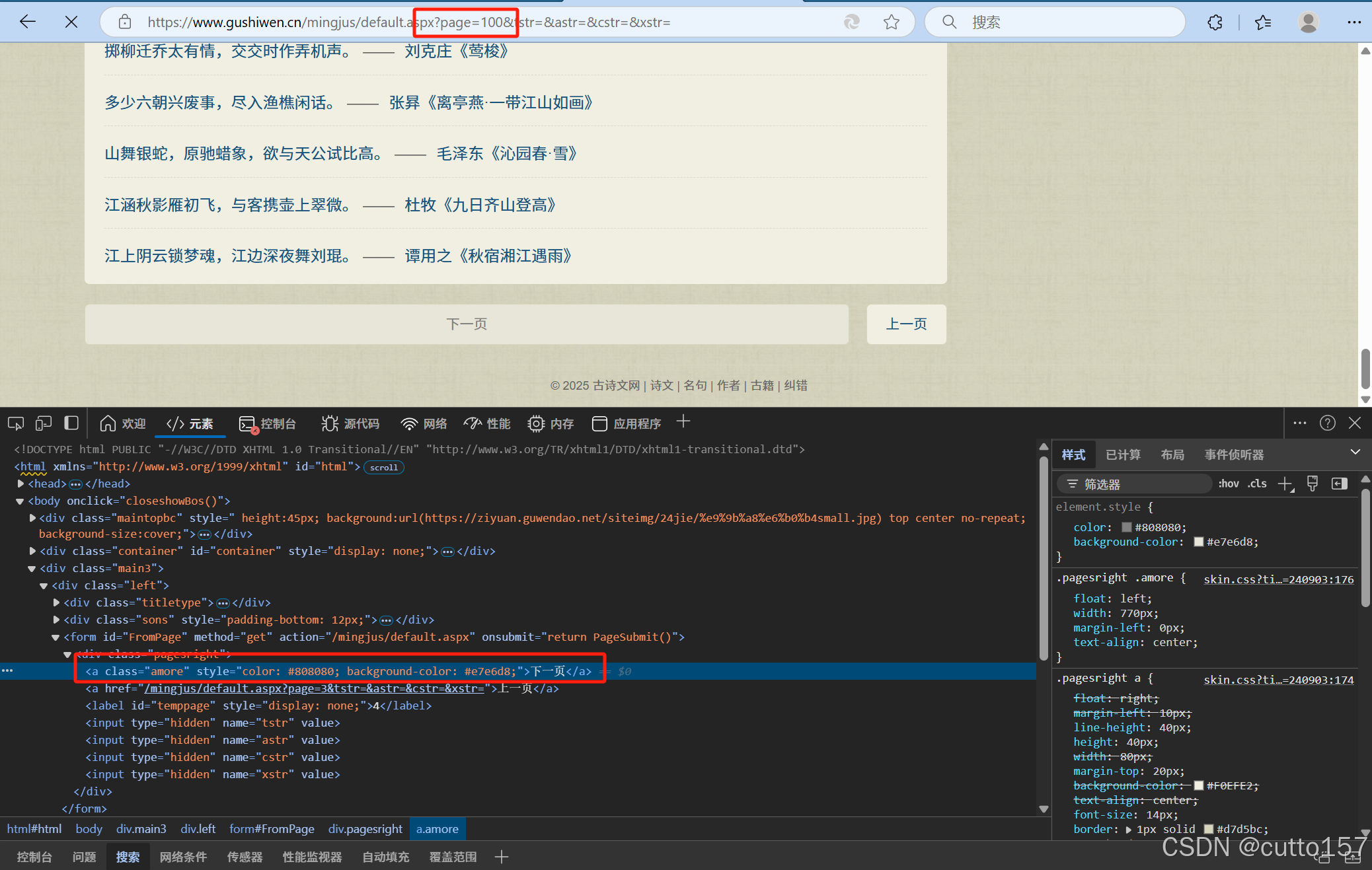
4.根据步骤一的猜测,修改page参数的值,发现确实有最大页码(为20)。
4.分析完毕,接下来进行爬取。首先通过requests模块发起http请求,获取响应的数据,然后通过pyquery提取数据,这里简单的将数据保存到csv中,最后重复(循环)100次。
四、完整代码
import csv
import requests
from pyquery import PyQuery as pq
MAX_PAGE = 20
URL = 'https://www.gushiwen.cn/mingjus/default.aspx'
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36 Edg/133.0.0.0'
}
def fetch_quotes(page):
params = {
'page': page,
'tstr': '',
'astr': '',
'cstr': '',
'xstr': ''
}
try:
response = requests.get(URL, params=params, headers=HEADERS)
response.raise_for_status()
return response.text
except requests.RequestException as e:
print(f"爬取错误,页码 {page}: {e}")
return None
def parse_quotes(html):
doc = pq(html)
quotes = []
for item in doc('div.main3 > div.left > div.sons > div.cont').items():
quote = item.find('a:nth-child(1)').text()
source = item.find('a:nth-child(3)').text()
quotes.append([quote, source])
return quotes
def save_to_csv(writer, quotes):
writer.writerows(quotes)
def main():
fp = open('mingjus-mj.csv', 'w', encoding='utf-8', newline='')
writer = csv.writer(fp)
for page in range(1, MAX_PAGE + 1):
html = fetch_quotes(page)
if html:
quotes = parse_quotes(html)
save_to_csv(writer, quotes)
print(f'第{page}页,爬取完毕')
if __name__ == "__main__":
main()
小结
今天的内容比较简单,适合新手入门。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









